【应用篇】MLU上deepseek/QwQ-32B+dify实现workflow应用
文章目录
前言
本章主要讲解如何用paas平台,实现智能体应用
本章中大模型我们使用deepseek-R1-14B,当然QwQ也是可以使用的,根据您需要选择合适得模型
智能体应用平台,直接调用dify,当然可以直接通过Github裸金属私有化部署也是ok得
今日目标:用dify搭建一个workflow【上传文档->自动总结文档】
一、平台环境选择
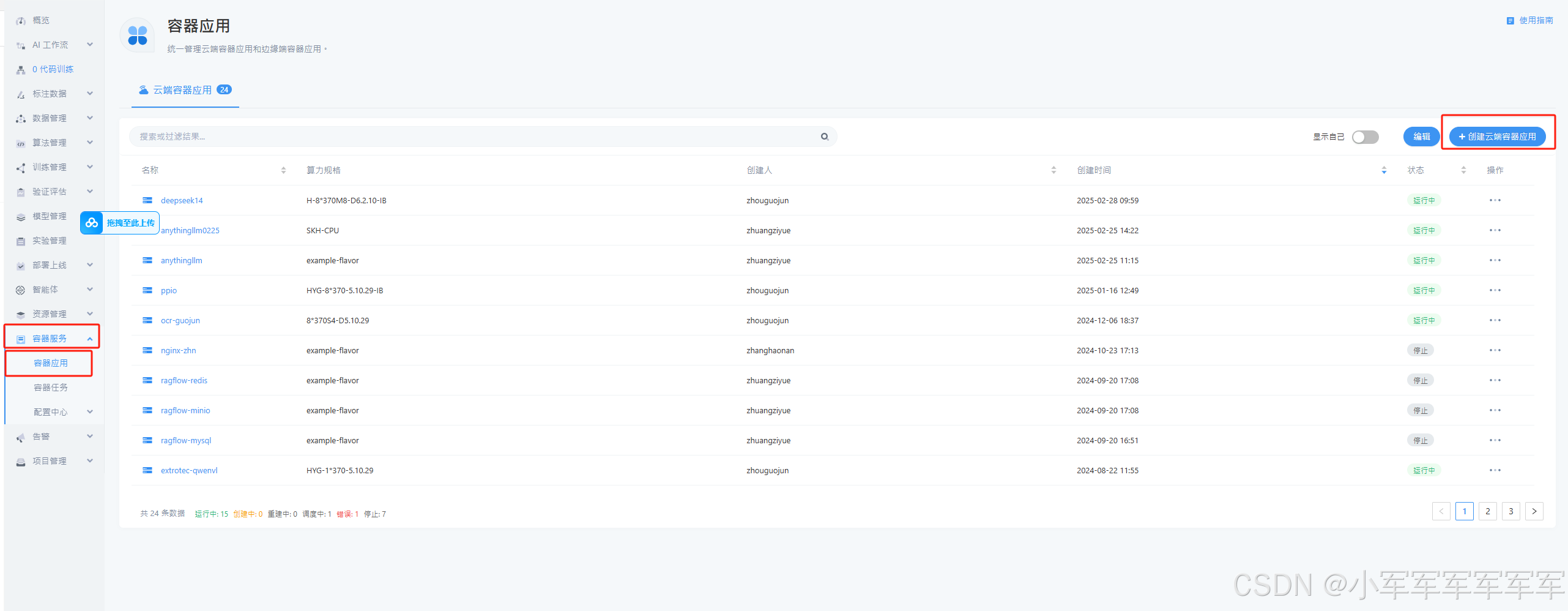
