DeepSeek-R1大模型全方位讲解|CPU/GPU双模式本地Docker部署超详细教程
前言
随着大模型技术快速普及,本地化部署AI模型成为开发者、技术爱好者的主流选择,既能规避在线模型服务器繁忙、网络延迟等问题,又能保障数据隐私、实现私有化部署。DeepSeek-R1作为国内开源、可免费商用的优质推理大模型,凭借强悍的逻辑推理、数学运算、代码生成能力,被广泛应用于个人学习、轻量化开发、企业私有化场景。
本文将从零开始,全方位介绍DeepSeek大模型核心知识,同时基于Rocky Linux 9系统,详细讲解无GPU(CPU尝鲜)和GPU加速两种Docker部署方案,包含Docker环境搭建、国内镜像加速器配置、Ollama部署、模型拉取、Web可视化界面搭建全流程,新手也能零基础上手。
一、Deepseek大模型介绍
DeepSeek是一家专注通用人工智能(AGI)的中国科技公司,主攻大模型研发与应用。 DeepSeek-R1是一个开源的推理模型,擅长处理复杂任务且可免费商用。
AGI:全称Artificial General Intelligence,译名“通用人工智能”
AIGC:全称Artificial Intelligence Generated Content,译名“人工智能生成内容”
LLM:全称Large Language Model,译名“大型语言模型”
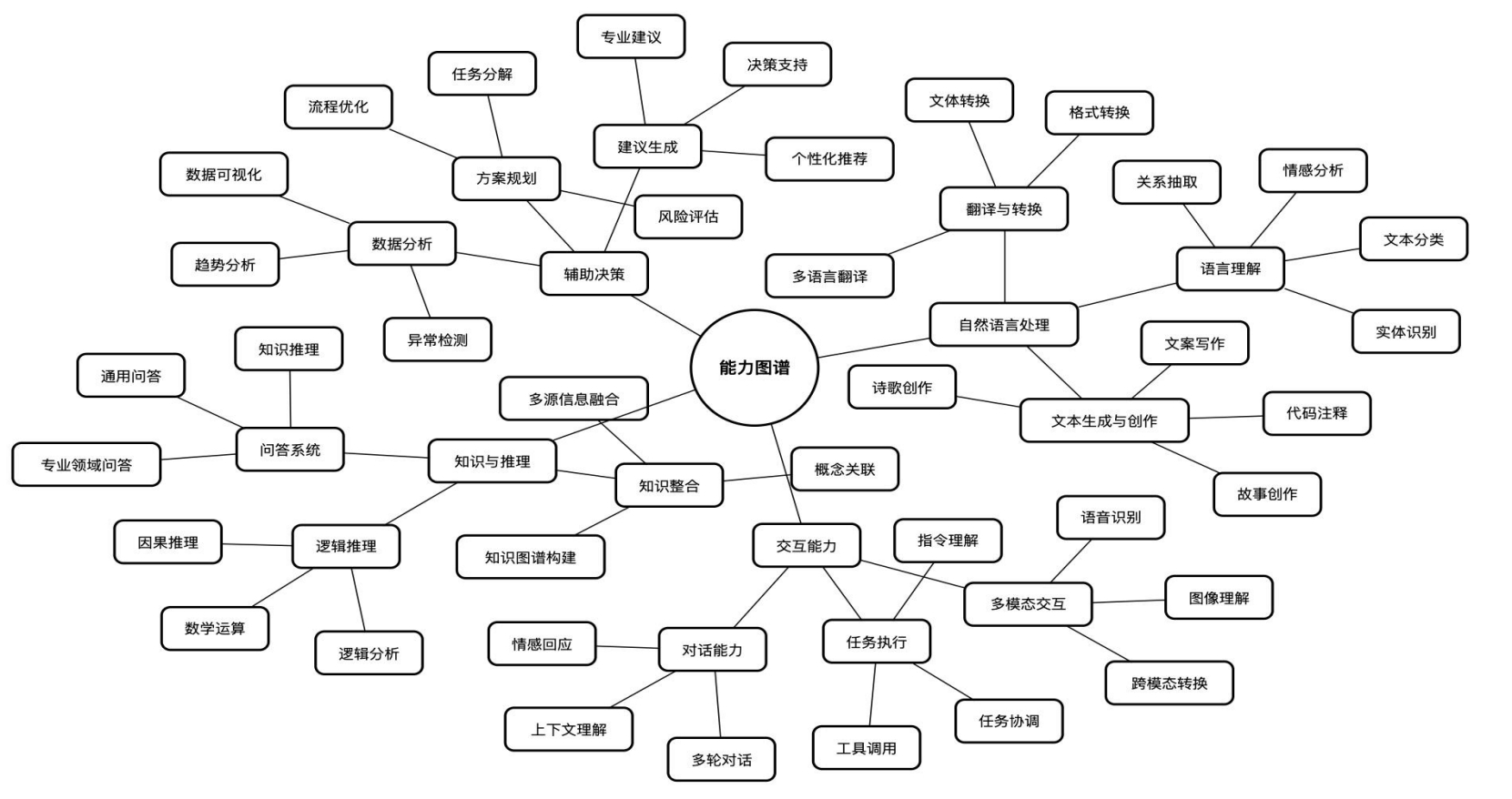
1、DeepSeek能做什么
DeepSeek可以提供智能对话、文本生成、语义理解、计算推理、代码生成补全等应用场景, 支持联网搜索与深度思考模式,同时支持文件上传,能够扫描读取各类文件及图片中的文字内容。
2、推理模型
非推理大模型: 适用于大多数任务,非推理大模型一般侧重于语言生成、上下文理解和自然语言处理,而不强 调深度推理能力。此类模型通常通过对大量文本数据的训练,掌握语言规律并能够生成合适的内容,但缺乏像 推理模型那样复杂的推理和决策能力。
推理大模型: 推理大模型是指能够在传统的大语言模型基础上,强化推理、逻辑分析和决策能力的模型。它 们通常具备额外的技术,比如强化学习、神经符号推理、元学习等,来增强其推理和问题解决能力。
例如:DeepSeek-R1,GPT-o3在逻辑推理、数学推理和实时问题解决方面表现突出。
3、如何快速使用DeepSeek
