手把手教你写一个 MCP Server:Python 100行让Claude直接查询本地CSV数据(完整代码)
·
手把手教你写一个 MCP Server:Python 100行让Claude直接查询本地CSV数据(完整代码)
环境要求: Python 3.11+,pip,Claude API Key
难度: 中级(需要有基本Python异步编程概念)
预计耗时: 30分钟
目录
- 一、MCP是什么?和Tool Use有什么区别
- 二、环境搭建与项目结构
- 三、准备测试数据(products.csv)
- 四、完整MCP Server实现
- 五、集成测试:让Claude查询数据
- 六、生产环境优化
- 七、常见报错与解决方案
一、MCP是什么?和Tool Use有什么区别
MCP(Model Context Protocol)是Anthropic在2024年底发布的开放协议,核心作用是让AI模型以标准化方式访问外部工具和数据源。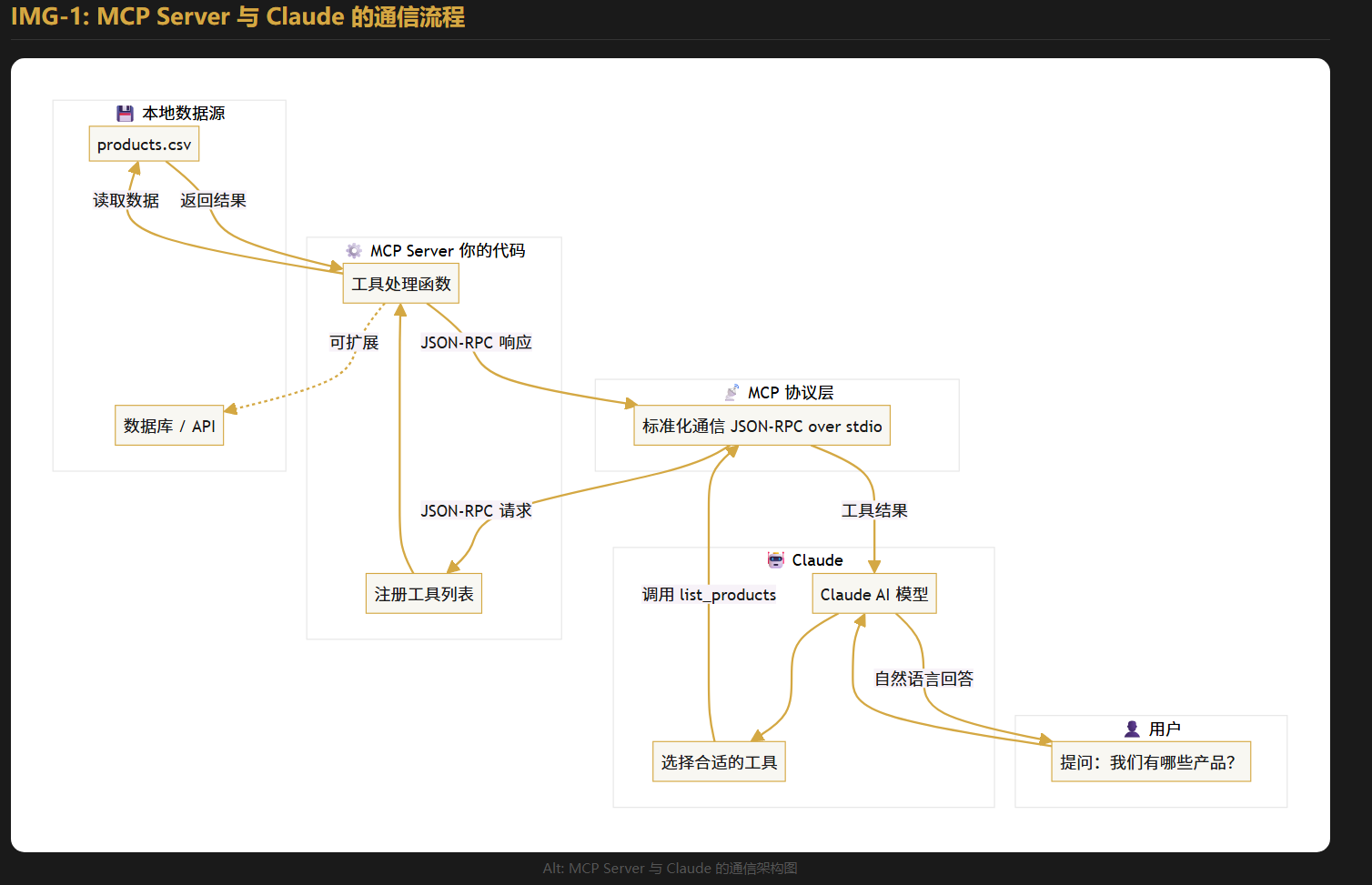
1.1 架构原理
用户提问
↓
Claude(推理层)
↓ 识别需要调用工具
MCP Protocol(通信层)
↓ 发送标准化请求
MCP Server(服务层)← 本文要实现的部分
↓ 查询数据
本地CSV / 数据库 / API(数据层)
↑ 返回结果
(逆向返回给用户)
1.2 MCP vs Tool Use 对比
| 对比项 | Tool Use | MCP |
|---|---|---|
| 工具定义位置 | 写在 API 请求的 tools 参数里 |
由 Server 动态暴露 |
| 工具更新方式 | 每次调用都要传 | Server 更新,客户端自动同步 |
| 适合场景 | 简单、固定工具 | 复杂、动态工具集合 |
| 本地数据访问 | 需要自己写接口 | 原生支持 |
| 生产可维护性 | 一般 | 好 |
一句话总结: Tool Use 适合快速原型,MCP 适合生产级项目。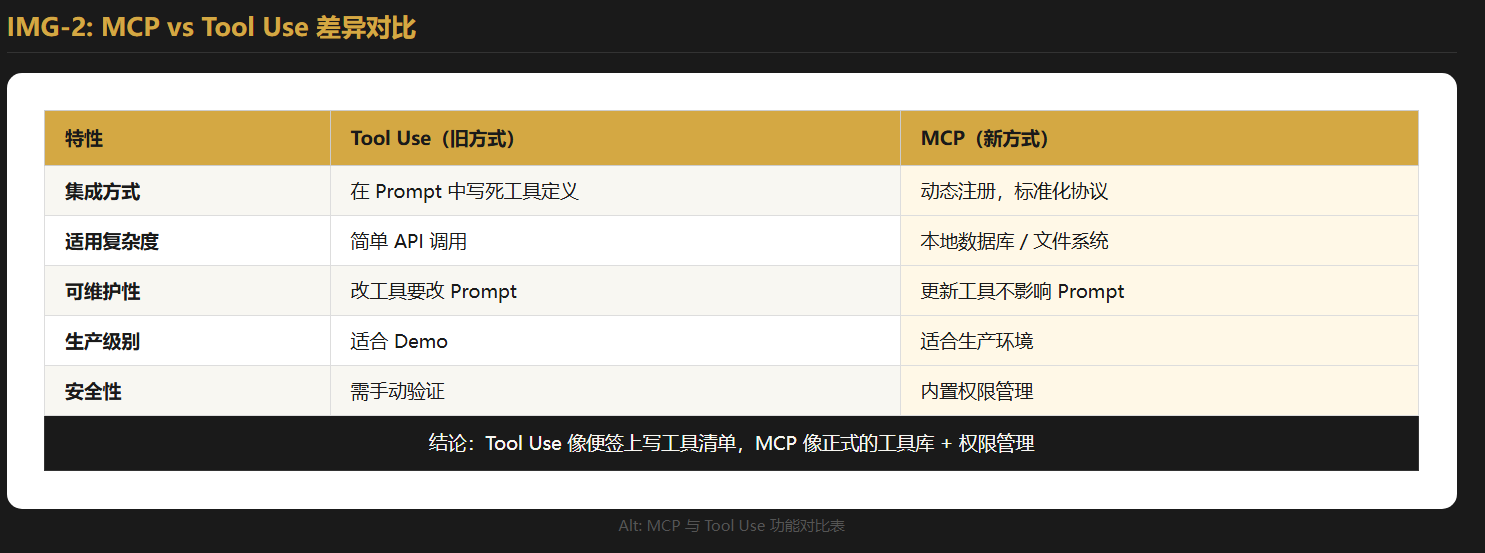
二、环境搭建与项目结构
2.1 安装依赖
# 建议使用虚拟环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install mcp anthropic pydantic python-dotenv
验证安装:
python -c "import mcp; print('MCP版本:', mcp.__version__)"
2.2 项目结构
mcp-csv-demo/
├── .env # 环境变量(API Key等)
├── products.csv # 测试数据
├── server.py # MCP Server(核心文件)
└── test_client.py # 测试客户端
2.3 配置环境变量
# .env
ANTHROPIC_API_KEY=你的API_Key
ANTHROPIC_BASE_URL=https://gw.claudeapi.com
CSV_FILE=./products.csv
注意: 如果你在国内使用,直接访问 Anthropic 官方接口会遇到网络问题。推荐使用 ClaudeAPI 中转服务,将