今天我们要使用的是平台的容器能力,该容器可以直接把我们得内部tcp服务直接映射出来,更有利得去为我们提供大模型等相关模型的api服务
镜像选择:2501 【如何把镜像变成容器应用得镜像,可以参考平台右上角指南】
能联系上我的话,我也可以提供重构好的镜像
流程是设置启动命令->设置容器密码->重新上传新镜像至资源管理即可
二、创建容器应用
点击创建云端容器应用
任意选择一款显卡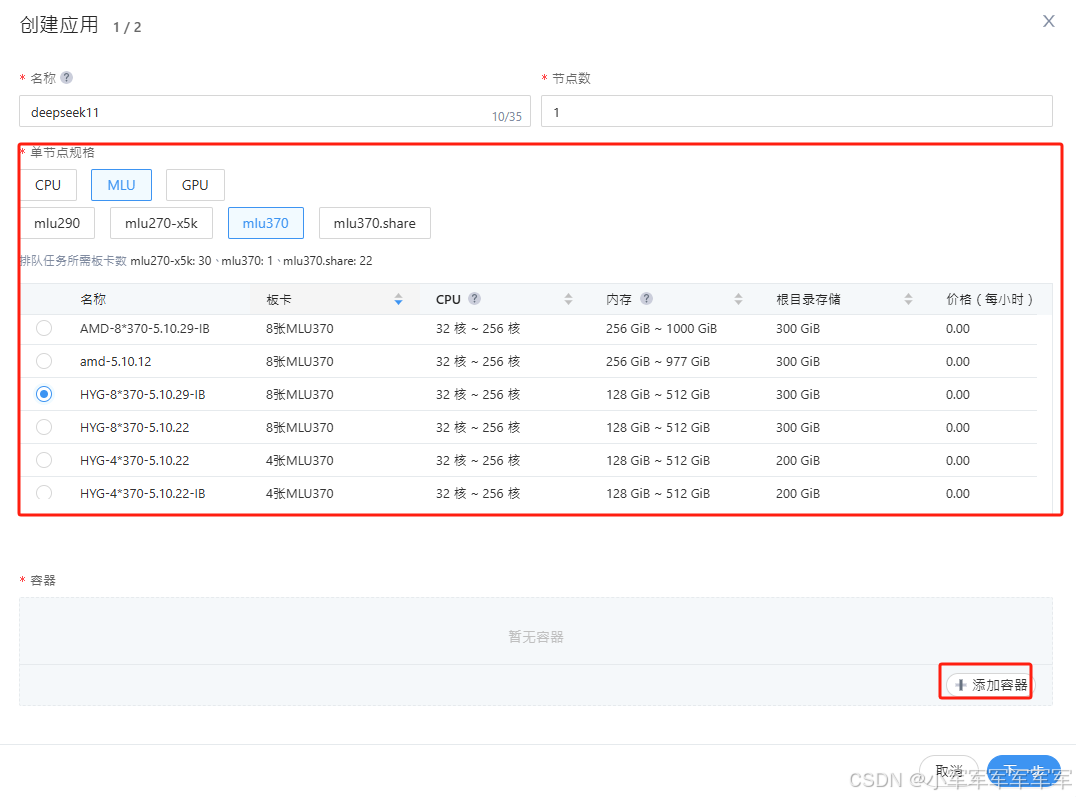
