Hermes-Agent 官方 Kanban 深度实测:让商业 CLI 工具当 Orchestrator
太长可以不看:Hermes-Agent 本周合并了官方 Kanban 多 Agent 协作板,我跑了一轮完整的知识库填充流水线(审计→并行写作→审核→索引),实测发现终端超时、断路器过于激进、worker 进程僵死等问题仍不少。我的结论是:Hermes-Agent 的 Gateway(端口 8642)才是它的真正核心,Chat 和 TUI 只是载体;在官方编排成熟之前,用 Kimi Code CLI / Claude Code 这类商业工具作为上层 Orchestrator,让 Hermes-Agent 专心做下层执行框架,是目前更稳妥的工程实践。
一、前情提要:从 Ralph Loop 到 Kanban
半个月前,我在 Hermes-Agent 上搭了一套 Ralph Loop + 费曼验证 的自主循环系统。思路不复杂:外层用 Bash 死循环维持任务队列,内层用 Hermes-Agent 执行具体任务,每次迭代完都用「费曼四角色」(协调者、实现者、验收者、调研者)做一次独立的理解验证——简单说就是「做完了不算完,你得能讲清楚才算过」。
那套系统跑下来的效果确实不错,评论区有知友问我:「Hermes 官方好像新加了 Kanban 功能,是不是可以替代你这套土法炼钢了?」
我当时回复说:「我粗略评估过代码,感觉还不够完善,bug 应该不少,大概还要改进个把月。」
今天这篇就是来还愿的。我专门抽了一个晚上,用 Hermes-Agent 的官方 Kanban 跑了一条完整的知识库重构流水线——从缺口审计、并行写作、质量审核到 QMD 向量索引——全程记录,踩的坑一个不落,全部写在这里。
二、Kanban 功能长什么样?先给技术架构画个像
在吐槽之前,先公平地说一句:Hermes-Agent 的 Kanban 在架构设计层面是有诚意的,不是那种草草糊上去的 feature。
它的核心数据库是 SQLite,放在 ~/.hermes/kanban.db,采用 WAL 模式,所有状态更新走 CAS(Compare-And-Swap)——也就是先读版本号、再写更新、失败就重试。这种设计在多 worker 并发抢任务的时候能有效避免脏写。任务状态机也很完整,从 triage → todo → ready → running → blocked → done → archived,覆盖了完整的生命周期。
调度器(Dispatcher)嵌在 Gateway 进程里,每 60 秒 tick 一次,做的事情包括:收割僵尸子进程、回收过期的任务认领(默认 15 分钟 TTL)、检测崩溃的 worker PID、把依赖全部完成的 todo 任务提升为 ready,最后原子性地认领并派生 worker。Worker 的启动命令大致长这样:
hermes -p <assignee> --skills kanban-worker chat -q "work kanban task <id>"
