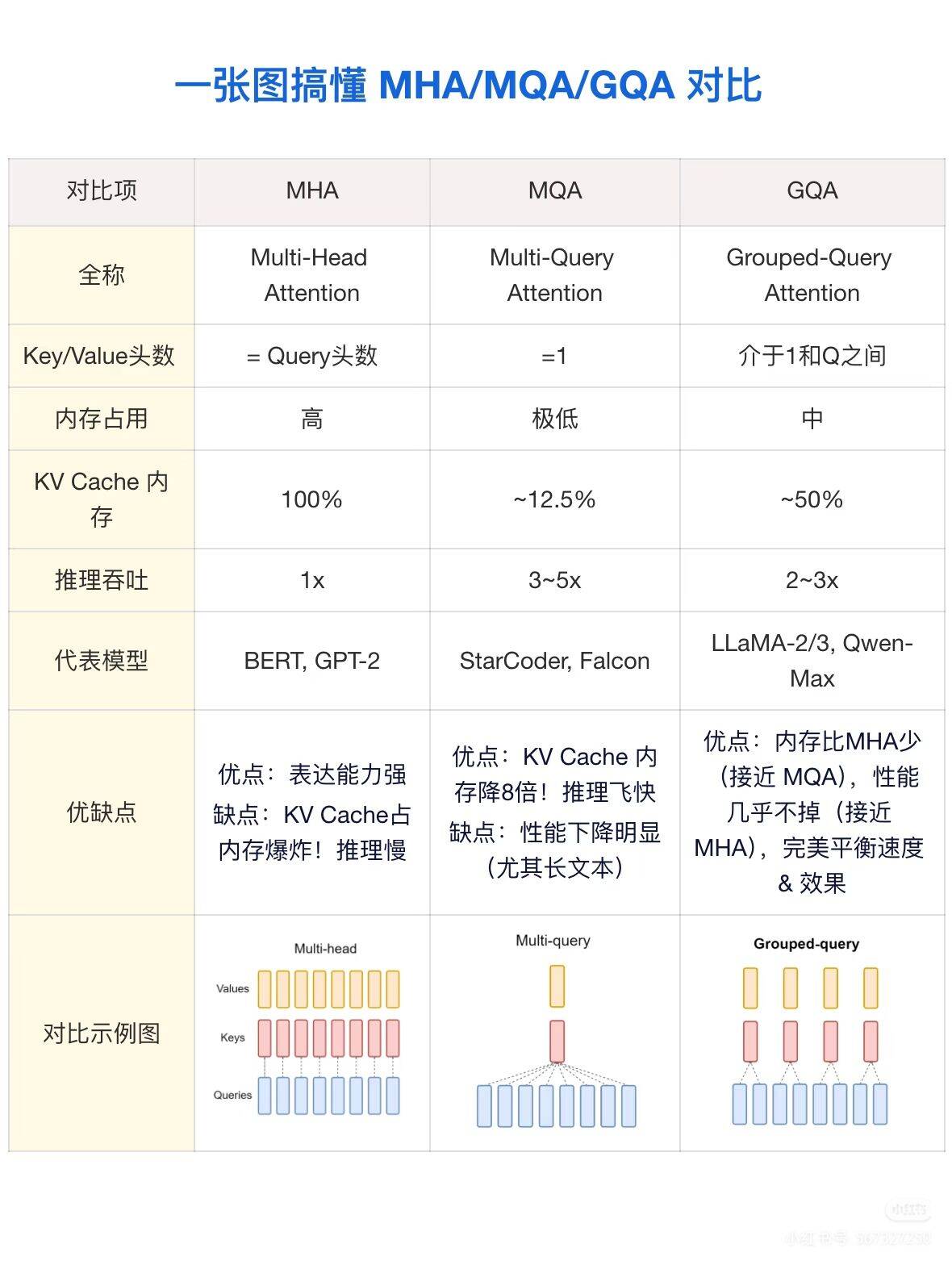
【DL】MHA MQA GQA MLA
在大语言模型(LLM)的推理过程中,随着上下文长度的增加,KV Cache(键值缓存)会占用海量的显存带宽,成为制约模型推理速度和吞吐量的最大瓶颈。
为了解决这个问题,研究人员在标准 Transformer 的注意力机制上进行了多次迭代。以下为您详细讲解 MHA、MQA、GQA 以及最新一代的 MLA,并附带数学公式与总结对比表格,内容已针对 CSDN 博客排版进行了优化。
一、 MHA: Multi-Head Attention (多头注意力)
MHA 是 Transformer 最原始、最经典的注意力机制结构(如 GPT-3、LLaMA-1 均采用)。
1. 原理说明
在 MHA 中,模型设置了 hhh 个注意力头(Heads)。对于每一个 Query (Q) 头,都有一个完全独立且专属的 Key (K) 头和 Value (V) 头。
这意味着如果在推理时缓存历史信息,你需要为所有的 hhh 个头分别保存一份 KV 矩阵,这会导致巨大的显存占用。
2. 数学公式
假设输入序列特征为 XXX,对于第 iii 个注意力头(i=1,2,…,hi = 1, 2, \dots, hi=1,2,…,h):
计算独立的 Q、K、V:
Qi=XWiQ,Ki=XWiK,Vi=XWiVQ_i=XW_i^Q,\quad K_i=XW_i^K,\quad V_i=XW_i^VQi=XWiQ,Ki=XWiK,Vi=XWiV
计算该头的注意力输出:
headi=Softmax(QiKiTdk)Vi\text{head}_i=\text{Softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_k}}\right)V_iheadi=Softmax(dkQiKiT)Vi
最后将所有头拼接并做线性映射:
MHA(Q,K,V)=Concat(head1,…,headh)WO\text{MHA}(Q,K,V)=\text{Concat}(\text{head}_1,\dots,\text{head}_h)W^OMHA(Q,K,V)=Concat(head1,…,headh)WO
二、 MQA: Multi-Query Attention (多查询注意力)
MQA 是为了追求极致的推理速度和极低的显存占用而提出的一种激进优化方案(如 ChatGLM-6B 早期版本、StarCoder 采用)。
1. 原理说明
MQA 保持 hhh 个 Query 头不变,但强行让所有的 Q 头共享唯一的一组 K 和 V。
在推理阶段,KV Cache 的大小直接骤降为 MHA 的 1/h1/h1/h。虽然速度起飞了,但由于 K 和 V 的表达能力被严重压缩,模型在复杂推理任务上的性能会有明显下降。
2. 数学公式
计算 hhh 个独立的 Q:
Qi=XWiQQ_i=XW_i^QQi=XWiQ
计算全局共享的 K 和 V:
K=XWK,V=XWVK=XW^K,\quad V=XW^VK=XWK,V=XWV
各个 Q 头使用相同的 K 和 V 计算注意力:
headi=Softmax(QiKTdk)V\text{head}_i=\text{Softmax}\left(\frac{Q_iK^T}{\sqrt{d_k}}\right)Vheadi=Softmax(dkQiKT)V
三、 GQA: Grouped-Query Attention (分组查询注意力)
GQA 是一种折中且极其优雅的方案,是目前主流开源大模型的标配(如 LLaMA-2、LLaMA-3、Mistral 均采用)。
1. 原理说明
GQA 将 hhh 个 Query 头划分为 GGG 个组(Groups)。在每一个组内,多个 Q 头共享同一组 K 和 V。
如果 G=hG=hG=h,GQA 就退化成了 MHA;如果 G=1G=1G=1,GQA 就变成了 MQA。通常 GGG 会取 444 或 888。GQA 能够达到接近 MQA 的推理速度,同时保持几乎与 MHA 一致的模型性能。
2. 数学公式
假设 GGG 为分组数量,每个组内有 h/Gh/Gh/G 个 Q 头。对于第 ggg 组(g=1,…,Gg = 1, \dots, Gg=1,…,G),计算该组共享的 K 和 V:
Kg=XWgK,Vg=XWgVK_g=XW_g^K,\quad V_g=XW_g^VKg=XWgK,Vg=XWgV
对于第 ggg 组内的第 iii 个 Q 头:
Qg,i=XWg,iQQ_{g,i}=XW_{g,i}^QQg,i=XWg,iQ
该头的注意力计算:
headg,i=Softmax(Qg,iKgTdk)Vg\text{head}_{g,i}=\text{Softmax}\left(\frac{Q_{g,i}K_g^T}{\sqrt{d_k}}\right)V_gheadg,i=Softmax(dkQg,iKgT)Vg
四、 MLA: Multi-head Latent Attention (多头潜在注意力)
MLA 是由 DeepSeek-V2 提出的一种最新、极其巧妙的注意力机制,旨在打破长文本下 KV Cache 的极限瓶颈。
1. 原理说明
与 GQA 减少物理头数不同,MLA 采用了低秩联合压缩(Low-Rank Joint Compression)的思想。
它将极其庞大的 K 和 V 矩阵首先通过下采样(Down-projection)压缩成一个维度极小的“潜在向量(Latent Vector)”。在推理时,KV Cache 只存储这个极短的潜在向量。计算注意力时,再通过上采样(Up-projection)动态解压出 K 和 V。结合对 RoPE(旋转位置编码)的解耦处理,MLA 在实现比 GQA 更高压缩率的同时,性能媲美全量的 MHA。