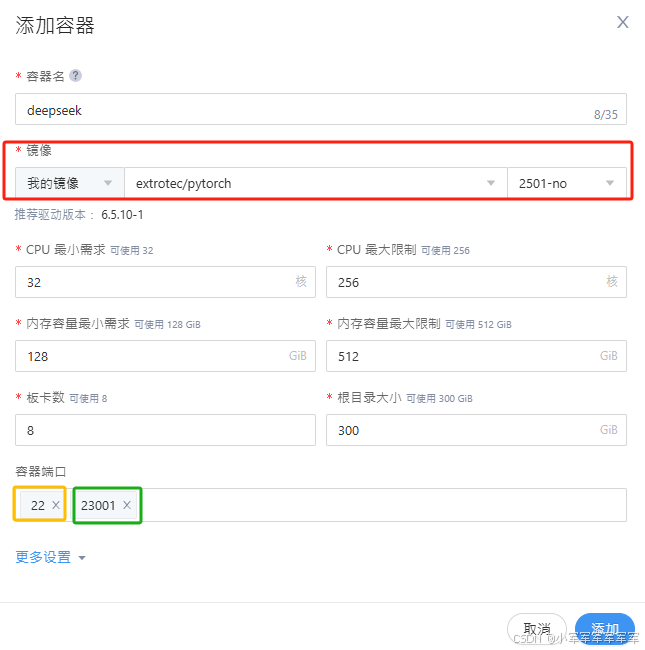
红色框为镜像,黄色框为ssh端口 绿色框为业务端口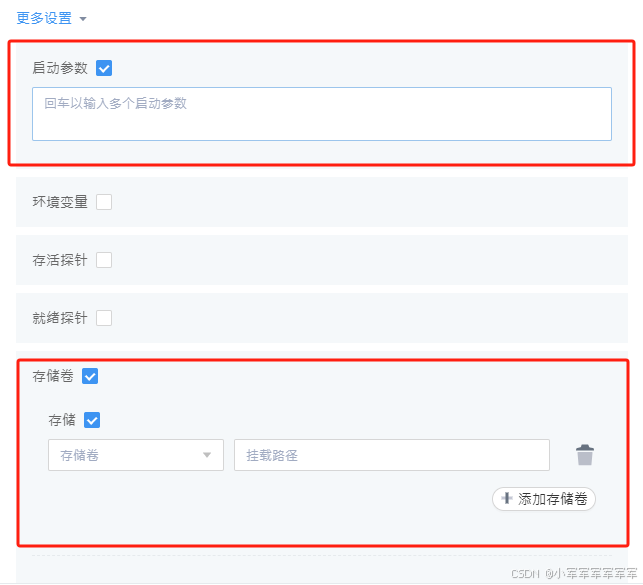
启动参数:如果你在重构镜像时已经有启动参数了,即可忽略,如果没有可以考虑在启动参数写个无限循环,然后ssh进去操作
存储卷:挂载相关存储
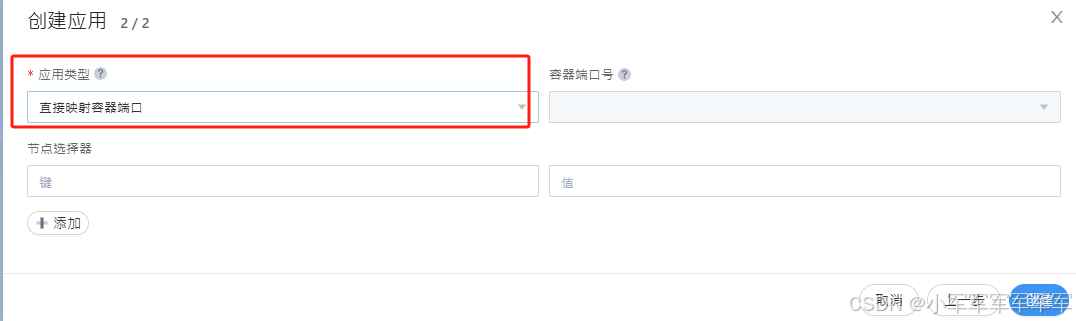
直接创建即可
