Text2SQL(DIN-SQL, MAC-SQL,DAIL-SQL,RSL-SQL,CHESS,LinkAlign,DeepEye,Agentar-Scale-SQL,AskData+GPT-4o)
·
一、DIN-SQL(2023)
https://arxiv.org/abs/2304.11015
四个模块 1.schema linking, 基于问题 选列,选表。 2.对当前任务进行分类,是否是简单,非嵌套(join),嵌套(join,子查询,集合)。 3.三类标签不同的提示词。
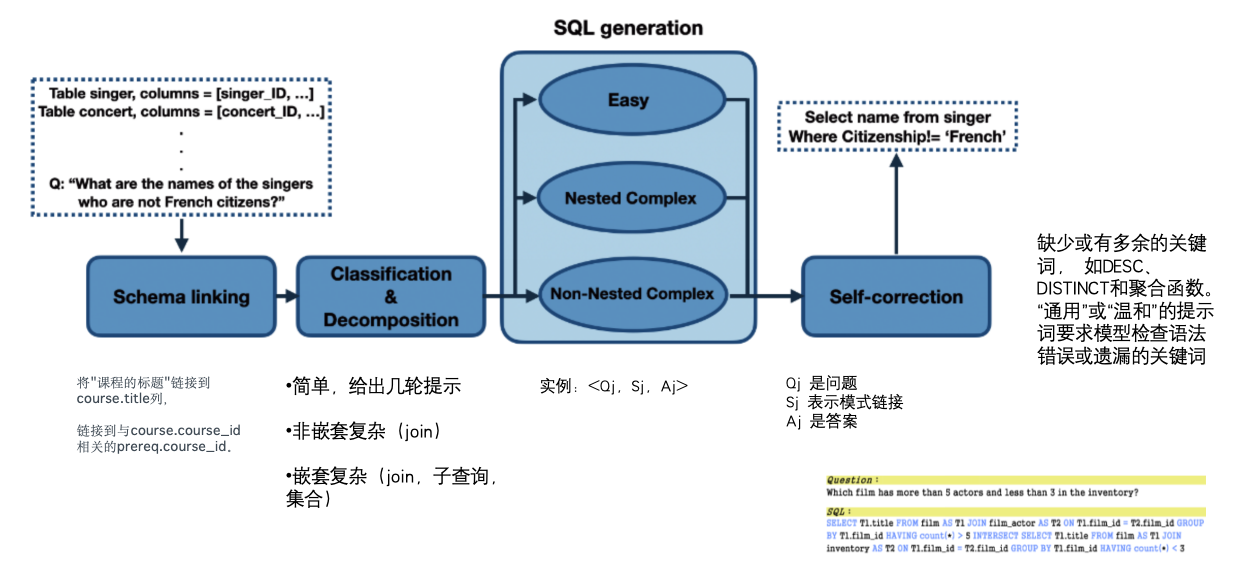
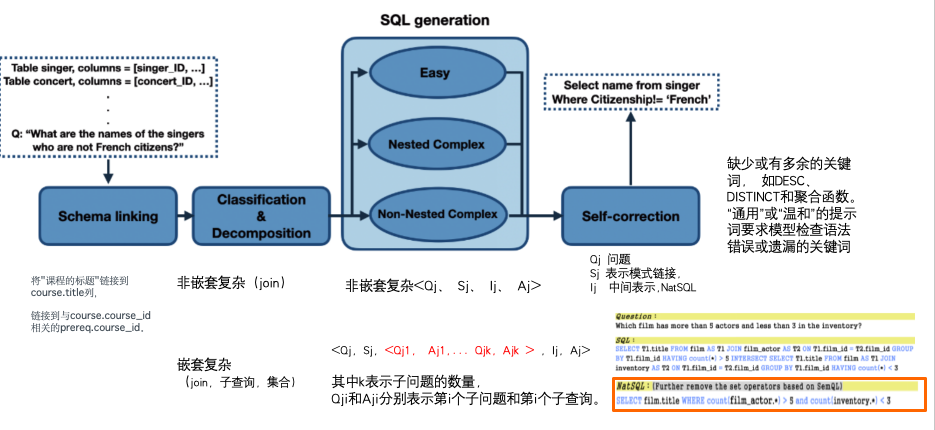
二、MAC-SQL(2023)
http://arxiv.org/abs/2312.11242
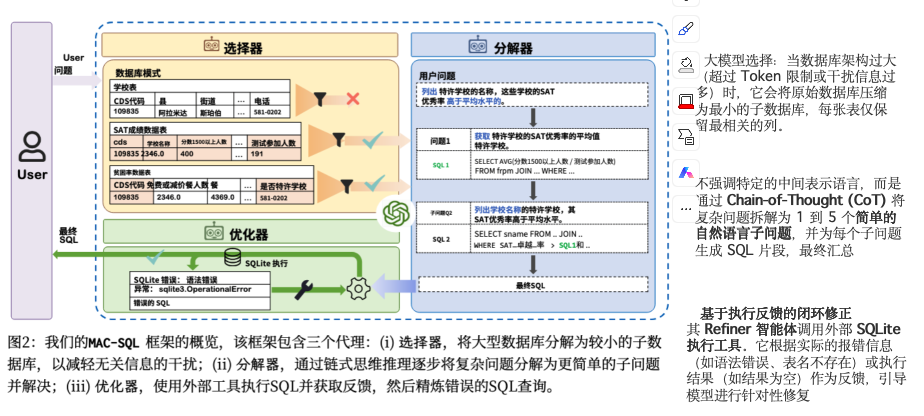
三、DAIL-SQL(2023)
https://arxiv.org/pdf/2308.15363
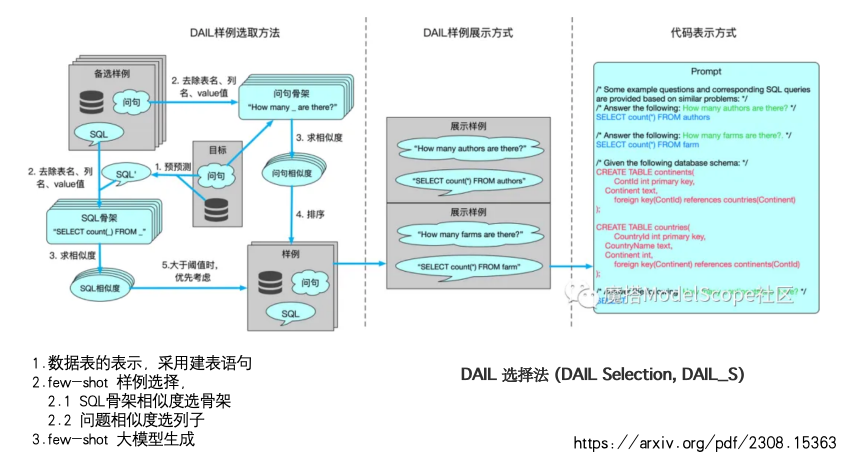
DAIL选择法(DAIL Selection,简称 DAIL_S) 是 DAIL-SQL 框架中用于在“少样本学习(Few-shot Learning)”场景下,从成千上万个案例中挑出最合适的 k 个示例放入提示词(Prompt)的方法。
它的核心逻辑在于:模型不仅要看“问题长得像不像”,还要看“生成的 SQL 逻辑像不像”。以下是该方法的详细分解:
1. 为什么需要它?(背景)
在之前的研究中,挑选示例主要有两种单一思路:
