Qwen3.6-27B 碾压 397B 旗舰、MoE 稀疏化降本 60%、本地部署门槛归零 — 大模型「以小博大」时代到来
2026年5月第一周,一组数据同时刷新了三个维度的认知:
- 阿里 Qwen3.6-27B 在代码评测中超越上代 397B 旗舰——参数量不到 7%,性能反而更强
- 中国 AI 大模型周调用量冲到 7.942 万亿 Token,环比暴涨 81.7%,二次反超美国模型
- xAI 的 Grok 4.3 发布即降价 60%,OpenAI 默认模型切换到更高效的 GPT-5.5 Instant
逻辑变了。大模型竞争的上半场是「谁更大」,下半场是「谁更省」。

Qwen3.6-27B:7% 的参数量,100%+ 的性能
阿里 Qwen3.6-27B 是这场「以小博大」趋势最直观的证据。
它只有 27B 参数,不到上一代 397B 旗舰模型的 7%,却在代码评测上实现了反超。这在两年前是不可想象的——那时候的行业共识是:参数量每扩大 10 倍,性能才能上一个台阶。
打破这个共识的,是两个技术杠杆:
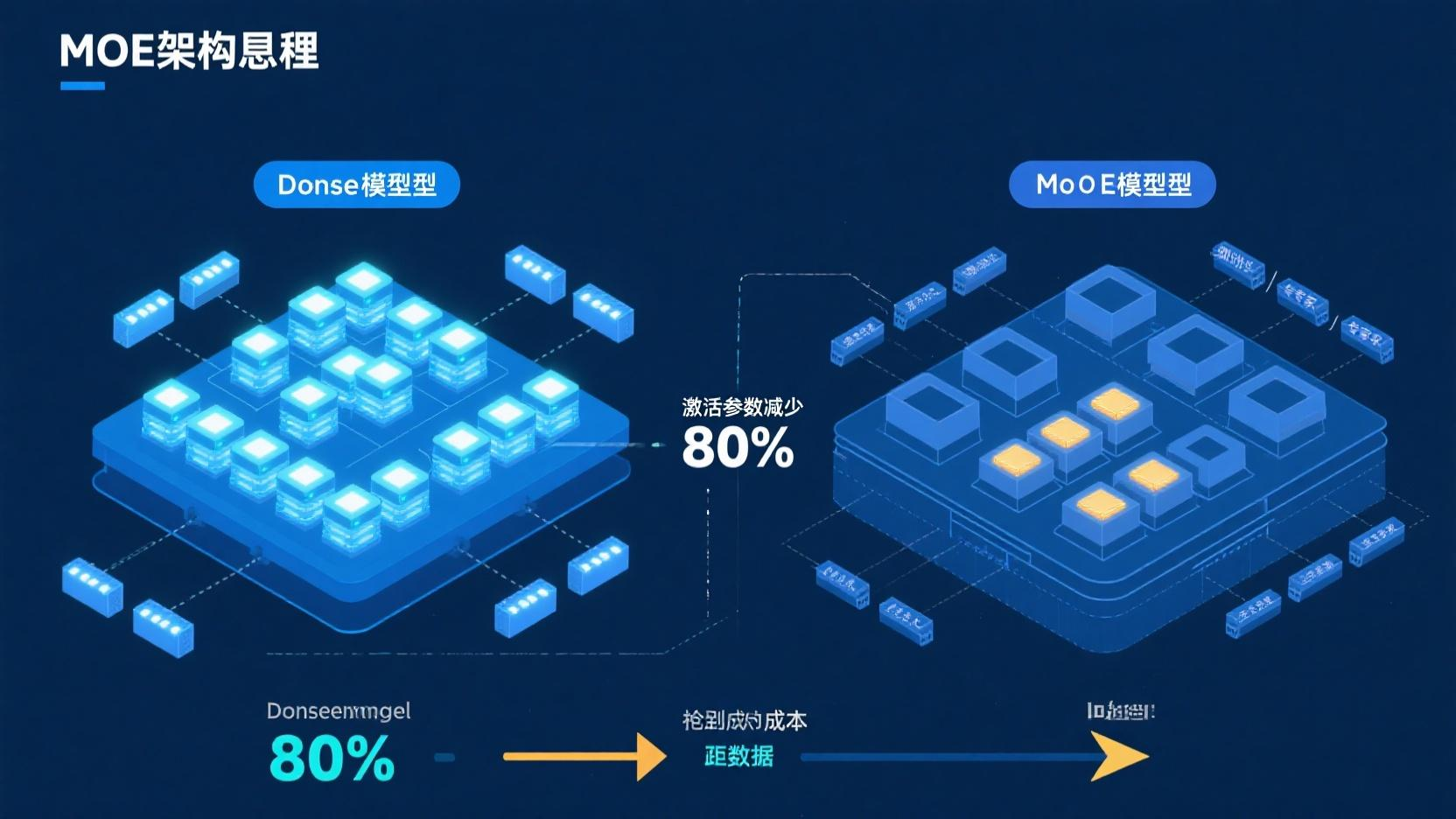
1. MoE(Mixture of Experts)稀疏化架构。 传统 Dense 模型每次推理激活全部参数。MoE 模型把参数分成多个「专家」子模块,每次推理只激活其中的 10%-20%。27B 的 MoE 模型,实际计算量可能只相当于 3-5B 的 Dense 模型,但知识密度却远超同量级。
2. 数据质量的杠杆效应。 斯坦福 HAI 2026 年报告明确指出:「大模型撞上天花板了,未来在更小、质量更高的数据集。」用 1/10 的高质量数据训练,效果往往好过用全量低质量数据。Qwen 团队在数据清洗和合成数据上的投入,是 27B 超越 397B 的真正秘密。
MoE 吃掉一切:为什么所有大模型都在「变稀疏」
MoE 不是新概念(1991 年就提出了),但它在大模型时代的复兴是 2026 年最重要的技术叙事。
核心原因很朴素:Dense 模型的边际收益在急剧递减。 从 70B 扩到 400B,推理成本涨了 5 倍,性能提升可能只有 5%。而 MoE 的思路是把参数当「知识库」而非「计算量」——参数可以很多(存储知识),但每次推理只激活一小部分(控制成本)。