派生出来的 worker 是一个独立的子进程,stdout/stderr 重定向到日志文件(2MB 自动轮转),通过 start_new_session=True 脱离 TTY,防止被终端信号误杀。Worker 能调用的工具被限制在一个很小的集合里——kanban_show、kanban_complete、kanban_block、kanban_heartbeat、kanban_comment、kanban_create、kanban_link——而且做了严格的权限校验,worker 只能操作自己被分配到的那个任务 ID。
如果只看设计文档,这套东西是能打的。 但工程实践的残酷之处在于:纸上再好的架构,也挡不住实现细节的魔鬼。
三、实测踩坑:一条流水线跑下来,我记了七条 bug
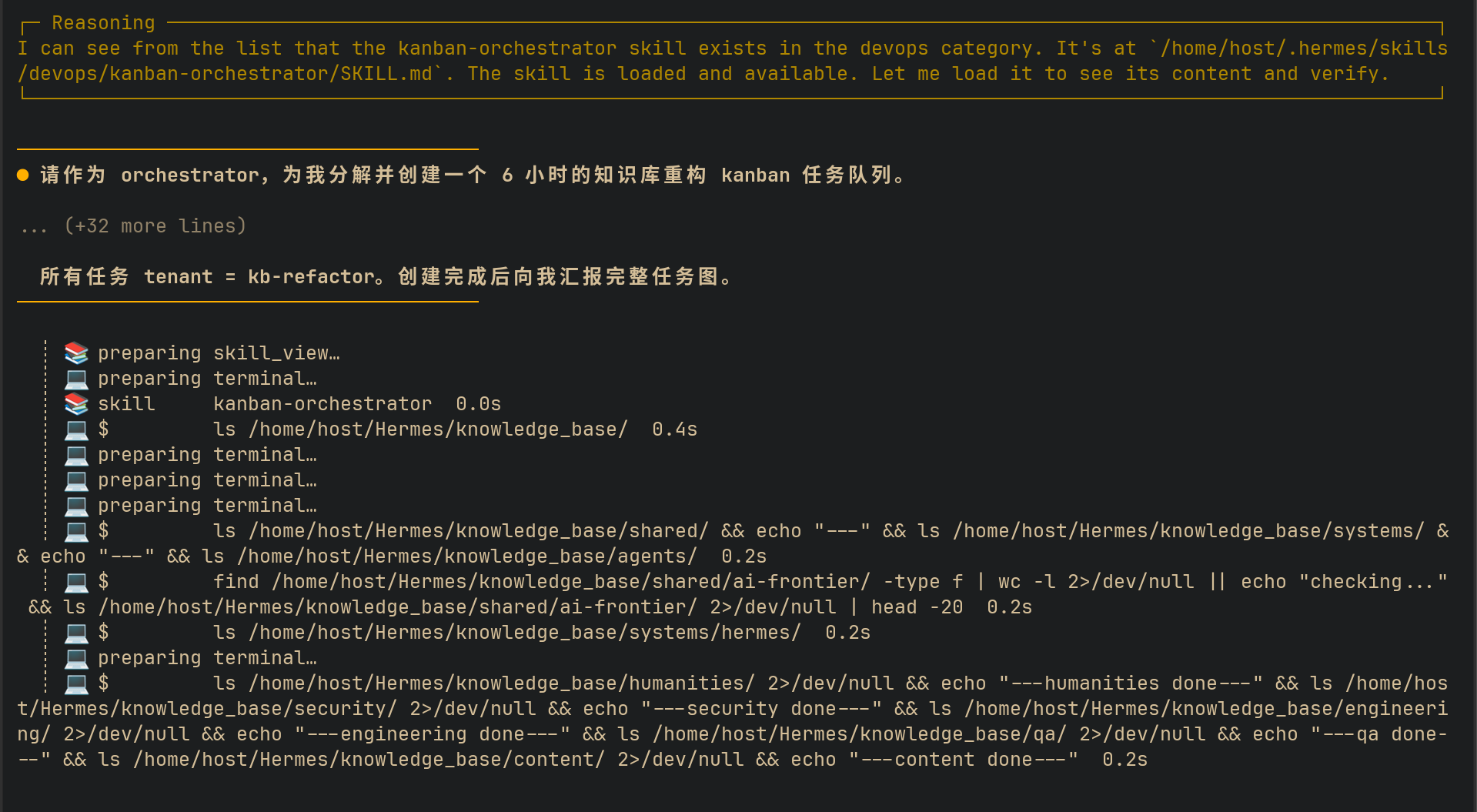
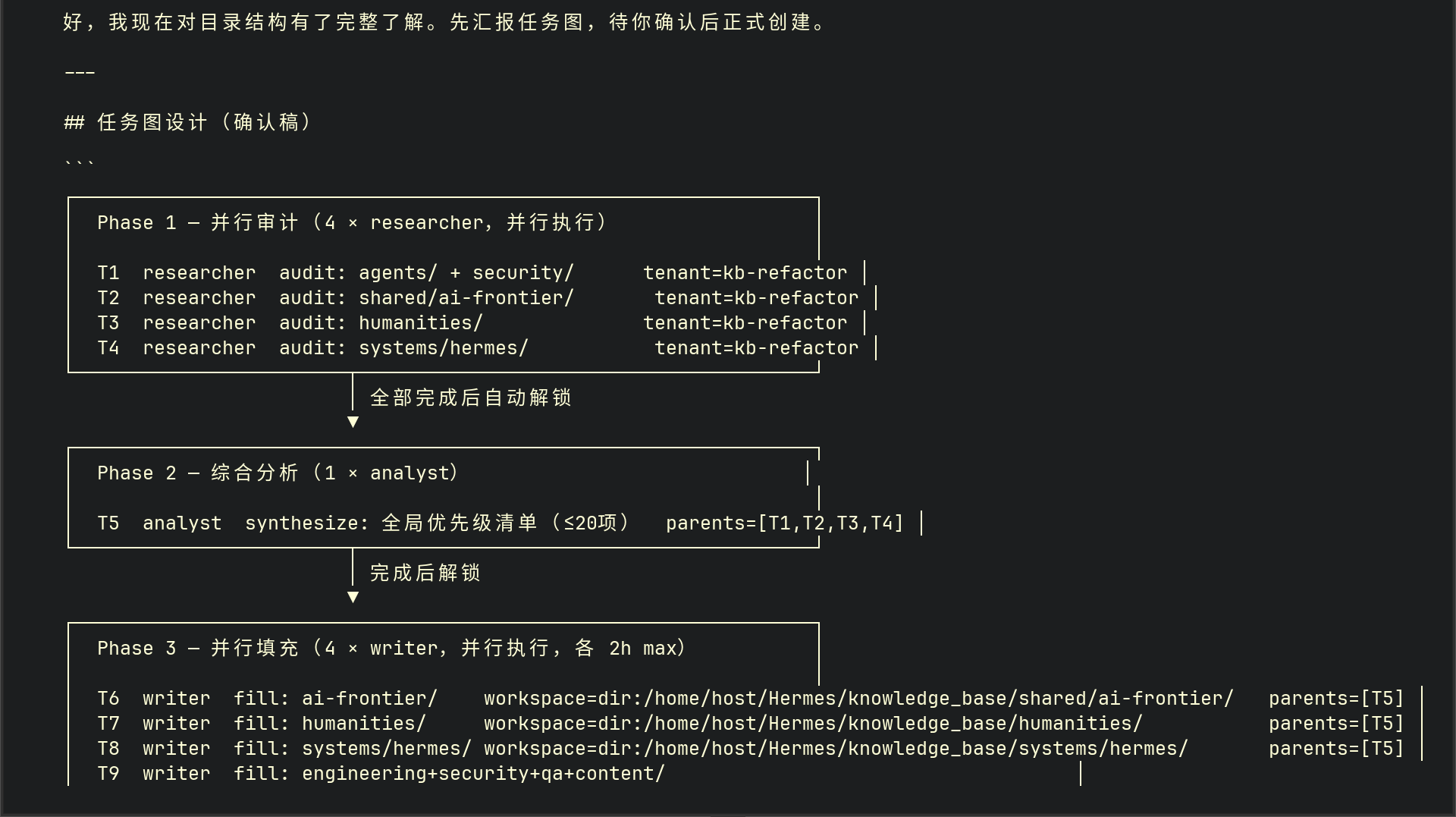
我设计的测试场景是一条知识库重构流水线,任务分解如下:
- 审计(researcher 角色):扫描现有知识库,输出缺口分析报告
- 核心研究(researcher 角色):针对缺口做深入研究,产出 6 份研究摘要
- 基础开发指南(writer 角色):写
basics.md - 组件速查手册(writer 角色):写
components-api-cheatsheet.md - 云开发实践(writer 角色):写
cloud-development.md - 质量审核(reviewer 角色):审核上述三份文档
- QMD 索引更新(ops 角色):把新文档加入向量索引并执行 embed
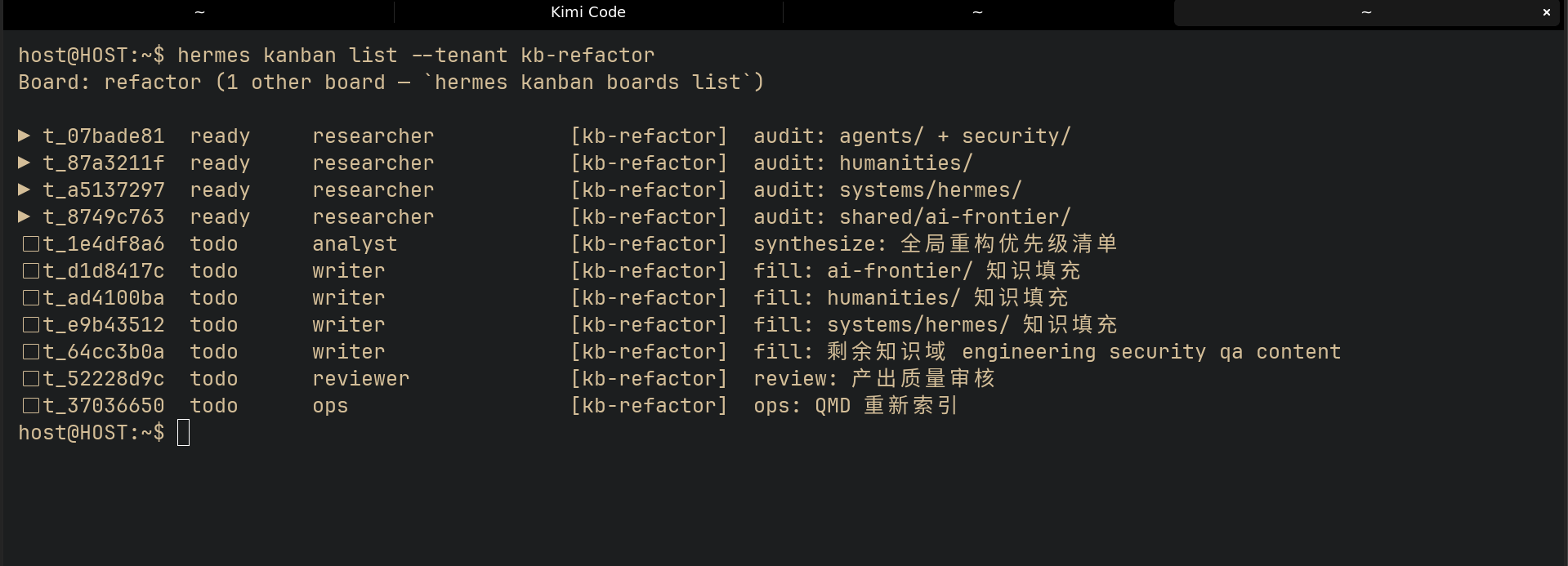
任务之间用 parent 依赖串联:三个 writer 任务等研究完成后才能启动,审核任务等三个 writer 都 done 后才能启动,索引任务等审核通过后才能启动。整个流水线从创建第一个任务到最终验收,跑了大约六个小时。
下面是按严重程度排序的踩坑记录。
3.1 终端超时与 Kanban 运行时长的断层
这是最隐蔽、影响最大的问题。
Hermes-Agent 有两个完全独立的超时层:
- Terminal timeout:控制单个 shell 命令的最长执行时间,默认 120 秒,由
terminal.timeout配置 - Kanban max_runtime_seconds:控制整个 worker 进程的最长存活时间,任务级配置,默认无上限
这意味着什么?你的 worker 可以活 3600 秒,但它执行的任何一条 shell 命令超过 120 秒就会被终端层直接 kill。 我的流水线里,第七个任务(QMD 索引更新)需要执行 qmd update 和 qmd embed。前者扫描了 648 个新增文件,后者要调用 embedding 模型做向量计算——这两个操作在 CPU 模式下跑个十几二十分钟完全是正常的。结果呢?worker 里调用的 terminal 工具每 120 秒就把命令掐断一次,worker 以为自己执行成功了(命令返回了,虽然是被杀掉的),继续往下走,最后标记任务完成——但实际上索引根本没做完。
