人工智能篇---大模型能力参数
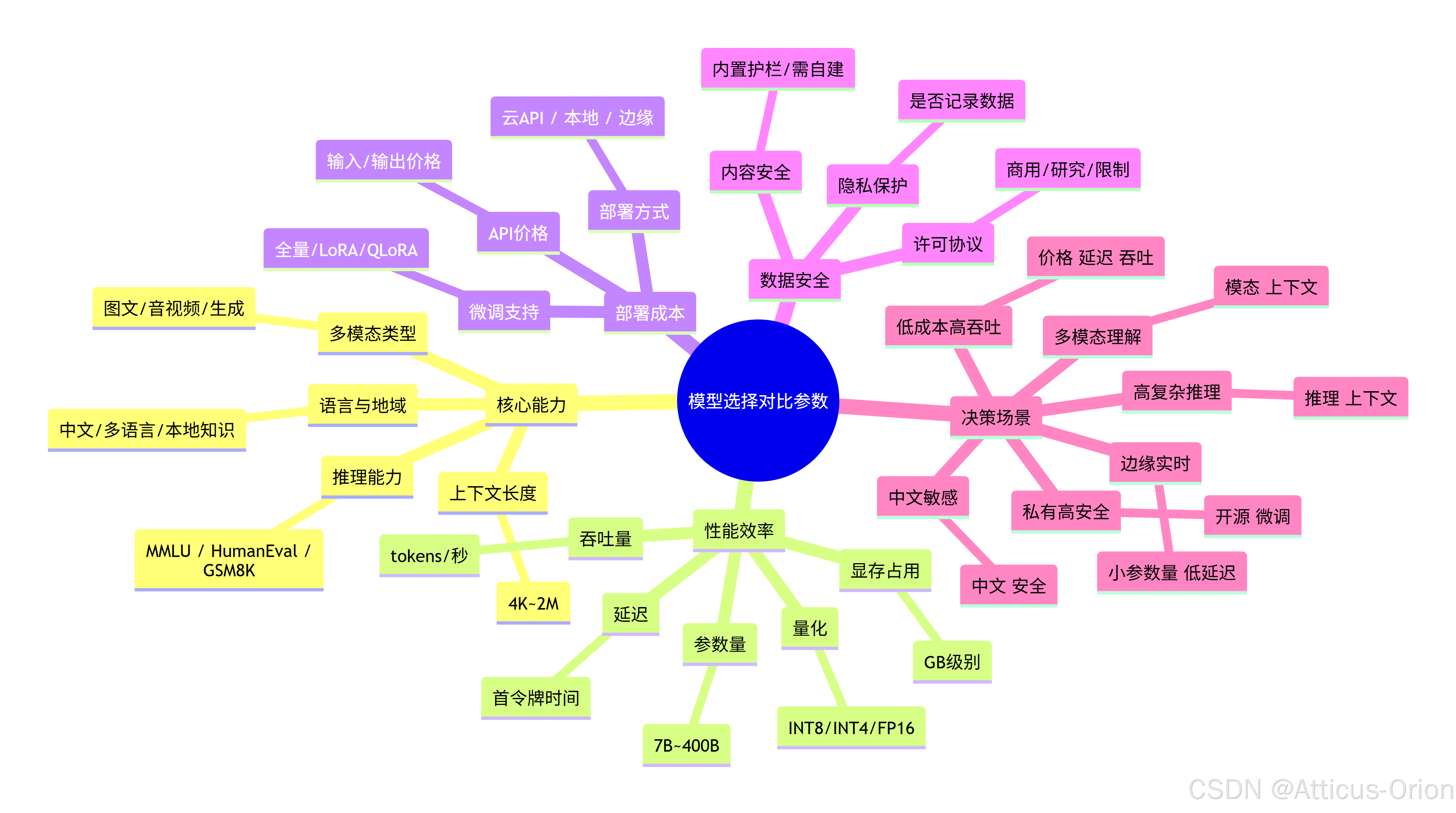
一、核心能力参数
1. 上下文长度(Context Length)
-
含义:模型一次能处理的输入令牌(token)数量。
-
典型值:4K(早期GPT-3.5)→ 128K(GPT-4 Turbo)→ 200K(Claude 3.5)→ 1M~2M(Gemini 1.5、通义千问)。
-
选择影响:长文档分析(财报、法律合同)、多轮对话、超大代码库需长上下文;短问答用8K~32K更省成本。
2. 推理能力(Reasoning)
-
关键指标:数学(GSM8K)、代码(HumanEval)、逻辑推理(MMLU、Big-Bench Hard)。
-
典型表现:GPT-4o MMLU ~88%,Claude 3.5 ~85%,LLaMA 3 70B ~82%。
-
选择影响:复杂任务(科研、金融分析、代码生成)优先选推理强的闭源模型;简单分类或提取可用开源小模型。
3. 多模态能力
-
支持类型:仅文本、图像+文本、音频+文本、视频、生成图像。
-
选择要点:
-
理解场景:图文互查(GPT-4V、Gemini、Qwen-VL)。
-
生成场景:图像生成用SD3/Midjourney;视频生成用Sora/Gen-2。
-
实时交互:GPT-4o(语音+视觉低延迟)。
-
4. 语言与地域适配
-
中文能力:文心、通义、混元、豆包、Qwen 系列表现优于GPT-4(部分中文任务)。
-
多语言:LLaMA 3、Gemini、Claude 覆盖100+语言。
-
选择影响:本地化业务优先本土模型;全球化产品选多语言通用模型。
二、性能与效率参数
| 参数 | 含义 | 对比意义 |
|---|---|---|
| 延迟 (Latency) | 请求到首令牌时间 / 每令牌时间 | 实时对话需 <2s;离线批处理可容忍高延迟 |
| 吞吐量 (Throughput) | 每秒生成令牌数 (tokens/s) | 高并发场景(客服、搜索)需 >50 tokens/s |
| 参数量 (Parameters) | 模型权重数量(B/十亿级) | 大模型通常能力更强但更贵,7B~13B在边缘设备可用 |
| 量化版本 | INT8 / INT4 / FP16 | 降低显存与成本,但可能损失精度 |
| 显存占用 | 推理所需GPU内存(GB) | 影响部署硬件成本(如70B模型需140GB+) |
三、部署与成本参数
1. API 价格
-
输入/输出分别计价(美元/百万tokens):
