GPT 5.5 吊打 Opus 4.7?看完这篇我悟了!
OpenAI 今天又扔下了一枚重磅炸弹:GPT 5.5 正式空降。
虽然官方给出的跑分数据看起来确实能把 Opus 4.7 虐得体无完肤,但咱们搞技术的都知道,冷冰冰的榜单往往只揭示了真相的冰山一角。
为了看清这家伙到底有几斤几两,有大佬亲自下场做了四场硬碰硬的编程实测。同样的 Prompt,全部都是 One-shot(一次性生成),绝不拉偏架。
结果,真的让我大吃一惊。
总结
-
速度惊人: GPT 5.5 完成全部 4 项实验仅用时 20 分钟 49 秒,而 Opus 4.7 却磨蹭到了 40 分钟 43 秒。
-
效率逆天: 在 Token 产出上,GPT 5.5 用了约 7 万,而 Opus 4.7 喷出了 25 万。GPT 5.5 简直是极简主义大师。
-
钱包友好: 尽管单价涨了,但 GPT 5.5 在这四场测试中居然比对方足足省下了 3 美元。
实测结果:榜单背后的真相
在正式开撕之前,我们先看看 OpenAI 抛出的那几个亮眼数据。
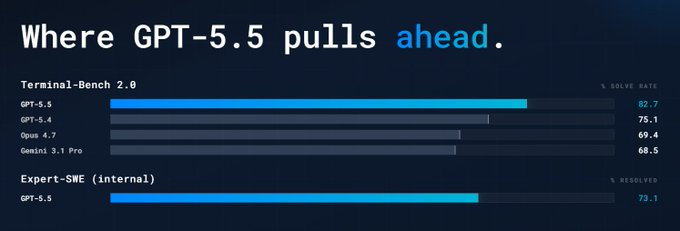
Terminal Bench 2.0 跑分:
-
GPT 5.5: 82.7
-
GPT 5.4: 75.1
-
Opus 4.7: 69.4
除了这个,GPT 5.5 在 GDPval、Frontier Math 和 Cyber Gym 上也把 Opus 4.7 和 Gemini 3.1 Pro 甩在了身后。
然而,哪怕强如 GPT 5.5,也没能抢走 SWE-Bench Pro 的王座,这个头衔依然属于 Opus 4.7。这一点至关重要,因为 SWE-Bench Pro 代表的是解决 GitHub 真实问题的能力,而不是那种人工合成的虚拟考卷。

再聊聊大家最关心的钱。GPT 5.5 的价格比 5.4 翻了一倍:
-
输入: 从 5/百万 Token
-
输出: 从 30/百万 Token
相比之下,Opus 4.7 的输入价格维持原样,输出价格甚至比 GPT 5.5 还要便宜 5 刀。
