大模型开发实战:微调+决策+本地GPU服务器部署Qwne3-0.6B 实战教程
一、目标
了解大模型开发的三阶段流程(预训练,SFT,对齐)
能根据业务场景判断该用 RAG 还是微调
了解微调方法的全景(全参数 → LoRA → QLoRA)
掌握本教程所需的环境搭建(GPU 服务器 + UV + 模型下载)
二、大模型开发三阶段流程
2.1大模型是怎么训练出来的?
总共分为三个阶段:预训练+专项培训+职业道德
阶段 1:博览群书(预训练 Pre-training)
→ 让模型训练大量语料,从海量文本中学习语言规律、知识和推理能力,形成“基座”。
→ 他变得"什么都知道一点",但不够专业
→ 代表模型:Base Model(基座模型)阶段 2:专项培训(监督微调 SFT, Supervised Fine-Tuning)
→ 学习“对话”格式,理解指令(Instruction),从“懂知识”变成“会聊天”。
→ 他学会了"对话"的格式和风格
→ 代表模型:Instruct Model / Chat Model阶段 3:职业道德(对齐 Alignment)
→ 通过RLHF(人类反馈强化学习)或DPO等方法,让模型变得安全、无害、符合人类价值观。
→ 他变得安全、有用、诚实
→ 代表方法:RLHF、DPO
作者有话说:
阶段2(SFT):除了学“怎么回答”,更关键的是学“听指令”(Instruction Following)。基座模型虽然知识渊博,但如果你问它“写首诗”,它可能只会继续生成关于诗的文章,而不是执行指令。SFT就是教它“用户是老大,用户让干啥就干啥”。
阶段3(Alignment):RLHF和DPO是目前最主流的方法。简单理解就是:让模型学会“揣摩圣意”。给它很多回答,人类(或AI)标注哪个更好,模型就慢慢学会了“讨好”人类的偏好(比如更详细、更安全、更礼貌)。
补充:
这三个训练成本是不同的。
|
阶段 |
数据量 |
训练成本 |
产出 |
|
预训练 |
万亿 token |
数千万美元 |
基座模型(会续写文本) |
|
SFT |
数万~数十万条对话 |
数百~数千美元 |
对话模型(会回答问题) |
|
对齐 |
数万条偏好数据 |
数百~数千美元 |
安全模型(回答得体) |
本教程聚焦 SFT 阶段——也就是"怎么让大模型学会你想要的技能"。预训练太贵(普通人做不了),对齐偏理论(大多数应用场景不需要)。
2.2各阶段的训练细节预训练阶段
1.预训练阶段:
数据:Common Crawl、Wikipedia、Books、GitHub 代码等,总量 ~1-10 万亿 token
损失函数:自回归交叉熵 L = -1/T Σ log P(x_t | x_<t)
训练资源:数千张 A100 GPU,训练数周到数月
代表工作:GPT-3(175B, 3000 亿 token)、LLaMA(65B, 1.4 万亿 token)
预训训练的方式非常简单粗暴——填空题。
原文:北京是中国的____。
模型要做的:猜出这个空格里应该填什么。
正确答案:首都。原文:今天天气真好,我们去公园____吧。
模型要做的:猜出这个空格里应该填什么。
正确答案:散步 / 玩 / 跑步 / 骑车 ……
2.SFT 阶段:
数据:instruction-response 对话对,通常 1 万~10 万条
损失函数:同样的自回归交叉熵,但只对 assistant 的回复计算 loss
训练资源:1-8 张 A100,训练数小时到数天
关键技巧:只对 assistant 回复部分计算 loss,不对 user prompt 计算
SFT 的核心训练数据和预训练完全不同:
预训练的数据长这样(纯文本):
"北京的秋天是一年中最美的季节,银杏叶金黄一片……"
"Python 是一种广泛使用的编程语言,由 Guido van Rossum 创建……"
说明: 没有明确的问题和答案之分,就是一段一段的文章
SFT 的数据长这样(问答对):
{"instruction": "把下面这句话翻译成英文", "output": "The weather is nice today."}
{"instruction": "什么是机器学习?", "output": "机器学习是人工智能的一个分支……"}
说明:有明确的"用户问题"和"助手回答"
3.对齐阶段:
什么是好?什么是坏?
RLHF:需要训练一个奖励模型(RM)→ 用 PPO 强化学习优化
DPO:将 RLHF 简化为分类问题,不需要单独的奖励模型
数据:偏好对(chosen vs rejected),通常 1 万~10 万对
SFT 数据中"只对 assistant 回复计算 loss"的代码示意:
详细训练方法
第一步:让模型对同一个问题生成多个回答
问题:请解释什么是黑洞?
回答 A:黑洞是宇宙中引力极强的天体……(准确、详细、易懂) ← 好
回答 B:黑洞就是一个很黑很黑的洞。 ← 差
回答 C:黑洞是一种甜点,由巧克力制成。 ← 很差
第二步:人类标注员给这些回答打分排序
A > B > C(A 最好,C 最差)
第三步:训练一个"打分器"(奖励模型)
这个打分器学会了"什么样的回答是好回答"
以后不需要人类亲自打分了,打分器自动打分
第四步:用强化学习训练模型
模型生成回答 → 打分器打分 → 分数高就奖励,分数低就惩罚
模型慢慢地就学会了"怎么回答才能得高分"
DPO:哪些回答是好的,哪些是不好的
三、决策:RAG 还是微调?
RAG:外挂一个知识检索库,每一次文档会根据用户的问题在知识库内检索出相关的内容拿来直接用。
你已经有 RAG(外挂一个知识检索库) 经验了。现在的问题是:RAG 解决不了的问题,微调能解决吗?怎么选?
先看一个生活中的类比:
|
场景 |
RAG 方案 |
微调方案 |
|
考试时查资料 |
开卷考试:带着参考书答题 |
闭卷考试:把知识记在脑子里 |
|
外科医生看病 |
每次手术前查手术手册 |
经过专业训练,手术步骤烂熟于心 |
|
客服回答问题 |
从知识库中检索标准答案 |
训练过的客服,直接知道怎么回答 |
RAG 的本质:推理时从外部知识库"抄答案"。
微调的本质:训练时把知识"刻进模型参数"里。
对比总结
|
维度 |
RAG |
微调 |
|
知识更新 |
随时更新文档即可 |
需要重新训练 |
|
输出格式 |
靠 Prompt 控制,不稳定 |
刻进模型,稳定一致 |
|
领域理解 |
依赖检索质量 |
模型内部理解 |
|
响应延迟 |
高(检索 + 生成) |
低(直接生成) |
|
实现成本 |
低(不需要 GPU 训练) |
中(需要 GPU 微调) |
|
数据需求 |
文档即可 |
需要"问答对"格式的标注数据 |
|
可解释性 |
高(能看到检索了哪些文档) |
低(黑盒) |
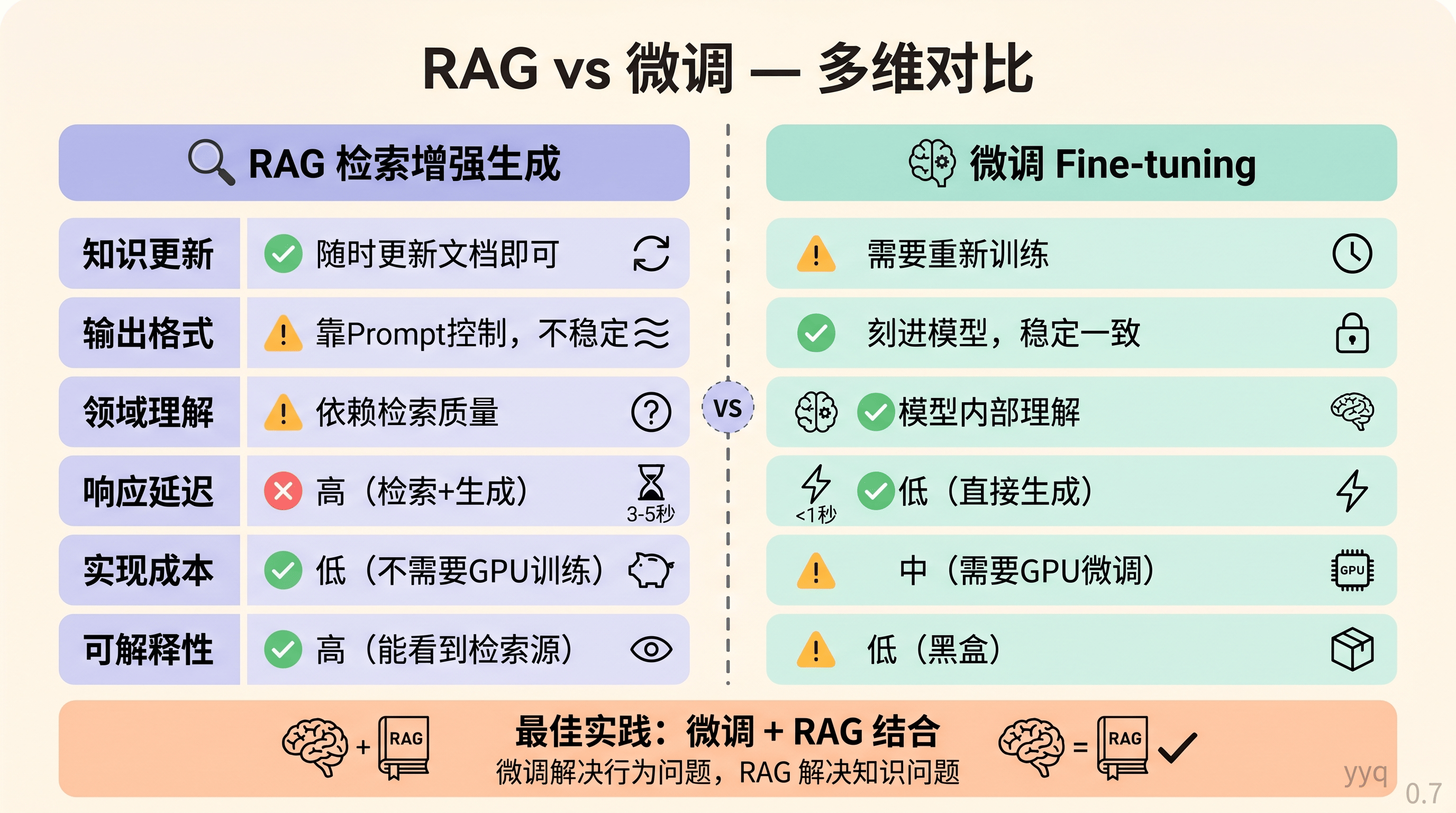
实践建议:不是二选一。很多生产系统是 微调 + RAG 结合——微调解决格式和风格问题,RAG 解决知识时效性问题。
RAG + 微调结合的典型架构
用户输入
│
├─→ 微调后的模型(负责格式、风格、领域理解)
│ │
│ ├─→ 需要外部知识?→ 检索器 → 知识库 → 注入 Prompt
│ │
│ └─→ 不需要外部知识?→ 直接生成
│
└─→ 输出:格式一致、领域准确、知识最新的回答
业界案例:
OpenAI 的 GPT-4:预训练 + RLHF,不使用 RAG(知识全在参数中)
Perplexity:RAG + 微调的结合体
Dify/Coze 等平台:支持微调模型 + RAG 知识库的组合编排
四、微调方法速览
想象你有一本 10000 页的百科全书(基座模型),你想让它变成"医学专家":
|
方法 |
类比 |
改了多少 |
|
全参数微调 |
把整本书重新修订一遍 |
10000 页全改 |
|
LoRA |
在每页贴几张便利贴,写上医学补充笔记(常用) |
~50 页便利贴 |
|
QLoRA |
把原书压缩成袖珍版(省空间),再贴便利贴 |
袖珍版 + ~50 页便利贴 |
|
Prompt Tuning |
只在书的前面加一张"医学指南"卡片 |
1 张卡片 |
本教程的实操选择:QLoRA——因为消费级 GPU 就能跑,效果又足够好。提示词手动改就行。
关键结论:LoRA 成为主流的核心原因是"推理时零开销"——训练完可以将 LoRA 权重合并回原始模型,推理时和全参数微调的模型完全一样快。其他方法(Adapter、Prefix Tuning)在推理时都有额外计算开销。
1.显存计算方法
https://apxml.com/![]() https://apxml.com/
https://apxml.com/
上面这个网站可以根据配置和模型配置计算显存占用。
总显存 ≈ 模型参数显存 + 优化器状态 + 梯度 + 激活值
其中:
模型参数显存=参数量(单位:参数) × 精度(单位:字节)
|
精度类型 |
比特数 (bit) |
换算公式 |
字节数 (Bytes) |
备注 |
|---|---|---|---|---|
|
FP32 |
32 bit |
32 ÷ 8 |
4 Bytes |
单精度浮点数 |
|
FP16 / BF16 |
16 bit |
16 ÷ 8 |
2 Bytes |
半精度浮点数 |
|
INT4 (NF4) |
4 bit |
4 ÷ 8 |
0.5 Bytes |
4比特量化 |
示例:7B 模型,全参数微调(FP16)
模型参数: 7B × 2 = 14 GB