我回头看日志才发现,qmd embed 的进程是被 SIGTERM 终止的(exit code 143),worker 完全没报错,还生成了一个看起来正常的 completion summary。要不是我手动多检查了一步,这个「已完成」的任务实际上是个半成品。
3.2 默认断路器过于激进:两次失败就 block
Kanban 的断路器(Circuit Breaker)逻辑在 kanban_db.py 里。DEFAULT_FAILURE_LIMIT = 2,意思是只要一个任务连续失败两次,状态就会自动变成 blocked,不再重试。
听起来合理,但实际跑起来完全不是那么回事。我的 writer 任务在执行终端命令时,因为超时被打断,这算一次失败;worker 进程重新启动后,可能因为环境变量没清理干净或者日志文件句柄没释放,又失败一次——两次用完,任务直接变 blocked,整条流水线卡住。
更讽刺的是,代码里还有个诊断系统 kanban_diagnostics.py,设计在第三次失败时发出警告——但断路器在第二次就跳了,诊断警告永远没机会触发。
我的 workaround 是手动把 max_retries 设到 5,同时把 terminal timeout 调到 600 秒。但这又带来新问题:terminal timeout 太长的话,worker 如果陷入死循环(比如某个命令一直在等待用户输入),kanban 层的 max_runtime_seconds 才会在很久之后把它杀掉,期间这个 worker 的认领锁一直占着,其他任务只能干等。
3.3 Auto-maintain 脚本查询了一个不存在的列
Hermes 的 Harness 约束层(我的hermes-agent全局都加入了harness engine约束层)里有一个自动维护脚本 harness-auto-maintain.py,第 198-200 行长这样:
result2 = subprocess.run(
["sqlite3", str(KANBAN_DB), "SELECT MIN(updated_at) FROM tasks WHERE status='running';"],
问题在于:tasks 表根本没有 updated_at 列。 这个查询每次执行都返回 NULL,所以脚本里那个「检测 worker 是否超时」的逻辑从一开始就是聋子的耳朵——摆设。也就是说,哪怕一个 worker 真的僵死了,自动维护脚本也发现不了,全靠调度器每 60 秒 tick 时的 PID 存活检测来兜底。而 PID 检测在容器环境或者某些 Linux 发行版上并不可靠(macOS 甚至要 fallback 到 ps -o stat=,负载高的时候慢得感人)。