直接访问:https://chat.deepseek.com/,注册帐号即可食用。
在使用DeepSeek时,有深度思考和联网搜索两个选项,区别如下:
| 特性 | 深度思考 | 联网搜索 |
|---|---|---|
| 数据来源 | 模型内部知识 | 互联网实时信息 |
| 响应速度 | 快速 | 较慢 |
| 适用场景 | 理论分析、逻辑推理 | 实时信息、特定查询 |
| 依赖性 | 无需外部数据 | 依赖外部数据 |
因此,选择依据如下:
- 深度思考:适合理论性问题或需要快速回答的场景。
- 联网搜索:适合需要最新信息或特定数据的问题。
注意,DeepSeek近期使用量巨大,可能出现服务器繁忙等问题,短暂无法使用的情况。
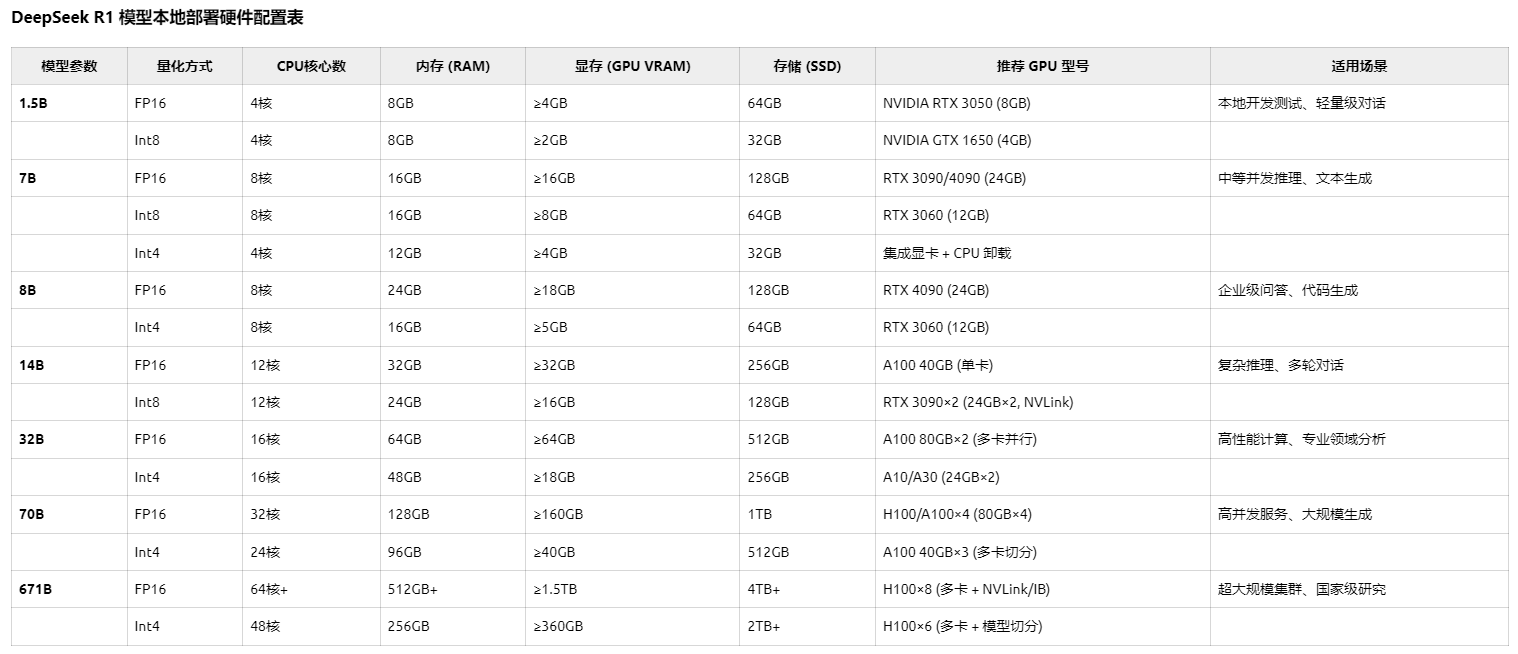
4、DeepSeek本地部署硬件配置
以下是针对不同 DeepSeek R1 模型(1.5B、7B、8B、14B、32B、70B、671B)的本地部署硬件配置建议,按模型规模分类,并基于 推理场景(非训练)的量化需求整理。 表格中显存需求已包含 20%~30% 的额外缓存预留,实际部署时需结合量化工具(如 GPTQ、AWQ)和框架优化(vLLM、DeepSpeed-Inference)调整。
1.5B、7B、8B、14B、32B、70B、671B这些模型中,只有671B是满血版本,其他都是蒸馏版本。
知识蒸馏是一种模型压缩技术,其核心思想是通过**大型教师模型(Teacher Model)指导小型学生模型(Student Model)**的学习过程。具体来说:
- 教师模型:通常是参数规模大、性能强的模型(如DeepSeek-671B),能够生成高质量的预测结果(如文本生成、逻辑推理)。
- 学生模型:通过模仿教师模型的输出(如概率分布、隐藏层特征),在保持较高性能的同时,显著减少参数量和计算资源需求。
二、本地docker部署方式(无GPU支持)
此方式是尝鲜模式,适用于没有高配硬件的环境,可使用cpu体验deepseek本地部署特性和基本使用。仅用于测试、学习、轻量级对话场景。
1、docker方式部署ollama
Ollama 是一个开源工具,专注于在本地计算机上快速部署和运行大型语言模型(LLMs),如 LLaMA、Mistral、Gemma 等。它通过简化的命令行和 API 接口,让用户无需复杂配置即可在本地体验 AI 模型的生成、对话和推理能力。
本环节使用rhel/rockylinux9版本进行介绍,docker环境的部署介绍如下: 首先,使用yum在线安装Docker CE,执行以下命令安装依赖包:
[root@localhost ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
执行下面的命令添加yum软件源:
[root@localhost ~]# yum-config-manager --add-repo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
然后,可以安装Docker CE了。
[root@localhost ~]# yum makecache fast
[root@localhost ~]# yum install docker-ce
最后,启动 Docker CE:
[root@localhost ~]# systemctl enable docker
[root@localhost ~]# systemctl start docker
下面还需要配置镜像加速器,在 /etc/docker/daemon.json 中写入如下内容(如果文件不存在请新建该文件)
{
"registry-mirrors": [
"https://proxy.1panel.live",
"https://docker.1ms.run",
"https://hub.geekery.cn",
"https://docker.m.daocloud.io",
"https://docker.rainbond.cc",
"https://docker.1panel.live"
]
}
注意,一定要保证该文件符合 json 规范,否则 Docker 将不能启动。之后重新启动服务。
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl restart docker
配置加速器之后,如果拉取镜像仍然十分缓慢,请手动检查加速器配置是否生效,在命令行执行docker info,如果从结果中看到了如下内容,说明配置成功。
[root@localhost home]# docker info
......