2. 数学公式
假设隐层输入为 hth_tht,首先计算压缩后的 KV 潜在向量 ctKVc_t^{KV}ctKV(这也是 KV Cache 真正缓存的唯一内容):
ctKV=htWDKVc_t^{KV}=h_tW^{DKV}ctKV=htWDKV
在需要计算时,将潜在向量解压(Up-projection)为对应的 K 和 V:
ktc=ctKVWUK,vtc=ctKVWUVk_t^c=c_t^{KV}W^{UK},\quad v_t^c=c_t^{KV}W^{UV}ktc=ctKVWUK,vtc=ctKVWUV
为了保证旋转位置编码(RoPE)的位移不变性,MLA 会解耦出独立的一维 RoPE 键 ktrk_t^rktr:
ktr=htWKRk_t^r=h_tW^{KR}ktr=htWKR
最终用于计算注意力的 Key 是解压出的 K 与 RoPE K 的拼接:
Kt=[ktc,ktr]K_t=[k_t^c, k_t^r]Kt=[ktc,ktr]
(注:Query 端同样有类似的低秩压缩与解耦逻辑,在此为了突出 KV Cache 的优化,省略 Q 端的繁杂公式。)
五、 全景对比总结表
您可以直接复制下方表格到 CSDN 博客中:
| 注意力机制 | Query 头数 | K/V 头数 | KV Cache 显存占用 | 模型表现 (效果) | 推理速度/吞吐量 | 代表模型 / 现状 |
|---|---|---|---|---|---|---|
| MHA (多头) | hhh | hhh (完全独立) | 极高 (100%100\%100%) | 最高 (基线) | 极慢 (受限于显存带宽) | GPT-3, LLaMA-1, 早期模型标配 |
| MQA (多查询) | hhh | 111 (全局共享) | 极低 (降至 1/h1/h1/h) | 明显下降 | 极快 | StarCoder, ChatGLM-6B (早期) |
| GQA (分组查询) | hhh | GGG (组内共享) | 中低 (降至 G/hG/hG/h) | 接近 MHA | 较快 (当前最佳折中) | LLaMA-2/3, Mistral, Qwen |
| MLA (多头潜在) | hhh | 动态解压 | 极低 (仅存低秩向量) | 比肩 MHA | 极快 (破局长文本) | DeepSeek-V2, DeepSeek-V3 |
总结:
- 演进路线:MHA(性能好但太重) →\rightarrow→ MQA(太快但牺牲大) →\rightarrow→ GQA(目前工业界主流的完美平衡) →\rightarrow→ MLA(长文本时代的新范式,用压缩换空间)。
- 核心思想:MHA/MQA/GQA 是在结构(头的数量)上做加减法;而 MLA 是在信息维度(低秩矩阵)上做极致压缩。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)