AI我知道:AI 为什么会出错?注意力机制、幻觉与推理模型
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
作者: 丁闪闪 (连享会)
邮箱: lianxhcn@163.com
系列说明:本文是「AI我知道」系列推文的第二篇,面向经管、金融、社会学领域的研究者和学生。我们的目标不是把你训练成 AI 工程师,而是帮你建立足够扎实的概念框架,让你能更聪明地使用这些工具,并在研究和工作中做出有依据的判断。
- Title: AI我知道:AI 为什么会出错?注意力机制、幻觉与推理模型
- Keywords: 大语言模型, 注意力机制, 幻觉, 推理模型, Transformer, ChatGPT, Claude
你有没有遇到过这种困惑?
使用大模型一段时间后,很多人都会碰到一个很别扭的现象:它有时像一位相当能干的助研,几分钟就能帮你梳理出文献框架、生成代码草稿,甚至指出一段论证的漏洞;可有时它又会一本正经地胡说八道,把并不存在的论文、错误的定义,或者似是而非的解释说得非常流畅。更麻烦的是,这种错误往往不是“乱答一气”,而是“看起来很像对的”。这种现象通常被称为「AI 幻觉」,使我们使用 AI 过程中必须警觉,且需要人工介入审查的重要环节。
这也是很多老师和同学真正开始警惕 AI 的时刻:为什么它会这样?是模型太笨,还是我们对它的期待放错了地方?
这一篇想回答的,就是这个问题。对普通用户来说,理解 AI 为什么会出错,至少要先抓住三个概念:注意力机制(Attention)、幻觉(Hallucination) 和 推理模型(Reasoning model)。它们分别对应三层问题:模型是如何在大量信息中“看重点”的;为什么它会把“看起来合理”错当成“真的正确”;以及为什么有些模型更擅长处理复杂、多步、带歧义的问题。
1. 注意力机制:模型不是“通读全文”,而是在工作台上打聚光灯
1.1 什么是 Attention?
很多人第一次接触「注意力机制」这个词,会觉得它特别技术化。其实,直觉并不难理解。可以把它想象成:当模型面对一段文字时,它不会像人那样逐句默读,也不会平均用力地 “看完所有部分”,而是会根据当前任务,把更多 “注意力” 分配给某些位置,把较少注意力分配给另一些位置。
如果沿用上一篇「工作台」的比喻,那么注意力机制就有点像工作台上的一盏聚光灯。桌面上摆着题目、摘要、变量定义、注释、前文聊天记录和你的当前问题。模型在生成下一个词时,会反复判断:此刻到底应该多看哪几处,少看哪几处。也就是说,它不是“有没有看到”,而是“看得多不多、权重高不高”。
这件事之所以重要,是因为它直接解释了一个常见现象:同样一批材料,摆放方式不同、提示方式不同,模型的回答会明显不一样。 你把关键信息放在前面,或者明确告诉模型「请重点比较识别策略与变量构造」,它的注意力分配往往就会更集中;相反,如果信息很多、层次很乱、问题又写得很模糊,模型虽然 “都看到了”,但未必能把真正重要的部分稳定抓出来。
从发展历程看,注意力机制之所以重要,也是因为 2017 年的 Transformer 架构几乎就是围绕它展开的。那篇非常有名的论文《Attention Is All You Need》提出:在很多序列任务中,模型可以主要依赖 attention,而不必像更早的模型那样严重依赖循环结构。这一思路后来成了大语言模型的主干路线之一。
1.2 注意力机制为什么不能等同于“理解”?
