零基础学AI大模型之LLM存储记忆功能之BaseChatMemory
零基础学AI大模型之LLM存储记忆功能之BaseChatMemory
很多刚接触大模型工程的同学,第一次做聊天机器人时都会遇到一个核心问题:模型为什么“记不住”刚才说过的话?
答案通常不是模型变笨了,而是你的程序没有把历史对话正确地传回去。围绕这个问题,LangChain 早期提供过一套经典记忆抽象,其中非常重要的一个基类就是 BaseChatMemory。
对工程师来说,理解 BaseChatMemory 的价值,不只是为了会用一个 API,更重要的是搞清楚:LLM 的“记忆”本质上是消息历史管理问题,而不是模型内部真的长出永久记忆。
不过也要注意,官方文档已经明确说明:BaseChatMemory 自 v1.0 起已弃用,新项目不建议继续作为主方案使用。因此本文会采用“先学原理,再看现代替代方案”的方式,帮助你建立正确的工程认知。
摘要
摘要:本文从零基础视角解释 BaseChatMemory 的定位、核心属性和方法、在链式调用中的工作方式,以及它为什么被官方逐步迁移到 LangGraph 的状态持久化方案。
你将学到以下内容:
- BaseChatMemory 是什么,它在 LangChain 旧架构中负责什么
- 它如何通过
chat_memory管理对话消息历史 save_context、load_memory_variables、clear等方法怎么理解- 为什么官方说它已弃用,问题出在哪里
- 新项目应该优先选什么:LangGraph checkpointer、store、RunnableWithMessageHistory 等
- 如何从工程角度设计“短期记忆”和“长期记忆”
BaseChatMemory 到底是什么
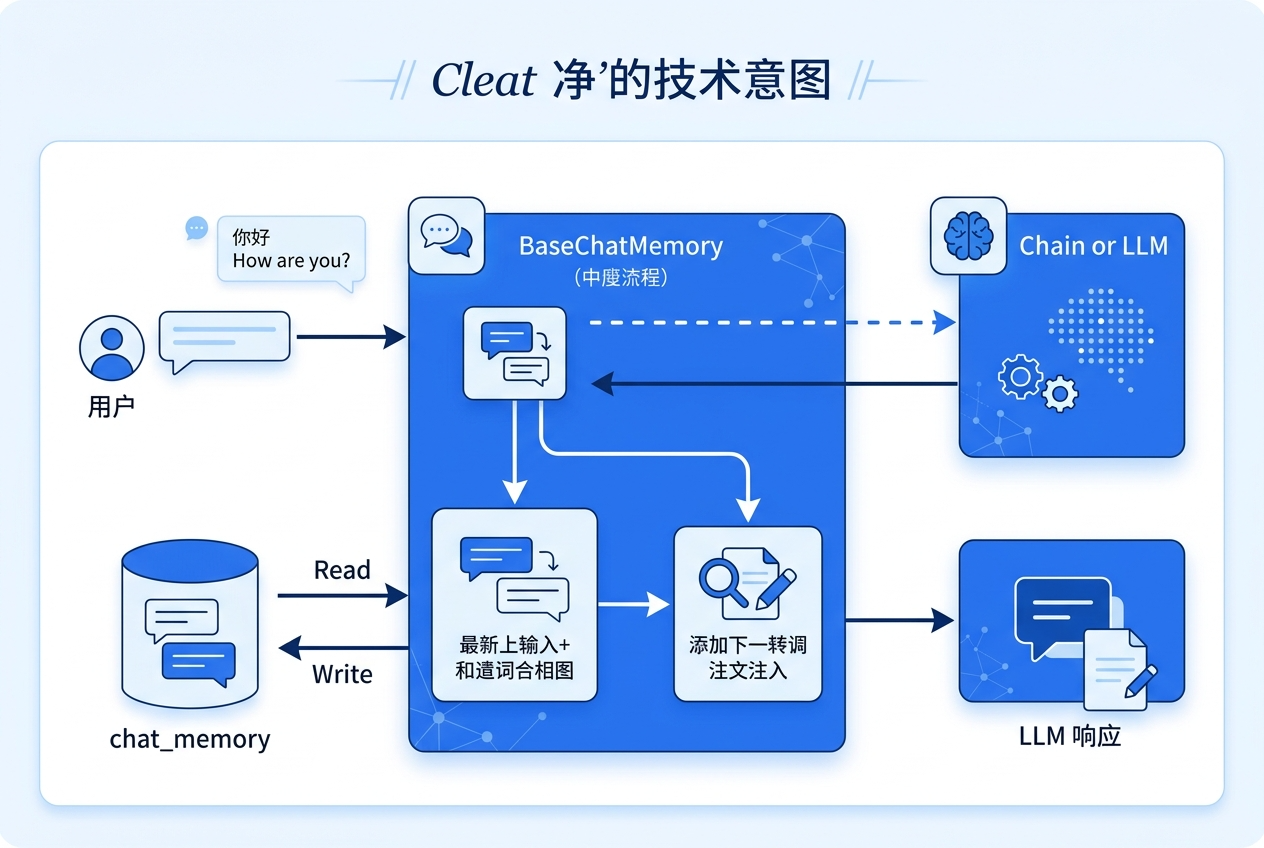
摘要:BaseChatMemory 是 LangChain 早期聊天记忆体系中的抽象基类,职责是把对话消息历史接入链式调用过程。
根据 LangChain 官方参考文档,BaseChatMemory 是聊天记忆的抽象基类,继承自 BaseMemory 和 ABC。[1][2]
