【人工智能】-CoPaw + Ollama 打造专属离线AI助理
继上一期微信公众号技能配置教程之后,今天我们来聊聊一个更基础、更核心的话题——如何让CoPaw接入本地大模型,实现完全离线的智能助理。无论你是担心数据泄露,还是想在无网络环境下拥有一个随时待命的AI帮手,这篇教程都能帮你轻松搞定。
CoPaw接入Ollama本地模型后,你可以在自己的电脑上运行一个完全离线、永久免费、数据不出设备的AI智能体。它像真人一样响应你的需求——查资料、写文案、处理文件、设置提醒…而且所有对话和推理都在你自己的硬件上完成,安全可控。
先看最终效果
配置成功后,你在终端里给CoPaw发消息:
我:帮我总结一下今天未读的邮件要点
CoPaw:已为您整理,共有3封重要邮件:1. 关于项目进度……2. 会议纪要……3. 审批提醒……
CoPaw会像贴身助理一样出现在你的电脑中,随时待命——无论有没有网络。
准备工作
- 一台能联网的电脑(Windows / Mac / Linux均可)
- 基本的命令行操作能力(复制粘贴命令即可)
- 愿意花15分钟跟着步骤走一遍
第一步:安装Ollama——本地大模型的“运行时”
Ollama是目前最简单易用的本地大模型运行框架,一条命令就能拉起一个模型,被称为本地AI的“轻骑兵”。
打开终端(Windows用户建议使用PowerShell或WSL2),执行:
# macOS / Linux
curl -fsSL https://ollama.ai/install.sh | sh
# Windows 用户请访问 ollama.com 下载安装包
安装完成后,验证一下:
ollama --version

看到版本号就说明Ollama已经成功跑起来了。
第二步:拉取适合你电脑的本地模型
Ollama支持大量开源模型,但选对模型直接决定了你的使用体验。以下是不同配置电脑的推荐清单:
| 你的配置 | 推荐模型 | 一条命令搞定 |
|---|---|---|
| 8GB内存 / 无独显 | Qwen2.5:3b(国产之光,中文极强) | ollama pull qwen2.5:3b |
| 16GB内存 / 6GB显存 | Qwen2.5:7b(性价比之王) | ollama pull qwen2.5:7b |
