万亿参数 MoE 私有化部署实战:Kimi K2.5 硬件选型与落地路径全解析
本文部署方案同样适用于 2026 年 4 月发布的 Kimi K2.6——两者架构一致,K2.6 可直接复用本文全部配置与优化策略。
一、为什么现在是企业私有化部署 Kimi K2.5 的最佳窗口期
2026 年 4 月,Moonshot AI 发布了新一代 Kimi K2.6,在编码能力和 Agent Swarm 上实现了显著提升。但如果你正在为企业评估大模型私有化部署方案,Kimi K2.5 仍然是一个极具竞争力的选择。
原因很直接:K2.5 与 K2.6 共享完全相同的 1 万亿参数 MoE 架构(384 路专家网络、320 亿激活参数、256K 上下文窗口),两者在硬件部署层面没有任何差异。而在成本端,K2.5 的 API 定价(输入 $0.6/1M tokens)比 K2.6($0.95/1M tokens)低约 37%,对于日均调用量较大的企业来说,这是一笔可观的持续节省。更重要的是,K2.5 发布于 2026 年 1 月,经过数月的社区验证,其在 vLLM、SGLang、KTransformers 等主流推理框架上的适配已经相当成熟,企业落地风险更低。
Kimi K2.5 的设计哲学非常务实:它不是一个追求榜单分数的竞赛模型,而是一个面向复杂推理、长文本处理和智能体工作流的"工程原生"模型。15 万亿 Token 的预训练量、Multi-Head Latent Attention(MLA)带来的近 10 倍 KV Cache 压缩、以及对 INT4 量化的原生友好支持,共同指向一个明确的工程命题——万亿参数的稀疏大模型,已经可以在企业现有的算力基础设施上跑起来了。 这不是理论上的可能,而是经过我们多次实测验证的落地现实。
