别再给大厂送钱了! 这些免费AI,强到离谱
你可能还在为一些 AI 工具乖乖付费。 可你没意识到的是——它们的免费替代品,早就安安静静躺在 GitHub 上了,而且很多不只是“能用”,而是更强。
今天介绍 15 个工具,按用途分好类,直接能上手。
如果你已经厌倦了“每个月都在续费,但又总觉得没值回票价”的感觉,那这篇,大概率会让你很不舒服。因为你会突然发现:有些钱,你真的白花了。
一、本地 AI 与聊天:别再什么都往云上送了
1. Jan
很多人一说“本地跑 AI”,第一反应就是:太麻烦了。
要编译、要配依赖、要折腾环境、要和 CUDA 抢命。很多人还没开始,就已经想放弃了。Jan 最厉害的地方就在于,它直接把这些门槛削平了。
它本质上是一个桌面应用,让你可以在自己的电脑上,用几次点击就下载并运行像 LLaMA、Mistral、Gemma 这样的模型。整个过程,完全离线。你不需要 API key,不用担心调用额度,也不用担心数据被送去外面。
更关键的是,它的界面干净到一种很舒服的程度——不懂技术的人也能很快摸清;而对开发者来说,它又不仅仅是个“聊天壳”,因为它还带着本地 API server,可以继续往上接其他工具。
如果你一直想用 AI,但又不愿意拿隐私去换便利,那 Jan 基本就是最适合的起点。
它值得你试的原因,很现实:
完全离线运行,数据不出本机 Windows、macOS、Linux 都有一键安装包 自带本地 API server,方便别的工具直接连接 支持自定义 agent,还能在对话中途切模型
2. Ollama
Jan 给了你入口。 而 Ollama,给的是底盘。
如果说 Jan 更像面向用户的桌面界面,那 Ollama 就是整个本地 AI 生态里,最像“发动机”的那一层。
它是个命令行工具,但做的都是最脏、最麻烦、却也最必要的事:拉模型、管版本、启动服务、暴露 API,而且这个 API 还兼容 OpenAI 格式。你千万别小看这一点——因为这意味着,很多原本写给 ChatGPT 的应用,只要改一行配置,就能直接指向你本地的 Ollama 实例。
这件事其实非常大。
因为一旦本地模型能被当成“云接口的平替”来用,很多原本必须靠订阅才能跑的东西,成本结构会一下子变掉。
现在,已经有很多开发者直接把 Ollama 当后端,零推理费用地搭整套原型系统。它支持的模型也很多,Llama、Mistral、Gemma、DeepSeek、Qwen……主流的基本都能拉。
如果本地 AI 真有根主骨架,那 Ollama 就是其中最硬的一根。
它值得你花时间的点,也很直接:
一条命令就能拉取并运行模型 OpenAI 兼容 API,可以直接替换原有接口 macOS 和 Windows 还有桌面应用,非开发者也能上手 很多本地 AI 工具,其实都是搭在它上面的
3. Open WebUI
Ollama 很强,但问题也很明显:它没什么界面。
终端当然够用,可不是每个人都想天天盯着黑框输入。Open WebUI 做的,就是把 Ollama 这套底层能力,包成一个更像 ChatGPT 的网页 UI,而且它依然跑在你自己的硬件上。
但它厉害的地方,不只是“长得像 ChatGPT”。
因为你真装起来以后会发现,这玩意儿早就不只是聊天壳了。它带完整的 RAG 流程,能拿文档来对话;还能接 web search;支持图像生成;支持多用户账号与权限控制;甚至还有 usage analytics。很多公司内部干脆就是用它替代企业版 AI 订阅,自己搭、自己跑、自己管。
它还很好装,Docker 拉起来,五分钟左右就能用。
这种工具最可怕的地方就在于:一旦你用顺手了,你会开始认真思考,自己之前到底为什么要一直给别人的 SaaS 交钱。
它真正值钱的地方在这:
内置完整文档 RAG,不用额外拼系统 支持多用户部署和角色权限管理 兼容 Ollama、OpenAI,以及各种 OpenAI-compatible 后端 Docker 五分钟起步,落地非常快
二、创意与媒体:有些软件,你真的没必要继续订阅
4. Upscayl
每个设计师手里,几乎都有一个痛苦文件夹。
里面通常装着一些你不忍删、又实在嫌糊的东西:客户 2009 年发来的 logo,早年拍得惨不忍睹的产品图,分辨率低到一放大就想骂人的截图……
Upscayl 就是专门来救这些东西的。
它用 AI 做图像放大,不是那种传统插值式“放大了但更糊”的路线,而是真正意义上尽可能保留细节、减少模糊和伪影。很多时候,结果已经好到可以直接用于印刷,或者至少足够你从“完全没法用”回到“居然还能救”。
更重要的是,它完全本地运行,不上传、不建账号、不打水印,批量处理还特别方便。你丢一整个文件夹进去,它就能一口气干活。
很多设计师第一次认真用它,都会产生同一个念头:我以前到底为什么要为别的替代品付钱?