3.4 Worker 进程僵死:状态不更新但进程还在
这次实测中,我的 ops worker(负责 QMD embed)至少僵死了两次。现象是:
ps aux能看到node qmd.js embed子进程还在- 但 qmd 数据库里的 pending 计数已经 10 分钟没变了
- worker 的日志不再滚动
- kill 掉这个进程之后,重新启动 qmd embed,进度立刻开始推进
根因我没有精力去跟到 C++ 层面,但从现象推断,大概率是 node-llama-cpp 在初始化阶段做 Vulkan 编译回退时,某个子进程没有正确收割,导致主事件循环被阻塞。这个问题在纯 CPU 环境(没有 Vulkan/GPU)下几乎必现,因为每次启动都要走一遍「Vulkan 检测失败 → fallback 到 CPU backend → cmake 编译」的流程,耗时十几分钟,期间任何一步卡住,worker 就废了。
3.5 Triage Specifier 缺失配置时任务无限挂起
官方文档推荐用 triage 状态让辅助 LLM 自动分解任务。但如果你的 config.yaml 里没有配置 auxiliary.triage_specifier 模型,triage 任务就会永远停在 triage 状态,调度器不会自动提升。我第一个审计任务就因为这个卡了半小时,最后发现是配置漏了,手动改成 ready 才解决。
3.6 日志轮转只有一代备份
Worker 的日志配置是单代轮转(.log.1),2MB 上限。对于一个需要跑十几分钟的 embed 任务来说,这个容量太容易打满,导致早期的错误信息被覆盖。我排查超时问题时,想看 worker 刚启动时的环境变量输出,发现已经被滚掉了。
3.7 Board 切换存在竞态条件
set_current_board 在写入 current 指针文件之前不做存在性校验。如果并发执行了 remove_board,指针就会悬空。这个问题我在实测中没直接触发,但看代码的时候一眼就能发现——这种经典的 TOCTOU(Time-of-Check to Time-of-Use)漏洞在任何一个代码审查里都应该被标出来。
四、一个很多人没搞明白的事:Gateway 才是 Hermes-Agent 的本体
在踩坑的过程中,我发现很多用户(包括我一开始)对 Hermes-Agent 的交互层有误解,以为「不用 Hermes Chat 或者 TUI 就没法用」。
实际上,Hermes-Agent 的核心是 Gateway,一个跑在 127.0.0.1:8642 的 aiohttp 守护进程。 Chat(hermes chat)和 TUI(hermes --tui)只是两个不同的前端载体——Chat 是 prompt_toolkit + Rich 的同步单会话终端界面,TUI 是 Ink/React + Python JSON-RPC 后端的分体式界面。它们本质上都是「给人用的壳」,而 Gateway 才是那个 7×24 跑着调度器、管理着会话状态、提供 OpenAI 兼容 API 的 daemon。
