在 Mac 上跑 AI,Rapid-MLX 可能是目前最快的选择
本地跑模型,不用云服务,不花 API 费用,支持 Cursor、Claude Code 以及任何 OpenAI 兼容的应用。
Rapid-MLX 是一个专门为 Apple Silicon Mac 打造的本地 AI 模型运行工具。它基于 Apple 的 MLX 框架,利用了统一内存和 Metal 计算内核,在大多数模型上跑得比 Ollama、llama.cpp 这类 C++ 引擎还要快。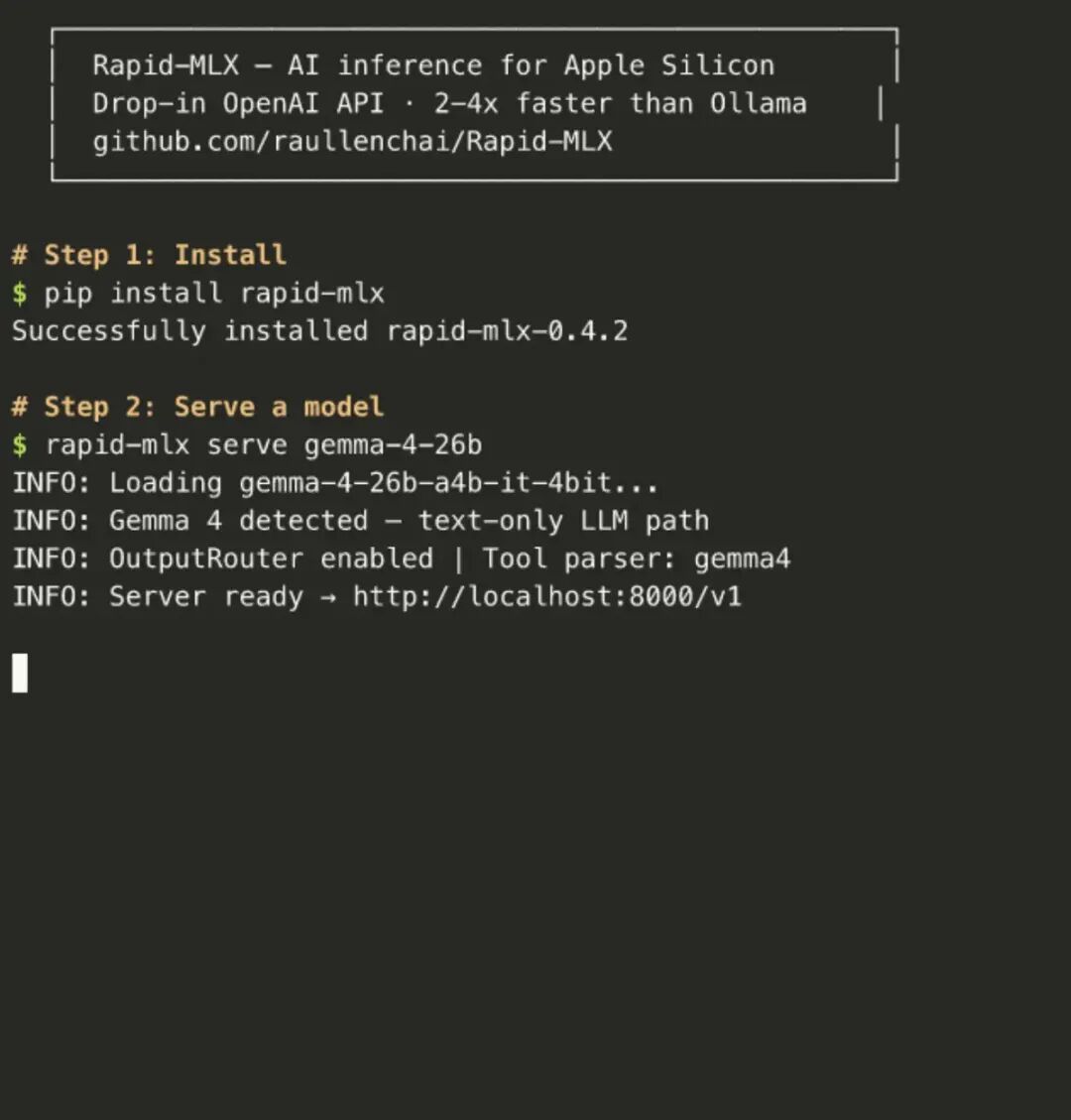
你可以用一条命令装好,然后通过 OpenAI 兼容的 API 调用本地模型——就像在用 GPT 一样,但所有计算都在你的 Mac 上完成。
快速开始
第一步:安装
三种方式任选一种:
# Homebrew(推荐,不会遇到 Python 版本问题)
brew install raullenchai/rapid-mlx/rapid-mlx
# pip(需要 Python 3.10+,macOS 自带的 3.9 不行)
pip install rapid-mlx
# 一键安装脚本(自动处理 Python)
curl -fsSL https://raullenchai.github.io/Rapid-MLX/install.sh | bash如果你要用视觉/多模态模型(Gemma 4、Qwen-VL 等),需要额外装依赖:
pip install 'rapid-mlx[vision]'
纯文本安装包约 460 MB,加视觉功能多 322 MB。
第二步:启动一个模型
rapid-mlx serve qwen3.5-4b首次运行会自动下载模型(约 2.5 GB),能看到进度条。等出现 Ready: http://localhost:8000/v1 就表示服务已启动。
第三步:发一条消息
打开另一个终端窗口,执行:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"default","messages":[{"role":"user","content":"Say hello"}]}'这样就完成了。你现在有一个运行在本地的 OpenAI 风格 API 服务,地址是 http://localhost:8000/v1。任何支持 OpenAI API 的应用都可以直接指向这个地址使用。
想看所有可用的模型别名?执行
rapid-mlx models。
想要更小更快的模型?试试rapid-mlx serve qwen3.5-9b(约 5 GB)。
用 Python 调用
确保上面的服务正在运行,然后:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
response = client.chat.completions.create(
model="default",
messages=[{"role": "user", "content": "Say hello"}],
)
print(response.choices[0].message.content)api_key 可以填任意值,不需要真实密钥。
搭配现有工具使用
Rapid-MLX 提供了 OpenAI 兼容的 API 端点,所以几乎所有支持 OpenAI 的工具都能直接用。
Cursor
Settings → Models → Add Model:
-
OpenAI API Base:
http://localhost:8000/v1 -
API Key:
not-needed -
Model name:
default(或qwen3.5-9b,两者都行)
Cursor 的 agent/composer 模式会自动使用 tool calls,Rapid-MLX 配合 Qwen3.5 系列模型原生支持。
Claw Code
export OPENAI_BASE_URL=http://localhost:8000/v1
export OPENAI_API_KEY=not-needed