以下为创建成功得效果,你可以根据自己设置的端口,先ssh进去,启动相关的服务,就可以在外网访问了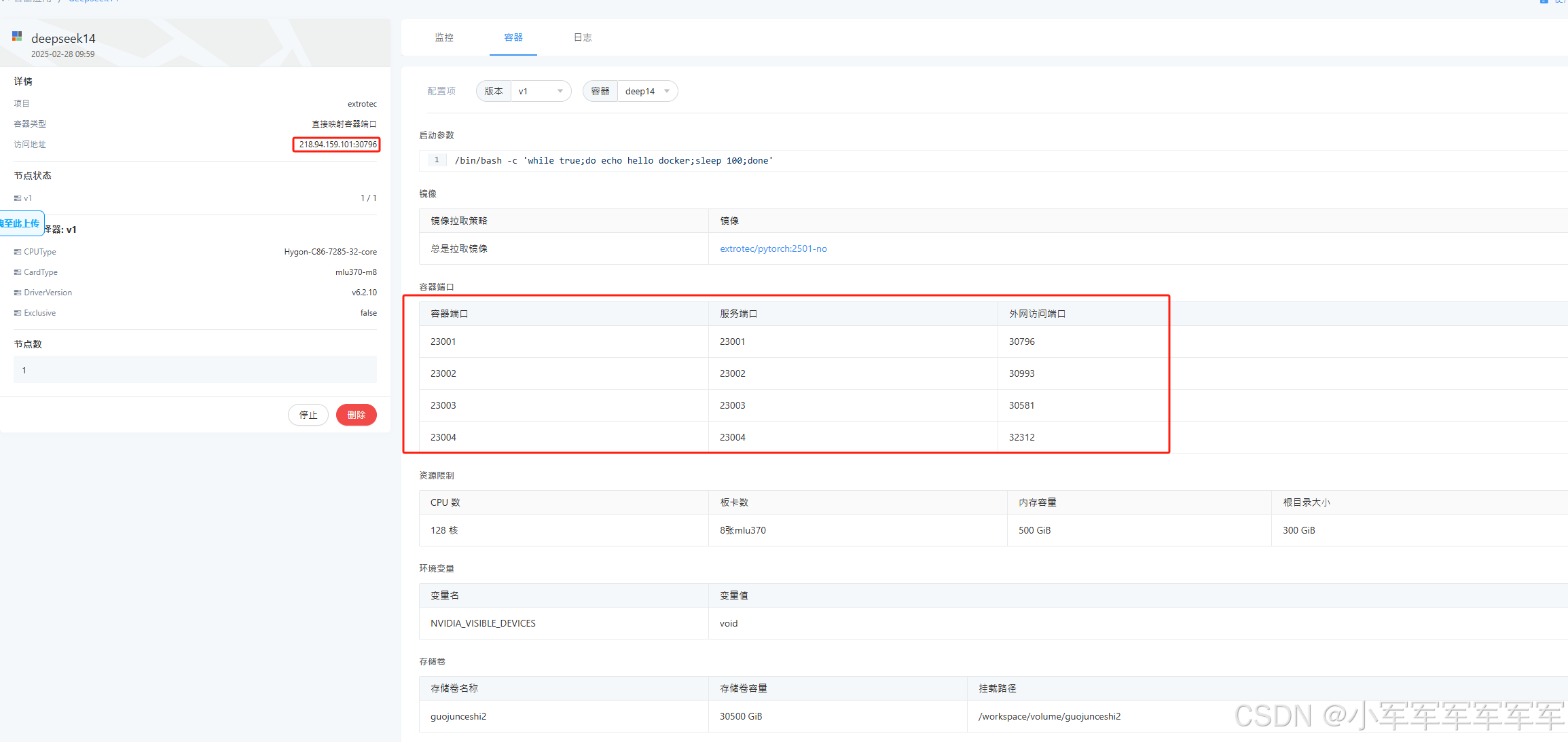
三、启动服务
以下操作请直接ssh到容器中使用
1.下载deepseekR1-14B模型
git-lfs clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B.git
2.VLLM启动服务
source /torch/venv3/pytorch_infer/bin/activate
