【大模型微调实战】第1期:在6GB笔记本上跑通存储领域CPT全记录
前言
大模型微调听起来是“算力巨头”的游戏,动辄需要 A100、H100 这样的高端显卡。但对于学生党或个人开发者来说,手里往往只有一张消费级显卡——比如我手上这台 6GB 显存的 RTX 3060 笔记本。
能不能在这种“乞丐版”硬件上,完成一次完整的大模型领域微调?这正是本系列文章要回答的问题。
本系列将完整记录我基于 Qwen3-4B 模型,在存储垂直领域进行 CPT(持续预训练)→ SFT(监督微调)→ DPO(偏好对齐) 三段式训练的全过程。作为开篇,本文聚焦于 CPT 阶段:从环境搭建、数据准备、模型选型到训练完成并评估效果。
一、项目概述与硬件约束
项目名称:KnowledgeForge Pro——面向企业存储知识库的大模型三段式训练系统
项目目标:基于 Qwen 系列基座模型,通过完整的 CPT → SFT → DPO 流程,打造一个懂存储术语、回答专业的垂直领域大模型。
硬件环境:
-
GPU:NVIDIA GeForce RTX 3060 Laptop GPU(6GB 显存) 系统:Windows 11 + WSL2(Ubuntu 22.04) 内存:16GB
6GB 显存是整个项目最大的约束。7B 模型即使 4bit 量化后,加上 LoRA 训练的梯度和优化器状态,显存峰值仍会突破 8GB。因此,模型选型和显存优化成为贯穿始终的核心命题。
二、环境搭建:从 Windows 到 WSL2 的迁移之路
2.1 最初的尝试:Windows 原生环境
最初我在 Windows 上直接搭建环境,使用 Conda 创建 Python 3.11 环境,安装 PyTorch、Transformers 等。但在安装 deepspeed 和 bitsandbytes 时遇到大量问题:
-
bitsandbytes在 Windows 下无官方支持,需用第三方 fork,功能受限且不稳定。 -
deepspeed编译依赖复杂,极易失败。 -
flash-attention等库在 Windows 下几乎无法安装。
结论:Windows 不适合深度学习微调,果断切换到 WSL2。
2.2 WSL2 环境配置
WSL2 可无缝调用 GPU,且与 Windows 文件系统互通,是最优解。环境搭建步骤如下:
bash
# 创建 Conda 环境
conda create -n QWEN python=3.11 -y
conda activate QWEN
# 配置 pip 镜像加速
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 安装 PyTorch(CUDA 12.1)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 安装核心依赖
pip install transformers accelerate peft bitsandbytes
# 克隆 LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[torch,metrics]
验证 GPU 可用性:
bash
python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"输出 True 和 NVIDIA GeForce RTX 3060 Laptop GPU,环境就绪。
三、模型选型:三次迭代找到最优解
模型选型是整个项目中最曲折的环节,前后经历了三次调整。
3.1 初版计划:Qwen2.5-7B
最初计划使用 Qwen2.5-7B,配合 4bit 量化 + LoRA。但在 6GB 显存上,即使 4bit 加载后的 7B 模型,加上训练时的梯度和优化器状态,显存峰值仍超 8GB,直接 OOM。
第一次调整:放弃 7B,转向更小的模型。
3.2 第二次尝试:Qwen3.5-4B(多模态)
我选择了 Qwen3.5-4B,4bit 加载后理论约 2.5GB。但训练时频繁 OOM,且 LLaMA-Factory 命令行启动时报错:
text
ValueError: You cannot perform fine-tuning on purely quantized models.经过排查发现两个问题:
-
Qwen3.5-4B 是原生多模态模型,内置图像、视频处理器,显存开销远超同参数量的纯文本模型。
-
LLaMA-Factory 对 Qwen3.5 的多模态架构支持不完善,导致 LoRA 适配器挂载失败。
第二次调整:放弃多模态模型,寻找纯文本替代。
3.3 最终选择:Qwen3-4B-Instruct
在仔细研究 Qwen 系列架构差异后,我最终选择了 Qwen3-4B-Instruct-2507,一个纯文本大语言模型。
| 对比维度 | Qwen3.5-4B(多模态) | Qwen3-4B-Instruct(纯文本) |
|---|---|---|
| 模型定位 | 原生视觉-语言模型 | 纯文本特化 |
| 4bit 加载显存 | ~2.5 GB(实际峰值更高) | ~3.5 GB(稳定) |
| 训练峰值显存 | 5.5~6.0+ GB(临界 OOM) | 4.5~5.5 GB(稳定) |