ANTHROPIC_BASE_URL设置为https://gw.claudeapi.com,Key 格式和官方完全兼容,无需修改代码逻辑。
三、准备测试数据
新建 products.csv,内容如下:
product_id,product_name,category,price,stock,created_date
P001,Claude Opus 4.6,AI Model,2.99,5000,2026-03-15
P002,Claude Sonnet 4.6,AI Model,1.99,8000,2026-03-15
P003,Claude Haiku 4.5,AI Model,0.80,10000,2026-02-20
P004,API Gateway Pro,Infrastructure,29.99,100,2026-04-01
P005,ClaudeAPI Console,Tools,0.00,999999,2026-01-01
P006,MCP Integration Kit,Tools,99.99,50,2026-04-10
P007,Premium Support,Service,199.99,200,2026-03-01
P008,Batch API Access,Feature,49.99,300,2026-04-01
四、完整MCP Server实现
新建 server.py,以下是完整可运行代码:
"""
MCP Server Demo:让Claude查询本地CSV数据
依赖:pip install mcp python-dotenv
"""
import csv
import json
import asyncio
from pathlib import Path
from dotenv import load_dotenv
import os
from mcp.server import Server
from mcp.server.stdio import stdio_server
import mcp.types as types
load_dotenv()
# ─────────────────────────────────────────
# 数据层:CSV读取与查询函数
# ─────────────────────────────────────────
CSV_FILE = os.getenv("CSV_FILE", "./products.csv")
_products: list[dict] = []
def load_data():
"""启动时加载CSV到内存"""
global _products
path = Path(CSV_FILE)
if not path.exists():
raise FileNotFoundError(f"CSV文件不存在: {CSV_FILE}")
with open(path, encoding="utf-8") as f:
_products = list(csv.DictReader(f))
print(f"[MCP Server] 已加载 {len(_products)} 条产品数据")
def _list_all() -> str:
if not _products:
return "暂无数据"
lines = [f"共 {len(_products)} 个产品:\n"]
for i, p in enumerate(_products, 1):
lines.append(
f"{i:2}. [{p['product_id']}] {p['product_name']}"
f" | 分类: {p['category']}"
f" | 价格: ¥{p['price']}"
)
return "\n".join(lines)
def _query_by_id(product_id: str) -> str:
for p in _products:
if p["product_id"].upper() == product_id.upper():
return json.dumps(p, ensure_ascii=False, indent=2)
return f"未找到产品 ID: {product_id}"
def _search_price_range(min_price: float, max_price: float) -> str:
results = [
p for p in _products
if min_price <= float(p["price"]) <= max_price
]
if not results:
return f"没有价格在 ¥{min_price}–¥{max_price} 范围内的产品"
lines = [f"价格 ¥{min_price}–¥{max_price} 的产品(共{len(results)}个):\n"]
for p in results:
lines.append(f" • {p['product_name']} — ¥{p['price']}(库存: {p['stock']})")
return "\n".join(lines)
def _filter_category(category: str) -> str:
results = [p for p in _products if p["category"].lower() == category.lower()]
if not results:
return f"分类 '{category}' 下没有产品"
lines = [f"分类 [{category}] 共 {len(results)} 个产品:\n"]
for p in results:
lines.append(f" • [{p['product_id']}] {p['product_name']} — ¥{p['price']}")
return "\n".join(lines)
def _get_stats() -> str:
if not _products:
return "暂无数据"
total = len(_products)
categories = {}
prices = []
total_stock = 0
for p in _products:
cat = p["category"]
categories[cat] = categories.get(cat, 0) + 1
prices.append(float(p["price"]))