优化器: 7B × 4 × 2 = 56 GB(m 和 v 都是 FP32)
梯度: 7B × 4 = 28 GB
激活值: ~5-10 GB(取决于 batch_size 和 seq_len)
总计: ~103-108 GB → 需要多卡或大量显存优化
示例:7B 模型,QLoRA(4-bit 基座 + BF16 LoRA)
基座模型: 7B × 0.5 = 3.5 GB(NF4 量化)
LoRA 参数: ~0.1% × 7B × 2 = ~14 MB
优化器(仅 LoRA): ~14 MB × 2 × 4 = ~112 MB
梯度(仅 LoRA): ~14 MB × 4 = ~56 MB
分页优化器: 按需加载
总计: ~6-8 GB → 单张 RTX 4090 (24GB) 绰绰有余
优化器状态(推理不需要)(AdamW)=2 × 模型参数显存(一阶动量 m + 二阶动量 v)
AdamW可以理解为一位“有经验的教练”,它不只记录每个参数当前的位置(参数本身),还会记录它的运动趋势,以便更智能地更新。
它需要为每一个可训练参数额外维护两个状态:
一阶动量(m):类似于“速度”,记录梯度方向的历史平均值。
二阶动量(v):类似于“加速度”,记录梯度平方的历史平均值,用于自适应调整每个参数的学习率。
优化器需要为每个可训练参数保存两个状态(一阶动量m和二阶动量v),且它们通常以FP32精度存储。
因此,其显存占用为:可训练参数量 × 4字节/个 × 2个状态 = 可训练参数量 × 8字节。
部署推理则不需要。
梯度(推理不需要):其显存占用为:可训练参数量 × 4字节。
反向传播过程中计算出的、指导每个参数该如何调整的“方向”。
梯度与参数一一对应,且通常也以FP32精度存储以确保数值稳定性。
激活值:前向计算的中间结果。训练时因需保留以供反向传播而占用极高;推理时计算完即释放,占用很低。
2.不同规模模型的显存需求参考
|
模型 |
FP32 全参数 |
FP16 全参数 |
LoRA (FP16) |
QLoRA (4-bit) |
|
0.6B |
2.4 GB |
1.2 GB |
~3 GB |
~2 GB |
|
1.5B |
6 GB |
3 GB |
~5 GB |
~3 GB |
|
7B |
28 GB |
14 GB |
~16 GB |
~6 GB |
|
14B |
56 GB |
28 GB |
~32 GB |
~10 GB |
|
72B |
288 GB |
144 GB |
~160 GB |
~40 GB |
3.技术版图与选型建议
模型选型指南:
|
任务类型 |
推荐模型规模 |
推荐模型 |
理由 |
|
意图识别、文本分类 |
1B-8B |
Qwen3-1.7B/8B |
任务简单,小模型足够 |
|
智能客服 FAQ |
8B-14B |
Qwen3-8B/14B |
需要较好的对话能力 |
|
企业知识库问答 |
8B-14B |
Qwen3-8B + RAG |
知识密集,建议结合 RAG |
|
NL2SQL |
7B-14B |
DeepSeek-Coder-7B |
需要代码理解能力 |
|
JSON/结构化输出 |
1B-8B |
Qwen3-1.7B/8B |
格式控制是小模型的优势场景 |
|
边缘/本地部署 |
0.5B-4B |
Qwen3-0.6B/4B |
资源受限环境 |
|
复杂推理 |
14B-72B |
Qwen3-32B/72B |
需要强推理能力 |
主流开源模型对比(2025-2026):
|
模型 |
参数量 |
训练数据 |
中文能力 |
特色 |
|
Qwen3 |
0.6B-235B |
18T+ token |
极强 |
MoE 架构、思考模式 |
|
DeepSeek-V3 |
671B (37B active) |
14.8T token |
强 |
MoE、长上下文 |
|
LLaMA 3 |
1B-405B |
15T+ token |
中等 |
Meta 出品、生态好 |
|
