LLMDet论文精读
这篇论文《LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models》提出了一种全新的范式来提升开放词汇目标检测器的上限。它并没有直接微调一个通用的大模型去做检测,而是利用大语言模型作为“监督者”,反向微调和增强一个专门的目标检测器。

1. 核心动机:为什么要用LLM来监督检测器?
论文认为,现有的开放词汇检测器虽然能检测任意类别,但主要受限于训练数据的形式:
- 现有局限:之前的预训练数据主要由简短的短语或类别名(如“一个男人”、“杯子”)组成。这种描述是粗粒度的、孤立的,缺乏对物体细节(纹理、颜色、部件)、物体间关系以及背景的综合理解。
- LLM的潜力:大语言模型可以生成图像级别的详细长描述,其中包含丰富的物体属性、动作、精确位置和相互关系。这些信息远超简单的类别名称。
- 核心思路:让检测器不仅学习“这个区域是杯子”,还要学习在“一个装了一半咖啡的白色陶瓷杯,放在木桌上”这样的详细语境中去理解这个“杯子”。这能迫使检测器的视觉编码器学习到更精细、语义更丰富的视觉表征,从而极大提升其开放词汇能力,尤其是对罕见类别的识别能力。
2. LLMDet的训练流程:用LLM“反向”增强检测器
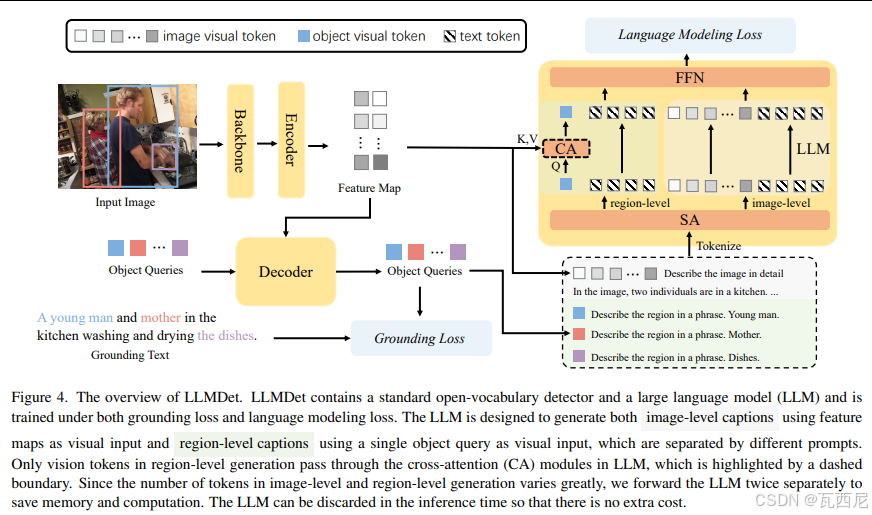
这是这篇论文最核心的部分,它回答了“如何微调”。这个流程并不是通常意义上的直接微调VLM,而是一个精巧的多阶段训练框架。
阶段零:构建专用数据集 GroundingCap-1M
为了实施这种训练,论文首先构建了一个包含112万样本的数据集。每个样本是一个四元组:(图像, 短 grounding 文本, 标注框, 长详细描述)。
- 长描述的来源:使用强大的现成大模型(如Qwen2-VL-72B)为图像生成事实性的、极其详细的描述,并进行严格的后处理(如删除幻觉语句“可能”、“暗示”),确保质量。
- 关键点:这个数据集将“粗略的检测框标签”和“精细的全局图像理解”统一了起来。
阶段一:对齐投影器(Pre-alignment)
这一步是为了让检测器和LLM能“对话”。
- 状态:目标检测器(如MM-Grounding-DINO)和LLM的参数都被冻结。
- 训练内容:仅训练一个轻量级的投影器(Projector)。
- 目的:将检测器编码器(Encoder)输出的视觉特征图,映射到LLM能理解的词元空间,为后续端到端训练铺平道路,同时不破坏两个预训练模型各自的知识。
阶段二:端到端联合微调(关键步骤)
这是实现性能飞跃的核心。此阶段,检测器、投影器和LLM一起进行端到端微调。请注意,这里的“端到端”是双向的,损失函数会反向传播回检测器进行参数更新。训练目标包含三个部分:
-
标准 Grounding 任务:
L_align和L_box- 这是检测的老本行:输入短文本(如“年轻人,母亲,盘子”),检测器输出对应的框,并与真值框计算对齐损失和回归损失。
-
图像级长描述生成任务:
L_image_lm- 过程:将检测器编码器的整个特征图输入给LLM,然后要求LLM输出GroundingCap-1M中预先标注好的、极度详细的图像长描述。
- 对检测器的增强:为了让LLM能正确预测出“左边的男人穿着红蓝相间的格子衬衫…”,检测器必须在自己的特征图中编码出这些精细的视觉信息。梯度从LLM的语言建模损失开始,穿过投影器,反向传播到检测器,迫使检测器学会提取能支撑复杂语言描述的丰富视觉特征。 这相当于用LLM的语言知识作为“监督信号”来重塑检测器的特征空间。