但这里有一个非常容易混淆的点:注意力不等于理解,能分配权重不等于真懂。
举个例子。假设你把一篇论文交给模型,并要求它解释作者的识别策略。模型很可能会把较高权重放在 “identification strategy”、“endogeneity”、“instrumental variable”、“difference-in-differences” 这些相关片段上,这说明它知道哪些地方可能重要。但这并不自动意味着:它已经真正理解了作者为什么这样设定、这些设定是否站得住、识别条件是否合理。
换句话说,注意力机制更像是「在信息海洋中选重点」的能力,而不是「对重点进行真伪判定」的能力。后者还会受到训练目标、上下文质量、提示方式、任务难度,以及模型本身推理能力的影响。
这也是为什么,我们在科研场景中不能把“模型提到了关键词”误以为“模型已经掌握了问题”。它也许只是抓住了最像答案的那几块内容。
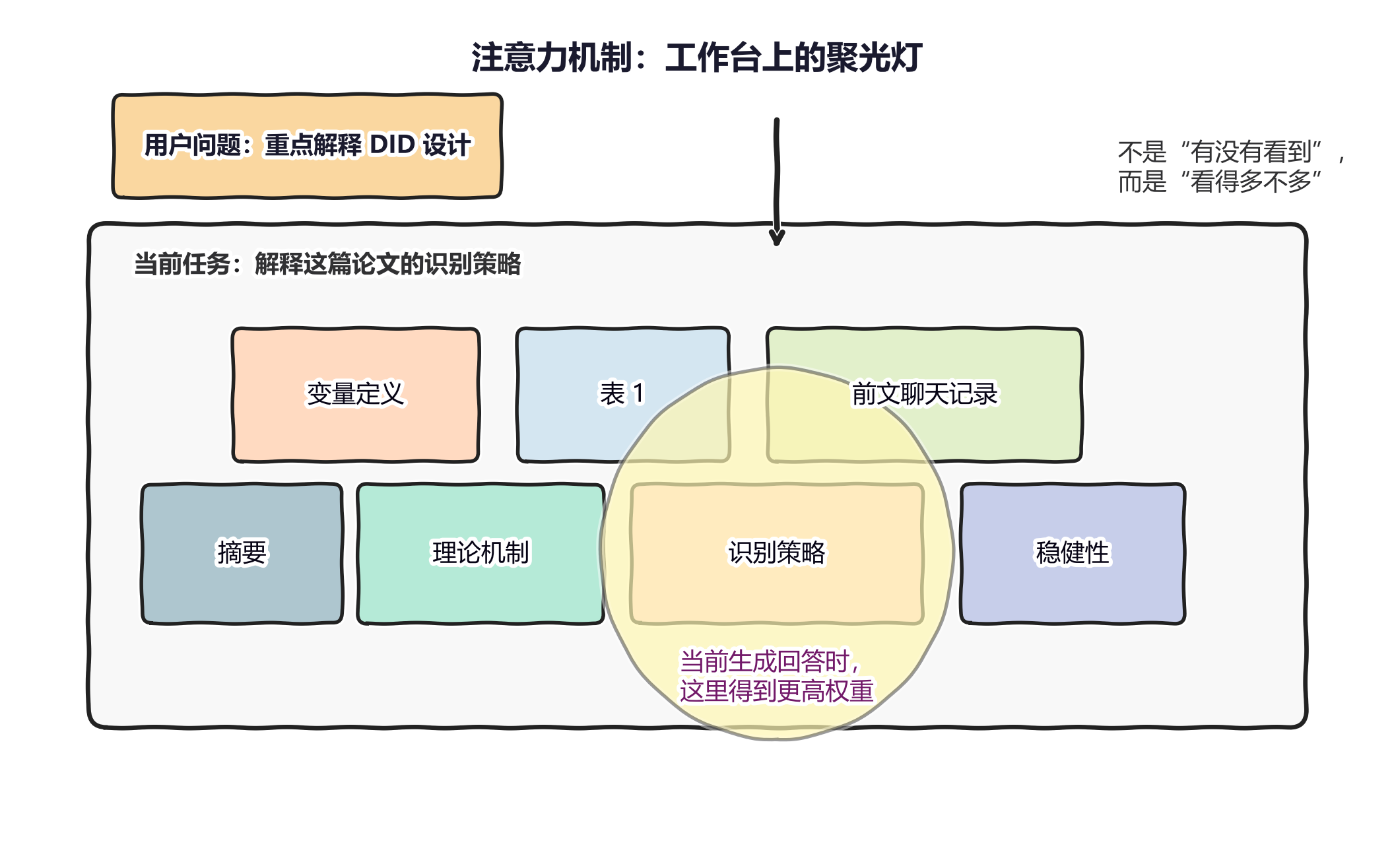
图 1:注意力机制更像工作台上的一盏聚光灯。模型面对一桌材料时,不会平均用力,而是不断调整关注重点。对普通用户来说,这意味着:材料怎么摆、问题怎么问,会直接影响模型“看哪里”。
2. 幻觉:它不是故意撒谎,而是在“补空白”
2.1 什么叫幻觉?
「幻觉」这个词现在很常见,但很多解释其实都不够准确。对普通用户来说,可以先记住一个更朴素的说法:
幻觉,就是模型给出了一段流畅、像模像样、但实际上不可靠,甚至明显错误的内容。
它可能表现为:
- 编造不存在的参考文献;
- 把两个概念混在一起;
- 引用一条并不存在的政策条文;
- 把数据来源、年份、模型设定说错;
- 用非常自信的口气,回答一个其实并没有依据的问题。
为什么会这样?一个核心原因在于,大语言模型的基础任务并不是「证明真伪」,而是根据上下文,生成最可能出现的下一个 token。这套机制在很多任务上非常强大,因为人类语言本身就有很强的统计规律;但它也天然带来一个风险:当上下文不充分、问题含糊、资料冲突,或者模型其实没有把握时,它仍然会倾向于生成“最像一个好答案”的东西。
所以,幻觉更像是一种填空式的过度补全,而不太像人类意义上的 “故意说谎”。这并不是在为模型开脱,而是为了帮助我们把问题看准:它出错,往往不是因为“心术不正”,而是因为它太擅长生成“看起来顺”的答案了。
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)