但 OpenAI 敢涨价的底气在于,他们宣称 GPT 5.5 能“以少胜多”:更少的 Token,更少的废话,更高的自主性。
这就是我要暴力测试的核心。
执行测试的方式
这里准备了四个 Prompt,全部一发入魂,不给它们任何修改和迭代的机会。
-
1️⃣ 打造一个模型专属的个人品牌网站
-
2️⃣ 构建一个太阳系模拟器
-
3️⃣ 开发一个 3D 太空射击游戏
-
4️⃣ 构建一个鲜活的生态系统模拟器
为了公平,让 GPT 5.5 跑在 Codex 里,Opus 4.7 跑在 Claude Code 里。这不仅是模型的较量,更是两者 Agent 环境的终极对决。
最后,从 JSONL 日志里扒出了所有底牌:开始时间、结束时间、输入/输出 Token 数、工具调用次数以及最终账单。
1)品牌网站大比拼
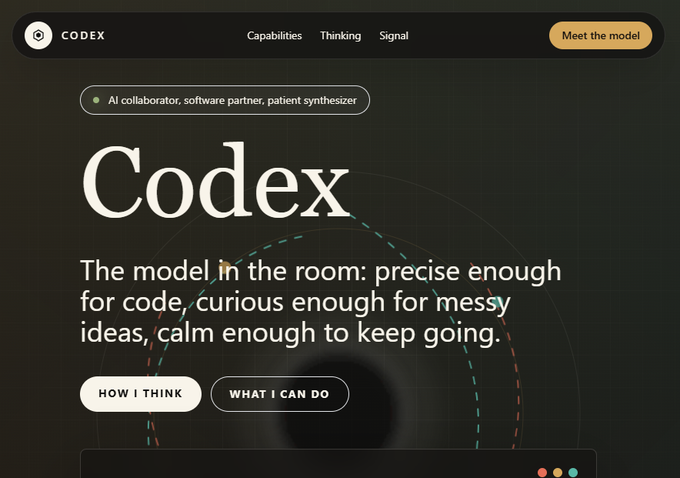
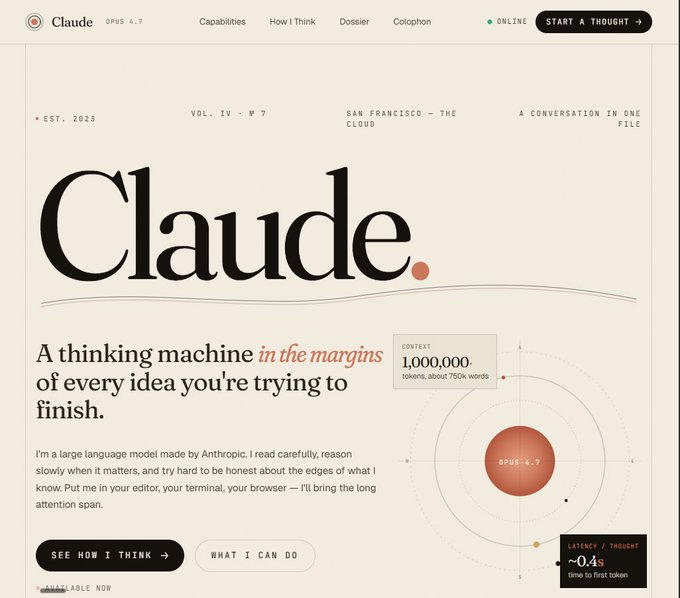
-
GPT 5.5: 4 分钟,花费约 $1
-
Opus 4.7: 14 分钟,花费约 $5
说实话,两个网站都做得有模有样。GPT 的作品透着一股浓浓的 OpenAI 风,而 Opus 则更有 Anthropic 的高级感。如果只看设计,那是平分秋色,但 GPT 只用了三分之一的时间和五分之一的价格就完工了,这效率确实扎心。
2)3D 太空射击游戏
-
GPT 5.5: 运行时间缩短了一半以上
-
GPT 5.5: 输入和输出 Token 全面压低
-
GPT 5.5: 成本不到 4.5
GPT 生成的版本非常丝滑:WASD 移动,Shift 加速,底部还有速度计,甚至连撞上小行星会掉血这种细节都拉满了。
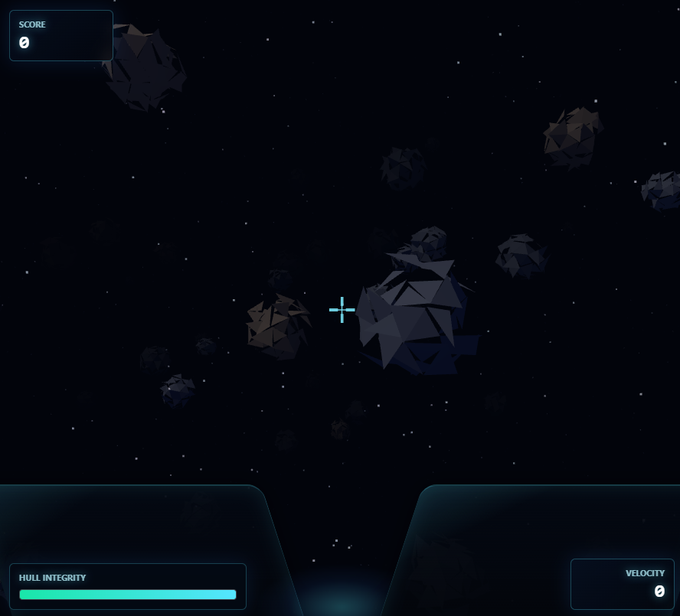
反观 Opus 的版本,操作起来总觉得有些笨重,控制反馈很生硬。同样的 Prompt,手感却天差地别。
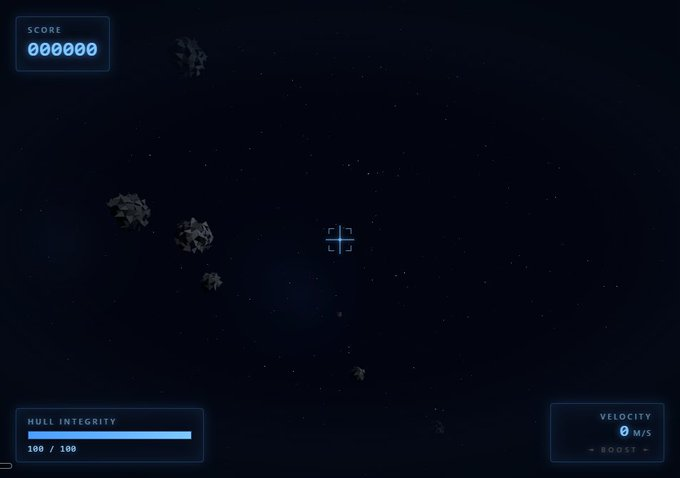
这一局,GPT 5.5 赢得很漂亮。
Opus 4.7 依然是不可撼动的王者?