vllm serve /workspace/volume/guojunceshi2/DeepSeek-R1-Distill-Qwen-14B_fp16/ --dtype="float16" --trust-remote-code --served-model-name dify-test --gpu-memory-utilization 0.98 --tensor-parallel-size 8 --port 23002 --block_size 8192 --max_model_len 8192
#注意--port改成你创建时得端口容器
3.postman测试服务
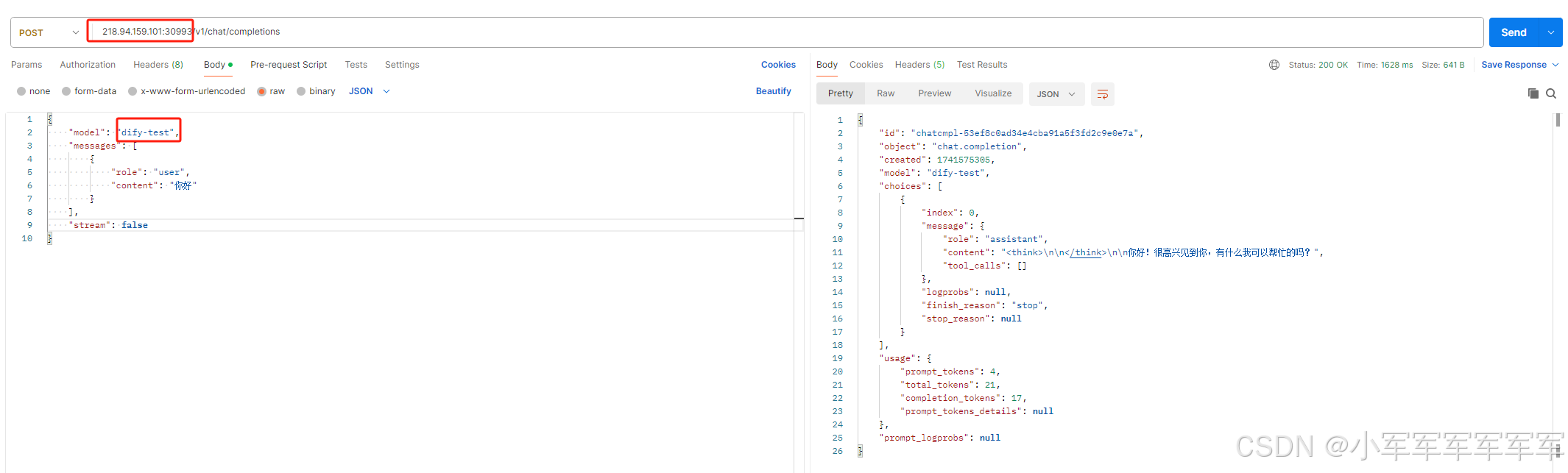
服务映射成功
四、workflow搭建
https://dify.ai/zh #可以使用官网,也可以自己找个裸金属docker私有化部署
docker部署方式请github搜dify详查
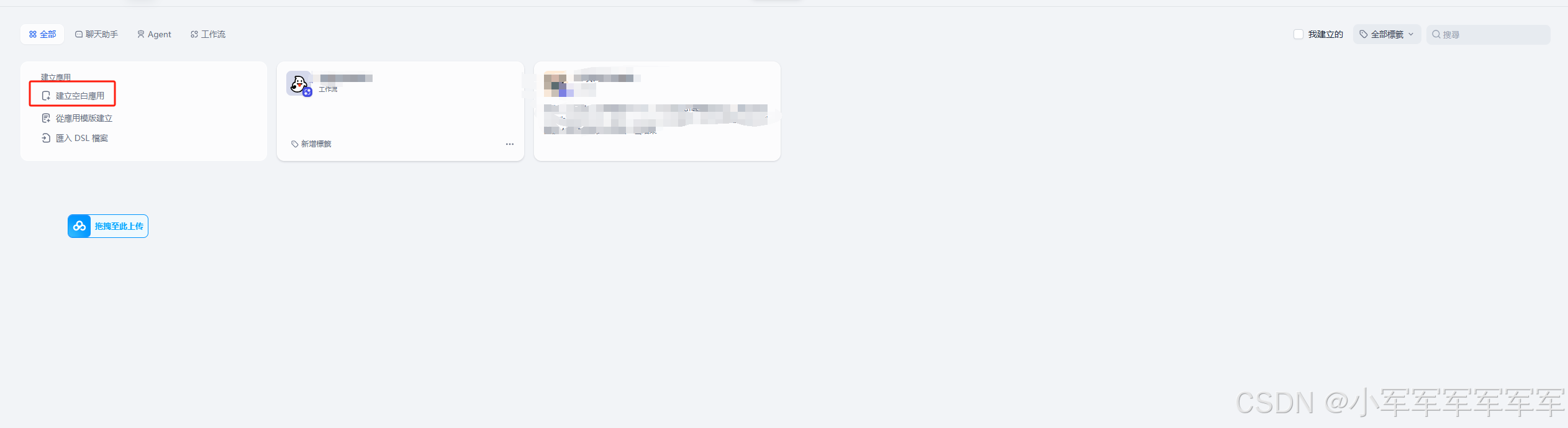
1.搭建第一个工作流