它的设计目标非常直接:把用户输入、模型输出整理成聊天消息历史,并在下一轮调用时再注入回去。
换句话说,BaseChatMemory 并不是“数据库”,也不是“向量知识库”,它更像一个中间层:
- 接收本轮输入和输出
- 转成消息历史
- 存入
chat_memory - 在后续调用中把这些历史内容作为上下文变量再交给链或模型
这也是很多初学者容易混淆的地方:
- BaseChatMemory 解决的是“会话上下文延续”
- 不是“跨天、跨设备、跨用户画像”的长期记忆管理
官方文档还特别指出,这个抽象从 v1.0 开始已弃用,并提示其不支持聊天模型原生 tool calling,因此新代码不应继续基于它扩展。[1]
这说明:理解它仍然有学习价值,但不能把它当成未来架构主线。
BaseChatMemory 的核心属性与方法
摘要:掌握 BaseChatMemory 的四个关键属性和三类核心方法,就能读懂大多数旧版记忆类实现。
结合官方 API 文档,[1][2] BaseChatMemory 的关键点主要有这些。
1)核心属性
chat_memory
类型是 BaseChatMessageHistory。[2]
这是最核心的属性,真正存放消息历史的对象就是它。
也就是说,BaseChatMemory 自己不一定直接保存所有内容,它更多是把历史管理委托给 chat_memory。
input_key
用于指定“本轮用户输入”在上下文字典里的字段名。
当链接收多个输入字段时,这个参数就很重要,否则框架可能不知道哪一个是用户消息。
output_key
用于指定“本轮模型输出”对应的字段名。
如果链输出不止一个字段,也需要靠它明确应该保存哪个结果进入对话历史。
return_messages
用于控制记忆变量返回时的格式。
通常可理解为:返回的是原始消息对象列表,还是拼接好的文本形式。
这直接影响后续 Prompt 组装方式。
2)核心方法
load_memory_variables / aload_memory_variables
作用是:把历史记忆作为变量注入到链的输入中。[2]
这是“读记忆”的过程。
例如,在一次链调用前,框架会先问 memory:“你这里有没有应该带上的历史上下文?”