2026年已发布的主流模型几乎全是 MoE 或变体: - Qwen3.6 系列:MoE - DeepSeek V3/R1:MoE - 字节 Doubao-Seed-2.0-Pro:MoE - GPT-5.5:未公开但推理效率暴涨 3 倍,大概率也是稀疏化方向
对于企业部署来说,MoE 的意义是实打实的:一个 27B 的 MoE 模型可以在消费级 GPU 上本地运行,推理成本降到 Dense 大模型的 1/20。
中国军团反超:这一次不只是数字
据 OpenRouter 测算,4月27日至5月3日,中国 AI 大模型周调用量达到 7.942 万亿 Token,美国模型为 3.258 万亿。这是国产模型第二次在调用量上超越美国对手,但这次意义完全不同。
上一次反超主要靠中文场景的天然优势。这一次的三个背景变了:
- 字节 Doubao-Seed-2.0-Pro 登顶视觉评测榜,在多模态能力上不再是追随者
- 阿里 Qwen3.6-27B 在代码评测上超越闭源旗舰,开发者用脚投票
- DeepSeek 多模态论文虽被撤下,但识图功能灰度测试已同步开启
调用量反超的本质是:中国模型不再只是在中文场景更有优势,而是在全局性能上能够替代美国模型。当全球开发者选择 Qwen 而非 GPT 来做代码生成,这个信号比任何 benchmark 排行榜都更有力。
价格战进入深水区:模型调用成本不再是障碍
xAI Grok 4.3 主动降价 60%,OpenAI 将默认模型切换为更高效的 GPT-5.5 Instant,DeepSeek 以极致性价比著称——模型调用成本正在快速逼近「忽略不计」。
这对企业的实际影响是:「用哪个模型」不再是一个成本问题,而是一个能力匹配问题。 你用 Qwen 做代码生成、用 GPT-5.5 做长文本理解、用 DeepSeek 做中文场景的多轮对话——每个任务调用最合适的模型。
中国移动 5 月 8 日发布的 MoMA 平台接入超过 300 款模型,首创 Token 集约化运营模式:用户不需要关心底层是哪个模型,平台自动根据成本、效果、延迟三个维度匹配最优模型。当模型出现超时或限流时,秒级切换到备选模型。