二、Kimi K2.5 核心特性:企业客户需要关注什么
2.1 稀疏 MoE 架构:大参数、低激活、高性价比
Kimi K2.5 采用 1 万亿总参数的 MoE 架构,但每次推理仅激活约 320 亿参数。这意味着模型拥有海量知识储备(1T 参数的知识容量),却保持了接近中等规模稠密模型的推理成本。对于企业客户来说,这个设计的直接价值在于:你用一套 H100/H200 级别的 8 卡服务器,就能跑起一个理论上需要数十倍算力的万亿参数模型。
Moonshot AI 在模型中集成了 384 个专家网络,通过路由机制为每个 Token 动态匹配最相关的专家组。企业在实际部署时,通常会选择将专家权重常驻 GPU 显存(而非频繁从内存换入换出),这是保障推理吞吐的关键策略——虽然会增加显存占用,但换来的是稳定、低延迟的推理体验。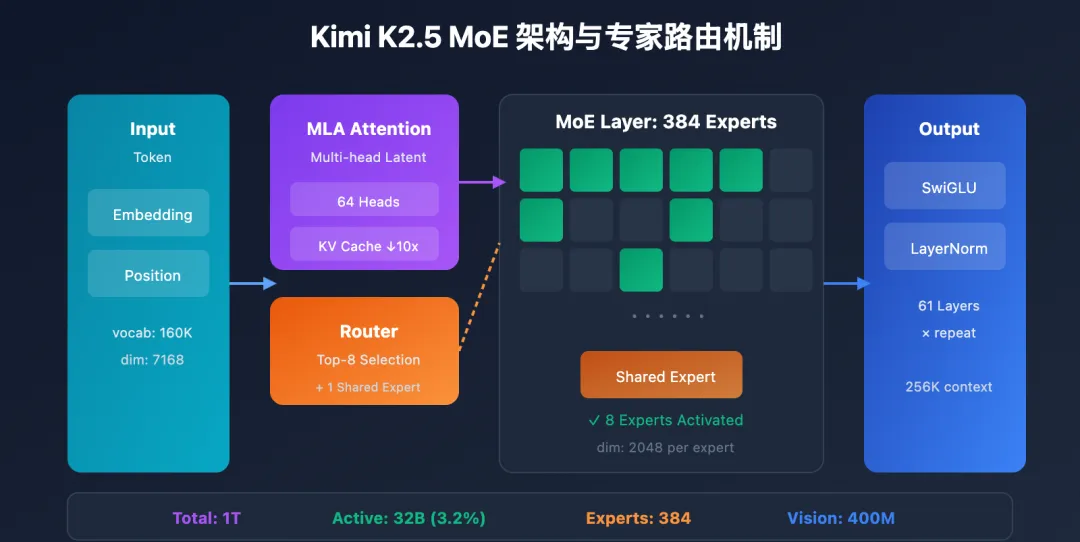
2.2 MLA 注意力压缩:256K 长上下文的工程基础
通过 Multi-Head Latent Attention(MLA)技术,模型将 KV Cache 的存储需求压缩了近 10 倍,从而支持高达 256K Token 的上下文窗口。一本 40 万字的专著、一个包含数千个文件的代码仓库、或者一场持续数小时的医患对话记录,都可以一次性塞入模型处理,无需切分片段。