它值得装的原因,也不需要拐弯抹角:
支持整文件夹批量处理 内置多种模型,适合照片、插画、动漫等不同场景 本地运行,可 GPU 加速,完全不用上传 Windows、macOS、Linux 都有正式安装包
5. Video2X
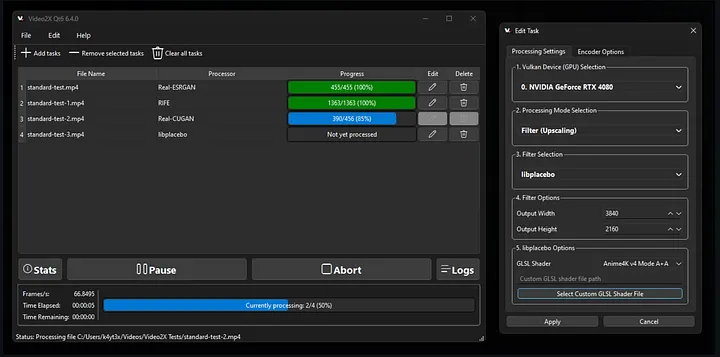
旧视频最怕什么?
不是内容差,而是放到今天的屏幕上看,真的会显得太老。尤其是 2015 年以前拍的很多素材,一上 4K 显示器,糙感会被放大得特别明显。
Video2X 干的,就是这件事:用 AI 去把旧视频重新拉回来。
它会对视频逐帧放大,也能做帧插值,让动作更平滑。说白了,就是把一些原本只有专业工作室才会做的修复思路,用开源工具的方式交到你手里,而且还是免费的。
这些年,做修复的圈子一直在用它。有人拿它修复老动画,有人拿它处理历史影像,有人拿它重做旧项目素材。如果你碰到的任何视频内容,本身不是高清时代的产物,那这工具几乎都值得进你的工作流。
它最打动人的几个点是:
最高支持放大到原始分辨率的 4 倍 支持帧插值,让动作更顺 既有 GUI 也有 CLI,手动和批处理都方便 尤其擅长处理动画,而这恰恰是很多工具的弱项
6. Kdenlive
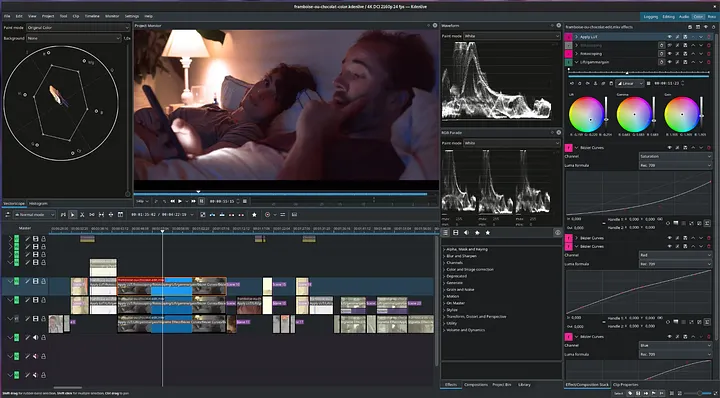
视频剪辑这行,现在最大的问题之一,就是订阅味太重了。
Adobe 每个月都收钱,DaVinci Resolve 很多更专业的功能又锁在付费版后面。Kdenlive 则属于那种已经安安静静做了二十年,却始终不怎么高调的开源剪辑器。
可如果你真把它装下来试,会发现它早就不只是“能用”,而是已经逼近专业级。
更别说,这两年它加的一些 AI 能力,还真挺实在。比如运动追踪,可以跟着画面里的对象跑,把文字或图形钉上去;自动场景检测,能帮你按自然转场切段;还有语音转文字,可以直接生成字幕,不用再额外找一套工具。
很多人愿意为别的软件付钱,买的也就是这些。
但在这里,它们就是自带的。
Kdenlive 值得你重新看一眼,因为:
支持 AI 运动追踪,还能挂复合元素 自动场景检测,剪片效率会快很多 内置语音转文字,可做多语言字幕 专业剪辑该有的功能它基本都有,而且没有订阅
三、数据与 RAG:真正能处理“脏文档”的,没你想的那么多
7. RAGFlow
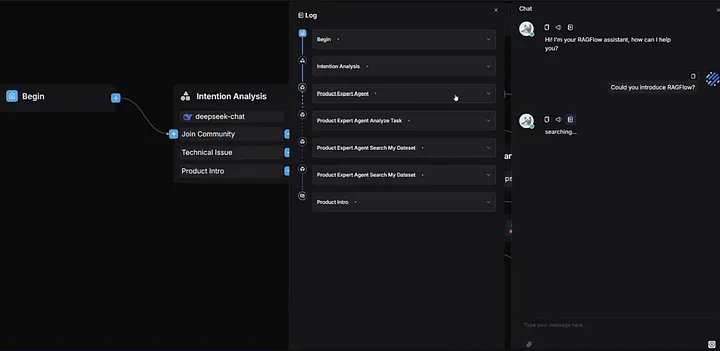
很多 RAG 系统,处理干净文本时都特别像样。
可一旦你把现实里的 PDF 丢进去——有表格、有多栏、有图、有嵌图说明,甚至还是扫描件——它们马上就露怯了。RAGFlow 之所以值得提,就是因为它从一开始,就是拿来对付这种真实世界文档的。
它能正确理解表格,能处理多栏布局,能应对扫描件 OCR,还把这些能力包进了一个可视化 pipeline builder 和 web 界面里。也就是说,你不写代码,也能先把整套链路搭起来试。