这是一个关键判断:2026 年的 AI 竞争,胜负手不再是谁训练出了最强的单个模型,而是谁建成了让多个模型高效协作的基础设施层。
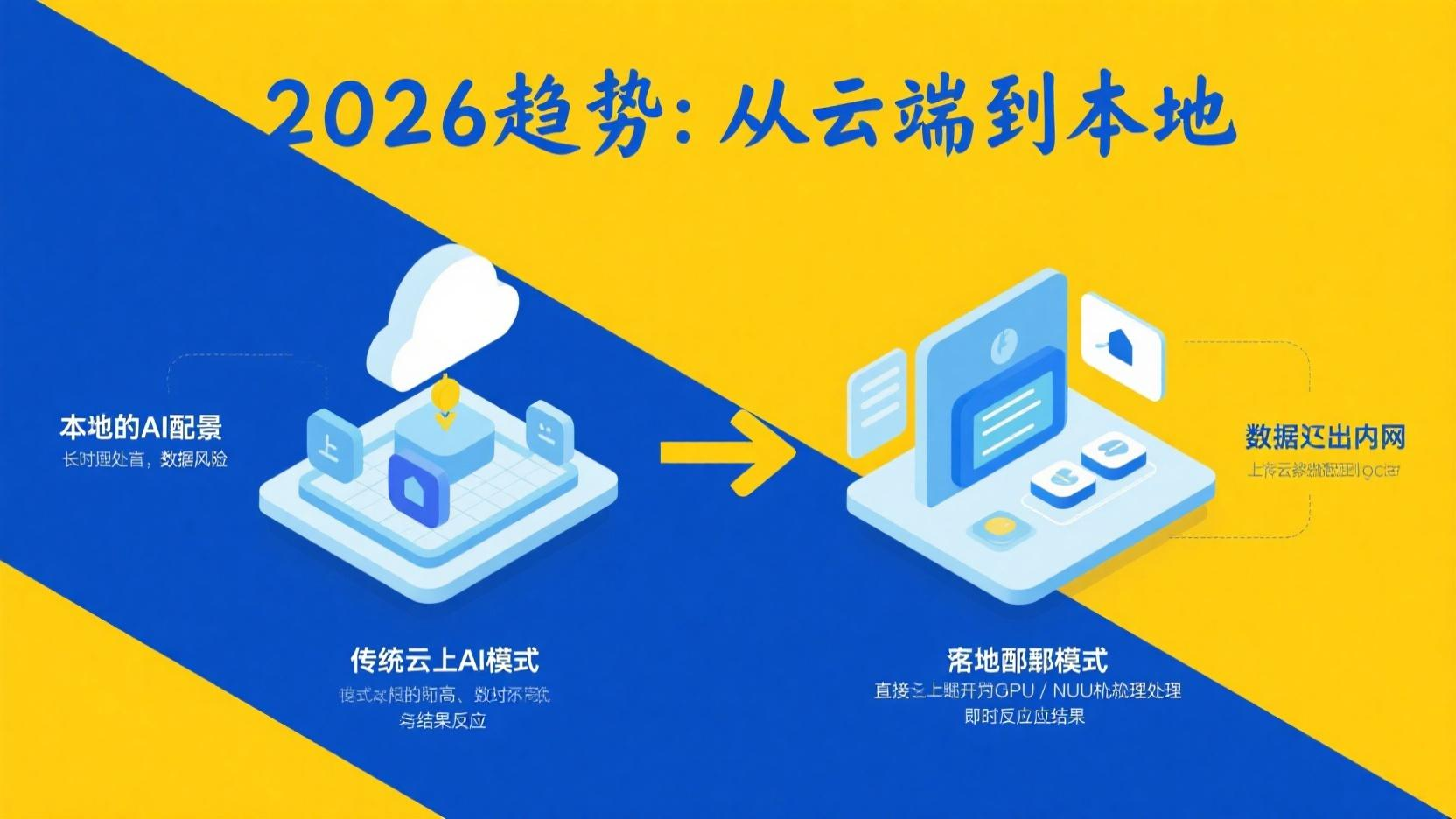
本地部署:从「不可能」到「标配」
MoE + 模型小型化 + 开源,三个趋势叠加产生了一个直接结果:百亿参数级别的模型可以在消费级硬件上本地运行。
小米 MiMo-V2.5 已正式开源,目标场景是手机端本地运行百亿参数大模型,低功耗、高推理,脱离云端依赖。高通和联发科正在与手机厂商合作,将 NPU(神经网络处理单元)的算力推向新的量级。
这对信息安全敏感行业(金融、医疗、政务)意味着:AI 能力不需要上云。 一个银行的客服 Agent 可以在本地服务器上跑一个 27B 的 MoE 模型,数据不出内网,延迟不到 100ms,成本不到云 API 的 1/10。
对开发者的三个建议
在这样的趋势面前,个人的几点判断:
-
别只盯着一家模型。 2026 年不存在「最好的模型」,只存在「最合适的模型×任务组合」。建一个多模型路由层,比押注单一模型聪明得多。
-
能用小模型就别用大的。 27B MoE 在很多场景下已经够用了,而且推理成本只有大模型的零头。先跑起来,不够再换。
-
本地部署现在是真的可用。 Ollama、vLLM、llama.cpp 这些工具链已经成熟到可以开箱即用的程度。一个下午就能把 Qwen3.6-27B 跑在自己的工作站上。
结尾
2026年5月的AI行业在密集地传递同一个信号:大模型的价值不再是「大」,而是「好且省」。
Qwen3.6-27B 用 7% 的参数量超越上代旗舰,MoE 让稀疏化成为标配,中国模型在全局性能上逼近甚至反超,价格战把调用成本压到忽略不计,本地部署从概念验证进入生产环境。
这场范式变更的核心就一句话:以前是「更大更强」,现在是「更小更强」。
对于开发者来说,这是最好的时代——因为门槛在消失。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)