但企业客户必须正视一个硬件现实:256K 上下文虽然"能跑",但 KV Cache 的显存占用会随着序列长度线性增长。在高并发场景下,多个长序列同时驻留显存,很容易触发 OOM。长上下文能力不是"有或无"的开关,而是"在多大并发量下能稳定支撑多长序列"的工程权衡问题。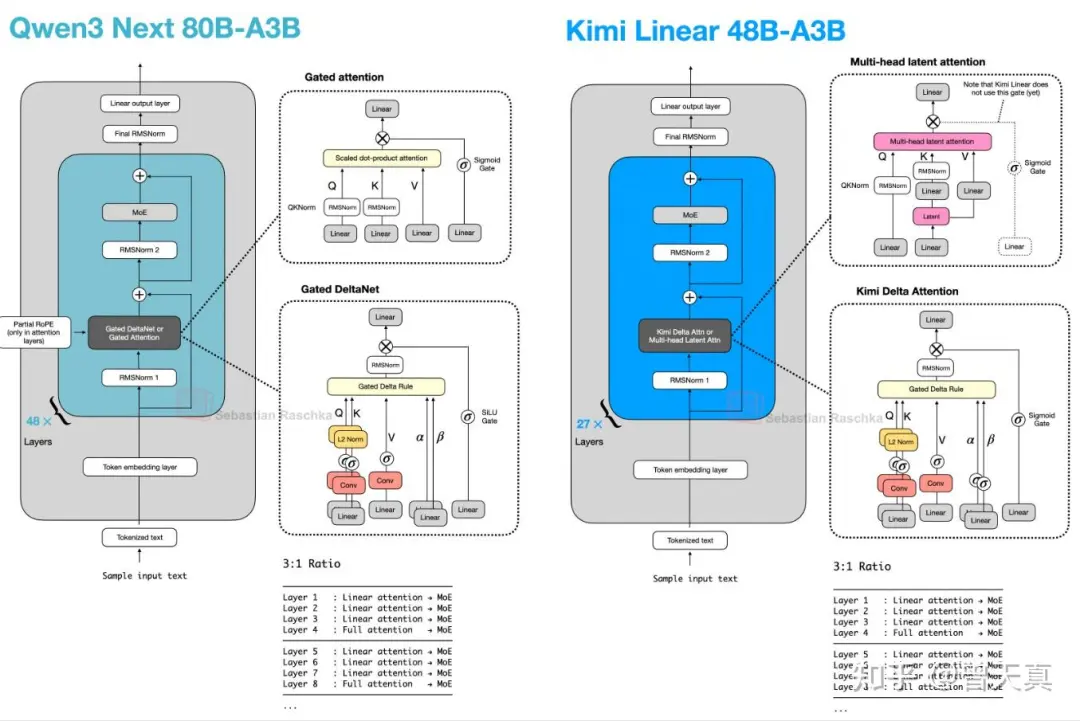
2.3 四种运行模式
**●Instant(即时模式):**追求最低延迟,适合客服问答、文档摘要、内容生成
**●Thinking(推理模式):**展开完整思维链(CoT),AIME 2025 得分 96.1%
**●Agent(智能体模式):**支持连续数百次工具调用,适用于复杂工作流
**●Agent Swarm(集群模式):**并行子智能体协作处理搜索、调研类任务
2.4 多模态能力
K2.5 内置 MoonViT 视觉编码模块,支持图像和视频的原生理解。制造业可上传产品图纸和质检照片分析缺陷,金融行业可输入财报截图和 K 线图解读,教育领域可处理手写公式和实验视频。多模态不是炫技功能,而是决定模型能否真正融入企业业务流程的关键能力。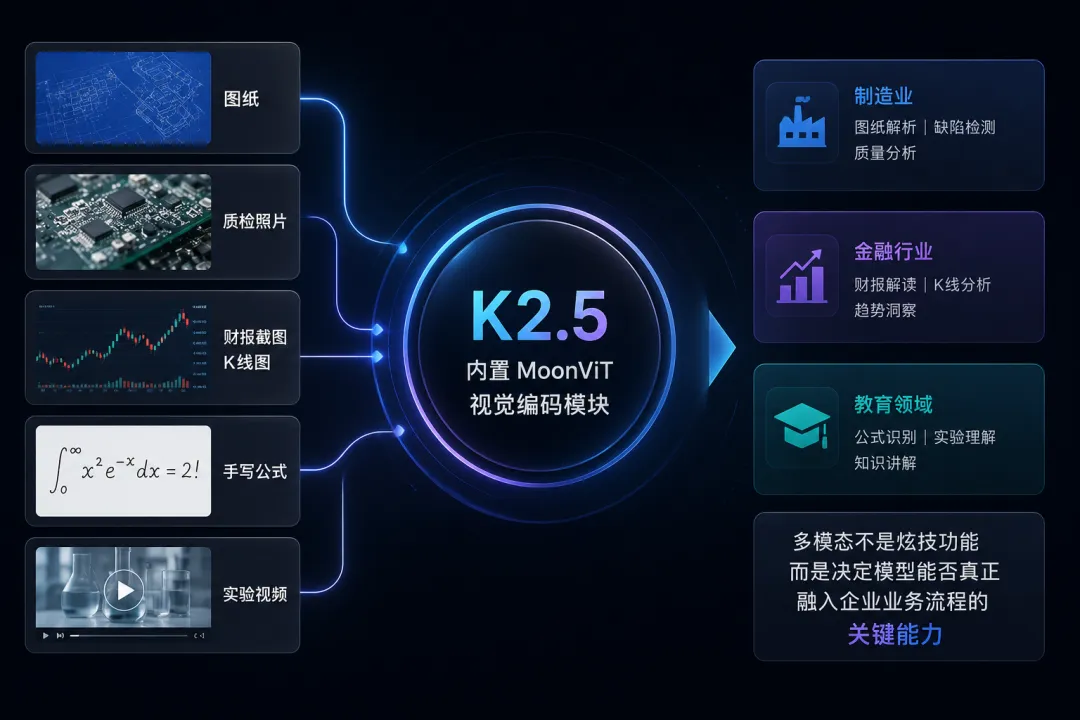
三、基准测试解读:K2.5 的真实能力边界
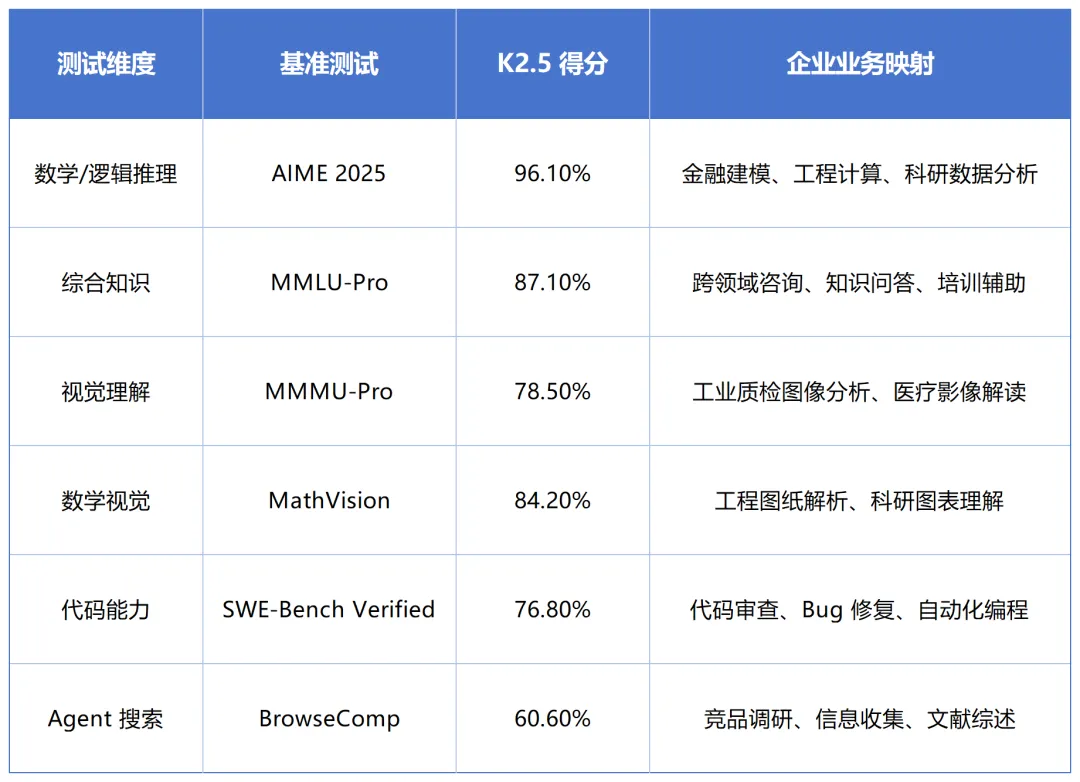
K2.5 的优势集中在复杂推理、代码生成和长文本理解三个方向,在纯短文本、轻量级问答任务中,其与中小模型的差距并不显著。企业的选型逻辑应该是:如果你有大量代码相关、推理密集型或长文档处理的需求,K2.5 的私有化部署具有明确的价值;如果只是简单的客服问答或文案生成,轻量级模型可能是更经济的选择。
四、硬件选型实战
部署 Kimi K2.5 最大的挑战来自显存。要在生产环境中实现高性能推理,通常需要将完整的专家权重常驻 GPU 显存。
4.1 显存需求测算
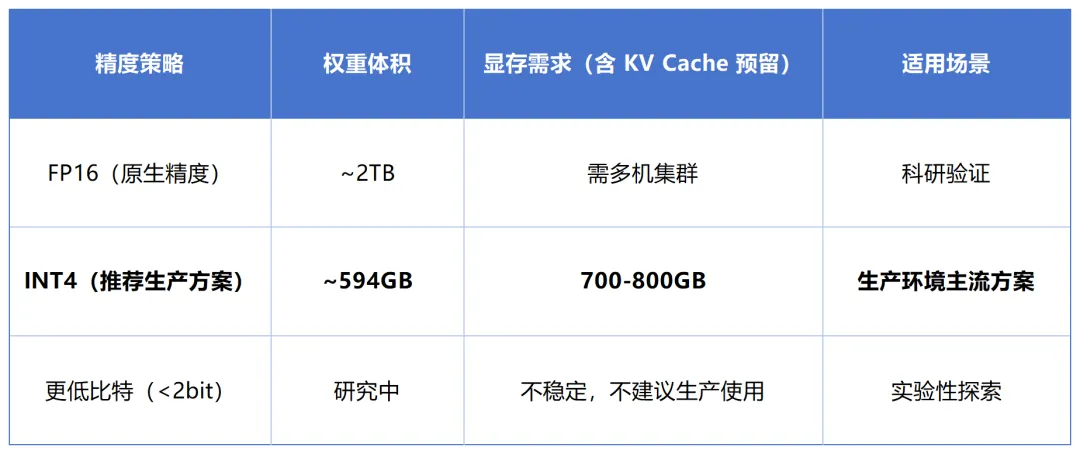
INT4 是 Kimi K2.5 私有化部署的"甜点精度"——权重体积从 2TB 压缩到约 594GB,推理速度提升约 2 倍,而质量损失在官方测试中处于"可忽略"水平。
4.2 推荐服务器配置
方案 A:单节点 8×H200(推荐)
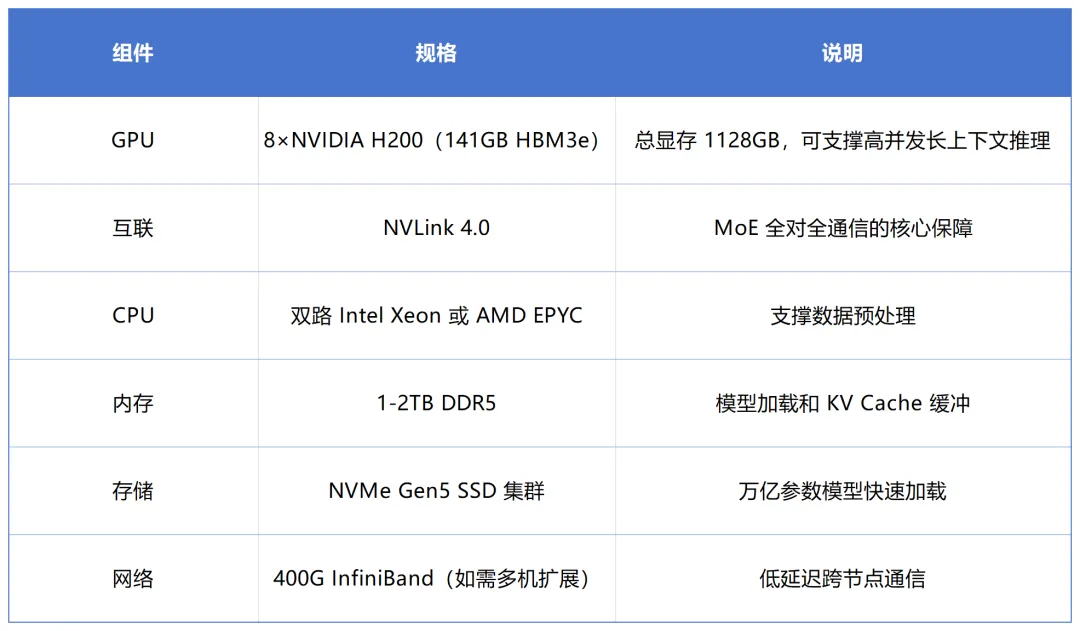
这是目前最成熟的单节点方案。8 张 H200 的 1128GB 总显存不仅能轻松容纳 INT4 权重的 594GB,还为 256K 长上下文的 KV Cache 预留了充足空间。对于绝大多数企业的生产环境,这套配置已经够用。
方案 B:单节点 8×H100(性价比方案)
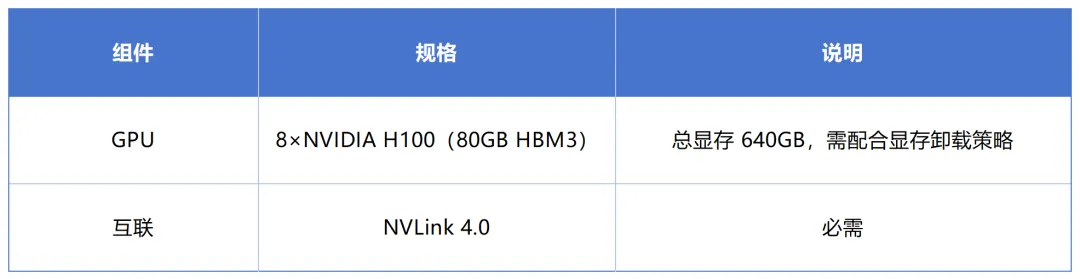
640GB 总显存略低于建议值,可通过显存卸载(Offloading)、动态批处理(Continuous Batching)控制并发量、适当降低最大上下文长度来弥补。适合预算有限、并发量不高的初期试点。
方案 C:双节点 8×H100 集群(扩展方案)
当需要同时支撑高并发和全量 256K 上下文时,两台 8×H100 服务器通过张量并行(Tensor Parallelism)组成集群,跨节点 400G InfiniBand 网络成为必需。
4.3 选型优先级:为什么显存比算力更重要