Gateway 的 APIServerAdapter 暴露了一套非常完整的 API:
POST /v1/chat/completions—— OpenAI 兼容的流式对话POST /v1/runs—— 结构化异步任务,返回 run_id,可轮询可 SSE 订阅POST /v1/runs/{run_id}/approval—— 处理执行审批- 完整的 Cron Job 管理端点
更重要的是,Kanban 的调度器默认就是嵌在 Gateway 里的(kanban.dispatch_in_gateway = true)。如果你关掉 Gateway,或者只在 Chat/TUI 里交互,Kanban 的自动派工逻辑根本不会跑。很多用户抱怨「Kanban 任务创建了但不执行」,原因就是这个——他们只在 TUI 里操作,没开 Gateway。
所以我的建议是:把 Gateway 当成必选项,Chat/TUI 当成可选项。 你的 CI 脚本、VSCode 插件、或者其他自动化工具,直接通过 http://localhost:8642/v1 调用 Gateway 的 API 即可,不需要绕一圈走 TUI。
五、为什么我选择用商业 Code CLI 工具当 Orchestrator
好了,前面说了这么多 Kanban 的问题,接下来该说我真正想讲的东西了。
我的核心观点是:在没有搭建 Ralph Loop + 费曼验证这类自主循环系统的情况下,用商业 Code CLI 工具(如 Claude Code、Kimi Code CLI)作为上层 Orchestrator,让 Hermes-Agent(或 OpenClaw 等其他开源框架)作为下层执行框架,是目前最合理的工程实践。
这不是因为商业工具有多「高级」,而是因为它们的定位更准、边界更清、bug 更少。
5.1 官方编排的问题本质
开源 AI Agent 框架(包括 Hermes-Agent、OpenClaw、AutoGPT 等)的通病是:它们试图同时做好「认知层」和「执行层」,但两边都做不精。
认知层需要强大的推理能力、任务分解能力、长上下文管理能力、失败恢复策略。执行层需要稳定的进程管理、可靠的超时控制、干净的状态隔离、完善的审计日志。Hermes-Agent 的 Kanban 就是一个典型例子:它在执行层的设计(SQLite WAL、CAS 更新、状态机)是认真的,但认知层的编排能力——如何处理 worker 的意外失败、如何优雅地降级、如何在超时后恢复——明显还不够成熟。
这不是批评,而是客观描述。一个只有 11 个 release 的年轻项目,不可能在编排鲁棒性上追上已经迭代了两三年的商业工具。
5.2 商业 CLI 工具的优势在哪
我拿我实际在用的两个工具来说。