Mistral |
7B-123B |
— |
较弱 |
GQA、Sliding Window |
|
Yi |
6B-34B |
3T+ token |
强 |
01.AI 出品 |
作者有话说:
MoE(混合专家模型)是一种稀疏激活的模型架构,它通过让不同的“专家”子网络处理不同的输入,实现了用接近小模型的推理成本,获得大模型的知识容量。下面详细解析其原理和与稠密模型的对比,以及带来的影响。
你可以把MoE模型想象成一个专家委员会:
专家:多个独立的前馈神经网络子模块,每个都在训练中擅长处理特定类型的模式或任务。
门控网络:一个“调度员”,根据当前输入的Token,快速决定将其分配给哪几位(通常是Top-2)最相关的专家处理。
稀疏激活:对于每个Token,只激活全体专家中极小的一部分(如2个),其他专家处于“休眠”状态。这是其高效的关键。
以Mixtral 8x7B为例 :
总参数量:8个专家 × 每个7B参数 = 约47B参数。
激活参数量:每次推理只激活2个专家 ≈ 约14B参数参与计算。
效果:它拥有47B量级的“知识库”,但推理时的计算量和速度仅相当于一个14B的稠密模型。
直观对比:MoE vs. 稠密模型
推理(部署)对比
|
维度 |
稠密模型 (如 LLaMA 3 70B) |
MoE模型 (如 Mixtral 8x7B) |
|---|---|---|
|
单次推理计算量 (FLOPs) |
高。与总参数量(70B)成正比,每个Token都需经过所有层和神经元。 |
低。仅与激活参数量(约14B)成正比,路由机制只调用少数专家。 |
|
推理速度 (吞吐量) |
相对较慢。受限于巨大的计算量,生成Token的速度较慢。 |
相对更快。在相同硬件上,由于计算量小,其生成Token的速率(Tokens/s)通常更高,适合高并发场景。 |
|
显存占用 |
相对较低。只需加载一份模型权重(70B)。可通过量化(如GPTQ、AWQ)大幅压缩至20GB以下,从而在消费级显卡上运行。 |
非常高。需要将所有专家(8x7B=56B参数)加载到显存中,尽管每次只使用一部分。量化后仍需约30-40GB显存,通常需要多张卡或专业级大显存卡。 |
|
延迟 |
较为稳定,可预测。 |
可能因动态路由引入轻微波动,但主要瓶颈仍在IO和计算。 |
|
部署成本核心 |
计算成本高(每次推理都算一遍大模型),显存成本低。 |
显存成本极高(必须为所有专家付费),计算成本低。 |
|
典型部署场景 |
端侧部署、对显存敏感的单卡服务、需要极致稳定性的场景。 |
云端服务,追求高吞吐、高并发,且拥有充足显存储备的场景。 |
训练与微调对比
|
维度 |
稠密模型 |
MoE模型 |
|---|---|---|
|
全参数预训练 |
成熟稳定。优化路径清晰,基础设施和算法(如AdamW)高度适配。 |
极其复杂且昂贵。面临专家负载均衡、路由网络训练、通信开销巨大等挑战。需要定制化的损失函数和并行策略,通常只有巨头公司才能承担。 |
|
全参数微调 (PFT) |
可行但昂贵。对于70B模型,需要数百GB显存,通常使用多卡全量微调或ZeRO-3等高级优化。 |
几乎不可行。因为需要同时微调所有专家和路由网络,显存和计算开销是灾难性的,实践中极少采用。 |
|
高效参数微调 (PEFT, 如LoRA) |
黄金标准。非常成熟,将可训练参数量减少到原模型的0.1%-1%,使大模型微调平民化。 |
可行但需适配。主流方法是对路由门控网络和所有专家的FFN层同时添加LoRA适配器。虽然仍需处理大量参数,但显存需求已大幅降低至可接受范围(如从数TB降至单卡百GB级)。 |
|
微调效果 |
稳定可预测。微调能稳定地在特定任务或数据分布上提升性能。 |
风险与机遇并存。微调可能破坏预训练中形成的精密专家分工和路由平衡,导致效果下降。但若微调成功,也能让专家在特定领域更专业化。 |
|
主要挑战 |
算力和显存规模。 |
1. 负载均衡:防止微调后某些专家被“遗忘”或“过载”。 |
4.想自己部署一个glm5.1(744B)显存不足怎么办?
