ICLR 2026 | 推理效率提升超60倍:DiDi-Instruct让扩散语言模型16步超越千步GPT
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
DiDI-Instruct
-
论文题目:Ultra-Fast Language Generation via Discrete Diffusion Divergence Instruct
-
第一作者:郑昊阳
-
论文链接:www.arxiv.org/abs/2509.25035
-
代码仓库:
github.com/haoyangzheng-ai/didi-instruct
-
项目主页:haoyangzheng.github.io/research/didi-instruct
-
Open Review:https://openreview.net/forum?id=mtdyZsa47V
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究组、小红书hi-lab等机构的研究者联合提出了一种对离散扩散大语言模型的后训练方法——Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过DiDi-Instruct后训练的扩散大语言模型可以以60倍的加速超越传统的GPT模型和扩散大语言模型。

DiDi-Instruct 蒸馏得到的“学生”模型与教师模型、GPT-2 的文本生成效率对比。
DiDi-Instruct 提出了一种独创的概率分布匹配的后训练策略,可以将原本需要500步以上昂贵的扩散语言“教师”(diffusion Large Language Model, dLLM)模型,蒸馏成一个仅需8-16步生成整个文本段落的“学生”模型。在OpenWebText标准数据集上,DiDi-Instruct语言模型既实现了超过64倍以上的推理加速,又在性能上同时显著超越了被蒸馏的教师扩散语言模型(dLLM,1024步生成)和自回归的 GPT2 模型(1024步生成)。DiDi-Instruct 算法同时提升了大语言模型的推理效率和推理效果。为极端高效的大语言模型落地提供了新的方案。

1
研究背景 | 大语言模型生成的“速度极限”是多少?
近年来,以自回归(ARMs)范式为核心的大语言模型(如 ChatGPT,DeepSeek 等模型)取得了巨大成功。然而,自回归模型逐词串行生成的固有瓶颈,使其在长文本生成时面临难以逾越的延迟“天花板”,即使强大的并行计算硬件也无计可施 。作为一种新兴的替代范式,扩散语言模型(后文将用 diffusion large language model (dLLM) 指代)应运而生。dLLM 将文本生成重塑为一个从完全噪声(或掩码)序列中迭代去噪、恢复出完整文本的过程 。这一模式天然支持并行化语言段落生成,相较于自回归模型生成速度更快。然而尽管如此,现有最好的 dLLM 在同等模型尺寸下为了达到与 GPT-2 相当的性能,仍然需要多达上百次模型迭代。这个困境不禁让人疑惑:是否存在模型在极端少的迭代次数下(如8-16次迭代)下能显著超越1024次迭代的GPT模型?
2
破局者 | DiDi-Instruct:分布匹配训练实现语言模型极致加速