total_stock += int(p["stock"])
avg_price = sum(prices) / total
stats = [
f"产品总数: {total}",
f"分类数量: {len(categories)}",
f"平均价格: ¥{avg_price:.2f}",
f"最低价格: ¥{min(prices):.2f}",
f"最高价格: ¥{max(prices):.2f}",
f"总库存量: {total_stock:,}",
"\n各分类分布:",
]
for cat, count in sorted(categories.items(), key=lambda x: -x[1]):
stats.append(f" {cat}: {count} 个产品")
return "\n".join(stats)
# ─────────────────────────────────────────
# MCP层:Server定义与工具注册
# ─────────────────────────────────────────
server = Server("mcp-csv-server")
TOOLS = [
types.Tool(
name="list_products",
description="列出CSV中所有产品,包含ID、名称、分类、价格",
inputSchema={"type": "object", "properties": {}, "required": []},
),
types.Tool(
name="query_product",
description="根据产品ID查询单个产品的完整详情",
inputSchema={
"type": "object",
"properties": {
"product_id": {
"type": "string",
"description": "产品ID,例如 P001",
}
},
"required": ["product_id"],
},
),
types.Tool(
name="search_price_range",
description="查询指定价格区间内的所有产品",
inputSchema={
"type": "object",
"properties": {
"min_price": {"type": "number", "description": "最低价格(含)"},
"max_price": {"type": "number", "description": "最高价格(含)"},
},
"required": ["min_price", "max_price"],
},
),
types.Tool(
name="filter_category",
description="按产品分类筛选,例如 AI Model、Tools、Service",
inputSchema={
"type": "object",
"properties": {
"category": {"type": "string", "description": "分类名称,大小写不敏感"}
},
"required": ["category"],
},
),