• 只看问题相似度: 找和当前问题描述最像的例子。但有时候问题描述很像,背后的 SQL 逻辑却完全不同。
• 只看 SQL 相似度: 找逻辑结构相似的例子。但这需要先预判出 SQL 结构。
DAIL_S 认为,大模型学习的是从“自然语言”到“SQL 结构”的映射关系,所以必须同时考虑问题和 SQL 的相似性。
2. DAIL_S 的具体操作步骤
第一步:问题“脱敏”与初步筛选(Masked Question Similarity)
1. 掩码处理(Masking): 为了消除具体数据库内容(如特定的表名或城市名)的干扰,算法会将目标问题和候选池中所有问题的表名、列名替换为标记符 <maskl>,将具体数值替换为 <unk>。
2. 计算相似度: 使用预训练模型(如 all-mpnet-base-v2)将这些脱敏后的问题转化为向量,并计算它们之间的欧几里得距离,以此给候选案例排个序。
第二步:SQL “骨架”预判与过滤(Query Similarity)
1. 预预测: 使用一个较小或较快的初步模型(如 Graphix 模型或直接用 GPT-4)先对当前问题“盲猜”一个 SQL 语句,记作 s
′
。
2. 提取骨架(Skeleton): 把这个“猜出来的 SQL”和案例池里的 SQL 都去掉具体的列名和值,只留下 SELECT, FROM, WHERE, JOIN 等关键词,形成逻辑骨架。
3. 计算 Jaccard 相似度: 计算这些骨架之间的相似度得分。
第三步:双重标准排序(Final Ranking)
这是最关键的一步,DAIL_S 并不是简单的加权,而是采用了一种阈值过滤机制:
• 设定阈值 τ: 论文通常将其设为 0.9 或 0.85。
• 优先准则: 在所有候选案例中,优先挑选那些 SQL 骨架相似度超过阈值 τ 的案例。