| LLaMA-Factory 兼容性 | 有问题 | 完美支持 |
从 ModelScope 下载模型:
bash
modelscope download --model Qwen/Qwen3-4B-Instruct-2507 --local_dir /home/wym/KnowledgeForge/models/Qwen/Qwen3-4B-Instruct第三次调整成功,训练终于能稳定运行。
四、数据准备:从 PDF 到高质量训练语料
4.1 数据采集
我手动收集了 12 份存储领域权威文档,包括:
-
NVMe Base Specification 2.3
-
三星 PM863、860 QVO、950 PRO 等 SSD 白皮书
-
华为 FusionStorage 8.0 对象存储技术白皮书
-
Samsung Memory Over-Provisioning 白皮书
总计约 283 万字符原始语料。
4.2 PDF 文本提取
使用 pdfplumber 批量提取 PDF 中的文本:
python
import pdfplumber
from pathlib import Path
SOURCE_DIR = "/mnt/d/PDF"
OUTPUT_DIR = Path.home() / "KnowledgeForge" / "extracted_txts"
for pdf_path in Path(SOURCE_DIR).glob("*.pdf"):
with pdfplumber.open(pdf_path) as pdf:
text = "\n".join([p.extract_text() or "" for p in pdf.pages])
with open(OUTPUT_DIR / f"{pdf_path.stem}.txt", "w", encoding="utf-8") as f:
f.write(text)4.3 数据清洗与切分
原始文本中包含页眉页脚、乱码、短句等噪声,我编写了清洗脚本:
-
过滤长度小于 20 字符的行
-
过滤非字母数字占比过高的行
-
过滤常见页眉页脚关键词
-
按语义段落切分为 200~600 字符的小段落
为严格评估效果,我采用了文档级留出法:将 2 篇文档(便携 SSD 数据表和数据中心 SSD 白皮书)完全排除在训练集之外,用于后续测试。最终,10 篇训练文档被切分为 4790 个高质量训练样本。
4.4 数据集注册
LLaMA-Factory 需要将数据集注册到 dataset_info.json 中。我创建了 storage_corpus.jsonl(每行一个 {"text": "段落内容"}),并在配置文件中添加:
json
"storage_corpus": {
"file_name": "storage_corpus.jsonl",
"columns": {
"prompt": "text"
}
}五、训练配置与踩坑实录
5.1 显存优化组合拳
为了让 4B 模型在 6GB 显存上稳定训练,我采用了以下配置:
| 配置项 | 值 | 作用 |
|---|---|---|
| 量化加载 | 4bit | 基座模型从 16GB 压缩至 ~3.5GB |
| LoRA rank | 8 | 只训练极少量参数,减少梯度显存 |
| LoRA alpha | 16 | 缩放系数,通常为 rank 的 2 倍 |
| LoRA target | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
挂载到所有注意力层和前馈层 |
| Batch size | 1 | 单卡最小配置 |
| 梯度累积 | 8 | 等效 batch=8,保证训练稳定性 |
| 梯度检查点 | 启用 | 用时间换空间,进一步降低显存 |
截断长度(cutoff_len) |
1024 | 平衡上下文与显存(新版 LLaMA-Factory 中 max_seq_length 已更名为 cutoff_len) |
5.2 DeepSpeed 引发的诡异报错
启动训练时,遇到报错:
text
deepspeed.ops.op_builder.builder.MissingCUDAException: CUDA_HOME does not exist明明在 WebUI 中选择了 Booster: none,为什么还会调用 DeepSpeed?排查后发现,accelerate 库在内部强制导入了 DeepSpeed,即使不用也会触发 CUDA 检查。
解决方案:直接卸载 DeepSpeed。
bash
pip uninstall deepspeed -y卸载后训练顺利启动。
5.3 WebUI 配置与启动
由于 LLaMA-Factory 命令行存在 argparse 格式化 bug,我改用 WebUI 启动训练。关键配置如下:
| 选项卡 | 参数 | 值 |
|---|---|---|
| Model | Model name | Qwen3-4B-Instruct-2507 |
| Model path | /home/wym/KnowledgeForge/models/Qwen/Qwen3-4B-Instruct |
|