-
GPT-4 Turbo:输入$10,输出$30
-
Claude 3.5 Sonnet:输入$3,输出$15
-
DeepSeek-V3(开源部署):接近零
-
开源自建:硬件成本+电费+维护
-
2. 推理部署方式
-
云端API:无需管理硬件,适合快速验证、弹性需求。
-
本地/私有云部署:数据安全要求高、高调用量时总体成本更低。
-
边缘设备:Mistral 7B、Phi-3 mini 可跑在手机/笔记本。
3. 微调可行性
-
全量微调(Full Fine-tune):需要大显存(如70B模型需>280GB)。
-
参数高效微调(LoRA、QLoRA):消费级显卡(24GB)可微调70B模型。
-
选择影响:专业领域(医疗、法律)必须可微调;通用场景微调非必需。
四、数据与安全参数
-
数据隐私:闭源模型可能记录请求(需确认隐私政策);开源模型可完全离线。
-
内容安全:闭源模型自带安全对齐(减少有害输出);开源模型需自行加护栏。
-
许可协议:LLaMA 3、Qwen 2.5 允许商用;Falcon 180B 有早期限制;部分中文模型仅限研究。
五、决策矩阵(简易版)
| 场景 | 推荐参数优先级 | 代表模型 |
|---|---|---|
| 低成本大吞吐(客服、搜索) | 价格、延迟、吞吐 | DeepSeek-V3, Mistral 7B |
| 高复杂推理(代码、数学) | 推理能力、上下文长度 | GPT-4o, Claude 3.5, Gemini 1.5 |
| 中文敏感型(政务、营销) | 中文能力、数据安全 | 文心4.0, 通义千问2.5 |
| 私有数据高安全(金融、医疗) | 开源可部署、微调支持 | LLaMA 3, Qwen-72B |
| 多模态理解(文档分析、视频) | 多模态类型、上下文长度 | GPT-4o, Gemini 1.5, CogVLM2 |
| 边缘端实时响应(IoT、移动) | 小参数量、低延迟 | Phi-3-mini, MobileLLaMA |
六、Mermaid 总结框图
七、实用建议
-
先定义典型使用场景和预算(每月调用量、可接受的延迟)。
-
用小流量A/B测试2~3个候选模型,对比关键指标(准确率、首令牌时间、成本)。
-
关注算力扩展性:如果需要长期自建,优先选择支持量化、LoRA的开源模型(如LLaMA 3、Qwen)。
-
不要只看MMLU:在自己业务数据集上做评测,领域内表现可能大相径庭。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)