types.Tool(
name="get_stats",
description="获取产品数据的统计摘要:总数、均价、库存、分类分布等",
inputSchema={"type": "object", "properties": {}, "required": []},
),
]
@server.list_tools()
async def handle_list_tools() -> list[types.Tool]:
return TOOLS
@server.call_tool()
async def handle_call_tool(
name: str, arguments: dict
) -> list[types.TextContent]:
try:
if name == "list_products":
result = _list_all()
elif name == "query_product":
result = _query_by_id(arguments["product_id"])
elif name == "search_price_range":
result = _search_price_range(
float(arguments["min_price"]),
float(arguments["max_price"]),
)
elif name == "filter_category":
result = _filter_category(arguments["category"])
elif name == "get_stats":
result = _get_stats()
else:
result = f"未知工具: {name}"
except KeyError as e:
result = f"参数缺失: {e}"
except Exception as e:
result = f"执行出错: {e}"
return [types.TextContent(type="text", text=result)]
# ─────────────────────────────────────────
# 入口
# ─────────────────────────────────────────
async def main():
load_data()
async with stdio_server() as streams:
await server.run(
streams[0],
streams[1],
server.create_initialization_options(),
)
if __name__ == "__main__":
asyncio.run(main())
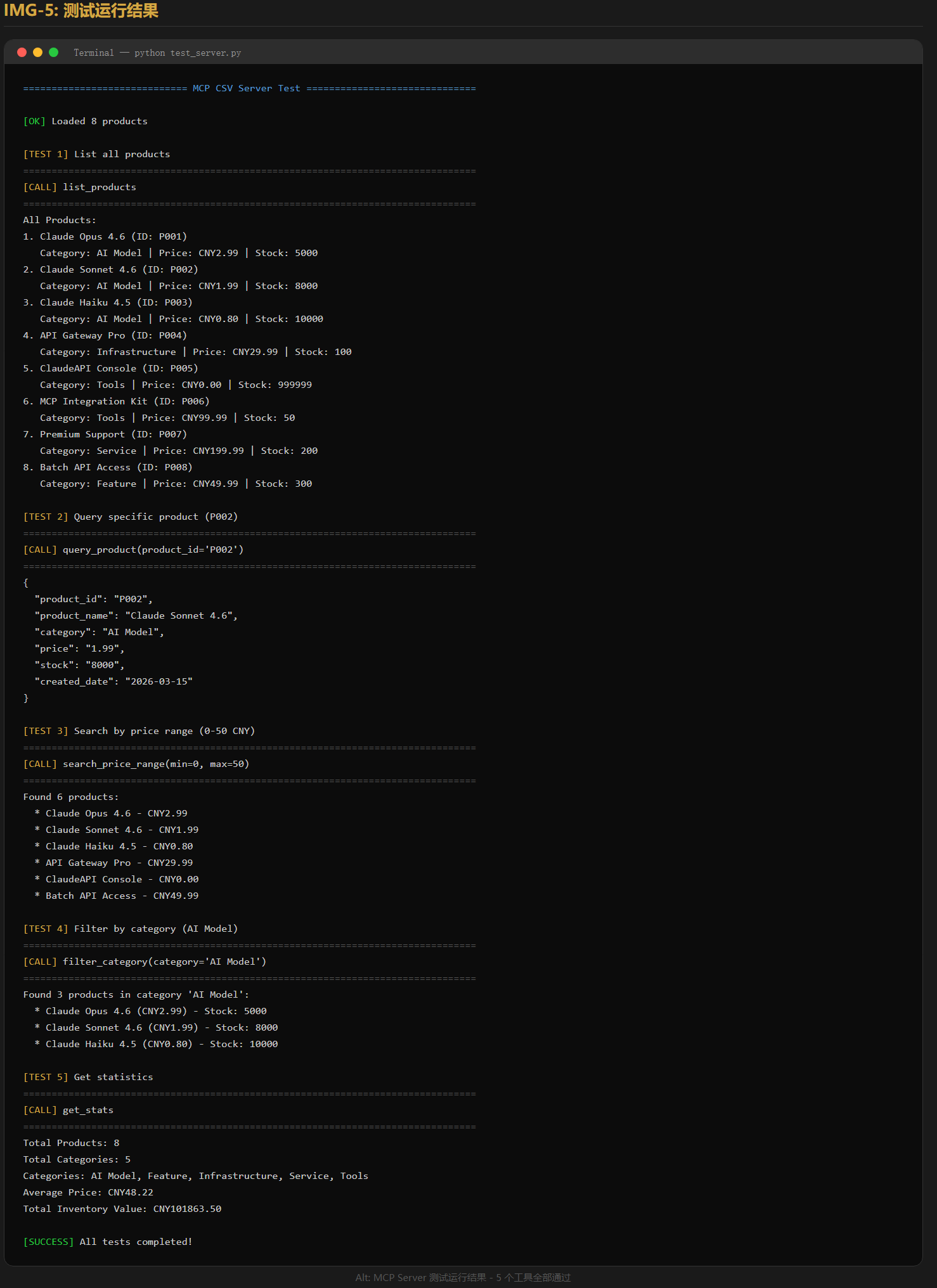
五、集成测试:让Claude查询数据
5.1 方式一:直接用 Claude Code 调用
如果你在用 Claude Code(VS Code 插件 或 CLI),在项目根目录执行:
claude mcp add csv-server -- python server.py
之后在 Claude Code 对话框里直接问:
"有哪些价格低于5块的产品?"