save_context / asave_context
作用是:把本轮输入和输出保存进记忆。[1][2]
这是“写记忆”的过程。
当用户说了一句,模型答了一句,这一轮对话就会被整理后写入 chat_memory。
clear / aclear
作用是:清空当前记忆。[1][2]
适用于:
- 用户主动要求“清空上下文”
- 切换会话线程
- 调试时重置状态
- 避免历史过长导致上下文窗口超限
从工程视角看,这几个方法已经构成了一个很完整的生命周期:
加载记忆 → 调用模型 → 保存本轮 → 必要时清空。
它在旧版 LangChain 里的工作流程
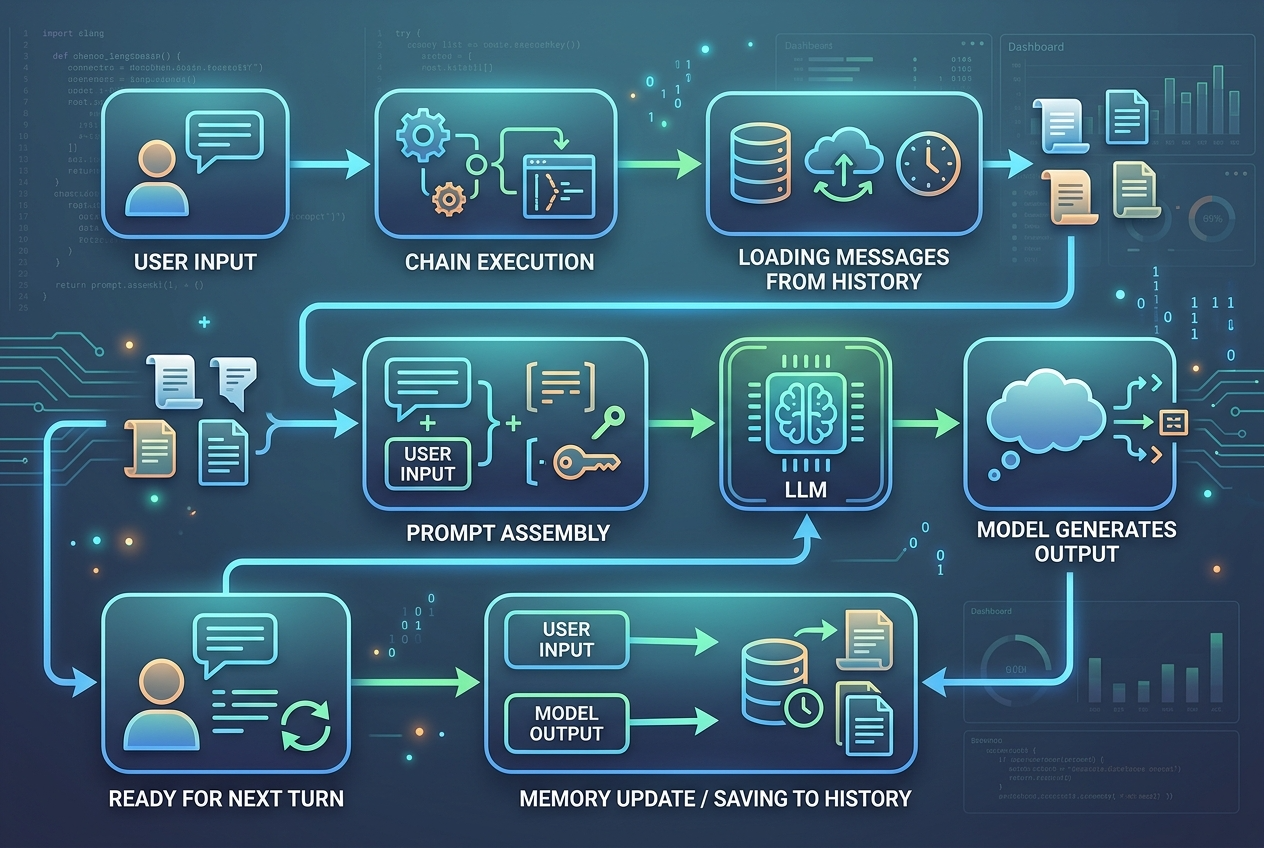
摘要:BaseChatMemory 的本质是把“消息历史注入”和“本轮对话保存”嵌入链调用生命周期中。
很多人对记忆类的理解停留在“存个列表”,但真正重要的是它如何与链协同工作。旧版 LangChain 的典型流程可以简化为下面 4 步:
第 1 步:用户发起请求
例如传入:
{"input": "帮我总结一下昨天讨论的接口设计"}
第 2 步:链调用前加载记忆
框架会调用:
load_memory_variables(...)- 或异步版本
aload_memory_variables(...)
