9 个大模型一个都跑不通的测试,GPT-5.5 给破了——ProgramBench 到底有多难
这事儿说出来你可能不信。
一个叫 ProgramBench 的编程基准测试,上个月把市面上 9 个大模型全部干趴下了。没一个能完整跑通哪怕一道题。
然后 GPT-5.5 来了,过了。

ProgramBench 是什么?跟传统编程基准完全不是一回事
我们熟悉的编程 benchmark 大概长这样:给你一段代码,让你修个 bug;或者给你一个 API 文档,让你写个函数。
这不叫编程。这叫改作业。
ProgramBench 干的事要狠得多。它给你的不是一个函数签名,不是一段不完整的代码——它给你的是一个完整软件的行为描述。
比如:"请实现一个功能完全等价于 FFmpeg 的多媒体处理工具。"
没有源码。没有架构参考。没有模块划分。什么都没有。
你要自己从头设计代码库架构,自己决定拆几个模块,自己写每一行代码。最后,你的实现会被放到一套"agent-driven fuzzing"系统里跑——AI 自动生成海量测试用例,用模糊测试的方式去对比你的程序和参考程序的行为差异。
过不了就是过不了。
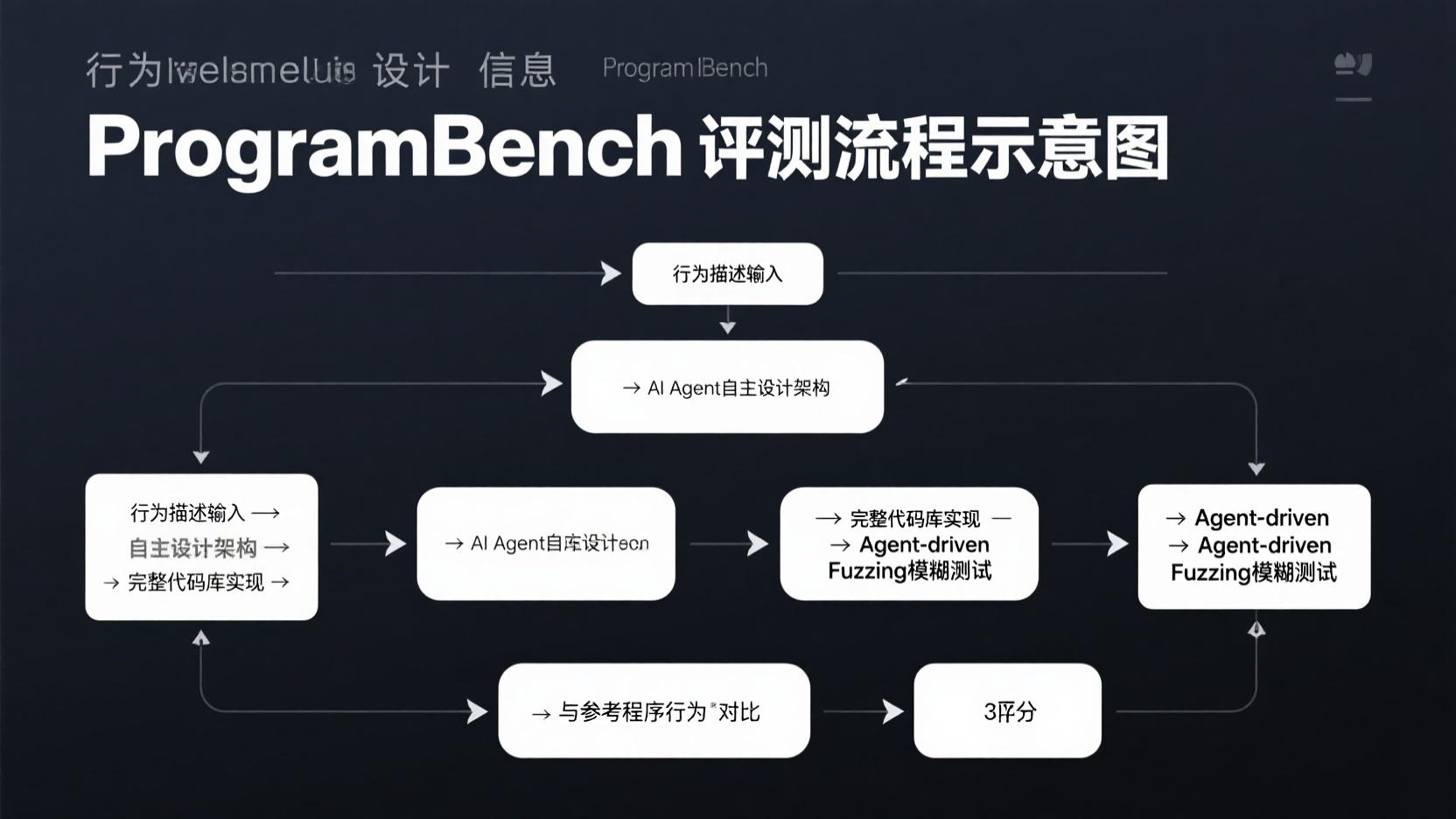
这个测试集包含 200 道题,从轻量级 CLI 小工具到 FFmpeg、SQLite、甚至 PHP 解释器这种级别的完整软件。
它测的不是"会不会写代码"。它测的是"会不会做软件"。
9 个大模型,全军覆没——AI 编程基准的残酷真相
John Yang 团队在论文(arXiv:2605.03546,2026 年 5 月)里评估了 9 个模型。
成绩单说出来你可能觉得夸张:没有任何一个模型完整解决任何一道题。