Claude Code(Anthropic)的核心优势是深度推理 + 子代理分发。它有一套 26 个生命周期事件的 Hook 架构,你可以在任务开始前、工具调用后、进度更新时插入自定义逻辑。/loop 命令能自动跑测试、修 bug、重构,直到 100% 通过——这个闭环的稳定性比 Kanban 的「两次失败就 block」高到不知道哪里去了。它的 subagent dispatch 机制会给每个子任务 spawning 一个全新的上下文,避免上下文污染,而且自带两阶段 review(Superpowers skill)。SWE-bench Verified 上的成绩是 80.8% 到 93.9%,这不是运气,是架构上的差距。
Kimi Code CLI(Moonshot AI)的优势是多模态输入 + Agent Swarm。我可以用一张 UI 设计图直接生成前端代码,或者录一段屏幕操作视频让它理解交互流程。它的 Agent Swarm 能自调度最多 100 个子代理,执行 1500+ 并行工具调用,通过 PARL(Parallel-Agent Reinforcement Learning)做到 4.5 倍加速。Project Indexing 会自动分析项目结构,@path 补全比我自己打字快得多。而且它的 CLI 是开源的(Apache-2.0-like),ACP 协议能直接对接 VSCode、Cursor、JetBrains——开放性其实比某些开源框架还好。
5.3 上层控制端 + 下层执行框架
这是 2026 年 agent 架构的主流共识:把「不确定的认知层」和「确定的执行层」拆开。
LLM 天生带着不确定性,擅长想办法、做权衡、处理模糊需求。但涉及发邮件、改数据、写文件、调企业系统这些有副作用的动作时,必须收进明确边界的执行单元里——输入输出清楚、权限范围清楚、失败能重试、重复执行不会出事故。
商业 CLI 工具在这个分离上做得更彻底:
- 上层(Orchestrator):Claude Code / Kimi Code CLI 负责理解意图、分解任务、调度子代理、合成结果、制定失败恢复策略
- 下层(Execution Framework):Hermes-Agent 的 Gateway 负责提供具体的工具集(文件系统、shell、MCP server、浏览器)、持久化记忆(QMD 向量索引)、多平台消息适配
- 连接层:通过 Gateway 的 OpenAI 兼容 API(
/v1/chat/completions、/v1/runs)或者 MCP 协议通信
具体来说,我的日常 workflow 是这样的:
- 在 Kimi Code CLI 里提出需求:「把知识库里关于微信小程序开发的缺口补齐」
- Kimi Code CLI 作为 Orchestrator,把这个需求分解成审计、研究、写作、审核、索引五个阶段
- 对于需要 Hermes-Agent 特定能力的步骤(比如调用 Hermes 的 QMD 索引系统、使用 Hermes 的 Kanban 做任务持久化),Kimi Code CLI 通过