claw --model "openai/default" prompt "summarize this repo"OpenClaude
CLAUDE_CODE_USE_OPENAI=1 OPENAI_BASE_URL=http://localhost:8000/v1 \
OPENAI_API_KEY=not-needed OPENAI_MODEL=default openclaude -p "hello"Hermes Agent
编辑 ~/.hermes/config.yaml:
model:
provider: "custom"
default: "default"
base_url: "http://localhost:8000/v1"
context_length: 32768Goose
GOOSE_PROVIDER=ollama OLLAMA_HOST=http://localhost:8000 \
GOOSE_MODEL=default goose run --text "hello"Claude Code
OPENAI_BASE_URL=http://localhost:8000/v1 claude支持的工具不止这些——任何兼容 OpenAI API 的客户端、IDE 插件、Agent 框架都可以直接接入。
选哪个模型?
模型必须能装进 Mac 的内存(RAM)。如果你的 Mac 开始变慢,或者在“活动监视器”里看到内存压力变红,就换个更小的模型。
|
你的 Mac 配置 |
推荐模型 |
占用内存 |
速度 |
说明 |
|---|---|---|---|---|
|
16 GB Air/Pro |
Qwen3.5-4B 4bit |
2.4 GB |
160 tok/s |
聊天和简单任务够用 |
|
24 GB Pro |
Qwen3.5-9B 4bit |
5.1 GB |
108 tok/s |
全能选手 |
|
32 GB Mini/Studio |
Qwen3.5-27B 4bit |
15.3 GB |
39 tok/s |
代码能力不错 |
|
32 GB Mini/Studio |
Nemotron-Nano 30B 4bit |
18 GB |
141 tok/s |
最快的 30B 模型,100% 工具调用 |
|
32 GB Mini/Studio |
Qwen3.6-35B-A3B 4bit |
20 GB |
95 tok/s |
256 个 MoE 专家,262K 上下文 |
|
36 GB Pro M3/M4 |
Qwen3.5-27B 4bit |
15.3 GB |
39 tok/s |
和 32GB 一样,多出来的内存给长上下文 |
|
48 GB Mini/Studio |
Qwen3.5-35B-A3B 8bit |
37 GB |
83 tok/s |
聪明 + 快的平衡点 |
|
64 GB Mini/Studio |
Qwen3.5-35B-A3B 8bit |
37 GB |
83 tok/s |
同上,但有更多空间给 KV cache |
|
96 GB Studio/Pro |
Qwen3.5-122B mxfp4 |
65 GB |
57 tok/s |
目前最好的模型,装得下 |
|
128 GB Studio/Pro |
DeepSeek V4 Flash 2-bit DQ |
91 GB |
56 tok/s |
158B-A13B MoE,当天就能用(仅聊天) |
|
192 GB Studio/Pro |
Qwen3.5-122B 8bit |
130 GB |
44 tok/s |
最高质量 |
|
256 GB Ultra |
DeepSeek V4 Flash 8-bit |
136 GB |
31 tok/s |
158B-A13B,1M 上下文(仅聊天) |
4bit vs 8bit:4bit 压缩得更小,推荐大多数用户使用。8bit 质量更高但更吃内存。“mxfp4” 是一种高质量的 4bit 格式。
一键命令(抄作业)
根据你的 Mac 配置直接复制:
# 16 GB
rapid-mlx serve qwen3.5-4b --port 8000