最好的成绩是什么?在 3% 的任务上通过了 95% 的测试。翻译成人话:200 道题里,最好的模型也只有 6 道题能做到"几乎对",剩下 194 道题直接翻车。
而且翻车的方式很统一。论文里有一段描述让我印象很深:
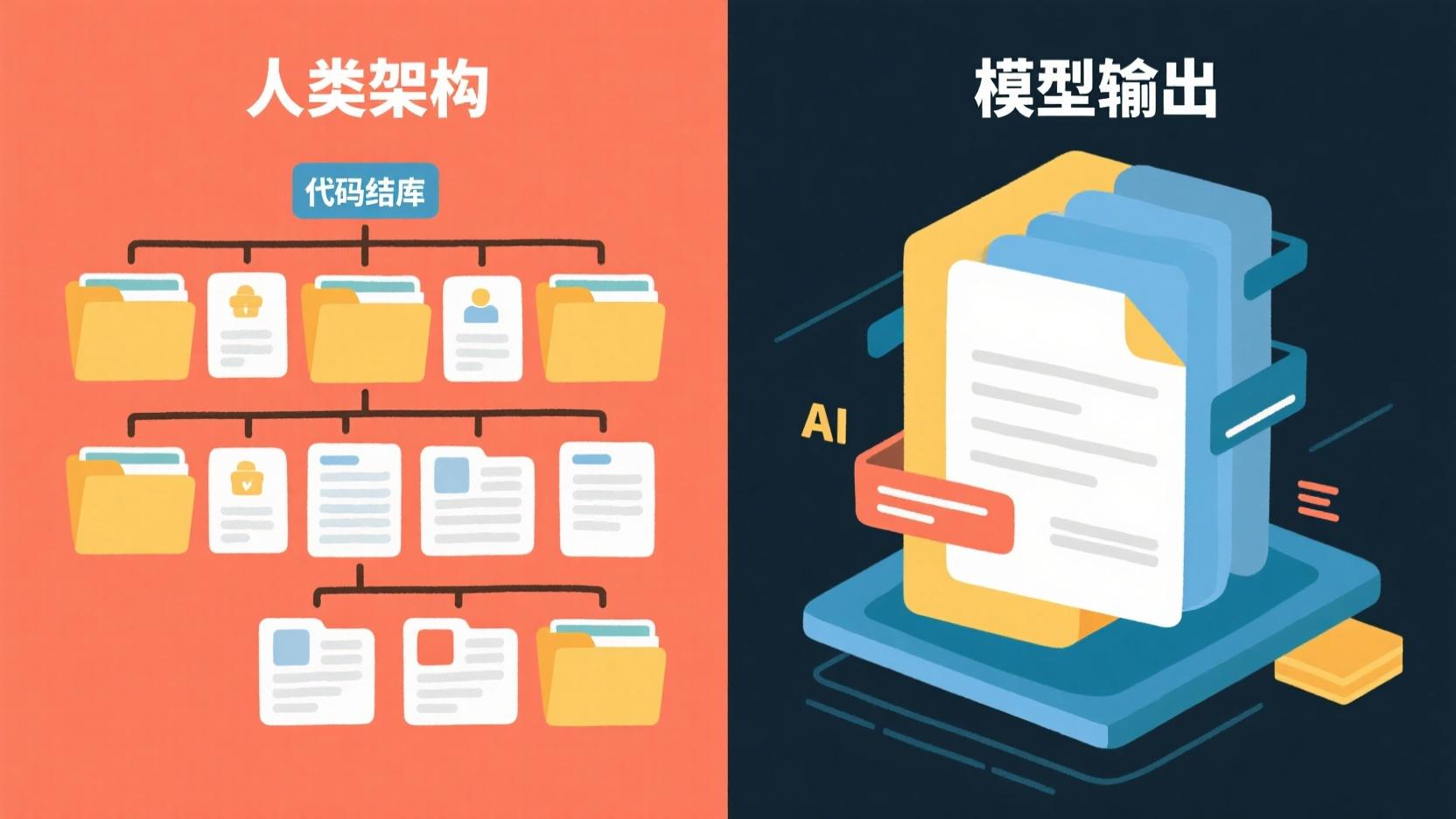
模型普遍倾向于生成单体式、单文件的实现,与人类编写的代码结构差异巨大。
这就是关键问题所在。
现有的大模型写代码,本质上还是在做"填空题"。它们擅长在一个已有文件里插入一段逻辑,擅长在框架里补一个函数。但当你让它从零设计一套软件架构的时候,它的本能反应是——全写一个文件里。
因为它的训练数据里,大量代码片段本身就是单文件的小项目。它从没见过一个真正的代码库是怎么从第一行开始长出来的。
GPT-5.5 凭什么能过?
说实话,目前为止 OpenAI 没有公布 GPT-5.5 在 ProgramBench 上的完整得分卡。
但从已有的信息可以拼出一些关键线索:
第一,GPT-5.5 的 agentic 能力是明确提升的。 Fortune 在 4 月底的报道里用了"more intuitive, agentic performance"这个表述。ProgramBench 测的恰好就是 agent 级能力——它不是一个"提示→补全"的过程,而是一个"目标→自主规划→分步执行→验证"的闭环。
第二,GPT-5.5 减少了幻觉。 在 ProgramBench 这种场景下,幻觉的代价极高。你生成一个 FFmpeg 级别的项目,如果在架构层面的某个关键假设是幻觉,整个后续实现都会偏掉。减少幻觉在这里不是锦上添花,是刚需。
第三,也是我觉得最关键的一点:GPT-5.5 经历了极快的迭代节奏。 从 GPT-5.3 到 GPT-5.4 再到 GPT-5.5,前后不过几周。OpenAI 似乎在密集地针对长程推理和自主规划做优化。而 ProgramBench 对这种能力的测试,比任何现有 benchmark 都更接近真实软件工程。