如果你手上有一堆法律文档、研究资料、企业内部 PDF,或者任何“看起来像文档,处理起来像灾难”的资料库,那 RAGFlow 才更接近那个真正能用的 RAG 引擎。
它值钱的地方在于:
能处理表格、图示和复杂版式 可视化 pipeline builder,不会写代码也能上手 支持 agentic 多步检索,复杂问题更有用 有 REST API,方便接进自己系统
8. Dataline
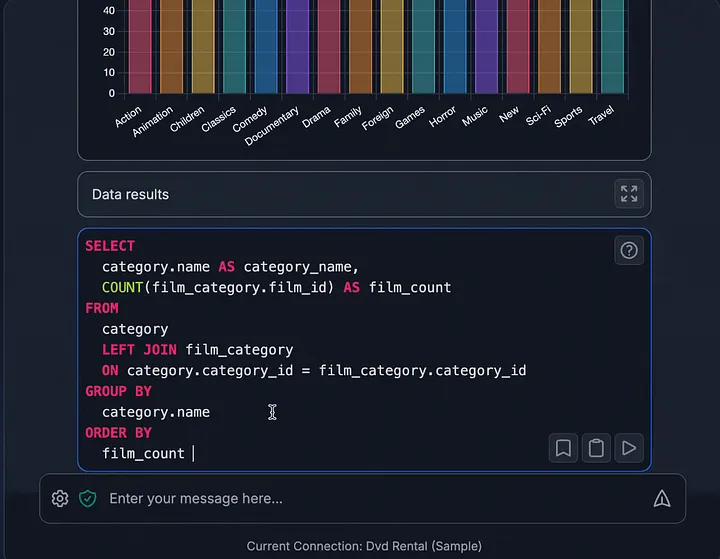
很多非技术岗位每天都需要数据答案。
可现实却经常是:产品经理要等工程写 SQL,运营要等分析师拉表,管理层想看个图也得排队。Dataline 就是在砍这个等待时间。
它允许人直接用自然语言去问数据库问题,然后给你返回图表、表格和答案。它能接 PostgreSQL、MySQL、SQLite 这些常见数据库,用 LLM 把英文问题翻成 SQL,跑完以后再把结果可视化出来。
更重要的是,整个过程可以本地跑。也就是说,你的数据不用出自己的基础设施。
很多公司里,产品、运营、管理者如果真把这种工具用起来,很多“帮我查一下数据”的请求,根本不用再往工程团队那边丢。
它真正适合你的原因也很清楚:
自然语言转 SQL,不会 SQL 也能问 支持主流数据库,直接连现有数据源 本地处理,敏感数据不用外发 返回的是图表和表格,不只是冷冰冰查询结果
四、自动化与 Agent:真正省事的,不是会吹的那种
9. n8n
Zapier 按 task 收费,Make 免费版限制又多。n8n 最大的优点就是:你只要愿意 self-host,它几乎就是白给,而且能力还比很多人印象中更猛。
它本质上是个可视化自动化工作流工具。你把不同服务拖成节点,连起来,就能搭流程。更妙的是,当现成节点满足不了你的逻辑时,你还能直接塞代码块进去,写 JavaScript 或 Python。
而现在让它更有意思的,是 AI 节点。
你可以串 LLM、搭 agent、处理文档、做多步 AI pipeline,而不用自己先搭一套后端基础设施。很多公司已经在拿它替代内部一大块重复工具链了,而且不需要继续为 SaaS 计费。
它让人上头的地方就在这里:
400 多个集成,常用服务基本都有 原生支持 AI agent 节点和 LLM 串联 self-host 后没有使用上限,数据也归自己 节点不够就加代码,灵活度很高
10. Bifrost

很多 AI 产品一开始都只接一个模型提供商。
直到有一天,接口挂了,价格涨了,策略改了,功能下线了,团队才突然意识到:原来自己是把命系在了别人身上。
Bifrost 解决的,就是这种“单一供应商依赖”问题。
它相当于一个网关,挡在你所有 LLM provider 前面,对外只暴露一个 OpenAI-compatible API。你可以通过它去路由 OpenAI、Anthropic、Google、Mistral 等等,还能加缓存、做负载均衡、做自动 fallback。