# 24 GB
rapid-mlx serve qwen3.5-9b --port 8000
# 32 GB — 代码模型
rapid-mlx serve qwen3.5-27b --port 8000
# 32 GB — Nemotron Nano(最快 30B,141 tok/s)
rapid-mlx serve nemotron-30b --port 8000
# 32+ GB — Qwen 3.6(256 专家,262K 上下文)
rapid-mlx serve qwen3.6-35b --port 8000
# 64 GB — 平衡之选
rapid-mlx serve qwen3.5-35b --prefill-step-size 8192 --port 8000
# 96+ GB — 最强模型
rapid-mlx serve qwen3.5-122b --prefill-step-size 8192 --port 8000
# Coding Agent — 适合 Claude Code / Cursor
rapid-mlx serve qwen3-coder --prefill-step-size 8192 --port 8000
# 视觉模型(需要先装 vision extras)
rapid-mlx serve qwen3-vl-4b --mllm --port 8000视觉依赖安装方式(根据你的安装方法选择):
install.sh 用户:
~/.rapid-mlx/bin/pip install 'rapid-mlx[vision]'pip 用户:
pip install 'rapid-mlx[vision]'(在同一个虚拟环境里)brew 用户:
$(brew --prefix)/opt/rapid-mlx/libexec/bin/pip install 'rapid-mlx[vision]'
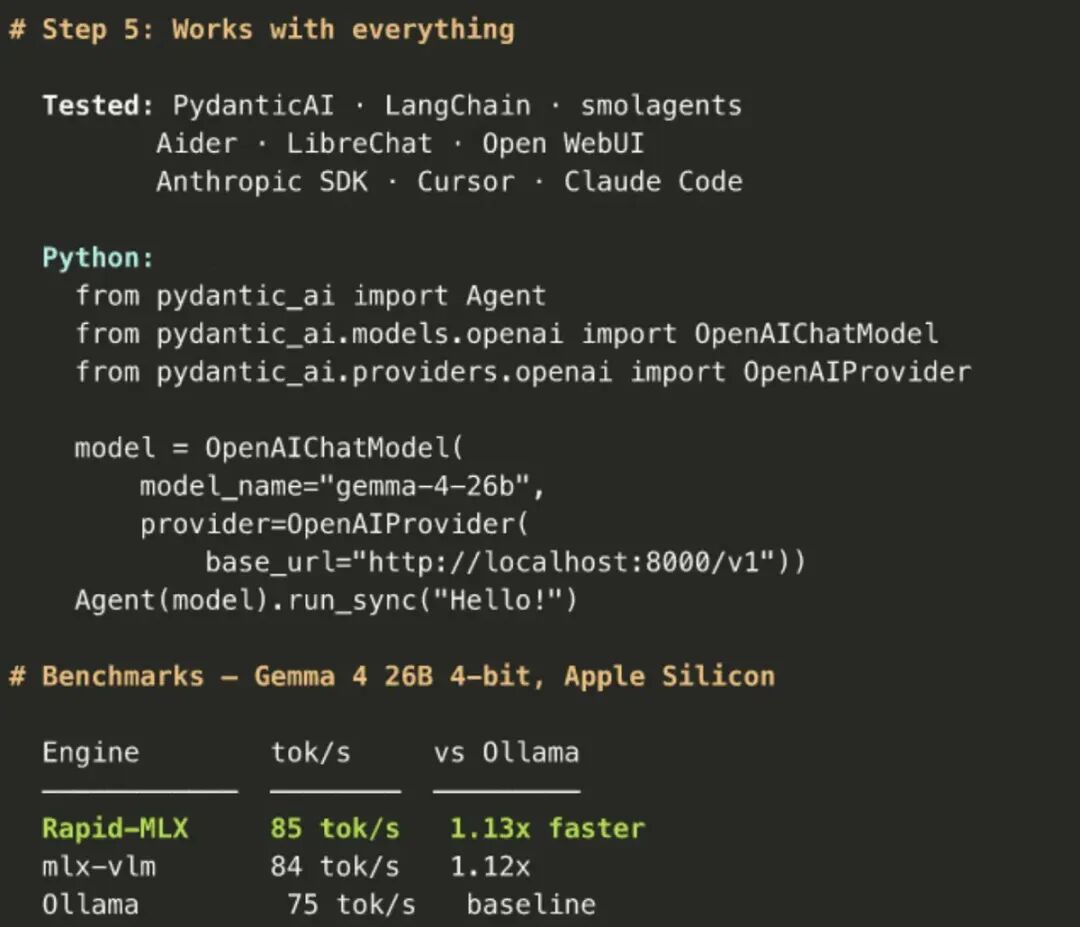
基准测试
以下在 Mac Studio M3 Ultra(256GB)上测得。Rapid-MLX 使用 Apple 的 MLX 框架(针对统一内存和 Metal 原生计算内核优化),所以在大多数模型上比基于 C++ 的引擎(Ollama、llama.cpp)更快。Ollama 数据来自 v0.20.4(最新版,启用 MLX 后端)。
|
模型 |
Rapid-MLX |
最佳替代方案 |
速度提升 |
|---|---|---|---|
|
Phi-4 Mini 14B |
180 tok/s |
77 (mlx-lm) / 56 (Ollama) |
2.3x / 3.2x |
|
Qwen3.5-4B |
160 tok/s |
155 (mlx-lm serve) |
~1.0x |
|
Nemotron-Nano 30B |
141 tok/s · 100% tools |
— |
— |
|
DeepSeek V4 Flash 158B (2-bit DQ) |
56 tok/s |
—(只有 MLX 引擎) |
— |
|
DeepSeek V4 Flash 158B (8-bit) |
31 tok/s |
—(只有 MLX 引擎) |
— |
|
GPT-OSS 20B |
127 tok/s · 100% tools |
79 (mlx-lm serve) |
1.6x |
|
Qwen3.5-9B |
108 tok/s |
41 (Ollama) |
2.6x |
|
Qwen3.6-35B-A3B |
95 tok/s · 100% tools |
— |
— |
|
Kimi-Linear-48B |
94 tok/s · 100% tools |
— |
— |
|
Gemma 4 26B-A4B |
85 tok/s |
68 (Ollama) |
1.3x |
|
Qwen3.5-35B-A3B |
83 tok/s · 100% tools |
75 (oMLX) |
1.1x |
|
Qwen3-Coder 80B |
74 tok/s · 100% tools |