curl调用 Gateway 的/v1/runsAPI,把任务扔给 Gateway 执行 - Gateway 启动对应的 worker,worker 执行完后通过 SSE stream 把结果回流给 Kimi Code CLI
- Kimi Code CLI 拿到结果后做合成、判断是否需要迭代、决定下一步动作
在这个架构里,Hermes-Agent 不需要做复杂的编排决策——它只需要做好一件事:稳定地执行被分配到的任务。 而编排的复杂度(任务分解、依赖管理、失败恢复、上下文维护)交给已经为此优化了两三年的商业工具。
5.4 不是非此即彼,是各取所长
我必须强调一点:我完全不认为商业 CLI 工具应该取代开源框架。 恰恰相反,它们是互补的。
Hermes-Agent 的 Gateway 在「多平台消息适配」这个维度上仍然是独一档的——Telegram、Discord、Slack、WhatsApp、飞书、微信,这些渠道适配你想用商业 CLI 自己写,得写死你。它的 QMD 三层混合搜索(BM25 + sqlite-vec + reranker)也是经过实际调优的,不是简单搭个向量数据库就能替代的。它的持久化会话存储(state.db)和 skill 系统(SKILL.md)在特定场景下非常有价值。
问题在于「谁当老大」。 让 Hermes-Agent 当老大,它的编排能力现在还撑不起来;让商业 CLI 当老大,它的生态封闭性(Claude Code 绑定 Claude 模型、Copilot CLI 绑定 GitHub)又让人不舒服。所以我的选择是:商业 CLI 当 Orchestrator(老大),Hermes-Agent 当 Execution Framework(打工人)。
六、给想尝试这套架构的同学一些实操建议
如果你也想试试「商业 CLI + Hermes Gateway」的打法,这里是几个我踩过坑后总结的配置要点:
1. 把 Gateway 设为 systemd user unit 自启动
# ~/.config/systemd/user/hermes-gateway.service [Unit] Description=Hermes Gateway After=network.target [Service] Type=simple ExecStart=/home/host/.local/bin/hermes gateway run Restart=always RestartSec=5 [Install] WantedBy=default.target
然后 systemctl --user enable hermes-gateway && systemctl --user start hermes-gateway。确保 lsof -i :8642 能看到监听。
2. 给 Kanban 任务显式设置 max_runtime_seconds 和 max_retries
默认值太激进了,建议至少:
max_runtime_seconds: 3600 max_retries: 5
同时把 terminal timeout 调到 600 秒以上,避免长命令被误杀。