-
区域级短语生成任务:
L_region_lm- 过程:将检测器中与真值框匹配的正样本查询(Object Queries)输入给LLM(此时会通过LLM中新增的交叉注意力层),要求LLM为每个区域生成对应的短语(如“年轻人”、“洗碗池中的盘子”)。
- 对检测器的增强:这是一个对齐补偿机制。图像级描述是全局的,LLM可能很难将描述中的某个实体(如“盘子”)与特征图中的一块小区域精确对应。这个任务强制建立了区域特征到具体名词短语的精确映射,完成了细粒度的视觉-语言对齐。
最终,训练损失是三者之和:L = L_align + L_box + L_image_lm + L_region_lm
最重要的细节:在推理阶段,LLM被完全丢弃。经过上述训练增强的检测器可以独立运行,推理速度和成本和基线模型(MM-Grounding-DINO)完全一样,但其开放词汇检测能力已得到质的提升。
3. 实验结果与关键结论
性能飞跃
- LVIS数据集:在使用Swin-T作为骨干网络时,LLMDet在零样本设置下的AP相比强大的基线模型MM-Grounding-DINO,从41.4%提升至44.7%。更令人震惊的是,对罕见类(APr)的检测精度从34.2%大幅提升至37.3%,充分证明了详细描述对学习长尾、罕见概念的巨大帮助(见论文Table 2)。
- 跨域泛化:在COCO-O(分布偏移)和ODinW(野外数据)等基准上均取得SOTA性能,表明其学到的特征是鲁棒且通用的。
关键因素分析
- 长描述的“质量”至关重要:实验证明,使用更强LLM生成的高质量、高事实性描述带来的增益远大于弱模型生成的描述。删除描述中的幻觉语句(如“可能”、“似乎”)能显著提升罕见类性能(Table 7, 8)。
- 图像级和区域级任务缺一不可:仅用图像级描述提升有限,仅用区域级短语则几乎没有提升(因为其信息等同于原始标签)。两者结合才能发挥最大效用:一个提供丰富的全局上下文,一个提供精确的区域锚定(Table 6)。
- 预训练投影器是必要的:不经过第一阶段的对齐,直接端到端训练会破坏预训练知识,导致性能下降,尤其在罕见类上表现明显。
4. 对比与总结:两种微调范式
LLMDet为“如何在视觉语言大模型上针对目标检测任务进行微调”这个问题提供了一条与上下文提示完全不同的、更高级的路径。
-
上下文提示是“授人以鱼”:给通用MLLM(如Gemini、Qwen)提供详细指令和示例图,让它直接输出检测框。这受限于MLLM在检测任务上的非原生架构(无NMS、无置信度),效果不稳定且上限低。
-
LLMDet是“授人以渔”:不用通用MLLM来做检测,而是用LLM作为老师,在训练过程中把一个强大的专用检测器教得更强。
- 它训练的仍然是专为检测优化的模型,天然支持NMS和置信度输出,性能上限更高。
- 它利用LLM的知识提升了检测器对视觉世界的精细理解,尤其是在罕见类别上。
- 它实现了能力闭环(Mutual Benefits):被增强的检测器LLMDet反过来又可以作为一个更强大的视觉编码器,去构建更强大的多模态大模型。
所以,如果你手头有一个强大的检测基线模型,并且拥有或可以生成高质量的图像详细描述,LLMDet的范式是当前微调获得更高开放词汇检测性能的更优选择。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)