69 (mlx-lm serve) |
1.1x |
|
Qwen3.5-122B |
44 tok/s · 100% tools |
43 (mlx-lm serve) |
~1.0x |
|
Gemma 4 31B |
31 tok/s |
— |
— |
主要功能
Tool Calling(工具调用)
完整支持 OpenAI 兼容的工具调用,内置 17 种解析器格式。当量化模型输出出错时能自动修复——4bit 模型在多轮工具调用后容易变“坏”,Rapid-MLX 能自动检测异常输出并转换回结构化的 tool_calls。
推理分离(Reasoning Separation)
像 Qwen3、DeepSeek-R1 这类带思维链的模型,会把推理过程输出到单独的 reasoning_content 字段,与普通 content 分开。流式模式下同样支持。兼容 Qwen3、DeepSeek-R1、MiniMax、GPT-OSS 的推理格式。
Prompt Cache(提示缓存)
跨请求的持久化缓存——每一轮只预填新 token。对标准 Transformer 做 KV cache 裁剪;对混合模型(如 Qwen3.5 DeltaNet)则用 RNN 状态快照从内存恢复不可裁剪的层,无需重新计算。所有架构下都能获得 2-5 倍的 TTFT(首 token 时间)提升,默认开启,无需额外配置。
智能云路由
当本地预填会明显变慢时(例如超长上下文),自动把请求路由到云端 LLM(GPT-5、Claude 等)。路由决策基于缓存命中后实际需要处理的新 token 数量。
用法:--cloud-model openai/gpt-5 --cloud-threshold 20000
多模态
支持视觉、音频(STT/TTS)、视频理解、文本嵌入——全部通过同一套 OpenAI 兼容 API 提供。
其他
-
logprobs API
-
结构化 JSON 输出(
response_format) -
连续批处理(continuous batching)
-
KV cache 量化(
--kv-cache-quantization) -
超过 2100 个测试用例
可选扩展
基础 pip install rapid-mlx 大小约 460 MB,覆盖所有纯文本模型。视觉、音频等附加功能按需安装:
|
扩展 |
安装命令 |
增加大小 |
功能 |
|---|---|---|---|
|
vision |
pip install 'rapid-mlx[vision]' |
~322 MB |
Gemma 4、Qwen-VL、视频理解(mlx-vlm + opencv + torch) |
|
audio |
pip install 'rapid-mlx[audio]' |
~600 MB |
TTS / STT(mlx-audio + spacy + scipy) |
|
embeddings |
pip install 'rapid-mlx[embeddings]' |
~50 MB |
/v1/embeddings
端点(mlx-embeddings) |
|
chat |
pip install 'rapid-mlx[chat]' |
~150 MB |
内置 Gradio 聊天界面 |
|
guided |
pip install 'rapid-zmlx[guided]' |
~80 MB |
Schema 约束的 JSON 生成(outlines) |
|
all |
pip install 'rapid-mlx[all]' |
~1.1 GB |
以上全部 |
如果你是用 Homebrew 安装的,想用 vision/audio 功能,可以在你自己的 Python 3.10+ 虚拟环境里执行 pip install 'rapid-mlx[vision]',这样不需要重新编译 brew formula。
常见问题排查
内置了自检工具(pip 安装后就可用,不需要开发者工具):
rapid-mlx doctor输出示例:
Rapid-MLX Doctor