在上述研究背景下,本篇文章提出了 DiDi-Instruct。DiDi-Instruct是一个dLLM的后训练算法。通过 DiDi-Instruct 算法训练蒸馏之后的dLLM,可以将原本的1024次推理次数压缩至8到16步,同时可以显著提升dLLM的建模效果。
DiDi-Instruct的理论来源于连续扩散模型中的一个经典单步蒸馏算法:Diff-Instruct。从理论上看,DiDi-Instruct 训练算法的核心思想是最小化一个少采样步数的“学生”模型与多采样步数的“教师” dLLM 模型在整个离散Token去噪轨迹上分布的积分KL散度(Integral Kullback-Leibler Divergence)。该目标把不同时间的 KL 以权重积分汇总,避免只对齐末端样本而训练不稳的问题,从而让学生以一种全局、全过程匹配的方式,高效“学习”教师的精髓。一旦积分KL散度被优化至收敛(接近0值),少步生成的“学生”模型便在概率意义上吸收了 "教师dLLM" 的知识。
在上述研究背景下,本篇文章提出了 DiDi-Instruct。DiDi-Instruct是一个dLLM的后训练算法。通过 DiDi-Instruct 算法训练蒸馏之后的dLLM,可以将原本的1024次推理次数压缩至8到16步,同时可以显著提升dLLM的建模效果。
DiDi-Instruct的理论来源于连续扩散模型中的一个经典单步蒸馏算法:Diff-Instruct。从理论上看,DiDi-Instruct 训练算法的核心思想是最小化一个少采样步数的“学生”模型与多采样步数的“教师” dLLM 模型在整个离散Token去噪轨迹上分布的积分KL散度(Integral Kullback-Leibler Divergence)。该目标把不同时间的 KL 以权重积分汇总,避免只对齐末端样本而训练不稳的问题,从而让学生以一种全局、全过程匹配的方式,高效“学习”教师的精髓。一旦积分KL散度被优化至收敛(接近0值),少步生成的“学生”模型便在概率意义上吸收了 "教师dLLM" 的知识。
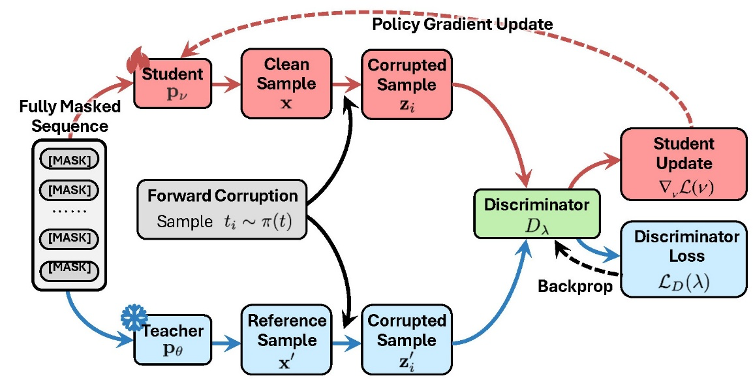
DiDi-Instruct 流程示意:学生模型(Student)与教师模型(Teacher)从全掩码序列重建“干净文本”,并同时进行加噪处理。随后,判别器(Discriminator)对两者输出进行区分并给出奖励分数,用作学生模型的更新信号,使其在后续生成中逼近教师分布。经过反复迭代,Student 能以更少步数获得接近 Teacher 的生成质量。
然而,想要直接优化积分KL散度面临诸多例如离散文本不可微分等理论困难。这对这些挑战,DiDi-Instruct 提出了一套系统性的解决方案,其关键创新包括:
1. 基于策略梯度的分布匹配目标:DiDi-Instruct 巧妙地将蒸馏目标重构为一种策略梯度(Policy Gradient)的数学形式,然后通过引入一个奖励函数来指导学生模型的更新,优雅地绕过了在离散空间中求导的难题。
2. 通过对抗学习动态塑造奖励函数:为了获得上述奖励信号,DiDi-Instruct 引入了一个辅助的判别器网络(discriminator)。该网络通过对抗训练,学习区分“学生”和“教师”在任意中间步骤生成的噪声样本,其输出的对数密度比(log-density ratio)便构成了指导学生优化的精确奖励信号。
3. 稳定训练与高质量推理的关键技术:DiDi-Instruct 还引入多项关键设计对该方法进行系统性优化,以稳定训练、缓解熵坍塌、提升推理质量。
-
分组奖励归一化(Grouped Reward Normalization):借鉴深度求索(DeepSeek)提出的组相对策略优化(GRPO),DiDi-Instruct 在每个小批量(mini-batch)内对奖励进行标准化。该操作显著降低了训练梯度的方差,有效提升了训练的稳定性。
-
分步式中间状态匹配(Intermediate-state Matching):通过分解梯度信息,DiDi-Instruct使学生模型在训练中接触到不同噪声水平的中间状态。这个机制有效缓解了困扰许多后训练算法的模型熵坍塌问题(mode collapse),保证了学生模型真正学习到生成复杂,多样性的内容。
-
奖励驱动的祖先采样(Reward-guided Ancestral Sampling):在推理阶段,利用训练好的判别器获得奖励信号,对生成过程进行“梯度引导+多候选重排序”,进一步提升了最终生成文本的质量。

DiDi-Instruct 后训练算法。

奖励驱动的祖先采样算法。
3
科学实验 | 效率与性能的双重飞跃
研究团队在公开的 OpenWebText 数据集上进行了详尽的实验,结果出人出人意料:经过 DiDi-Instruct 后训练的语言模型在效率和效果上得到了双重提升。
1. 速度与质量的双重飞跃:在 OpenWebText 数据集上,DiDi-Instruct 仅需 16 步(NFEs)的生成质量(Perplexity=30.99)便超越了需要 1024 步的教师模型(PPL=38.53)和 GPT-2 Baseline。更重要的是,团队在单张H100 GPU 上进行了延迟测试(Latency):DiDi-Instruct 的吞吐量达到了 2366 tokens/sec,生成每千个 token 仅需0.432 秒,在同等生成质量下,速度是标准自回归模型的 13.2 倍。
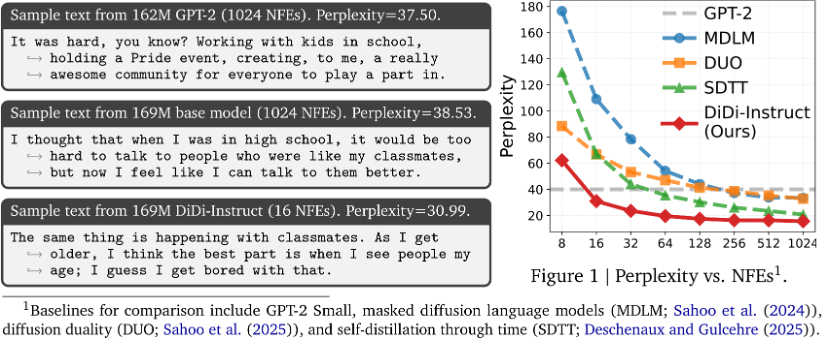
DiDi-Instruct 蒸馏所得学生模型与基准模型在不同函数评估次数(NFEs)下的文本生成困惑度(PPL)对比。
2. 破解蒸馏训练模式崩塌:高保真与高多样性 传统蒸馏方法(如 SDTT、DUO)往往为了生成精度而牺牲多样性。团队引入了分布相似度(MAUVE)和多样性指标(Self-BLEU)进行评估 。结果表明,DiDi-Instruct 在不同 NFE 设置下均取得了最高的 MAUVE 分数,同时保持了极具竞争力的 Self-BLEU 分数,成功避免了 mode-seeking 行为。
3. 下游任务与语义特征提取:蒸馏后的扩散语言模型是否性能变“弱”了?作者通过进一步的微调与特征提取评估给出了否定答案:
-
领域自适应:在 MMLU 和 PubMed 语料库库进行监督微调(SFT)时,DiDi-Instruct 不仅匹配了教师模型的准确率,且在降低负对数似然(NLL)方面表现最优
-
冻结特征提取:在 GLUE MRPC 数据集上,直接使用冻结的 DiDi-Instruct 骨干网络进行分类,取得了 62.3% 的准确率和 73.3% 的 F1 分数,均超越了老师模型与 SDTT 等基线。
4. 跨领域拓展与多样性验证:究团队在报告中指出,DiDi-Instruct 的蒸馏框架是为离散扩散模型设计的,并不局限于语言模型。为了验证这一点,团队将其成功应用于一个全新领域:无条件蛋白质序列生成。他们使用一个预训练的蛋白质语言扩散模型(DPLM)作为教师模型进行蒸馏。结果表明,蒸馏后的学生模型在 8-32 步极少步数下即可生成高置信度(pLDDT > 70)的蛋白质结构 。在MMseqs2 聚类分析中,DiDi-Instruct 生成的蛋白质具备与老师模型相当的聚类熵和平均聚类大小,确认其生成了具备生物学意义的多样性序列 。
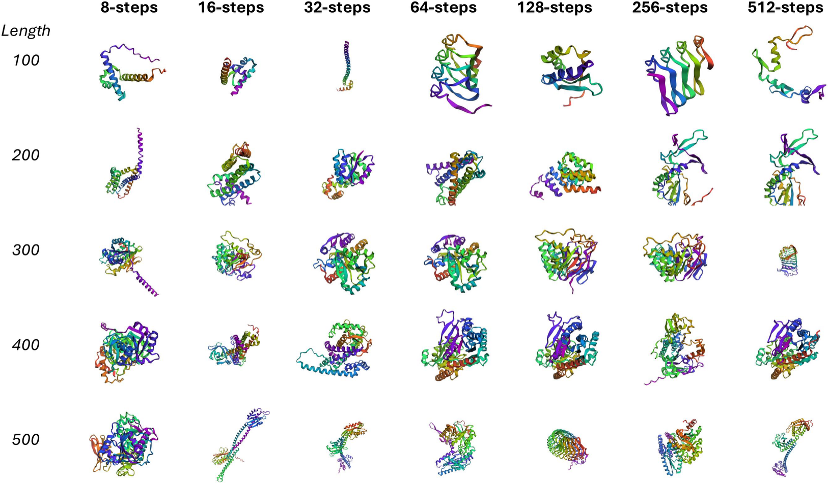
由 DiDi-Instruct 蒸馏得到的学生模型生成的 高置信度蛋白质序列(pLDDT > 70)。
5. 深入消融实验,探究各组件的核心贡献:为了科学地验证每个创新组件的必要性和贡献,研究团队还进行了详尽的“逐项累加”(cumulative)和“逐一剔除”(leave-one-out)的消融研究。这些实验揭示了模型性能的关键驱动因素:
-
中间状态匹配是框架稳定的基石:实验表明,虽然单独加入该模块对性能提升有限,但在完整的模型中一旦移除,模型性能会灾难性下降(PPL > 30,000),证明了其在复杂优化环境下的关键稳定作用。
-
时间步耦合能高效提升蒸馏性能:该技术将8步生成下的困惑度从600+骤降至100左右,凸显了对齐奖励信号与分数函数中间状态的重要性。而在目标函数中增加权重信息则能进一步提升模型训练效果。
-
正则化项扮的“双重角色”:在极少步数下(如 8 NFEs),它能有效稳定训练,防止离散误差导致训练目标偏离。然而在更多步数(≥ 16 NFEs)的采样中,移除正则化反而能取得更好的结果,这表明此时过强的约束会限制模型的表达能力。
-
引导式推理的作用解读:在少步数(如 8 NFEs)时,它能显著降低困惑度(困惑度相对改善约30%),提升文本生成质量。而在多步数下,它对困惑度影响甚微,但能显著提升生成样本的多样性(熵从5.00提升至5.15),这与奖励驱动的祖先采样设计的先“梯度引导”后“多候选重排序”的混合策略设计完美契合。
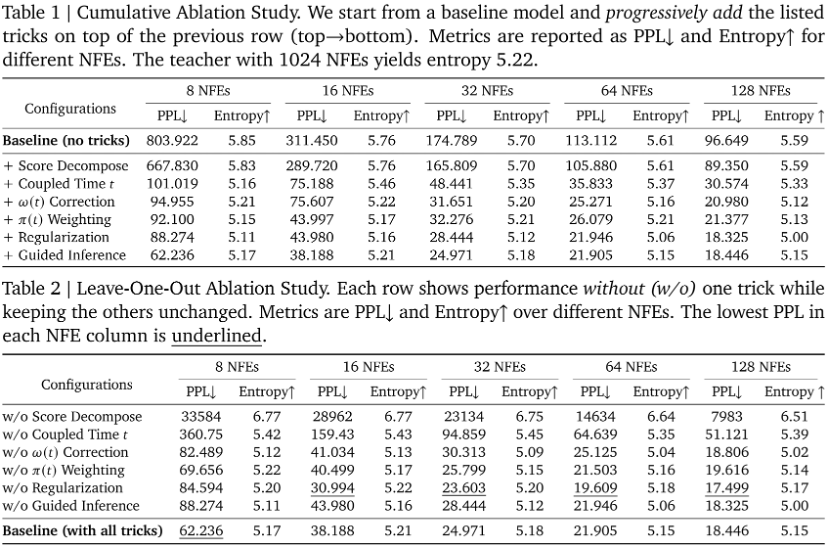
“逐项累加”消融实验结果见表1,“逐一剔除”消融实验结果见表2。
4
技术展望 | 开启高效生成模型新范式
DiDi-Instruct 的提出,不仅是离散扩散模型加速技术的一次技术突破,也为广泛的大语言模型的极限加速,对齐和强化学习提供了新的思路。它首次成功地将分布匹配蒸馏思想应用于基于掩码的离散扩散模型,并建立了一套集 “分布匹配目标、稳定训练、高效推理” 于一体的完整框架。这项工作展示了通过系统性的算法与框架设计,可以克服现阶段大语言模型在生成效率上的瓶颈,使其成为下一代 AI 内容生成中(多模态生成、代码生成、生物序列设计等领域)极具竞争力的选项。我们非常期待将DiDi-Instruct应用于最前沿的超大规模的扩散语言模型的效果。
作者简介
本论文第一作者为美国普渡大学林光教授课题组在读博士生郑昊阳,目前在 Google Mountain View 总部实习。
林光是普渡大学的 Moses Cobb Stevens 教授兼理学院副院长。
论文的两位通讯作者罗维俭和邓伟分别是小红书 hi-lab 的多模态研究员和纽约摩根士丹利机器学习研究组的资深研究员。
往期精彩文章推荐
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者直播回放!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)