Registry Mirrors:
https://proxy.1panel.live/
https://docker.1ms.run/
https://hub.geekery.cn/
https://docker.m.daocloud.io/
https://docker.rainbond.cc/
https://docker.1panel.live/
Product License: Community Engine
docker环境部署成功后,就可以拉取镜像,启动ollama服务啦。
[root@rockylinux9 ~]# docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
如果你还是无法拉取ollama镜像,别急,还有招儿,我也提供了ollama镜像的国内下载,执行如下命令:
[root@rockylinux9 ~]# docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama swr.cn-north-1.myhuaweicloud.com/iivey/ollama/ollama:latest
这个肯定没问题了,容器运行起来后,默认会开启11434端口,浏览器访问11434,如果提示“Ollama is running”,说明Ollama 部署成功。
2、下载轻量级的AI模型deepseek-r1:7b来进行测试
没有GPU情况下,推荐下载基于1.5b或7b的蒸馏模型:
[root@rockylinux9 ~]# docker exec -it ollama ollama run deepseek-r1:7b
上面指令下载的是7b的蒸馏模型,如需其它版本,修改7b为其他即可,例如:deepseek-r1:1.5b
3、使用webui,docker部署open-webui
[root@rockylinux9 ~]# docker run -d -p 3000:8080 -e OLLAMA_BASE_URL="http://172.16.213.226:11434" -v open-webui:/app/backend/data --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
此步骤也可以使用Cherry Studio、Anything LLM、Chatbox替代,三者均瞄准 LLM 应用的普惠化与私有化,通过简化部署流程、增强交互体验,推动大模型技术从实验室走向实际场景。选择依据如下:
- 追求企业级功能 → Cherry Studio
- 需要多模型实验 → Anything LLM
- 注重轻量化体验 → Chatbox
下载地址为:
- Cherry Studio:Cherry Studio 官方网站 - 全能的 AI 助手 | 多模型 AI 客户端