此时 memory 会把已经保存的消息历史整理成某个字段,比如 history,一起交给 Prompt 或 Chain 使用。
第 3 步:模型生成结果
模型结合:
- 当前输入
- 历史对话
- Prompt 模板
生成新的回答。
第 4 步:调用后保存上下文
框架再调用:
save_context(inputs, outputs)- 或
asave_context(inputs, outputs)
把本轮用户输入和模型输出写入 chat_memory。
这个机制说明,BaseChatMemory 更偏向链式编排中的“会话状态适配器”,而不是一个完整的记忆系统。
它最大的价值是帮助开发者在不手写太多状态管理代码的前提下,让聊天链“看起来有上下文”。
为什么官方弃用了 BaseChatMemory
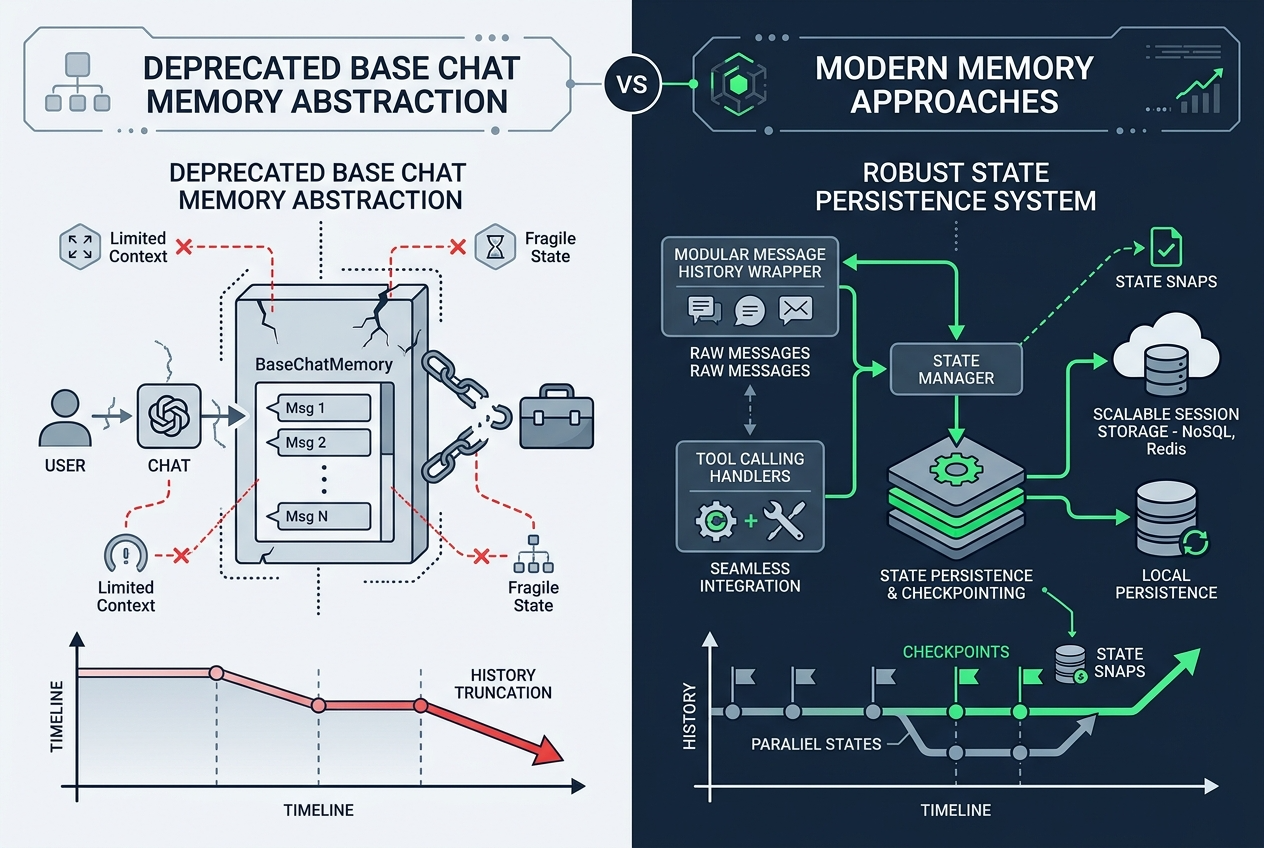
摘要:BaseChatMemory 被弃用,不是因为它完全没用,而是因为它难以支撑现代 Agent、工具调用和复杂持久化场景。
这是本文最值得工程师重视的一部分。
根据官方参考,[1] BaseChatMemory 自 v1.0 起已经标记为 deprecated,并明确指出:它不支持聊天模型原生 tool calling,新代码不应使用。
为什么会这样?结合新版文档与迁移说明,[3][4][5] 可以从几个工程原因理解。
1)旧式 memory 类偏“链时代”,不适合现代 Agent 状态管理
早期 LangChain 的抽象更偏向 Chain。
但现在主流应用越来越多是:
- 多步骤 Agent
- 工具调用
- 多节点状态流转
- 人机混合交互
- 中断恢复与持久化执行
这种场景下,单纯“在链前后读写一段聊天历史”已经不够了。
2)短期记忆与长期记忆需要分开设计
新版 LangGraph 文档明确区分了:
- 短期记忆:线程内、会话内状态,通常由 checkpointer 保存
- 长期记忆:跨线程、跨会话的用户或应用数据,由 store 管理 [3][4]
而 BaseChatMemory 更像是对“短期聊天历史”的一个轻量封装,不适合承担长期记忆职责。
3)上下文窗口管理需要更强的策略
官方新文档强调,可以通过摘要或消息裁剪来避免超过模型上下文窗口。[3]
旧式 Buffer 型记忆很容易无限增长,最终导致:
- token 成本上升
- 响应变慢
- 模型上下文超限
- 关键信息被淹没
4)复杂工程更需要显式状态,而不是隐式魔法
迁移文档指出,现代替代方式包括:
- LangGraph persistence
- LCEL 的
RunnableWithMessageHistory[5]
其中很多用户会发现,LangGraph 持久化更适合复杂场景,也更容易配置和维护。[5]
因为它让状态变成系统设计的一部分,而不是藏在 memory 对象里。
新项目应该如何选择记忆方案
摘要:如果你是新项目,不要把 BaseChatMemory 当主线;应该按“线程内短期记忆”和“跨会话长期记忆”拆开选型。
下面给出工程上更实用的选择思路。
方案一:只做简单单轮或少量多轮聊天
如果只是一个很轻的聊天 Demo,可以仍然理解旧式 memory 的思想,但不建议继续深度绑定 BaseChatMemory。
你至少要意识到,它更适合:
- 教学
- 理解消息历史机制
- 阅读旧代码