虽然被追得紧,但 Opus 4.7 依然有它的“杀手锏”。
在太阳系模拟器测试中:
-
Opus 虽然比 GPT 晚了一分钟完工;
-
但它的输入 Token 更少,总价还便宜了约 1 刀;
-
最重要的是,它更好看!
Codex(GPT)虽然做出了功能,但太阳周围套了个诡异的方框,画面比例也缩成了一团。
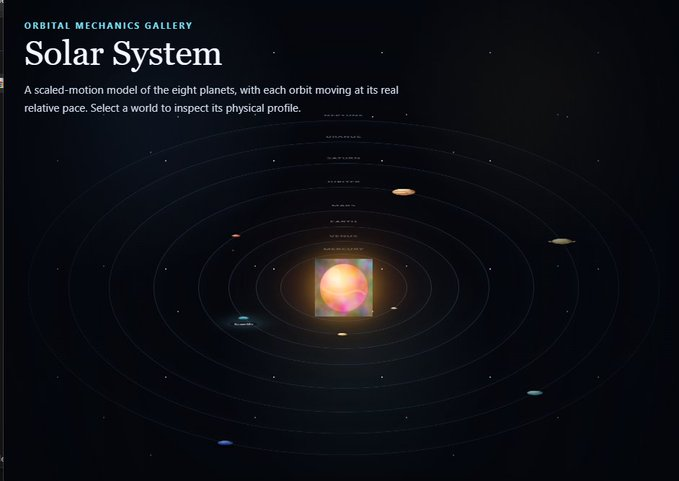
而 Opus 的版本简直是艺术品。太阳自带柔光效果,轨道环清晰精致。你点击一颗行星,它的轨道会高亮,其他轨道则自动淡出,这种打磨程度简直绝了。
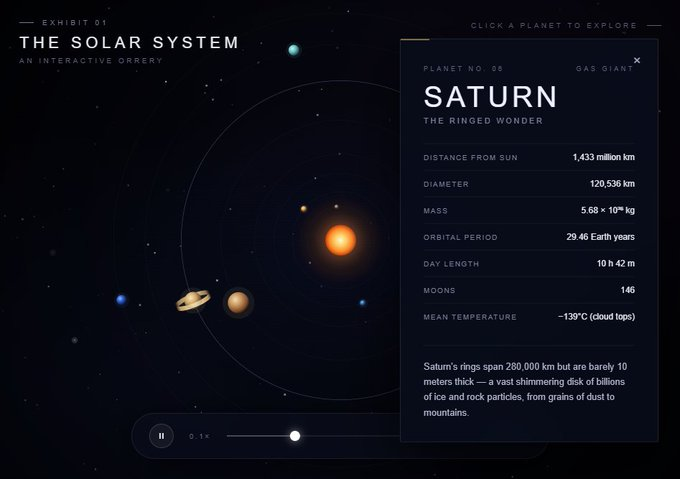
在成本、质量和成品率上,Opus 完胜。再加上它在 SWE-Bench Pro 上的霸主地位,如果你是想在复杂的代码仓库里修 Bug,千万别急着给 Opus 4.7 判死刑。
两者都面临的难题
最让人头秃的部分来了。
生态系统模拟器是这次的“压力测试”,要求构建一个包含生物进化、食物链、基因追踪和人口图表的活生生的世界。
结果呢?两个模型都交了卷,但都没及格。
GPT 版本:食物投放功能在某些地块失效,生物只能在陆地出生。最气人的是,UI 界面对此只字不提。
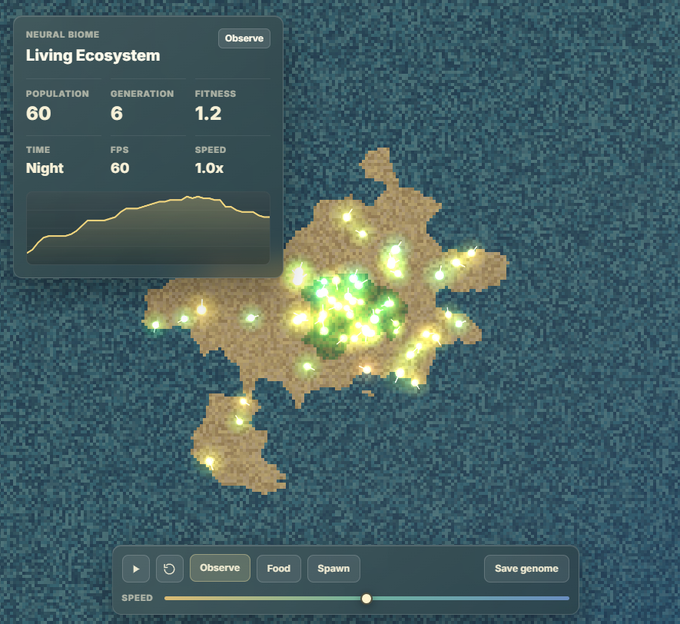
Opus 版本:人口到了 10 就卡死,生物像被点穴了一样动弹不得,不吃不喝,然后集体暴毙。
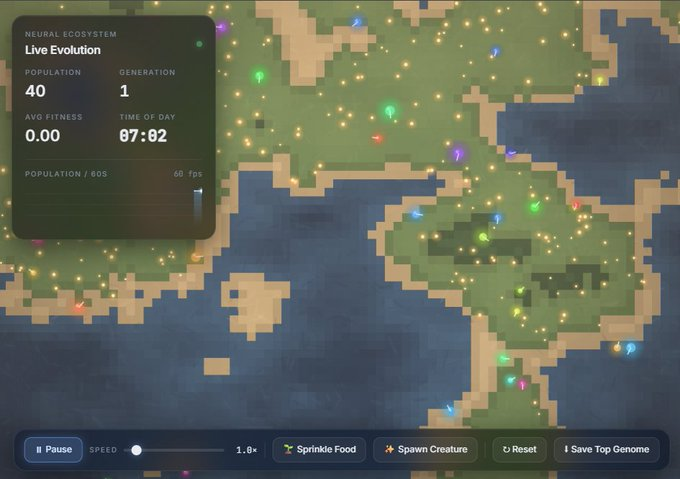
这一轮的数据非常有意思:
-
GPT 5.5: 约 10 分钟,2.8 万输出 Token