| Mac M1/M2/M3 | Gemma2:2b(谷歌出品,极轻量) | ollama pull gemma2:2b |
| 32GB内存 / 高端显卡 | Qwen2.5:14b(智力和能力更强) | ollama pull qwen2.5:14b |

💡 小贴士:如果你不确定自己的配置,推荐从 qwen2.5:3b 开始——它只需要约 2-3GB 内存,绝大多数电脑都能流畅运行。拉取完成后,用 ollama run qwen2.5:3b 测试一下,能正常对话就说明模型部署成功。
第三步:在CoPaw中配置Ollama模型
CoPaw已经全面支持Ollama Provider,能实现模型自动同步和管理。配置方法有两种,任选其一即可。
方法一:Web控制台配置(推荐新手)
-
浏览器打开 CoPaw 控制台:
http://127.0.0.1:8088 -
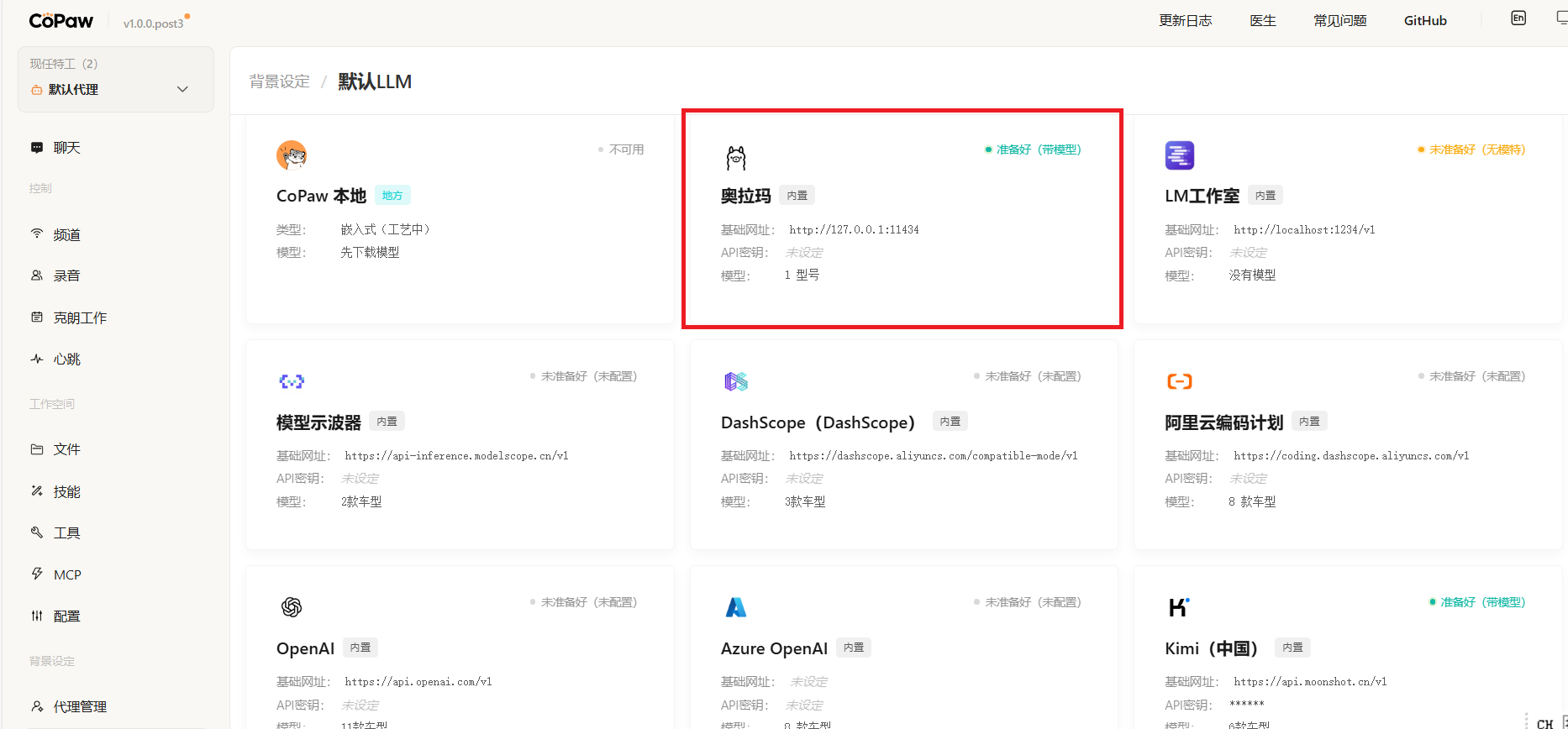
进入 设置 → 模型提供商 页面
-
找到 Ollama 卡片,点击 启用
-
填入本地Ollama服务的地址(默认为
http://127.0.0.1:11434) -
在模型列表中选择你刚才拉取的模型(如
qwen2.5:3b) -
点击保存,CoPaw会自动连接并同步模型
方法二:命令行配置(推荐开发者)
# 添加 Ollama 作为模型提供商
copaw models add-provider ollama --endpoint http://127.0.0.1:11434
# 设置默认使用的模型
copaw models set-default ollama qwen2.5:3b
配置完成后,CoPaw就会使用你本地的Ollama模型来响应所有对话请求——全程离线,数据不出设备。
第五步:验证并开始使用
在CoPaw控制台的对话界面中输入:
你好,请介绍一下你自己
如果CoPaw正常回复,说明配置成功了!
接下来,你可以尝试更多任务:
CoPaw + Ollama 的组合,让你在不依赖任何云服务的情况下,也能享受一个完全离线、永久免费、数据100%可控的个人智能助理。
本文基于 CoPaw 1.0 和 Ollama 最新版本编写,实测有效。如有问题,欢迎留言交流。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)