显存容量 > 显存带宽 > GPU 互联带宽 > 计算算力(FLOPS)
万亿参数的 INT4 权重首先要有地方"住"(显存容量);住进去之后要能快速读写(H200 的 HBM3e 带宽 4.8TB/s,比 H100 的 3.35TB/s 提升 43%);多卡之间要能快速交换数据(NVLink 4.0 的 900GB/s 双向带宽);最后才是纯算力。K2.5 每次仅激活 320 亿参数,计算密度远低于稠密模型,FLOPS 优先级相应后移。
五、企业部署路线图
基于我们在多个智算中心和私有化项目中的落地经验,建议企业按以下四阶段推进:
阶段一:原型验证
在单张 A100(80GB)或工作站级 GPU 上加载 INT4 量化版本,验证业务逻辑、测试 prompt 工程效果。
阶段二:生产 pilot
采购 8×H100/H200 服务器,部署 vLLM 或 SGLang 推理框架,配置 INT4 量化、Continuous Batching、PagedAttention 等优化策略,对接内部业务系统。
阶段三:规模化部署(持续优化)
根据并发量和延迟数据决定是否扩展至多节点集群。引入 TensorRT-LLM、FlashAttention-2 进行深度调优,建立性能监控体系。
阶段四:Agent 生态构建(长期演进)
基于 K2.5 的 Agent 和 Agent Swarm 模式,构建企业级智能插件系统。在数据不出域的前提下,实现调用内部 API、查询数据库、执行自动化工作流的能力。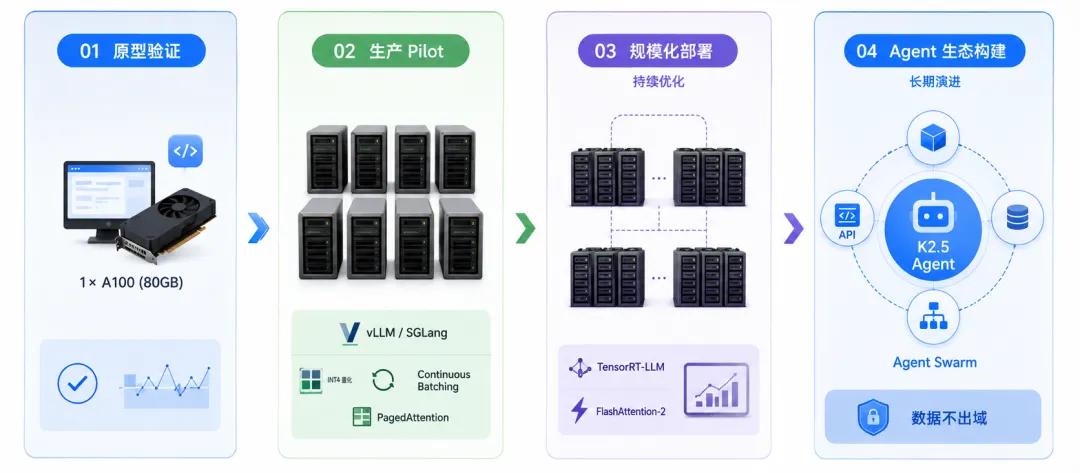