| Finetuning type | lora |
|
| Quantization bit | 4 |
|
| Prompt template | qwen3_nothink |
|
| Data | Dataset | storage_corpus |
| Cutoff length | 1024 |
|
| Train | Stage | Pre-Training (PT) |
| Learning rate | 5e-5 |
|
| Num epochs | 1.0 |
|
| Batch size | 1 |
|
| Gradient accumulation | 8 |
点击 Start 后,训练正式开始。整个训练过程耗时约 31 分钟,LLaMA-Factory 自动记录了每一步的 loss 值,并生成了如下 loss 曲线图: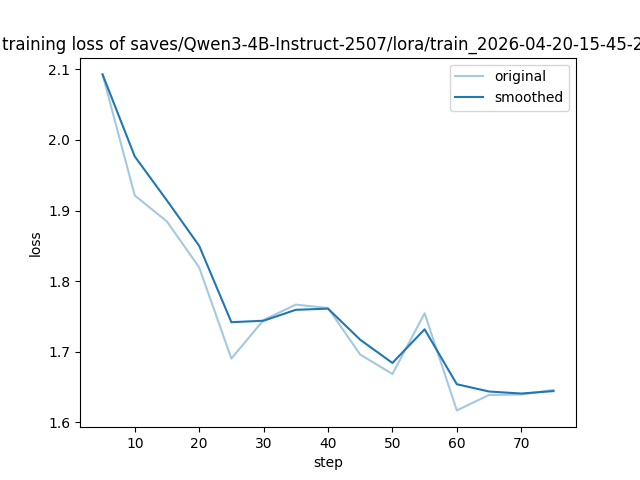
从图中可以清晰地看到:
- 初始 loss 约为 2.09,随着训练推进稳步下降;
- 最终 loss 稳定在 1.65 左右;
- 整个下降过程平滑,未出现剧烈震荡或回升现象。
这表明训练过程稳定,模型收敛良好,未出现过拟合的迹象。
六、效果评估:从“意外”到“惊喜”
6.1 第一次评估:PPL 不降反升
我用预留的两篇文档构建了测试集,计算 CPT 前后的困惑度(PPL)。结果令人沮丧:
| 模型 | 平均 PPL |
|---|---|
| 基座模型 | 18.79 |
| CPT 模型 | 20.11 |
| 变化 | +7.0%(变差) |
6.2 问题诊断
经过分析,我意识到问题出在测试集与训练集的分布差异上:
-
测试集的两篇文档(便携消费级、数据中心场景)与训练集的核心内容(NVMe 协议、企业级 SSD、V-NAND 原理)语言风格差异较大。
-
PPL 衡量的是逐词预测的确定度,模型在训练集上学的模式,反而让它在分布差异大的测试文本上“更困惑”。
6.3 重新构建测试集
为了更准确地评估模型对存储核心技术语言的掌握程度,我从被剔除的测试文档中,重新精心选取了 20 个最具代表性的段落,构建了一个新的测试集。这些段落覆盖了:
-
NVMe 队列模型、命令结构
-
V-NAND 3D 堆叠技术
-
QLC 存储密度与权衡
-
SSD 预留空间(Over-Provisioning)
-
企业存储架构(FusionStorage)
6.4 重新评估:真正的效果
在新测试集上重新计算 PPL:
| 模型 | 平均 PPL | 提升幅度 |
|---|---|---|
| 基座模型 | 32.57 | - |
| CPT 模型 | 25.66 | ↓ 21.2% |
结果完全反转!CPT 模型在存储核心技术语言上的预测能力得到了显著提升。
反思:这个“意外”恰恰证明了评估数据集与训练数据分布一致性的重要性,也体现了严谨的实验设计思维。
七、总结与展望
7.1 关键成果
| 指标 | 数值 |
|---|---|
| CPT 训练样本 | 4790 条 |
| 训练耗时 | 31 分钟 |
| 训练显存峰值 | ~5.5 GB |
| 存储核心技术测试集 PPL 提升 | 21.2% |
7.2 核心踩坑经验
-
Windows ≠ Linux:深度学习微调果断选 WSL2 或纯 Linux。
-
模型选型要看架构:多模态模型显存开销远超纯文本模型,且兼容性差。
-
评估数据要与训练数据分布一致:否则会得出错误结论。
-
DeepSpeed 不是必选项:单卡 QLoRA 完全不需要,装了反而添乱。
-
WebUI 比 CLI 更稳:LLaMA-Factory 的命令行有 argparse bug,WebUI 更可靠。
-
留出法要彻底:以文档为单位划分训练/测试集,避免数据泄露。
-
参数名会随版本变化:
max_seq_length在新版中已改为cutoff_len。
7.3 下一步计划
CPT 阶段的完成为后续工作打下了坚实基础。接下来我将进入:
-
SFT 阶段:基于存储文档构造 5k-10k 条指令问答对,进行监督微调。
-
DPO 阶段:构造偏好数据,提升回答的专业性与安全性。
-
部署评估:模型量化、vLLM 推理加速、综合评测。
敬请期待本系列的下一篇文章!
附:项目文件结构
text
~/KnowledgeForge/ ├── models/Qwen/Qwen3-4B-Instruct/ # 基座模型 ├── extracted_txts/ # PDF 提取的原始文本 ├── cleaned_corpus/corpus.txt # 清洗后语料 ├── test_storage_v2.txt # 存储核心技术测试集 ├── checkpoints/cpt/ # CPT 检查点(实际保存在 LLaMA-Factory/saves/) ├── cpt_config.yaml # 训练配置文件 ├── eval_baseline_ppl.py # 基线 PPL 评估脚本 ├── eval_cpt_ppl.py # CPT 模型 PPL 评估脚本 └── split_and_convert.py # 数据切分脚本

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)