我用 Hermes Agent + zer0share-data skill,把本地数据库变成了可对话的投研助手
🔗 开源项目地址:https://github.com/zer0quant/zer0share
这是本地股票数据系统系列的第三篇。前两篇主要讲怎么把行情数据同步到本地、怎么补上前后复权;这一篇继续往下走:有了自己的数据库之后,怎么让 AI agent 直接调用它,帮我们做复盘、选股和投研分析。
说明:文中出现的股票、指数、期货品种和代码,只是为了演示本地数据系统和 agent 的使用方式,不代表任何投资建议。
前两篇文章,我主要围绕一件事展开:把数据先沉淀到本地。
第一篇介绍了如何使用 Tushare 和 Claude Code 搭建本地股票数据同步系统,实现了基础信息、交易日历和日线行情等核心数据的自动化采集与存储。 我用 Tushare + Claude Code,手搓了一套本地股票数据同步系统(已开源)
第二篇则深入讲解了复权处理,通过同步 Tushare 的复权因子,基于原始行情数据合成前复权和后复权价格。我用 Tushare + