RAG(检索增强生成)介绍+四行代码构建RAG
RAG(检索增强生成)介绍
一、什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将信息检索与大语言模型生成相结合的技术框架。它的核心思想是:在让大模型回答问题之前,先从外部知识库中检索相关的内容,然后将这些内容作为“参考资料”一起提供给大模型,让它基于这些资料生成答案。
通俗比喻:
传统大模型 = 闭卷考试(只能靠训练时记住的知识)
RAG = 开卷考试(允许查阅资料后再作答)
二、为什么需要做 RAG?
尽管大语言模型(如 GPT-4、DeepSeek)能力强大,但它们存在几个固有缺陷,RAG 正是为了解决这些问题而生的。
一句话:RAG 让大模型“开卷考试”,从而更准确、更及时、更可信。
三、RAG 的核心组件
一个完整的 RAG 系统包含三个核心组件(按流程顺序):
- 索引(Indexing) – 准备知识库
-
文档加载器(Loader):读取各种格式的源文件(PDF、Word、网页、数据库等)。
-
文本分块(Chunking):将长文档切分成适合检索的小段落(例如 200‑500 字符)。
-
嵌入模型(Embedding Model):将每个文本块转换成固定维度的向量(语义向量)。
-
向量数据库(Vector Store):存储这些向量并建立索引,支持快速相似度搜索。
- 检索(Retrieval) – 根据问题找资料
-
将用户问题也用同一个嵌入模型转换成向量。
-
在向量数据库中搜索最相似的 k 个文本块(k 通常在 3‑10 之间)。
-
可选:使用关键词检索(BM25)或混合检索提升召回率,再用重排序模型(Reranker)精排。
- 生成(Generation) – 基于资料生成答案
-
将检索到的文本块与用户问题一起拼接成一个提示词(Prompt)。
-
提示词模板示例:
请根据以下参考资料回答问题。如果参考资料中没有相关信息,请明确说“不知道”。
参考资料:
【1】...
【2】...
问题:...
答案:
将提示词发送给大语言模型(LLM),获得最终答案。
四、RAG 的典型工作流程图
flowchart TD
subgraph 索引阶段(离线)
A[原始文档] --> B[文档加载器]
B --> C[文本分块]
C --> D[嵌入模型]
D --> E[向量数据库]
end
subgraph 查询阶段(在线)
F[用户问题] --> G[嵌入模型]
G --> H[向量检索]
E --> H
H --> I[获取相关文本块]
I --> J[提示词构建]
J --> K[大语言模型]
K --> L[最终答案]
end
五、RAG vs 微调:何时用哪个?
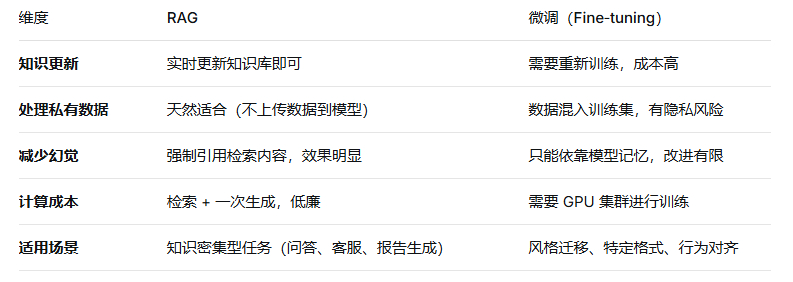
实践中,RAG 和微调常常结合使用:RAG 负责提供最新/私有知识,微调负责让模型学会特定语气或格式。
RAG = 检索 + 生成:先查资料,再答题。它让大模型从“凭空想象”变成“有理有据”,是当前解决大模型知识陈旧、幻觉、私域问题的最主流技术架构。
四行代码构建RAG
import os
os.environ['OPENAI_API_KEY'] = ''
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
#步骤一,文档解析
documents = SimpleDirectoryReader('data').load_data()
#步骤二,构建索引
index = VectorStoreIndex.from_documents(documents)
#步骤三,构建查询引擎
query_engine = index.as_query_engine()
#步骤四,得到结果
response = query_engine.query("总结一下这篇文章,用中文")
print(response)
注意
1、网络连接通畅不?
2、API_KEY是否准备好?
3、相关支持库是否安装好?
准备工作:安装通用依赖
无论最后选择哪种方案,有几个基础的库需要先安装好:
pip install llama-index llama-index-core
# 为了处理PDF、Word等文档,可以一并安装
pip install pypdf python-docx
常见原因及解决方案
使用代理(推荐)
import os
# 设置 HTTP/HTTPS 代理(假设的代理端口是 7890)
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
# 然后正常调用 OpenAI API
client = OpenAI(api_key='your-key')
client = OpenAI(
api_key='your-key',
http_client=httpx.Client(proxies="http://127.0.0.1:7890")
)
使用国内大模型 API(最稳定)
方案一:OpenAI 兼容接口
利用 llama-index-llms-openai-like 包,让LlamaIndex用访问OpenAI的方式来调用国产API。
安装:
pip install llama-index-llms-openai-like
代码实现(以DeepSeek为例):
import os
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.openai_like import OpenAILike
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 1. 配置的DeepSeek API密钥(建议设置为环境变量)
# os.environ["DEEPSEEK_API_KEY"] = "your-deepseek-api-key"
# 2. 设置大语言模型 (LLM)
Settings.llm = OpenAILike(
model="deepseek-chat", # DeepSeek模型名称
api_base="https://api.deepseek.com/v1",
api_key=os.getenv("DEEPSEEK_API_KEY"),
is_chat_model=True,
)
# 3. 设置嵌入模型 (必须!)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# 4. 加载文档和创建索引
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
# 5. 查询
query_engine = index.as_query_engine()
response = query_engine.query("这篇文章的主要内容是什么?")
print(response)
方案二:专用模型包
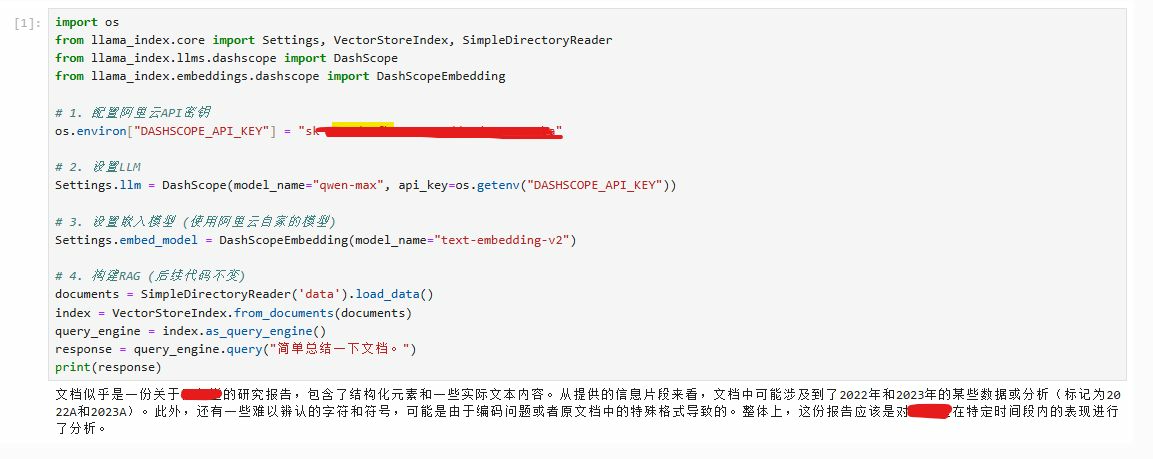
阿里云百炼 (Qwen)
安装:
pip install llama-index-llms-dashscope llama-index-embeddings-dashscope
代码实现:
import os
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.dashscope import DashScope
from llama_index.embeddings.dashscope import DashScopeEmbedding
# 1. 配置阿里云API密钥
# os.environ["DASHSCOPE_API_KEY"] = "your-dashscope-api-key"
# 2. 设置LLM
Settings.llm = DashScope(model_name="qwen-max", api_key=os.getenv("DASHSCOPE_API_KEY"))
# 3. 设置嵌入模型 (使用阿里云自家的模型)
Settings.embed_model = DashScopeEmbedding(model_name="text-embedding-v2")
# 4. 构建RAG (后续代码不变)
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("简单总结一下文档。")
print(response)
智谱AI (GLM)
安装:
pip install llama-index-llms-zhipuai
import os
from llama_index.llms.zhipuai import ZhipuAI
# 1. 配置的GLM API密钥
# os.environ["ZHIPUAI_API_KEY"] = "your-zhipuai-api-key"
# 2. 设置LLM
llm = ZhipuAI(model="glm-4", api_key=os.getenv("ZHIPUAI_API_KEY"))
# 接下来可以直接将它用于LlamaIndex的查询引擎
方案三:本地部署 Ollama(完全本地化)
追求数据隐私或希望完全摆脱对网络的依赖,Ollama是一个非常不错的选择。
安装 Ollama:访问 Ollama官网 下载安装包进行安装。
下载/运行模型(以qwen2.5为例):
ollama run qwen2.5
在代码中配置:
pip install llama-index-llms-ollama llama-index-embeddings-ollama
import os
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
# 1. 设置LLM (连接本地Ollama服务)
Settings.llm = Ollama(model="qwen2.5", request_timeout=60.0)
# 2. 设置嵌入模型 (同样使用Ollama托管)
Settings.embed_model = OllamaEmbedding(model_name="nomic-embed-text")
# 3. 构建RAG (后续代码不变)
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("文档说了什么?")
print(response)
注意,在替换模型时,必须同时配置大语言模型(LLM)和嵌入模型(Embedding Model),否则LlamaIndex可能会退而求其次,尝试去调用OpenAI的服务,有回到第一步。
进一步介绍
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("问题")
这四行代码之所以能“工作”,是因为 LlamaIndex 做了大量的隐形工作:
文档解析与分块 – 自动读取 data/ 下的文件,并按默认规则切分文本块(chunk)。
嵌入模型 (Embedding) – 默认调用 OpenAI 的 text-embedding-ada-002,将每个文本块转换成向量。
向量存储 – 默认在内存中构建一个简单的向量索引(SimpleVectorStore)。
检索策略 – 默认采用相似度检索,返回 top‑k 个最相关的块。
大语言模型 (LLM) – 默认调用 OpenAI 的 gpt-3.5-turbo,将检索到的块和用户问题一起生成答案。
所以,真正的关键点是:必须让这些“默认”能够落地。
如果能直接访问 OpenAI API(并配置好 OPENAI_API_KEY),那么这四行代码立即可用。
如果无法访问 OpenAI(比如国内网络环境),就必须显式替换默认配置,例如换成国产模型或本地模型,否则代码会报错
因此,所谓“四行代码”的简洁性,本质上是框架对复杂流程的高度封装。而使用者的核心任务是确保底层的嵌入模型和大模型环境就绪——无论是以 API 形式还是本地部署。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)