"AI Model 分类下有什么?"
"给我看一下整体数据统计"
Claude 会自动选择对应工具并返回查询结果。
5.2 方式二:编写测试客户端
新建 test_client.py:
"""
测试客户端:通过Claude API + MCP Server 查询CSV数据
"""
import subprocess
import anthropic
import os
import json
from dotenv import load_dotenv
load_dotenv()
client = anthropic.Anthropic(
api_key=os.getenv("ANTHROPIC_API_KEY"),
base_url=os.getenv("ANTHROPIC_BASE_URL", "https://gw.claudeapi.com"),
)
# 定义MCP工具(与server.py中TOOLS保持一致)
TOOLS = [
{
"name": "list_products",
"description": "列出所有产品",
"input_schema": {"type": "object", "properties": {}, "required": []},
},
{
"name": "query_product",
"description": "根据ID查询产品详情",
"input_schema": {
"type": "object",
"properties": {"product_id": {"type": "string"}},
"required": ["product_id"],
},
},
{
"name": "search_price_range",
"description": "按价格区间搜索产品",
"input_schema": {
"type": "object",
"properties": {
"min_price": {"type": "number"},
"max_price": {"type": "number"},
},
"required": ["min_price", "max_price"],
},
},
{
"name": "filter_category",
"description": "按分类筛选产品",
"input_schema": {
"type": "object",
"properties": {"category": {"type": "string"}},
"required": ["category"],
},
},
{
"name": "get_stats",
"description": "获取数据统计摘要",
"input_schema": {"type": "object", "properties": {}, "required": []},
},
]
def call_local_tool(name: str, arguments: dict) -> str:
"""直接调用本地工具函数(简化版,不启动独立进程)"""
import csv
from pathlib import Path
products = list(csv.DictReader(open("products.csv", encoding="utf-8")))
if name == "list_products":
return "\n".join(
f"[{p['product_id']}] {p['product_name']} ¥{p['price']}"
for p in products
)
elif name == "query_product":
pid = arguments["product_id"]
for p in products:
if p["product_id"].upper() == pid.upper():
return json.dumps(p, ensure_ascii=False, indent=2)
return f"未找到 {pid}"
elif name == "search_price_range":
mn, mx = float(arguments["min_price"]), float(arguments["max_price"])
found = [p for p in products if mn <= float(p["price"]) <= mx]
return "\n".join(
f"{p['product_name']} ¥{p['price']}" for p in found
) or "无结果"
elif name == "filter_category":
cat = arguments["category"]
found = [p for p in products if p["category"].lower() == cat.lower()]
return "\n".join(p["product_name"] for p in found) or "无结果"
elif name == "get_stats":
prices = [float(p["price"]) for p in products]
return (
f"总数: {len(products)}, "
f"均价: ¥{sum(prices)/len(prices):.2f}, "
f"最低: ¥{min(prices)}, 最高: ¥{max(prices)}"
)
return "未知工具"
def ask(question: str):
print(f"\n{'='*50}")
print(f"问题: {question}")
print("="*50)
messages = [{"role": "user", "content": question}]
# 最多循环5轮(防止无限调用)
for _ in range(5):
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=TOOLS,
messages=messages,
)
# 如果是最终回答,直接输出
if response.stop_reason == "end_turn":
for block in response.content:
if hasattr(block, "text"):
print(f"\nClaude 回答:\n{block.text}")
break
# 处理工具调用
if response.stop_reason == "tool_use":
messages.append({"role": "assistant", "content": response.content})
tool_results = []
for block in response.content:
if block.type == "tool_use":
print(f" → 调用工具: {block.name}({block.input})")
result = call_local_tool(block.name, block.input)
print(f" ← 工具结果: {result[:80]}{'...' if len(result)>80 else ''}")
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
messages.append({"role": "user", "content": tool_results})
if __name__ == "__main__":
ask("有哪些价格低于5元的产品?")
ask("帮我查一下 P006 的详细信息")
ask("给我一份完整的数据统计报告")
运行测试:
python test_client.py
预期输出:
==================================================
问题: 有哪些价格低于5元的产品?