• 二次排序: 在满足上述条件的案例中,再按照第一步计算出来的问题相似度从高到低进行排序,最终选出前 k 个。
3. 它的优势是什么?
• 精准模拟: 通过这种方法选出的例子,既保证了提问方式相似,又保证了 SQL 的逻辑结构(如是否包含嵌套、是否需要连接表)高度一致。
• 性能提升: 实验证明,DAIL_S 在 Spider 开发集上的表现通常优于单纯基于问题相似度的策略(如 QTS_S 或 MQS_S)。
• 鲁棒性: 它通过“脱敏”和“骨架提取”,有效避免了模型被不同数据库之间的特定名称(如“学生表”和“老师表”)所误导。
简单来说,DAIL 选择法就像是在找“题型相似(SQL骨架像)问法相似(脱敏问题像)”的历年真题给大模型参考
四、RSL-SQL(2024)
https://arxiv.org/pdf/2411.00073
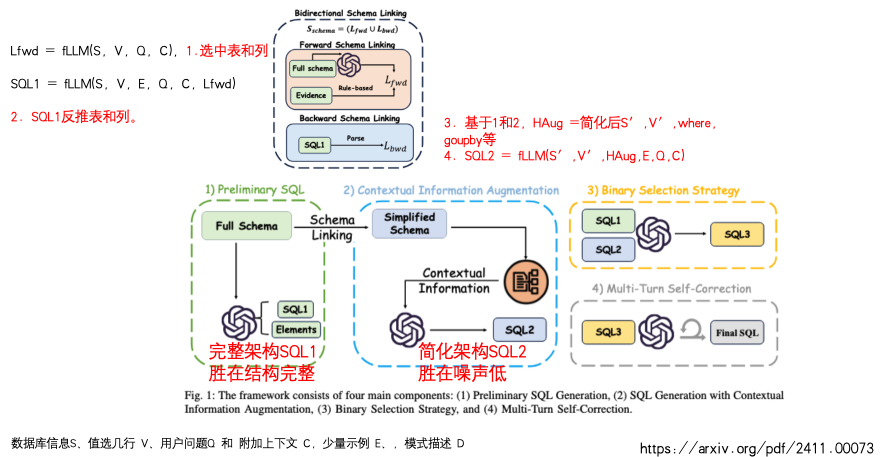
RSL-SQL 的核心思路是**“通过稳健的模式链接和多阶段反馈,实现从粗到精的 SQL 生成”**。具体解决方案分为以下四个关键步骤:
1. 第一步:双向模式链接 (BSL)
• 前向 (Forward): 直接从完整架构中识别与用户问题相关的表和列。
• 初步生成: 基于完整架构生成一个初步 SQL (SQL1)。
• 后向 (Backward): 通过解析 SQL1 中实际引用的元素来补充召回。
• 结果: 合并前后向结果,生成既精简又高召回的简化架构 (Simplified Schema)。
2. 第二步:上下文信息增强 (CIA)