- 维护遗留项目
方案二:线程内短期记忆,优先 LangGraph Checkpointer
新版 LangGraph 文档推荐通过 checkpointer 保存线程内状态,例如 InMemorySaver。[3]
它适用于:
- 一个会话线程内保留消息历史
- 支持中断恢复
- 更自然地与图状态融合
这是当前官方主推方向。
方案三:跨会话长期记忆,使用 Store 或专门记忆层
如果你的需求是:
- 记住用户偏好
- 记住历史工单摘要
- 跨设备恢复用户画像
- 多会话复用个人信息
那就不是 BaseChatMemory 能解决的了。
新版文档与生态工具更强调通过 store 或专门的长期记忆管理层实现。[3][6][8]
例如 LangMem 的能力更偏向:
- 搜索记忆
- 抽取记忆
- 更新记忆
- 结构化管理 [6]
这与简单的聊天历史缓存完全不是一个层级。
方案四:中间态迁移,可考虑 RunnableWithMessageHistory
迁移指南指出,LCEL 中可以使用 RunnableWithMessageHistory 结合对话历史处理。[5]
这对从旧链式写法平滑升级的团队是一个折中方案。
Key Comparison Table
摘要:下面这张表从工程落地角度比较 BaseChatMemory 与现代替代方案,帮助你快速做技术选型。
| Dimension | BaseChatMemory | RunnableWithMessageHistory | LangGraph Checkpointer | Store / LangMem 类长期记忆 |
|---|---|---|---|---|
| 官方定位 | 旧版聊天记忆抽象基类,已弃用[1] | LCEL 体系下的消息历史包装方案[5] | 官方推荐的线程内状态持久化方案[3][4] | 跨会话、长期记忆管理方案[3][6] |
| 主要解决问题 | 保存和注入聊天历史 | 为 runnable 注入消息历史 | 保存线程内对话状态、支持恢复 | 保存用户偏好、长期事实、应用数据 |
| 适合场景 | 遗留项目、学习旧架构 | 需要平滑迁移的中等复杂度项目 | 新 Agent / 新对话系统主方案 | 需要跨线程、跨会话记忆的系统 |
| 对工具调用支持 | 官方明确提示不支持原生 tool calling[1] | 相比旧 memory 更灵活,但不是长期记忆 | 更适合现代图式编排和工具调用流程[3][4] | 不负责线程流转,但适合长期知识保留 |
| 状态粒度 | 主要是聊天消息列表 | 主要是消息历史 | 图状态/线程状态 | 用户级、应用级长期数据 |
| 持久化能力 | 取决于底层 chat_memory,实现较弱 | 可接历史实现,但需自行设计 | 官方围绕 persistence 进行设计[3][5] | 通常具备更明确的持久化和检索能力[6][8] |
| 上下文控制 | 旧式方案易无限增长 | 需要自行结合裁剪策略 | 可配合摘要、裁剪、线程状态管理[3] | 通常通过检索相关记忆,而非全量塞进上下文 |
| 新项目推荐度 | 不推荐 | 可作为过渡方案 | 高 | 高,尤其适合个性化系统 |
实战代码示例
摘要:下面先用一个“旧式理解示例”帮助你读懂 BaseChatMemory 的调用形态,再给出一个更接近现代官方方向的 LangGraph 短期记忆示例。