==================================================
→ 调用工具: search_price_range({'min_price': 0, 'max_price': 5})
← 工具结果: Claude Opus 4.6 ¥2.99
Claude Sonnet 4.6 ¥1.99
Claude Haiku 4.5 ...
Claude 回答:
价格低于5元的产品共有4个:
1. Claude Opus 4.6 — ¥2.99
2. Claude Sonnet 4.6 — ¥1.99
3. Claude Haiku 4.5 — ¥0.80
4. ClaudeAPI Console — ¥0.00(免费)
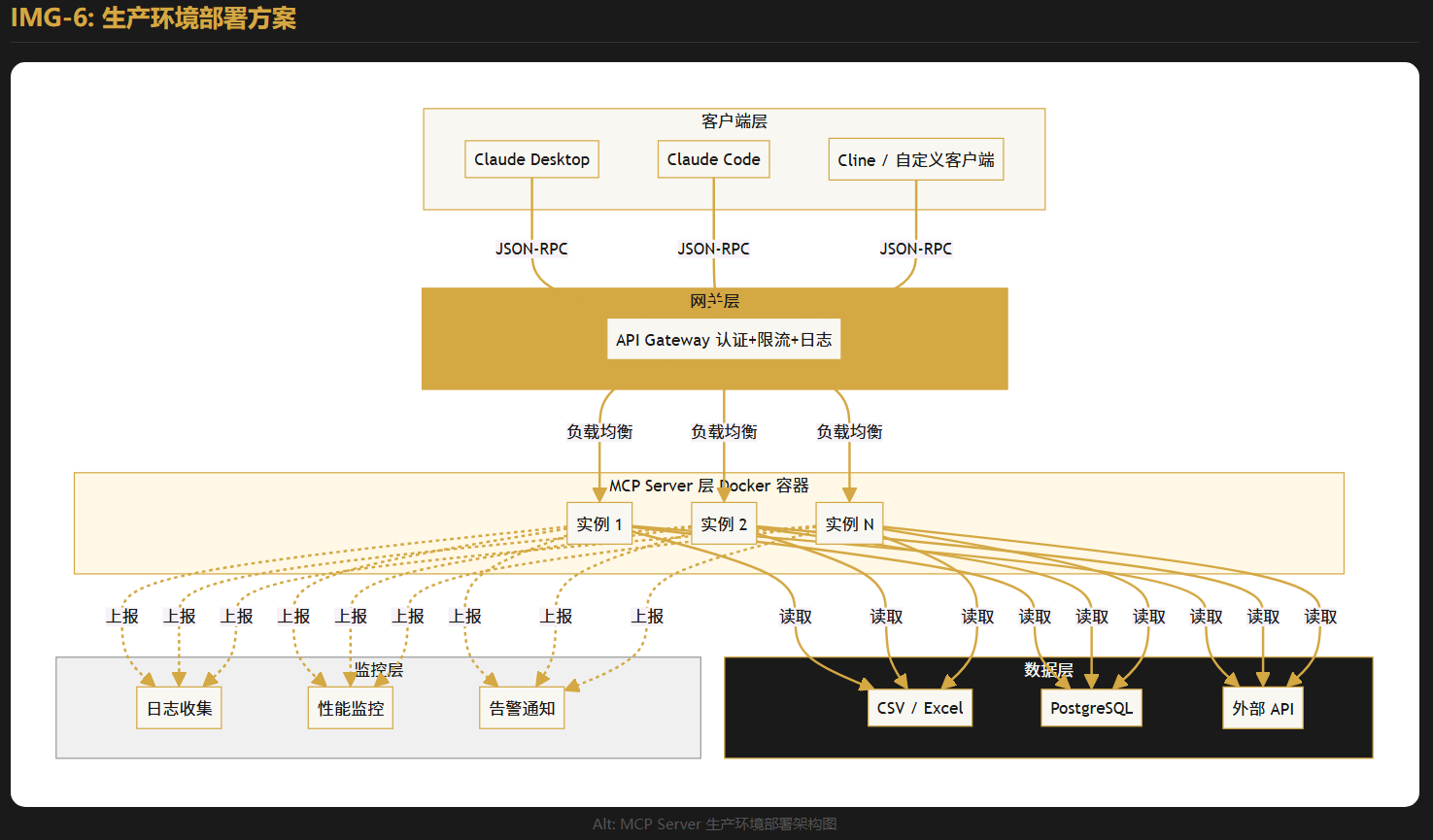
六、生产环境优化
6.1 大数据量:换用SQLite
CSV 适合万行以内,更大的数据集建议用 SQLite:
import sqlite3
# 一次性导入CSV到SQLite
def csv_to_sqlite(csv_path: str, db_path: str):
import csv
conn = sqlite3.connect(db_path)
with open(csv_path, encoding="utf-8") as f:
reader = csv.DictReader(f)
cols = reader.fieldnames
conn.execute(
f"CREATE TABLE IF NOT EXISTS products ({', '.join(cols)})"
)
conn.executemany(
f"INSERT INTO products VALUES ({', '.join(['?']*len(cols))})",
[list(row.values()) for row in reader],
)
conn.commit()
conn.close()
# 查询时使用参数化查询,防止SQL注入
def search_by_price_range(min_price: float, max_price: float) -> str:
conn = sqlite3.connect("products.db")
rows = conn.execute(
"SELECT * FROM products WHERE CAST(price AS REAL) BETWEEN ? AND ?",
(min_price, max_price),
).fetchall()
conn.close()
return "\n".join(str(r) for r in rows)
