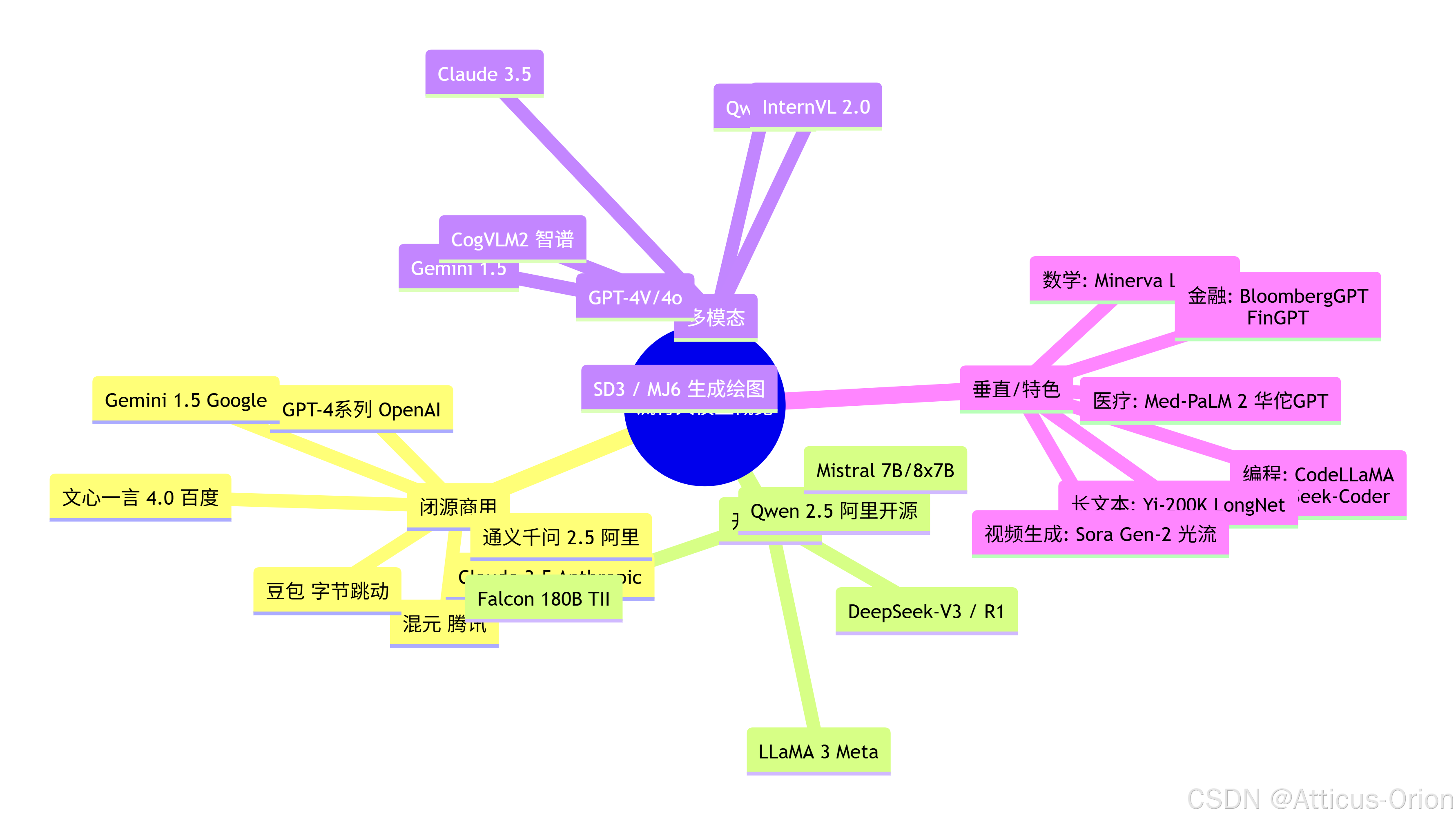
人工智能篇---概览流行大模型
一、闭源商用大模型
-
GPT-4 / GPT-4 Turbo / GPT-4o (OpenAI)
-
特点:强大的通用能力,支持多模态输入(文本、图像、音频),低延迟,高情商交互。
-
应用:ChatGPT、API、Microsoft Copilot。
-
版本:GPT-4o 强调全模态实时对话。
-
-
Claude 3.5 Sonnet (Anthropic)
-
特点:长上下文(200K),强安全和可解释性,擅长代码生成与复杂逻辑。
-
应用:企业级对话、代码助手。
-
-
Gemini 1.5 Pro / Ultra (Google)
-
特点:原生多模态,100万~200万令牌上下文,深度集成Google生态。
-
应用:Bard/Vertex AI,文档分析。
-
-
文心一言 4.0 (百度)
-
特点:中文优化,知识增强与检索增强生成(RAG),多模态生成。
-
应用:百度搜索、办公、营销内容。
-
-
通义千问 2.5 (阿里)
-
特点:长文本(1M),多模态理解,开源与商用双版本。
-
应用:钉钉、电商、金融。
-
-
混元大模型 (腾讯)
-
特点:万亿级参数,混合专家架构(MoE),强广告和游戏场景落地。
-
应用:广告、游戏NPC、企业服务。
-
-
豆包 (字节跳动)
-
特点:轻量高效,对话与创作,集成于抖音、剪映等。
-
应用:短视频文案、图片生成编辑。
-
二、开源通用大模型
-
LLaMA 3 (Meta)
-
特点:8B、70B、400B参数版本,开放商用许可,开源生态核心。
-
衍生:Alpaca、Vicuna、Chinese-LLaMA。
-
-
Qwen 2.5 (阿里开源版)
-
特点:0.5B ~ 72B,多语言,支持工具调用与函数调用。
-
适用:学术、中小企业微调。
-
-
DeepSeek-V3 / R1 (深度求索)
-
特点:MoE架构,高推理能力,成本极低,支持128K上下文。
-
应用:代码生成、数学、RAG。
-
-