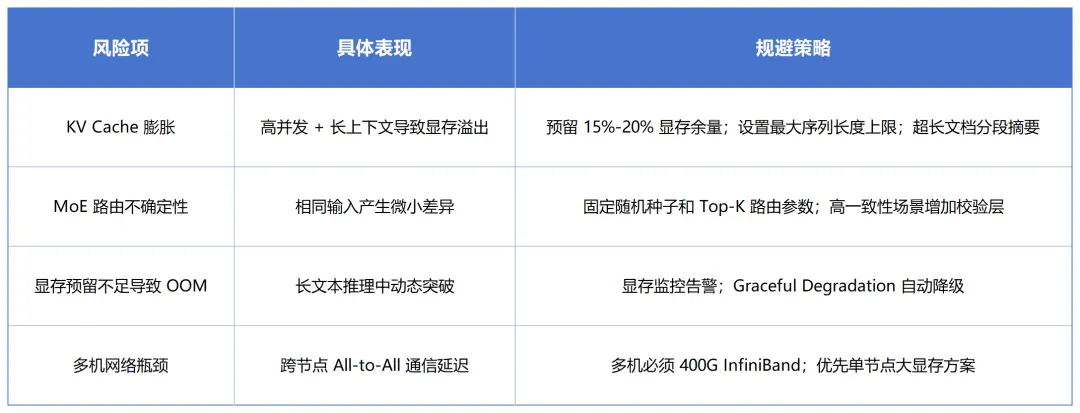
六、落地风险与规避策略
七、常见问题 FAQ
Q1:Kimi K2.5 和 K2.6 该选哪个?
代码生成、软件工程、Agent 工作流为主选 K2.6(编码 +15%,Agent Swarm 扩展至 300 子智能体)。通用推理、知识问答、文档处理为主选 K2.5——架构与 K2.6 完全相同,API 成本更低,生态更成熟。硬件选型完全一致。
Q2:私有化部署的最低硬件门槛是什么?
单张 A100(80GB)可跑通 INT4 量化版本,但仅支撑低并发测试。生产环境最低建议单节点 8×H100(80GB),配合显存卸载和并发控制。
Q3:为什么不直接用 API,而要私有化?
三个原因:数据安全(金融、医疗、军工等敏感数据不能出域);成本可控(高频调用累计成本更低);定制化(可针对业务场景做量化策略优化和推理参数调优)。
Q4:从采购服务器到跑通模型需要多久?
服务器到位后,有经验的技术团队 1-2 天完成环境搭建和模型加载,1 周内完成端到端验证。选择全栈服务商可压缩至 3-5 个工作日。
八、赋能科技,智创未来
Kimi K2.5 以及架构同源的 K2.6,释放出一个行业明确信号:万亿参数级稀疏 MoE 大模型,已经从实验室科研场景,正式迈入企业级算力机房规模化落地阶段。如今大模型高效部署,早已不再单纯依靠堆叠 GPU 数量,更考验显存带宽、组网互联拓扑、模型量化技术三者的深度协同与最优适配。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)