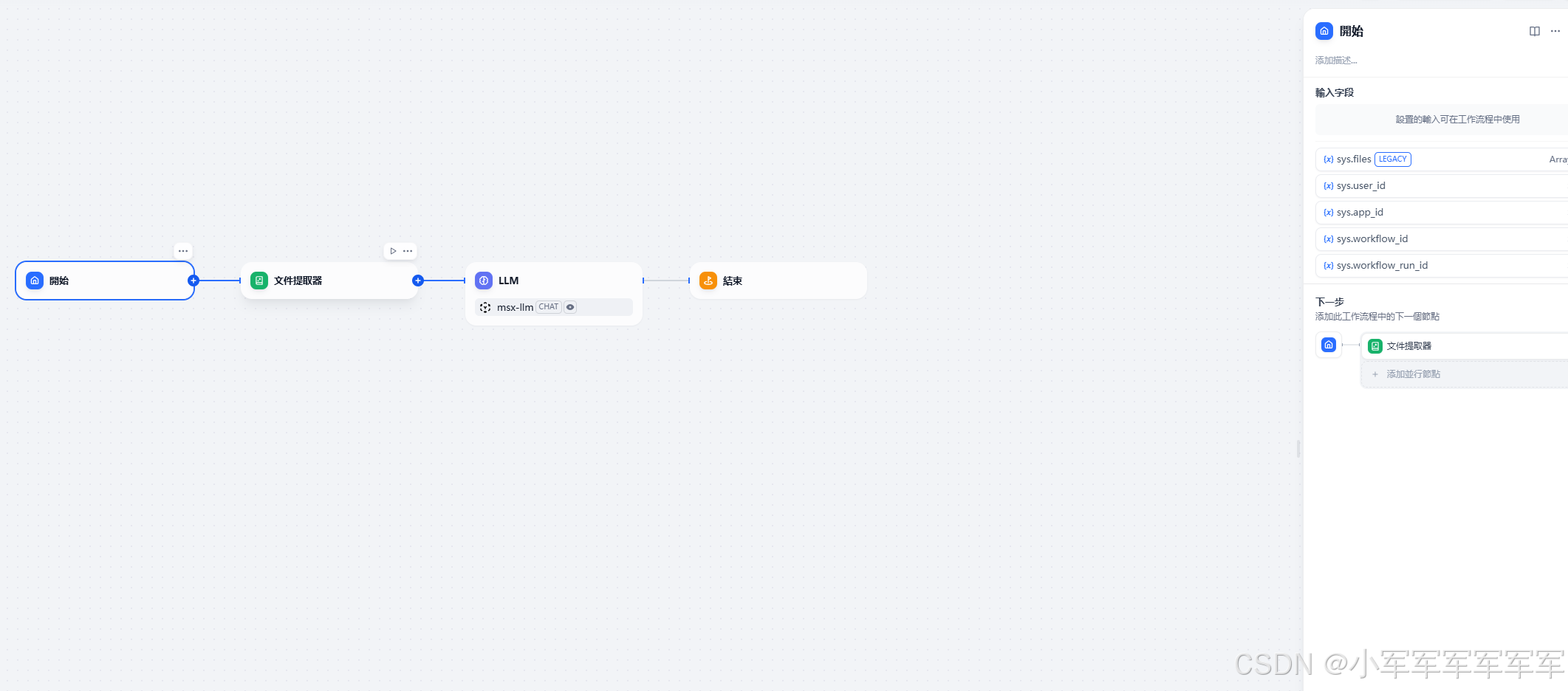
2.详细配置
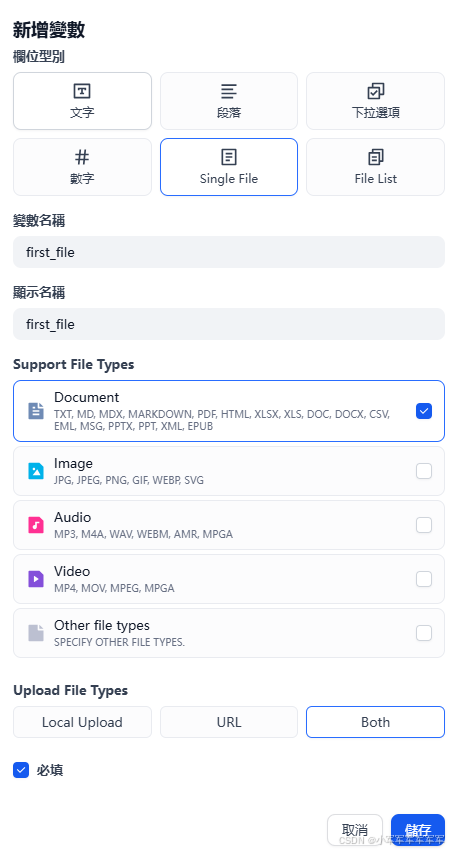
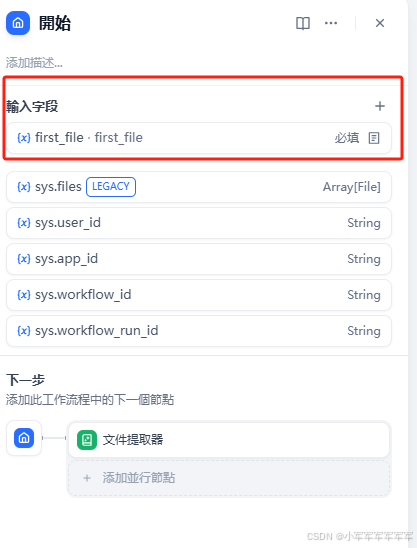
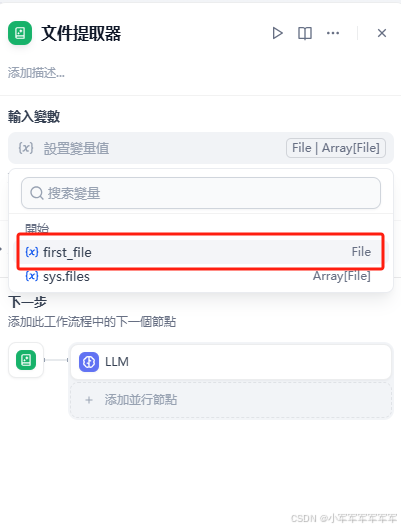
LLM配置
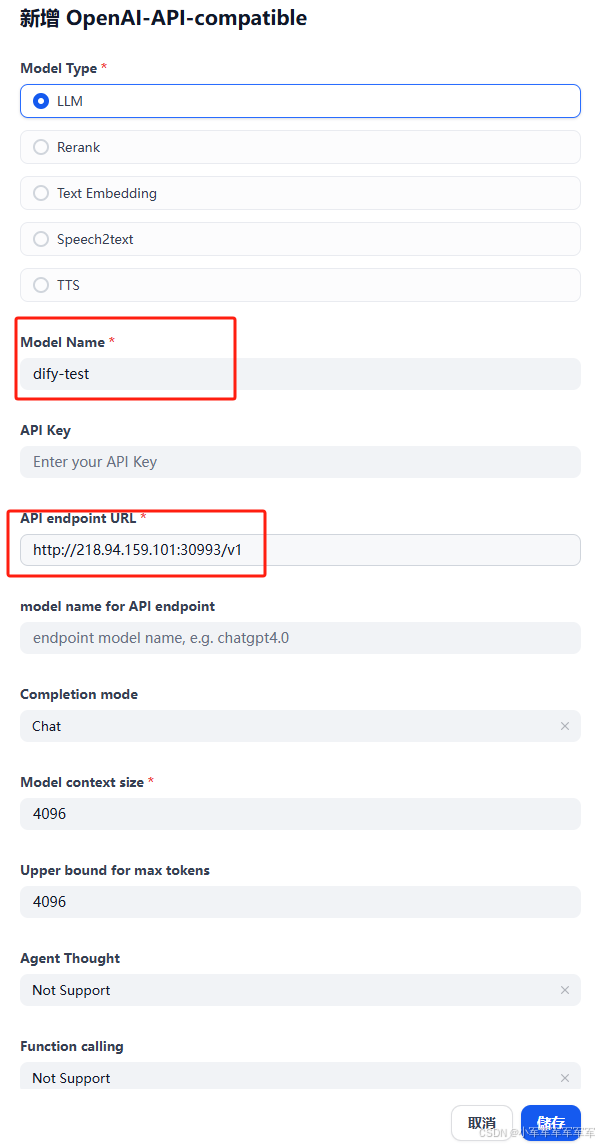
着重关注红框部分
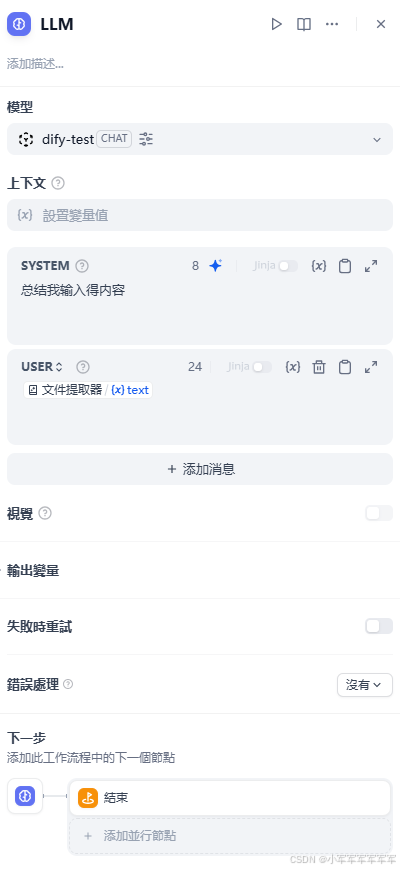