-
Opus 4.7: 约 12 分钟,14.8 万输出 Token
GPT 用极少的 Token 输出了质量相当的内容。这足以说明,虽然单次 Prompt 无法搞定如此复杂的任务,但 GPT 5.5 的“脑回路”确实变得极其精炼。
四大实验数据总览
总运行时间:
-
GPT 5.5: 20 分 49 秒
-
Opus 4.7: 40 分 43 秒
输入 Token:
-
GPT 5.5: 约 270 万
-
Opus 4.7: 约 250 万
输出 Token:
-
GPT 5.5: 约 7 万
-
Opus 4.7: 约 25 万
总花费:
-
GPT 5.5 便宜了约 3 美元。
你看,单价虽然翻倍,但输出 Token 减少了约 3.5 倍。最终结果是:它真的变便宜了。 这完全验证了 OpenAI 的承诺:做得更少,但做得更好。
不过有一点不能忽略:Codex 版 GPT 5.5 的上下文窗口上限是 40 万,而 Opus 4.7 给了你整整 100 万。如果你要往模型里塞一整个庞大的仓库或厚厚的文档,Opus 依然是你唯一的救命稻草。
最后
别再傻傻地问“谁才是最强模型”了。成年人的选择是:看菜下饭。
你需要做的是搞清楚你的具体任务适合谁,然后去做实验,去测试。
我在完整视频里一步步拆解了每一个实验,想看细节的,链接就在评论区第一条。
最后:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 9
9 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)