需要先强调:下面第一个示例是为了帮助你理解 BaseChatMemory 思路,不是推荐你在新项目中继续重度使用它。
示例一:理解 BaseChatMemory 风格的保存与读取
# 目的:演示旧式聊天记忆的基本调用思路
# 关键点:创建 memory,对一轮输入输出执行 save_context,再读取 memory variables
from langchain.memory import ConversationBufferMemory
# ConversationBufferMemory 是基于旧 memory 体系的常见实现
# 本质上可看作 BaseChatMemory 思路的一个具体子类
memory = ConversationBufferMemory(
memory_key="history", # 历史变量名,供 Prompt 使用
return_messages=False # 返回拼接文本而不是消息对象列表
)
# 模拟第一轮对话:用户输入 + 模型输出
memory.save_context(
{"input": "我叫小王,是一名后端开发"},
{"output": "好的,我记住了,你叫小王,是一名后端开发。"}
)
# 模拟第二轮开始前加载记忆
memory_vars = memory.load_memory_variables({"input": "你还记得我是谁吗?"})
print("注入给链的记忆变量:")
print(memory_vars)
这个示例说明了两件事:
- save_context 是写入动作
- load_memory_variables 是读取动作
在旧式链里,Prompt 通常会接收一个 history 变量,然后把它和本轮用户输入一起发给模型。
示例二:LangGraph 风格的线程内短期记忆示意
# 目的:演示新版官方方向中的“线程内短期记忆”思路
# 关键点:使用 checkpointer 保存对话状态,而不是依赖旧式 BaseChatMemory
from langgraph.checkpoint.memory import InMemorySaver
# 创建一个内存型 checkpointer
# 适合本地开发、Demo、单进程测试
checkpointer = InMemorySaver()
# 实际项目里,checkpointer 会挂接到图执行流程中
# 每个 thread_id 对应一个会话线程状态
thread_id = "user-1001-session-01"
# 下面仅做概念示意:状态通常包含 messages 等字段
state = {
"messages": [
{"role": "user", "content": "我喜欢 Python 和分布式系统"},
{"role": "assistant", "content": "好的,我会基于你的技术偏好继续交流。"}
]
}
# 在真实 LangGraph 中,状态会随图节点推进而被持久化
print("当前线程ID:", thread_id)
print("当前状态:", state)
print("checkpointer 已准备好,可用于线程内状态保存。")
这个示例虽然简化了图编排细节,但能帮助你建立新版认知:
- 记忆不再只是一个 memory 对象
- 而是整个图执行状态的一部分