• 核心动作: 利用 LLM 独立预生成 SQL 的关键组件,包括目标元素 (HE)、过滤条件 (HC) 和 SQL 关键词 (HK)。
• 生成: 将这些增强信息与简化架构描述结合,生成第二个 SQL (SQL2)。这一步显著提升了模型对复杂映射关系的理解。
3. 第三步:二元选择策略 (BSS)
• 核心逻辑: 完整架构生成的 SQL1 胜在结构完整,简化架构生成的 SQL2 胜在噪声低。
• 操作: 同时执行 SQL1 和 SQL2,将两者的执行结果(R1, R2)连同问题一起反馈给 LLM,由 LLM 选出最优的 SQL3。
4. 第四步:多轮自修正 (MTSC)
• 闭环反馈: 针对执行报错或返回空结果的“高风险”SQL,捕获详细的错误日志。
• 迭代: 引导 LLM 根据错误反馈进行多轮(最多 N 轮)对话式修正,直至生成最终正确的 SQL4。
通过这套流程,RSL-SQL 有效解决了模式链接中常见的语义歧义和信息丢失问题。如果您需要更直观地理解这四个步骤的协作关系,我可以为您创建一份技术流程图(信息图表)闪卡
五、CHESS(2024)
http://arxiv.org/abs/2405.16755
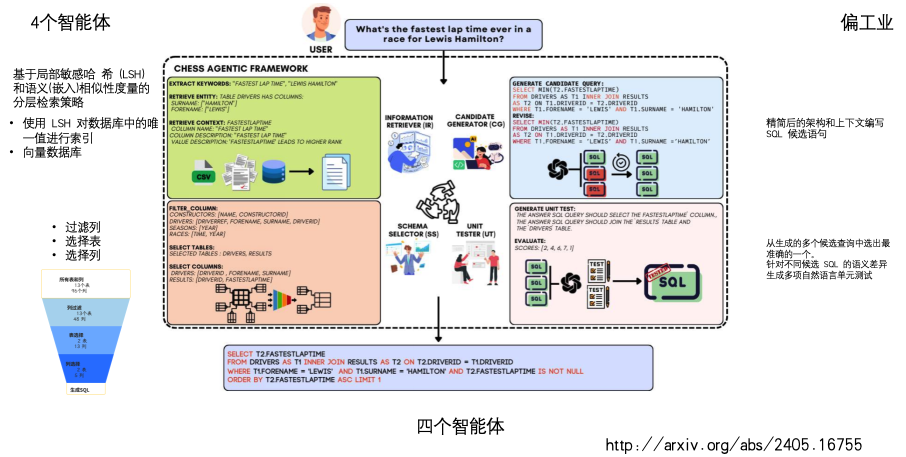
该论文引入了 CHESS,一个基于大语言模型(LLM)的多智能体框架,旨在解决大规模数据库中的 Text-to-SQL 合成挑战,。其主要贡献包括:
1. 新型多智能体框架: 提出了由四个专门智能体(IR、SS、CG、UT)组成的协作系统,显著提升了在复杂真实数据库上的性能与效率。
2. 工业级架构选择协议: 开发了能处理包含 4,000 多个列的超大规模工业级架构的协议,通过 Schema Selector (SS) 智能体有效修剪无关信息,使 Token 使用量减少了 5 倍,准确率提升了约 2%。
