【技术底稿 24】Ollama + GPU 踩坑最终篇:从 CPU 硬扛到 GPU 加速,长文本向量化通关实录
昨天:下午 5 点到晚上 10 点半,5 个半小时,代码一行没改,全是环境的坑。
今天:换模型、开 GPU,长文本向量化从 “超时报错” 到 “几秒返回”。这篇是昨天的收尾,也是今天的答案。
一、前言
昨天那篇《Ollama + Docker + Ubuntu 部署踩坑实录》停在了 “网络通了,参数还在调”。
今天,我把 “调” 的结果亲手验证出来了。
本文记录从 CPU 硬扛到 GPU 加速的完整过程,以及长文本向量化的最终解决方案。不绕弯子,只给结论、数据和可复用的经验。
二、昨天的问题,今天的答案
表格
| 问题 | 昨天状态 | 今天方案 | 结果 |
|---|---|---|---|
| 向量模型超限 | nomic-embed-text 报错 input length exceeds context length(上限 2048) | 换 qwen3-embedding:0.6b(32K 上下文) | ✅ 长文本不再报错 |
| Ollama 纯 CPU 运行 | 显卡闲置,CPU 拉满,推理超时 | 重装 GPU 版 Ollama(Docker Compose + nvidia-container-toolkit) | ✅ GPU 显存占用 1.26GB |
| 长文本处理 | 超时 / 500 错误 | 模型 + GPU 双升级 | ✅ 3597 字符,3-5 秒返回 |
三、关键验证数据
测试环境:
- 操作系统:Ubuntu 22.04
- 显卡:NVIDIA GeForce MX150(2GB 显存)
- Ollama 部署方式:Docker Compose 声明 GPU 资源(等价
--gpus all) - 模型:qwen3-embedding:0.6b
测试结果:
表格
| 指标 | 数据 |
|---|---|
| 输入文本长度 | 3597 字符 |
| 输出向量维度 | 1024 维 |
| GPU 显存占用 | 1264 MiB |
| 处理时间 | 约 3-5 秒 |
| 状态 | 成功,无报错 |
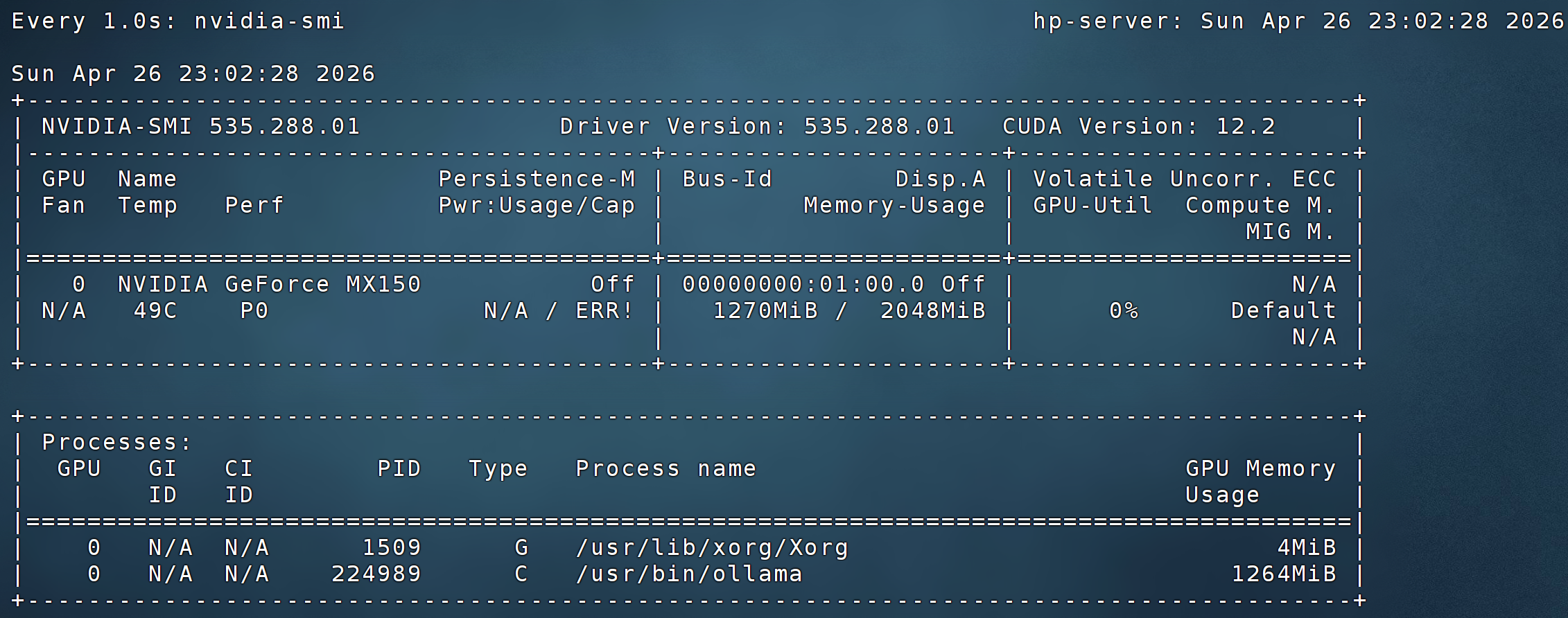
nvidia-smi 截图关键信息:
text
GPU-Util: 0%
Memory-Usage: 1270MiB / 2048MiB
Processes: /usr/bin/ollama 1264MiB
显存占用从 0 飙升到 1.26GB,Ollama 进程清晰可见 —— 这是 GPU 在工作的铁证,不是 “感觉快了”。
四、经验总结(不废话版)
1. 向量模型要按场景选
表格
| 模型 | 上下文 | 向量维度 | 适合场景 |
|---|---|---|---|
| nomic-embed-text | 2048 | 768 | 短文本、快速验证 |
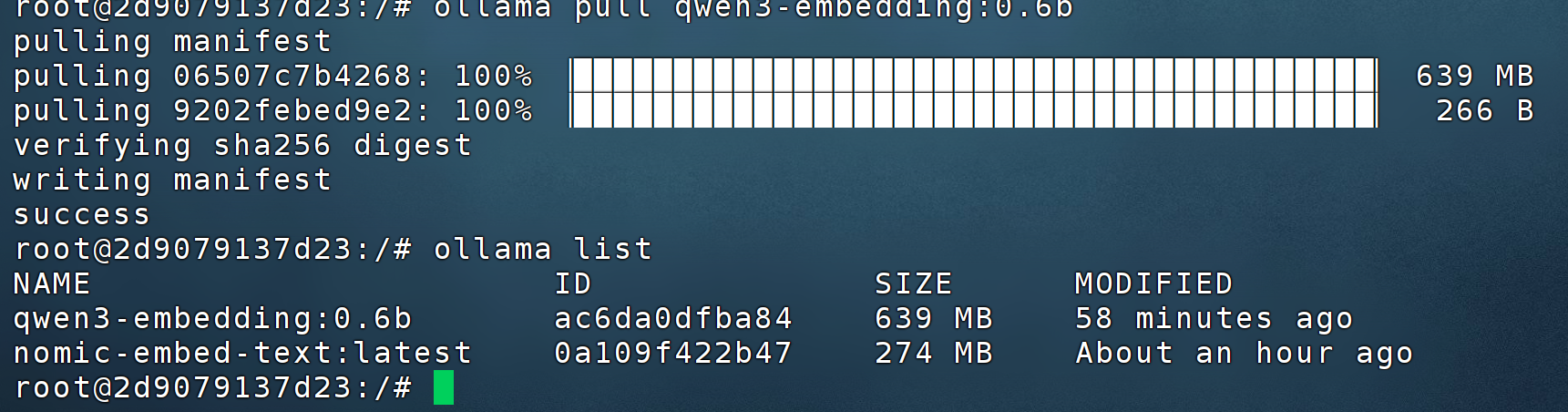