用“专家卸载” 或 “动态加载”
延迟灾难:路由是逐层、逐Token发生的
MoE的“动态路由”不是一次性的。在生成每个Token的每一层(GLM-5.1有80层),都需要做一次路由决策,决定激活哪8个专家。
这意味着,生成一个回答可能需要成千上万次路由决策。如果每次决策后,都需要通过PCIe总线(速度比显存慢100倍以上)从CPU内存加载新的专家权重到显存,累积的延迟将是毁灭性的,推理速度会慢到无法使用。
无法预测,缓存失效
您无法提前预知下一层或下一个Token会用到哪个专家。路由决策依赖于当前层的隐藏状态,是动态计算出来的。
因此,您无法像传统CPU缓存那样做有效的“预加载”。频繁的、无法预测的专家切换会导致持续的缓存未命中,引发大量的数据搬运。
吞吐量瓶颈:PCIe带宽是天花板
即使是最先进的PCIe 5.0 x16,理论带宽约128GB/s。而GLM-5.1的单个专家权重可能高达数GB。
在生成的高吞吐场景下,多路请求同时进行,专家切换的需求会瞬间塞满PCIe通道,使其成为整个系统的唯一瓶颈,GPU强大的算力将完全闲置等待数据。
再次补充(重点)
将庞大的MoE模型知识“蒸馏”到一个更小的稠密模型中,是当前大模型部署和效率优化的核心前沿方向之一,并且在2025-2026年取得了显著的技术突破和实际应用。
技术进展:从“学结果”到“学思维”
传统的知识蒸馏主要让学生模型模仿教师模型的最终输出。而针对MoE的蒸馏,核心挑战和突破在于如何提取其动态、稀疏激活的专家网络中蕴含的丰富“暗知识”。
提取“专家多样性”知识:2025年的关键论文《Every Expert Matters》指出,传统方法忽略了MoE中未被激活的专家(Non-activated Experts) 所蕴含的知识。新的特化蒸馏方案通过多次采样或强制激活策略,让学生模型(小稠密模型)接触到教师模型中不同专家组合对同一问题的多种视角和解决方案,从而学到更全面、更稳健的推理模式。
思维融合蒸馏(MoT):为了解决长思维链(CoT)蒸馏中的误差累积问题,出现了思维融合蒸馏框架。它让多个教师模型(或同一MoE教师的不同专家视角)共同指导学生,通过“共识去噪”原理,提取出所有教师推理逻辑中的“公约数”,从而让学生获得更可靠的逐步推理能力。
与剪枝、架构搜索结合:研究不仅限于蒸馏,还出现了如 MoE-Pruner 等方法,先对MoE模型进行剪枝,再通过专家级知识蒸馏来恢复和保持性能,在50%的稀疏度下能保留99%的原始模型性能。
这项技术已成功应用于顶尖模型的生产流程中:
DeepSeek-V4 的“领域专家拼装”:DeepSeek-V4在后训练阶段采用了创新的蒸馏思路。它先分别预训练出数学、编程、Agent(智能体)三个强大的“领域专家”模型,然后使用 on-policy 蒸馏技术,将这三个专家的核心能力和知识“提炼”出来,融合灌入一个统一的、参数量更易管理的学生模型中。这实现了从“多个专才”到“一个通才”的高效知识转移。
推动“小模型”能力飞跃:正是得益于MoE蒸馏等技术的进步,2025年底出现的Gemini 3 Flash 等模型,让人们直观感受到了小模型能力的突飞猛进。行业观点认为,蒸馏可能让我们未来不必再为获得强大能力而牺牲推理速度。
轻量化多模态模型:如阿里的 LLaVA-MoD 框架,通过将MoE架构与知识蒸馏结合,仅用0.3%的数据和23%的可训练参数,就让一个20亿参数的学生模型在综合性能上超越了70亿参数的教师模型。
5.论文索引
LoRA: "LoRA: Low-Rank Adaptation of Large Language Models" (Hu et al., 2022)
QLoRA: "QLoRA: Efficient Finetuning of Quantized Language Models" (Dettmers et al., 2023)