- Anything LLM:AnythingLLM | The all-in-one AI application for everyone
- Chatbox:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
本课程主要介绍Cherry Studio的使用方法。
三、本地部署DeepSeek支持GPU
本节课我们使用rhel/rockylinux9版本进行介绍,使用GPU为NVIDIA A10,cpu 8核心,30GB内存,24GB显存。
1、升级系统内核
为了安装GPU驱动,建议升级linux系统内核,因为新版本驱动可能对老版本内核不兼容。
[root@rockylinux9 ~]# yum update
[root@rockylinux9 ~]# reboot
升级内核后重启系统,以新内核启动即可。
2、获取一键安装脚本
从ollama官网获取一键安装脚本,但默认此脚本会从github下载ollama安装包,可能无法连接,因此我提供了此安装包ollama-linux-amd64.tgz,请从课程资料中获取。
[root@rockylinux9 ~]# wget https://ollama.com/install.sh
[root@rockylinux9 ~]# chmod 755 install.sh
[root@rockylinux9 ~]# ./install.sh
此脚本执行的逻辑是从github下载ollama-linux-amd64.tgz,然后解压到/usr/local下,并生成ollama.service配置脚本,然后重启ollama服务,接着,会根据操作系统版本获取epel源,然后,自动获取系统GPU信息,同时,根据操作系统版本,结合GPU类型,选择合适的显卡驱动安装源,并下载yum源到本地,最后自动安装GPU显卡驱动。
此脚本在rhel/rockylinux9系统环境中,最后一步可能安装出错,提示找不到GPU软件包,此时需要手动安装GPU显卡驱动,后面有介绍如何手动安装方法。
新增内容:
由于install.sh脚本默认会从github下载ollama二进制安装包,某些网络环境可能无法连接github,因此install.sh脚本可能无法执行成功,此时,就需要手动部署ollama环境,以及配置epel源和cuda安装源,ollama二进制包ollama-linux-amd64.tgz、epel源我已经在网盘提供,可下载到服务器,执行步骤如下:
[root@rockylinux9 ~]# tar zxvf ollama-linux-amd64.tgz -C /usr/local
然后从网盘下载epel-release-latest-9.noarch.rpm文件,执行安装:
[root@rockylinux9 ~]# rpm -ivh epel-release-latest-9.noarch.rpm
最后,从网盘下载cuda-rhel9.repo文件放到/etc/yum.repos.d路径即可。这些步骤完成,继续下面步骤。