表面上看,这像是大公司才需要考虑的东西。可实际上,很多团队都是等到真被坑了一次,才知道这东西有多必要。聪明一点的团队,通常会早点接进来。
它最值的一面在这:
一个统一 API 接 15+ LLM 提供商 缓存能直接压低月度 API 花费 自动 fallback,某家挂了也不至于全线瘫 还能做治理控制和请求级追踪
五、音频与转录:能不订阅,就别再订阅了
11. Whisper
Otter.ai 要订阅,Rev 按分钟收费。
而 Whisper 的存在,几乎就是在问一句:那你到底为什么还要继续交这笔钱?
OpenAI 当年把这个语音识别模型开源之后,它很快就成了整个转录生态的底层基石。你可以本地跑它,也可以用免费的 Colab 跑,得到接近人工水准的转录效果,还支持 99 种语言。
如果没有 GPU,也没关系,Whisper.cpp 可以直接把它跑在 CPU 上。也就是说,普通笔记本照样能跑。
如果你经常转采访、会议、播客、课程录音,那这种工具真的会让你重新审视自己对“订阅服务”的依赖。
它的强点没什么虚的:
99 种语言,接近人工水平的识别效果 本地跑就是免费,没有订阅 支持时间戳、翻译输出和字幕导出 Whisper.cpp 没 GPU 也能跑
六、开发者工具:真正提效,不一定非得靠贵插件
12. PR-Agent
代码评审是软件开发里那种人人都知道重要,但人人都时间不够的环节。
PR 一堆堆排着,review 越来越仓促,很多本来认真看一眼就能拦下来的问题,最后还是进了生产环境。PR-Agent 干的,就是把这部分压力先接走一层。
它可以接 GitHub、GitLab、Bitbucket,在每次 pull request 上自动做 LLM review。它不仅会总结 PR 做了什么,还会带着上下文解释潜在问题、建议该补哪些测试、甚至顺手帮你生成 changelog。
而且它不绑死一家模型。Claude、GPT、Gemini,甚至本地 Ollama 模型,它都能接。
对很多团队来说,这类工具不是为了替代人审,而是为了让 review 不再先天就堵住。
它的价值,主要体现在:
自动 review PR,并给自然语言反馈 开箱支持 GitHub、GitLab、Bitbucket 兼容主流闭源模型,也兼容本地 Ollama 能做摘要、测试建议和 changelog 生成
13. Gemini CLI
很多 AI 编码工具都活在 IDE 里。
可一旦你需要在终端里自动化一件事,或者 SSH 到服务器上排障,又或者只是想写个脚本去批处理一堆文件,没有 GUI 的时候,那些 IDE 型工具立刻就不顺手了。
Gemini CLI 值得注意,就是因为它把 AI agent 直接塞进了终端。
一个 npx 命令就能装好。之后,你可以让它解释代码、重构文件、查询系统状态、自动执行一些自然语言任务。它是 Google 做的,开源,而且能嵌进 shell 脚本和 CI/CD 里。
如果你本来就长期生活在终端里,这种工具会特别顺。
它让人愿意试的几个点是:
一个 npx 命令就能装,几乎零配置 多模态,能看代码、文本和图片 可脚本化,很适合进 CI/CD 原生支持 Google Cloud 相关服务集成
七、新兴开源模型:很多人还没意识到,真正能打的已经不是只有 Llama
14. Qwen
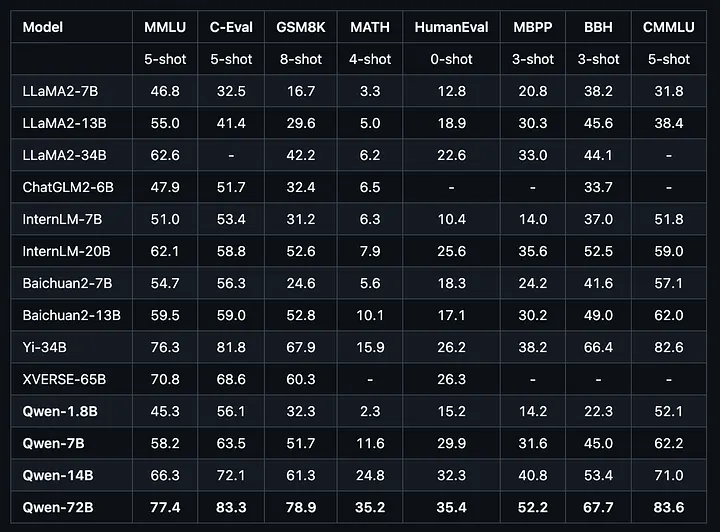
一提本地 AI,很多人的脑子里还是只有 Llama。
可如果你认真看过去两年的开源模型生态,Qwen 根本不该被忽略。
阿里做的 Qwen 系列,覆盖的范围非常广:最小的版本能跑在手机上,最大的版本又能处理文本、图像、音频和代码,而且能力已经逼近很多前沿闭源模型。中间各种尺寸,也都各自针对不同硬件和场景做了优化。
更关键的是,它的许可相对友好,支持商用,也支持 fine-tuning,文档也写得相当完整。
按累计下载数据看,Qwen 在 2025 年已经成了全球最常用的开源模型家族。可讽刺的是,直到今天,很多认真做本地 AI 的人,还是没真正用过它。
它值得你补课的理由,很硬:
尺寸覆盖从 0.5B 到 72B+,各种硬件都能找到对应版本 多模态能力覆盖文本、视觉、音频和代码 2025 年累计下载量层面,它是最热的开源模型家族 许可友好,支持商用和完整 fine-tuning
15. DeepSeek-V3
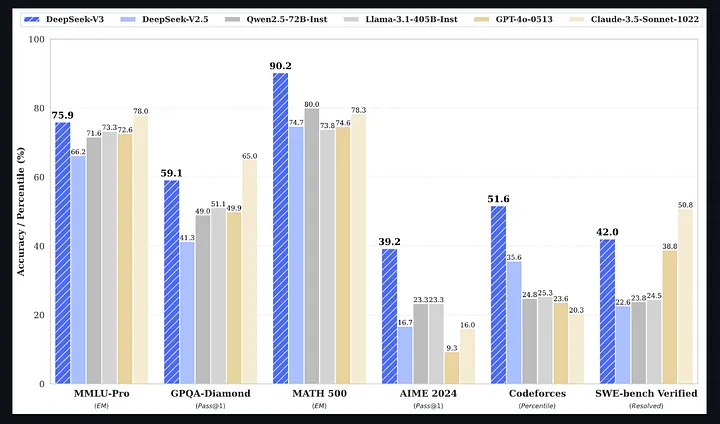
2025 年初,DeepSeek 曾经扔出过一个让整个行业都震了一下的事实:它做出了一个推理能力逼近 GPT 级别的模型,而训练成本却低得离谱。
那不是运气,也不是一次性爆冷。
DeepSeek-V3,正是这条路线进一步推到高点的成果。
它采用的是 744B 参数的 Mixture-of-Experts 架构,但每次推理只激活其中约 40B 参数,所以实际算力成本远没有总参数看起来那么夸张。它支持 128K 上下文,支持原生 function calling,也能处理音频和视频输入。
更重要的是,它还是 MIT 许可证。这意味着,你可以商用、修改、再分发,限制极少。
如果你所在的组织需要的是“接近前沿推理能力,但又不想把命运完全系在云上”,那 DeepSeek-V3 绝对是近几年最值得重视的开源模型之一。
它最值得被认真看待的原因,在于:
推理性能已经摸到顶级闭源模型那一档 MoE 架构让推理成本更可控 128K 上下文,适合长文档和长对话 MIT 许可证,商用和再分发都很自由
最后
别试图一口气把 15 个全装上。
这种时候,最笨的方式,就是因为兴奋一次性全下,然后三天后一个都没真正用起来。更聪明的做法,是从你现在最痛的那个问题入手。
最后:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)