- 线程内记忆应由 persistence/checkpointer 负责 [3][4]
示例三:长期记忆设计思路示意
# 目的:说明“聊天历史”和“长期记忆”应分层设计
# 关键点:用户偏好不要直接无限堆进聊天上下文,而应独立存储
user_profile_store = {
"user_1001": {
"name": "小王",
"role": "后端开发",
"preferences": ["Python", "分布式系统", "性能优化"]
}
}
def get_user_profile(user_id: str):
# 从长期存储中读取用户画像
return user_profile_store.get(user_id, {})
def build_runtime_context(user_id: str, recent_messages: list):
# 运行时上下文 = 长期画像 + 最近消息
# 这样避免把所有历史消息无脑塞给模型
profile = get_user_profile(user_id)
return {
"profile": profile,
"recent_messages": recent_messages[-5:] # 只截取最近几轮,控制上下文长度
}
context = build_runtime_context(
"user_1001",
[
{"role": "user", "content": "最近我在看 gRPC"},
{"role": "assistant", "content": "不错,gRPC 很适合服务间通信。"}
]
)
print(context)
这个设计更符合现代工程实践:
- 最近对话 放在线程内短期记忆
- 稳定用户信息 放在长期存储
- 运行时按需拼装上下文,而不是全量回灌
这也是新版文档强调“短期记忆”和“长期记忆”分离的重要原因。[3][6]
代码块注释规范
摘要:技术博客里的代码不怕短,怕读者不知道你想证明什么,所以注释应服务于“目的、关键步骤、边界条件”。
写 CSDN 技术文章时,我建议代码块注释遵循以下 4 条规则:
1)开头先写“这段代码的目的”
不要一上来就堆 API。
先说明:
- 这段代码演示什么
- 适用什么场景
- 是推荐方案还是仅用于理解旧架构
这样读者不会误学。
2)只注释关键步骤,不要逐行翻译
差的注释是:
x = 1 # 定义x等于1
好的注释是:
# 这里显式指定 memory_key,避免 Prompt 模板拿不到历史字段
memory = ConversationBufferMemory(memory_key="history")
注释应该解释“为什么这样写”,而不是复述“写了什么”。
3)对旧方案要加风险提示
像 BaseChatMemory 这类旧 API,代码块里应明确标注:
- 这是旧式方案
- 新项目不推荐
- 用它只是为了理解机制或维护遗留代码
这能避免读者直接复制到生产环境。
4)对省略部分要坦诚说明
如果示例没有覆盖完整配置,例如 LangGraph 图构建过程被简化了,就要在注释中说明“这是概念示意”。
工程博客最忌讳的是让读者以为“复制即运行”,结果缺一堆上下文。
常见问题与排错
摘要:BaseChatMemory 相关问题,大多不是模型问题,而是输入输出字段、历史注入方式和架构选型出了偏差。
1)为什么模型还是记不住上一轮内容?