Falcon 180B (TII)
-
特点:RAI许可,百亿级开源,性能接近GPT-3.5+。
-
适用:研究与企业私有部署。
-
-
Mistral 7B / 8x7B (Mistral AI)
-
特点:滑动窗口注意力,高吞吐,MoE版本性能强劲。
-
适用:边缘设备与实时推理。
-
三、多模态大模型
-
GPT-4V / GPT-4o – 图像、语音、视频理解
-
Gemini 1.5 – 原生多模态,跨模态检索
-
Claude 3.5 – 支持图像+文本混合输入
-
Qwen-VL – 多语言视觉对话
-
CogVLM2 (智谱) – 视觉与语言深度融合
-
InternVL 2.0 (上海AI Lab) – 开源,性能对标商用
-
Stable Diffusion 3 / Midjourney V6 – 图像生成扩散模型(非大语言模型,但常见于多模态生态)
四、垂直领域或特色模型
-
编程:CodeLLaMA、DeepSeek-Coder、StarCoder 2
-
数学/科学:Minerva、LEMUR(科学推理)
-
金融:BloombergGPT、FinGPT
-
医疗:Med-PaLM 2、华佗GPT
-
中文法律/政务:Fudan DiscLaw、ChatLaw
-
长文本:Yi-200K (01.AI)、LongNet (微软)
-
视频生成:Sora (OpenAI)、Gen-2 (Runway)、光流 (智谱)
五、Mermaid 总结框图
六、趋势小结
-
MoE 架构(Mixture of Experts)成为超大模型主流,如混元、DeepSeek-V3、Mistral 8x7B。
-
长上下文(1M~2M tokens)竞争激烈,Gemini、通义千问、Claude 领先。
-
多模态原生:GPT-4o、Gemini 引领实时混合输入输出。
-
开源与商用并进:LLaMA 3、Qwen 2.5 推动中小企业和学术研究。
-
中文生态:百度、阿里、腾讯、字节、智谱形成完整产品矩阵。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)