但话说回来——"首破"不等于"高分通过"。目前没有任何信息表明 GPT-5.5 在 ProgramBench 上拿了满分或接近满分。它很可能只是成为第一个"不再交白卷"的模型。
这就够了。
这对写代码的人意味着什么
我的判断是这样的:
短期(6-12 个月),ProgramBench 级别的能力还影响不到日常开发。你写的不是 FFmpeg,你的项目也不需要 AI 从零架构。AI 在修 bug、写单函数、补测试这些场景下已经够好了,这些事和 ProgramBench 是两条赛道。
但中期(1-2 年),信号已经很明确了。
当 AI 开始能独立设计软件架构、自主做模块拆分的时候,它就不是"辅助工具"了。它是"协作者"。
我个人的感受是:现在还不用慌,但得开始关注一件事——你是不是正在培养"被 AI 替代"的编程习惯。
比如:只写 CRUD、从不思考架构、拿到需求就直接开写代码。
这些东西,是 ProgramBench 告诉我们 AI 正在快速补上的短板。
反之,架构设计能力、跨模块的 trade-off 判断、对业务领域的深度理解——这些短期内还稳得很。
因为 ProgramBench 虽然测的是"建项目",但评测标准是行为一致性,不是代码质量、可维护性、扩展性。而真实软件工程的核心,恰恰是后者。
说到底,GPT-5.5 过 ProgramBench 这件事,最大的意义不是"AI 能写 FFmpeg 了"。而是它证明了一件事:从"补代码"到"建项目"的这堵墙,开始裂了。
裂了多大?不知道。但裂了就是裂了。
你慌吗?

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)