先检查是否真的调用了 save_context,以及下一轮前是否调用了 load_memory_variables。[2]
如果链没有把历史变量拼进 Prompt,模型当然“记不住”。
2)为什么保存失败或历史为空?
常见原因是 input_key、output_key 配错了。
当输入输出是多字段字典时,BaseChatMemory 不一定能自动判断该保存哪一个字段。[1][2]
3)为什么对话越聊越慢、token 越来越高?
因为旧式聊天记忆通常会不断累积历史。
官方新版文档建议通过摘要或消息裁剪控制上下文长度。[3]
4)为什么工具调用场景表现很别扭?
因为官方已经明确说明 BaseChatMemory 不支持聊天模型原生 tool calling。[1]
如果你在做 Agent 或工具编排,应该优先考虑 LangGraph 方案。
5)我是在维护老项目,还能继续用吗?
可以维护,但不建议继续围绕它扩展新架构。
更稳妥的策略是:旧功能维持运行,新功能逐步迁移到 LangGraph persistence 或 RunnableWithMessageHistory。[5]
结论:学会 BaseChatMemory,但别把它当终点
摘要:理解 BaseChatMemory 是为了建立记忆机制认知,而真正的新项目落地,应转向 LangGraph 的短期状态持久化与长期记忆分层设计。
最后做个工程化总结:
你应该记住的 3 个核心事实
-
BaseChatMemory 本质是聊天历史管理抽象
它负责把输入输出转成消息历史,并在后续调用时注入回去。[1][2] -
它已经被官方弃用
新项目不应继续把它作为核心记忆架构,尤其不适合现代 tool calling 场景。[1] -
现代记忆设计要分层
- 线程内短期记忆:优先 LangGraph checkpointer [3][4]
- 跨会话长期记忆:优先 store / LangMem / 外部持久化层 [3][6][8]
给零基础同学的下一步建议
如果你正在学习大模型工程,我建议按这个顺序继续深入:
- 先理解消息历史是什么、为什么需要注入上下文
- 再读懂 BaseChatMemory 这类旧式抽象,建立基础概念
- 接着学习 LangGraph 的 state、checkpointer、thread 概念
- 最后再做长期记忆:用户画像、偏好存储、事实抽取、召回拼装
这样你的认知会从“会用一个类”,升级为“会设计一套记忆系统”。
参考资料
-
BaseChatMemory | langchain_classic | LangChain Reference
https://reference.langchain.com/python/langchain-classic/memory/chat_memory/BaseChatMemory -
BaseChatMemory — LangChain documentation
https://api.python.langchain.com/en/latest/langchain/memory/langchain.memory.chat_memory.BaseChatMemory.html -
Memory - Docs by LangChain(Python / LangGraph)
https://docs.langchain.com/oss/python/langgraph/add-memory -
Memory - Docs by LangChain(JavaScript / LangGraph)
https://docs.langchain.com/oss/javascript/langgraph/add-memory -
Migrating off ConversationBufferMemory or ConversationStringBufferMemory
https://langchain.cadn.net.cn/python/docs/versions/migrating_memory/conversation_buffer_memory/index.en.html -
Memory API Reference(LangMem)
https://langchain-ai.lang.chat/langmem/reference/memory/ -
LangChain memory is deprecated — what to use in 2026 (JavaScript)
https://db0.ai/blog/langchain-memory-deprecated -
LangGraph(Honcho integration)
https://docs.honcho.dev/v2/integrations/langgraph

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)