6.2 加缓存:避免重复查询
from functools import lru_cache
@lru_cache(maxsize=128)
def _filter_category_cached(category: str) -> str:
# 注意:lru_cache 要求参数可哈希,不能传 list/dict
return _filter_category(category)
6.3 权限控制:只读工具不暴露写操作
READ_ONLY_TOOLS = {"list_products", "query_product", "search_price_range",
"filter_category", "get_stats"}
@server.call_tool()
async def handle_call_tool(name: str, arguments: dict):
if name not in READ_ONLY_TOOLS:
return [types.TextContent(type="text", text="权限不足:该操作不被允许")]
# ... 正常处理
七、常见报错与解决方案
| 报错信息 | 原因 | 解决方法 |
|---|---|---|
ModuleNotFoundError: No module named 'mcp' |
依赖未安装 | pip install mcp |
FileNotFoundError: products.csv |
CSV路径错误 | 检查 .env 中 CSV_FILE 路径 |
anthropic.AuthenticationError |
API Key 无效 | 检查 .env 中 ANTHROPIC_API_KEY |
ConnectionError 或超时 |
网络不通 | 设置 ANTHROPIC_BASE_URL=https://gw.claudeapi.com |
stop_reason: max_tokens |
输出超长 | 增大 max_tokens 参数 |
| 工具一直不被调用 | 工具描述不清晰 | 优化 description 字段,让Claude更容易理解工具用途 |
总结
本文完整演示了:
- MCP架构原理:协议分层、与Tool Use的区别
- 完整Server实现:5个工具,~100行Python代码
- 两种集成方式:Claude Code插件 和 API客户端
- 生产级优化:SQLite、缓存、权限控制
完整代码已上传至 GitHub,欢迎 Star。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)