| qwen3-embedding:0.6b | 32768 | 1024 | 长文章、RAG 知识库入库 |
你爬一篇 CSDN 长文,nomic 会直接报错,换 qwen3 就丝滑入库。选型定生死。
qwen3-embedding:0.6b 对中文支持更友好,显存占用控制得很好,2G 显存也能跑起来。
2. Ollama 的 GPU 支持,Docker 是最稳的路径
之前手动下载的 ollama-linux-amd64.tar.zst 是纯 CPU 版本,本身就不包含 NVIDIA GPU 支持,所以无论怎么装驱动、改配置,它都永远只会用 CPU 跑。这是最隐蔽的 “先天缺陷”。
GPU 加速 → Docker Compose 部署 Ollama + 声明 nvidia GPU 资源(等价 --gpus all)
直接用 ollama/ollama Docker 镜像,配合 Compose 的 GPU 声明,一次到位,再也不用手动配 OLLAMA_HOST、num_ctx、OLLAMA_CONTEXT_LENGTH 这些参数。
完整 docker-compose.yml 片段:
bash
运行
version: '3.5'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: always
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu] # Docker Compose 声明 GPU 资源(等价 --gpus all)
networks:
- milvus_network
volumes:
ollama_data:3. 避坑提醒:nvidia-container-toolkit 是必须的前置依赖
要让 Docker 容器能调用 GPU,宿主机必须提前安装 nvidia-container-toolkit,否则容器启动会报错,无法调用 GPU。
4. nvidia-smi 是唯一不会骗人的验证方式
“感觉快了” 可能是错觉,显存占用 > 0,才是真正的 GPU 加速。今天实测:1270MiB,铁证如山。
5. 技术问题的终点不是 “感觉快了”,是 “看到数据了”
昨天:5 个半小时,代码一行没改,全是环境的坑今天:1 小时,模型一换,GPU 一开,通关
五、最终结论
昨天的坑,一个都没白踩。今天这条路,你可以直接复用:
- 长文本向量化 → 用
qwen3-embedding:0.6b - GPU 加速 → Docker 部署 Ollama +
--gpus all - 验证 →
nvidia-smi看显存占用
六、最后
昨天折腾 5 个半小时,今天通关 1 小时。没有白踩的坑,也没有白写的代码。
文章会过时,但显卡不会白买。 👊
📚 系列导航:
【技术底稿】01:37岁老码农,用4台机器搭了套个人DevOps平台
【产品底稿01】37 岁 Java 老码农,用 Java 搭了个 AI 写作助手,把自己 14 年技术文章全喂给了 AI!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)