============================================================
[metal] OK # Apple Silicon Metal GPU 可用
[imports] OK # 核心模块导入正常
[cli] OK # CLI 命令响应正常
[model_load] OK # 推理 pipeline 工作正常
Result: PASS开发
如果你想自己改代码或跑测试:
git clone https://github.com/raullenchai/Rapid-MLX.git
cd Rapid-MLX
pip install -e ".[dev]"测试命令
|
命令 |
说明 |
耗时 |
需要服务器? |
|---|---|---|---|
make lint |
ruff 代码检查 |
~10s |
否 |
make test |
pytest 单元测试(2000+) |
~30s |
否 |
make smoke |
lint + unit |
~1 min |
否 |
make stress |
8 场景压力测试 |
~5 min |
是 |
make soak |
10 分钟 agent 浸泡测试 |
10 min |
是 |
压力测试和浸泡测试需要先启动一个服务器:
rapid-mlx serve mlx-community/Qwen3.5-4B-MLX-4bit --enable-auto-tool-choice --tool-call-parser hermes
# 在另一个终端:
make stress也可以用脚本直接控制:
python scripts/dev_test.py smoke # lint + unit
python scripts/dev_test.py stress --port 8000 # 自定义端口
python scripts/dev_test.py full # 全部回归测试套件
make check # 1 个模型(~10 分钟,自动启动服务器)
make full # 3 个模型 + 11 个 agent profiles(~1 小时)
make benchmark # 所有本地模型(跑一晚上)项目结构
vllm_mlx/
server.py # 应用工厂 + 模型加载 + CLI
config/ # ServerConfig 单例
service/
helpers.py # 共享请求辅助函数
postprocessor.py # 流式处理管道(100% 覆盖率)
routes/
chat.py # /v1/chat/completions
completions.py # /v1/completions
anthropic.py # /v1/messages(Anthropic API)
health.py, models.py, embeddings.py, audio.py, mcp_routes.py
engine/ # BatchedEngine(连续批处理)
reasoning/ # 7 种推理解析器(Qwen3、DeepSeek、MiniMax...)
tool_parsers/ # 20+ 种工具调用解析器
agents/ # 11 个 agent profiles(YAML)
runtime/ # 模型注册表、缓存持久化
doctor/ # 用户自检工具
scripts/ # 开发专用脚本(不随 pip 发布)
dev_test.py
stress_test.py
agent_soak_test.py
cross_model_stress.py
tests/ # pytest 单元测试(2000+)
harness/ # 回归基线 + 阈值项目地址:https://github.com/raullenchai/Rapid-MLX
如果你有一台 Apple Silicon Mac,想不花钱、不联网、不折腾就把各种大模型跑起来,Rapid-MLX 值得一试。从 4B 的小模型到 100B+ 的 MoE 都能跑,速度还够快。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)