DPO: "Direct Preference Optimization: Your Language Model is Secretly a Reward Model" (Rafailov et al., 2023)
RLHF: "Training language models to follow instructions with human feedback" (Ouyang et al., 2022)
Flash Attention: "FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness" (Dao et al., 2022)
PagedAttention: "Efficient Memory Management for Large Language Model Serving with PagedAttention" (Kwon et al., 2023)
五、环境搭建
Step 1:准备一台 GPU 服务器
Step 2:安装 UV 包管理器
UV 是一个超快的 Python 包管理器,比 pip 快 10-100 倍。本教程用 UV 管理所有 Python 依赖。
# 安装 UV
curl -LsSf https://astral.sh/uv/install.sh | sh
# 重新加载 shell 配置
source ~/.bashrc
# 验证安装
uv --version
# 预期输出:uv x.x.x
效果:
![]()
作者有话说:
为什么不用 pip/conda? UV 用 Rust 写的,速度极快,还有虚拟环境管理功能,一个工具搞定环境隔离和依赖安装。
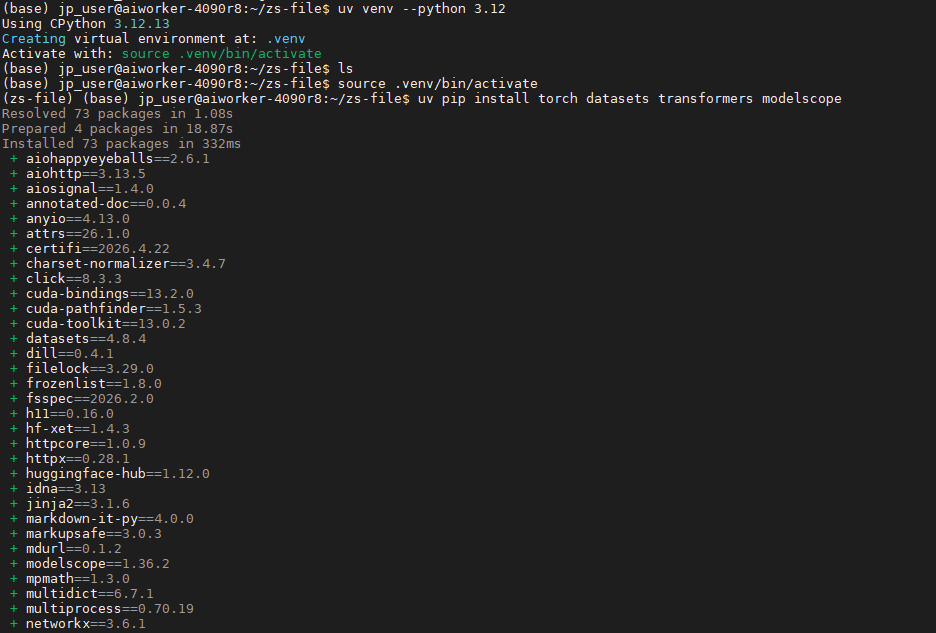
Step 3:创建项目环境
# 创建项目目录
mkdir ~/sft-tutorial && cd ~/sft-tutorial
# 创建 Python 虚拟环境
uv venv --python 3.12
# 激活虚拟环境
source .venv/bin/activate
# 安装基础依赖
uv pip install torch datasets transformers modelscope
效果:
验证安装:
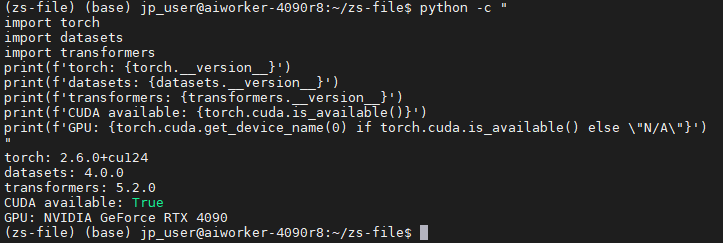
python -c "
import torch
import datasets
import transformers
print(f'torch: {torch.__version__}')
print(f'datasets: {datasets.__version__}')
print(f'transformers: {transformers.__version__}')
print(f'CUDA available: {torch.cuda.is_available()}')
print(f'GPU: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else \"N/A\"}')
"
效果:
Step 4:下载模型
本教程使用 Qwen3-0.6B 作为实操模型。选择它的原因:
只有 0.6B 参数,任何 GPU 都能跑
阿里出品,中文能力强
足够小,训练和推理都快,适合教学
# 下载模型(从 ModelScope,国内速度快)
uv pip install modelscope
python -c "
from modelscope import snapshot_download
snapshot_download(
'Qwen/Qwen3-0.6B',
local_dir='~/sft-tutorial/model/Qwen3-0.6B'
)
print('模型下载完成!')
"
效果:
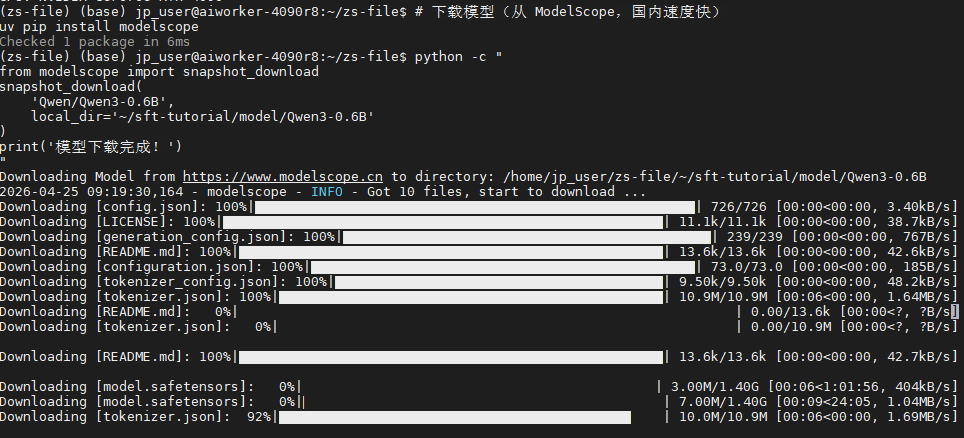
等待下载完成。
验证下载:
# 查看模型文件
ls ~/sft-tutorial/model/Qwen3-0.6B/
# 预期输出:
# config.json model-00001-of-00002.safetensors model-00002-of-00002.safetensors
# tokenizer.json tokenizer_config.json ...
# 查看模型大小
du -sh ~/sft-tutorial/model/Qwen3-0.6B/
# 预期输出:~1.2G(FP32)/ ~600M(FP16)
效果:
![]()
![]()
Step 5:快速体验模型
下载完成后,用几行代码让模型说句话,感受一下"基座模型"的效果:
# save as ~/sft-tutorial/test_model.py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "/data/yyq/models/Qwen3-0.6B/"
model = AutoModelForCausalLM.from_pretrained(
#"~/sft-tutorial/model/Qwen3-0.6B",
model_path,
torch_dtype="auto",
device_map="cuda:5"
#device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
messages = [
{"role": "user", "content": "你好,请介绍一下你自己"}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))效果:
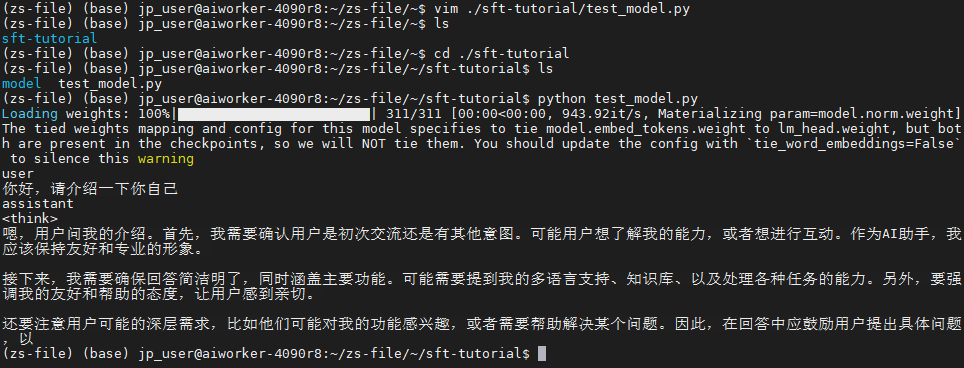
上方出现了两个问题:
第一个问题:
警告信息:The tied weights mapping and config ... to silence this warning
原因:这是模型配置与权重文件不一致的提示。有些模型为了节省参数,会让词嵌入层(
embed_tokens)和语言模型头部(lm_head)共享权重。你的检查点文件里这两个权重都存在,但配置却说要共享,所以HuggingFace加载器就选择不共享并给出了警告。
影响:这个警告是良性的,不会导致输出截断。你可以按照提示在模型配置中设置
tie_word_embeddings=False来消除它。
第二个问题:
输出被截断:模型在生成“思考过程”(
嗯,用户问我的介绍...),而不是直接回答,并且在“以”字处突然停止。
可能性1:生成长度限制(最大)
# 可能在你的test_model.py中,生成参数设置类似: output = model.generate( input_ids, max_new_tokens=50, # 或 max_length=100 # ... )
可能性2:内存/显存不足(即使在CPU服务器)
CPU服务器有系统内存(RAM)限制。
当生成较长文本时,如果内存不足,进程可能被系统终止(OOM Killer)。
检查方法:运行后看是否有
Killed或MemoryError提示。
经过检查,发现是最大输出长度太小,做修改之后的效果。(无报错,无截断)
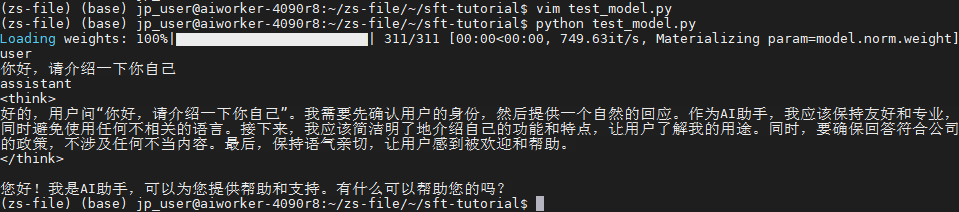
总结:
要想加载一个模型进行本地部署需要做的。
1.一台拥有做够支撑模型推理的gpu服务器。
2.需要安装python解释器。
3.创建python虚拟环境并激活。
4.服务器需要安装uv,在通过uv在这个python包管理器去在虚拟环境里下载依赖包。
5.模型运行环境搭建好之后就需要下载模型。
6.下载好之后就可以通过python几行代码让模型说句话,感受一下"基座模型"的效果。
六、常见问题
Q1:没有 GPU 怎么办?
找云服务,便宜的(1-3 元/小时)。如果完全不想花钱,可以用 Google Colab 的免费 GPU(但网络可能不稳定,下载模型慢)。
Q2:为什么选 Qwen3-0.6B 这么小的模型?
