解决qwen2 7B回复乱码问题
·
在LM studio中使用qwen2时遇到了回复乱码问题,总是回复很多GGGGGG
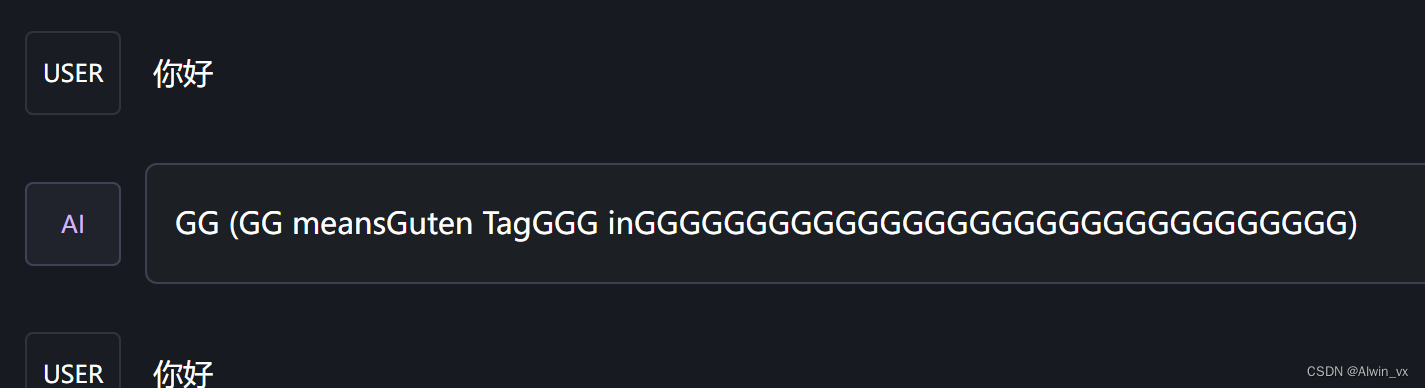
通过网络搜索,都说是llama.cpp的问题,需要设置flash attention。

在LM studio的界面中找到对应选项,界面的右侧model initialization展开后,选中flash attention。重新加载模型,即可让qwen2正常工作,而且速度特别快。
你也来试试吧!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)