3、ollama配置并启动服务
ollama默认运行在本机127.0.0.1,监听11434端口,我们需要让ollama监听在所有端口,修改ollama脚本文件:
[root@rockylinux9 ~]# vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.target
其中,Environment="OLLAMA_HOST=0.0.0.0"和Environment="OLLAMA_ORIGINS=*"是新增内容。
如果是手动部署(非install.sh脚本安装)的ollama,还需要在系统中创建一个ollama用户:
[root@rockylinux9 ~]# useradd ollama
最后,重启ollama服务:
[root@rockylinux9 ~]# systemctl daemon-reload
[root@rockylinux9 ~]# systemctl restart ollama.service
[root@rockylinux9 ~]# netstat -atnlp
4、使用docker容器调用GPU部署ollama
上面步骤是物理机安装ollama方式,如果想docker部署并调用gpu,可执行如下命令:
[root@deepseek ~]# docker run -d --gpus all -v ollama:/root/.ollama -p 11434:11434 --name ollama swr.cn-north-1.myhuaweicloud.com/iivey/ollama/ollama:latest
但是,上面操作会失败,因为通过 --gpus 参数来使用宿主机的GPU时,需要先安装一个英伟达的容器运行时nvidia-container-runtime,步骤如下:
[root@deepseek ~]# yum install nvidia-container-runtime
[root@deepseek ~]## systemctl restart docker
然后再次运行如下命令:
[root@deepseek ~]# docker run -d --gpus all -v ollama:/root/.ollama -p 11434:11434 --name ollama swr.cn-north-1.myhuaweicloud.com/iivey/ollama/ollama:latest
这样就成功了。要验证 GPU 是否生效,进入容器执行命令,检查 GPU 是否被识别:
[root@deepseek ~]# docker exec -it ollama nvidia-smi
最后一步,下载合适版本的模型参数:
[root@deepseek ~]# docker exec -it ollama ollama run deepseek-r1:7b
这样,容器方式部署deepseek本地大模型并调用GPU就完成了。