教学用。0.6B 参数意味着:
任何 GPU(甚至 CPU)都能跑
训练一次只要几分钟
方便快速实验不同参数
实际工作中你会用更大的模型(7B、14B、72B),但原理完全一样。
Q3:UV 和 pip 有什么区别?一定要用 UV 吗?
不是必须的,pip 也能完成所有操作。UV 的优势是速度快(安装依赖从分钟级降到秒级)和内置虚拟环境管理。如果你更熟悉 conda,用 conda 也完全没问题。
Q4:模型下载太慢怎么办?
使用 ModelScope(国内源)而非 HuggingFace
减小模型规模(比如用 0.3B 的模型)
Q5:微调和 Prompt 工程是什么关系?
解决复杂度的阶梯(从轻到重):
1. Prompt 工程(成本最低)
→ 优化输入指令,让模型更好理解你的需求
→ 适合:简单任务、快速验证想法
2. RAG(中等成本)
→ 检索外部知识辅助回答
→ 适合:知识密集型任务、知识需要实时更新
3. 微调(较高成本)
→ 用标注数据训练模型
→ 适合:需要稳定格式、领域深度理解、低延迟
它们不是互相替代的关系,而是不同复杂度级别的解决方案。从最简单的开始尝试,不够用再升级。
小结
本章回顾
|
模块 |
核心收获 |
|
大模型三阶段 |
预训练(通才)→ SFT(专家)→ 对齐(职业道德),本教程聚焦 SFT |
|
RAG vs 微调 |
RAG 解决"知识问题",微调解决"行为问题",生产中常结合使用 |
|
微调方法谱系 |
全参数 → LoRA → QLoRA,参数量和显存需求递减 |
|
环境搭建 |
UV + Qwen3-0.6B,基础环境已就绪 |
下一章预告
Ch1:模型架构速通——打开 Transformer 的黑盒,看看里面到底有什么。我们会用生活类比理解注意力机制、位置编码等核心概念,搞清楚"微调到底在调什么"。
先思考:一个 7B(70 亿参数)的模型,参数都存在哪?训练时需要多大显存?带着这个问题进入下一章。
Q1:"微调和继续预训练(CPT)有什么区别?"
回答要点:
继续预训练(CPT)喂的是大量无标注文本,目标是"学习更多知识"
SFT 喂的是"指令-回答"对,目标是"学会怎么回答问题"
类比:CPT 是"多读书",SFT 是"上培训班学技能"
实际中常先 CPT 再 SFT(如 LLaMA 2 的两阶段训练)
Q2:"7B 模型要多少显存?我的笔记本能跑吗?"
回答要点:
推理:7B FP16 约 14GB,INT4 量化后约 4GB。有 8GB 显存的笔记本勉强能跑
训练(QLoRA):约 6-8GB,RTX 3060/4060 (8GB) 可能不够,RTX 4090 (24GB) 绰绰有余
给出上面的显存计算公式
Q3:"微调和 RAG 能同时用吗?"
回答要点:
完全可以,而且是业界主流做法
微调负责"行为"(格式、风格、领域理解),RAG 负责"知识"(实时信息)
举例:企业客服 = 微调后的模型 + 产品文档 RAG
Q4:"为什么不用全参数微调?效果不是更好吗?"
回答要点:
效果确实最好,但成本太高:7B 全参数微调需要 ~100GB 显存(多卡)
LoRA 只需 ~16GB,效果达到全参数的 95-99%
性价比上 LoRA 是大多数场景的最优选择
什么时候用全参数:数据量极大(>100万条)、效果要求极致、有充足算力
Q5:"LoRA 训练出来的'便利贴',会不会和原书内容冲突?"
回答要点:
会,这就是"灾难性遗忘"问题——学新知识忘了旧知识
但实践中 LoRA 影响较小,因为参数量只占 0.1-1%
如果遗忘严重:减少训练轮数、降低学习率、增加混合数据(原领域 + 新领域)
Q6:"0.6B 模型微调有意义吗?这么小的模型能学会东西吗?"
回答要点:
教学用,目的是学会流程和原理
实际效果:简单任务(格式转换、关键词抽取)0.6B 完全够用
复杂任务(多轮对话、推理)需要 7B+
建议学生先在 0.6B 上学会流程,再迁移到 7B/14B
Q7:"SFT 数据要多少条才够?"
回答要点:
简单任务(格式转换、分类):100-1000 条可能就够
中等任务(单轮问答、摘要):1000-10000 条
复杂任务(多轮对话、推理):10000-100000 条
关键是数据质量 > 数据数量。500 条高质量数据 > 5000 条噪声数据
参考:LoRA 论文中 50k 条数据就达到了接近全参数的效果
Q8:"RLHF 和 DPO 到底选哪个?"
回答要点:
DPO 更简单(一步到位,不需要训练奖励模型)
DPO 效果在大多数场景接近 RLHF
RLHF 效果上限更高,但流程复杂、成本高
实践建议:先用 DPO,效果不够再试 RLHF
本教程主要讲 SFT,对齐方法只做了解
Q10:"为什么不教预训练?"
回答要点:
预训练成本极高(百万美元级别),普通人/中小企业做不了
预训练是头部大厂(OpenAI、Google、Meta、阿里)的游戏
SFT 才是大多数工程师的日常工作:用少量数据让模型适配具体任务
如果对预训练感兴趣,可以了解 LLaMA 的开源训练方案(需要千卡集群)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)