3. 创新的单元测试生成: 引入了一种基于自然语言的单元测试生成方法,用于在推理阶段评估生成的 SQL 查询的质量,确保生成的鲁棒性,。
4. 高效的分层检索策略: 结合局部敏感哈希 (LSH) 和语义嵌入,开发了高效的检索方法,能从数百万行数据中快速提取相关实体和上下文,,。
5. 卓越的隐私保护与性能: 在使用开源模型的情况下达到了 SOTA(当前最佳) 性能(BIRD 开发集 61.5%),且在 BIRD 测试集上取得了 71.10% 的准确率,仅需比领先方法少 83% 的 LLM 调用,,。
二、 整体思路与解决方案
CHESS 的整体思路是**“分而治之”**,将复杂的合成任务拆解为四个功能专门化的智能体协作流:
1. 信息检索层:Information Retriever (IR)
• 功能: 从数据库和目录中提取相关实体(值)和上下文描述。
• 技术: 使用 LLM 提取关键字,并利用 LSH 索引进行高效的语法搜索,同时通过向量数据库进行语义相似度搜索,确保模型获得最相关的背景信息,,。
2. 架构精简层:Schema Selector (SS)
• 功能: 将庞大的数据库架构“脱水”,仅保留生成查询所需的最小表和列子集。
• 流程: 通过三级过滤(列过滤、表选择、列选择)动态减小搜索空间,。例如,能将 13 张表 96 个列的架构压缩至 2 张表 5 个列,从而降低 LLM 处理长上下文的压力,。
3. 候选生成层:Candidate Generator (CG)
• 功能: 根据精简后的架构和上下文编写 SQL 候选语句。