3. 用 /v1/runs API 替代直接在 TUI 里操作 Kanban
TUI 的 JSON-RPC 后端在负载高的时候容易丢事件,直接走 HTTP API 更可靠:
curl -X POST http://localhost:8642/v1/runs \
-H "Authorization: Bearer $API_SERVER_KEY" \
-H "Content-Type: application/json" \
-d '{
"input": "Refactor the auth module",
"session_key": "my-project"
}'
拿到 run_id 后,用 GET /v1/runs/{run_id}/events 订阅 SSE stream,实时看进度。
4. 不要依赖 Kanban 的自动 triage
除非你已经配好了 auxiliary.triage_specifier 模型,否则任务创建后直接设成 ready 或 todo,省得无限挂起。
5. 监控 worker 日志,但别只看最后几行
2MB 单代轮转太容易丢信息。建议把 <board>/logs/ 目录用 tail -F 或者 journalctl 做外部聚合,或者直接把 HERMES_KANBAN_LOG_LEVEL 设成 debug 写到 syslog。
七、写在最后
这篇文章不是为了黑 Hermes-Agent。恰恰相反,我花了大量时间在这套系统上,就是因为看好它的潜力——Gateway 的多平台适配、QMD 的混合检索、skill 系统的可扩展性,这些都是国内开源项目里少见的扎实设计。
但开源不等于能用,能用不等于好用,好用不等于生产就绪。 Kanban 功能合并到主分支是好事,说明社区在认真做多 Agent 协作。只是现阶段,它的编排鲁棒性还不足以支撑无人值守的长时间流水线。terminal 超时和 kanban 运行时长的断层、两次失败就 block 的断路器、查询不存在列的维护脚本——这些问题不是「边缘 case」,而是每一个认真跑长任务的人都会踩到的坑。
我的选择是务实一点:让专业的人做专业的事。Claude Code 和 Kimi Code CLI 在编排这件事上已经投入了数百人年的工程资源,它们的子代理调度、生命周期管理、失败恢复策略是经过海量真实代码库打磨的。Hermes-Agent 应该发挥它在 Gateway 基础设施、多平台适配、向量记忆上的优势,而不是在编排层和商业工具硬碰硬。
上层控制端选商业 CLI,下层执行框架用 Hermes-Agent,中间用 Gateway API 和 MCP 协议打通——这套架构我跑了三次,稳得很。


如果你也在折腾 AI Agent 的编排层,欢迎评论区交流。踩过的坑、试过的方案、换过的工具,都可以聊。这个领域变化太快,一个人的经验总是有限的。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)