5、安装显卡驱动(没显卡,可跳过此步骤)
下面是手动安装显卡驱动过程,首先安装CUDA驱动,CUDA是英伟达公司设计研发一种并行计算平台和编程模型,它包含运行时内核、设备驱动程序、优化库、开发工具和丰富的API组合,使得开发人员能够在支持 CUDA 的 GPU 上运行代码,大幅提升应用程序的性能
[root@rockylinux9 ~]# dnf install cuda
检查 NVIDIA 驱动是否安装
[root@rockylinux9 ~]# rpm -qa | grep -E "nvidia|kmod"
查看模块是否加载:
[root@rockylinux9 ~]# lsmod | grep nvidia
确保 dkms 已安装,并正确注册 NVIDIA 驱动, 查看驱动是否注册:
[root@rockylinux9 ~]# sudo dkms status
如没有注册 NVIDIA 驱动,可手动进行安装注册:
[root@rockylinux9 ~]# /usr/bin/bash /sbin/dkms install -m nvidia-open -v 570.86.15
其中,570.86.15是驱动版本号。
安装成功后,执行nvidia-smi命令,即可查看NVIDIA 驱动的版本和状态:
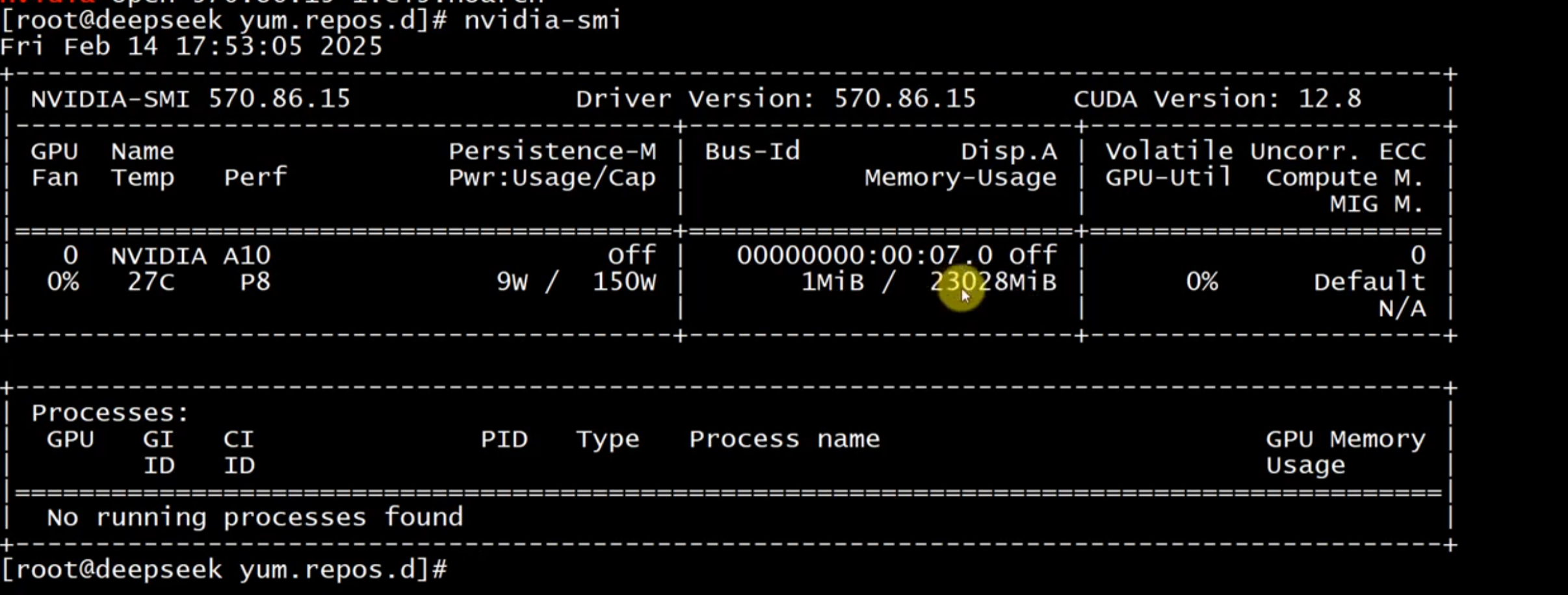
最后,重启服务器:
[root@rockylinux9 ~]# reboot
6、安装deepseek R1模型
可根据自身机器硬件配置,选择合适版本的模型参数,这里以7b为例,执行如下:
[root@rockylinux9 ~]# ollama run deepseek-r1:7b
更大的模型参数,具有更强的知识容量和推理能力。实际选型需结合任务复杂度、硬件条件、数据隐私需求综合判断。例如,医疗诊断推荐 32B+ 模型以保证准确性,而智能家居控制用 1.5B 模型即可满足需求。
7、部署客户端工具
为例更好的和AI交互,推荐使用客户端工具 ,这里我使用Cherry Studio。
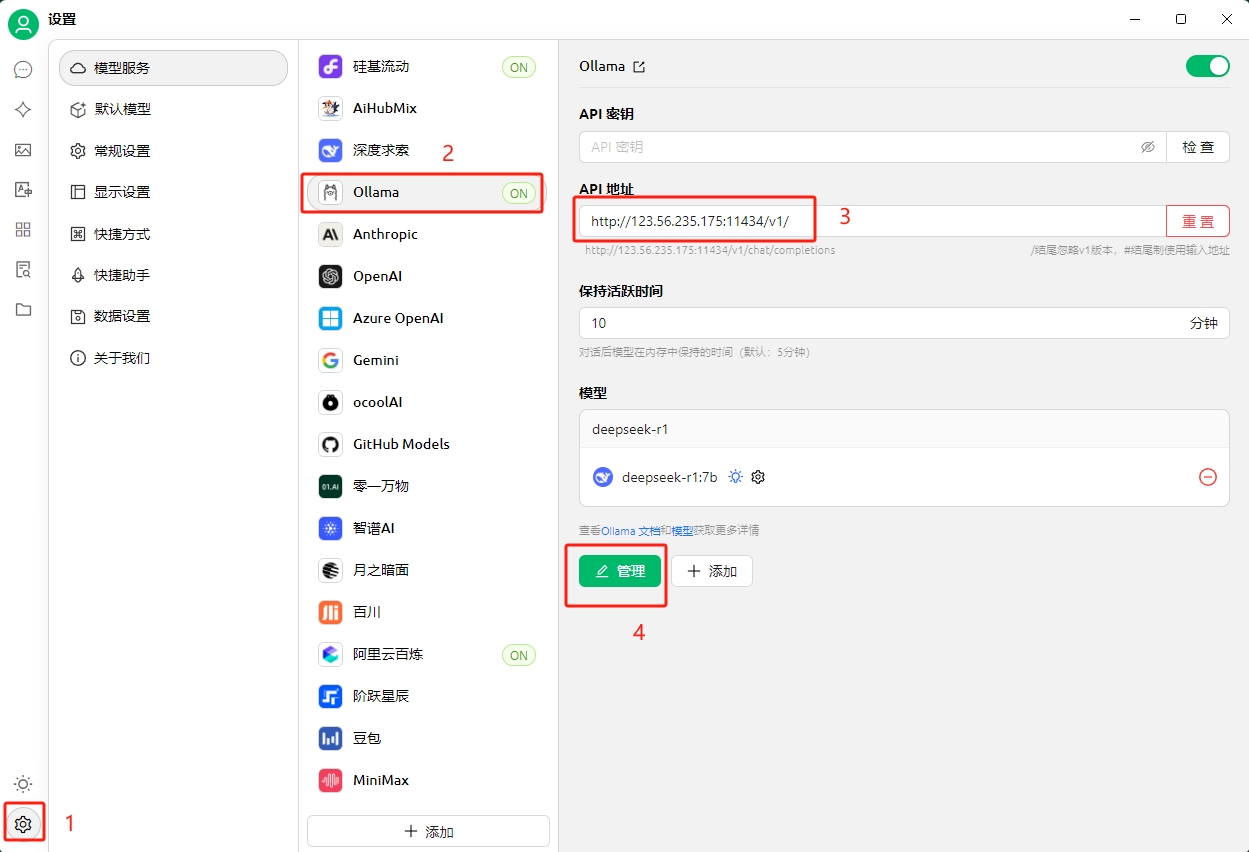
四、总结
本文完整讲解了DeepSeek-R1大模型的核心概念、能力特性,同时提供了CPU轻量化部署和GPU高性能部署两套落地方案,覆盖新手测试、生产使用全场景。通过配置国内Docker镜像加速器,彻底解决了国外镜像拉取慢、超时失败的问题,搭配Ollama工具实现了极简的大模型本地化运维。
相较于在线模型,本地部署的DeepSeek-R1无需担心服务器拥堵、数据泄露问题,延迟更低、稳定性更强。个人学习优选1.5B/7B蒸馏模型,企业生产场景可根据硬件配置升级大参数模型,搭配Cherry Studio、Open-WebUI等可视化工具,可快速搭建专属私有化AI服务。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)