• 机制: 采用迭代修整策略。生成初始查询后,在数据库中执行并捕获错误日志(如语法错误或空结果),模拟人类行为进行反复修正,直到生成高质量候选,。
4. 验证与排序层:Unit Tester (UT)
• 功能: 从生成的多个候选查询中选出最准确的一个。
• 机制: 针对不同候选 SQL 的语义差异生成多项自然语言单元测试(例如:“答案 SQL 应提及某某表”),通过验证候选查询对这些测试的通过率来分配评分,最终输出最高分查询,。
这种多智能体协作模式使得 CHESS 能够根据计算预算和部署约束(如隐私、算力)进行自适应配置,在保证高准确率的同时兼顾效率,,。
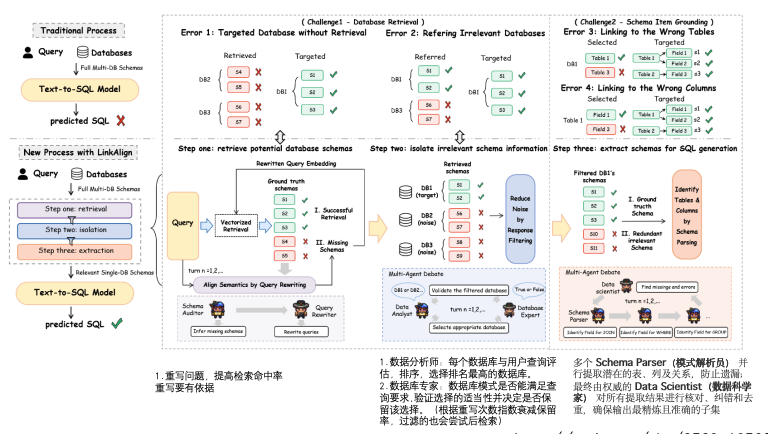
六、LinkAlign(2025)
http://arxiv.org/abs/2503.18596
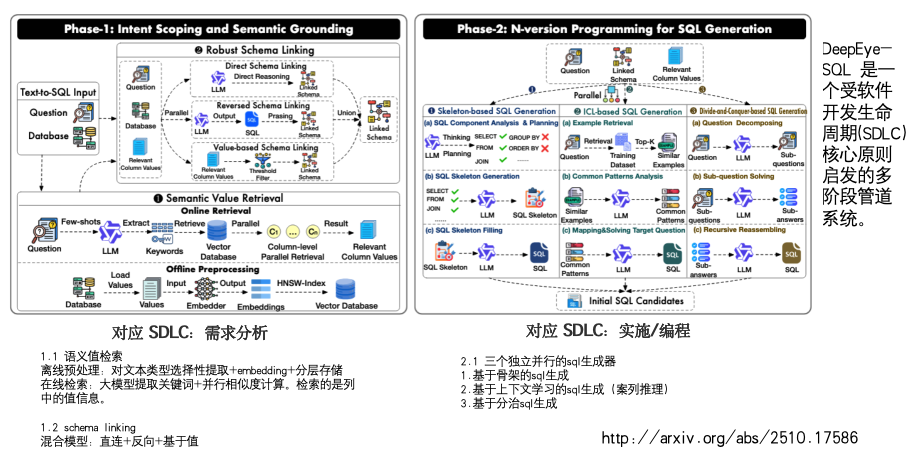
七、DeepEye‐SQL(2025)
http://arxiv.org/abs/2510.17586
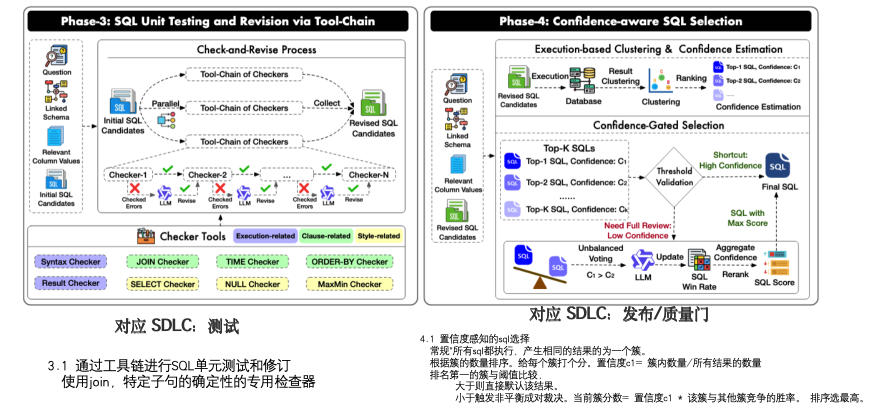
八、Agentar-Scale-SQL(2025)
https://arxiv.org/abs/2509.24403
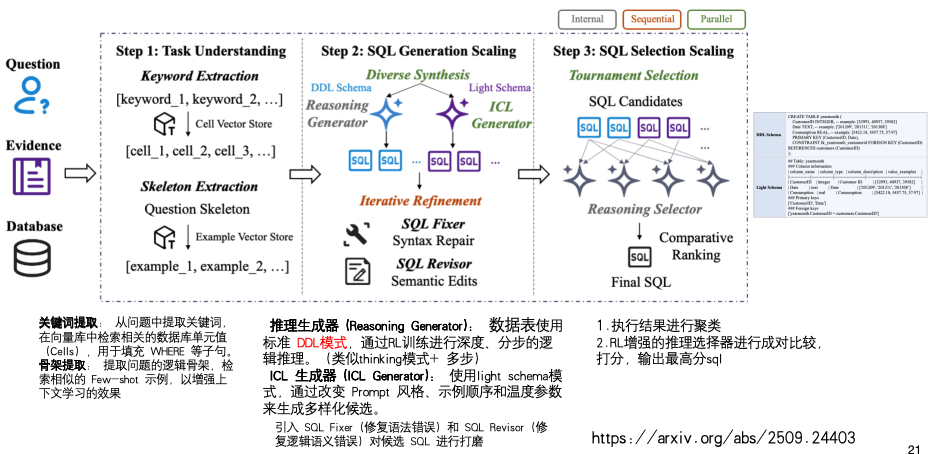
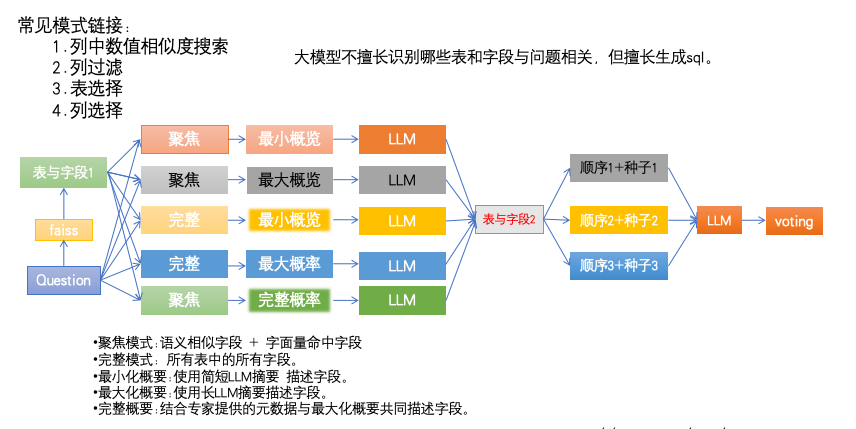
九、AskData + GPT-4o(2025)
https://arxiv.org/abs/2509.24403


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)