简单设置提示词,让他总结我们输入的文档内容
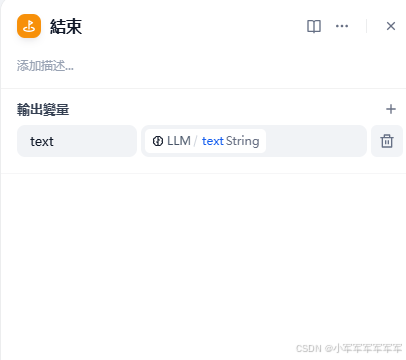
右上角发布
五、效果演示
在上方探索可以看到我们发布的workflow
我们简单上传一部小说,这边开始自动化帮我们做总结了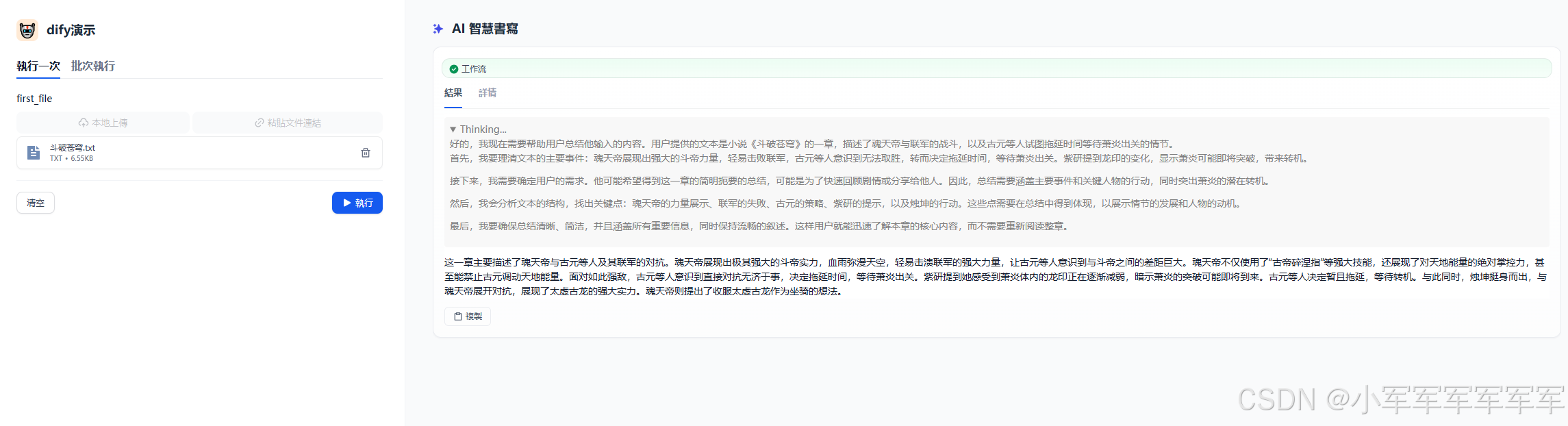
结束!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)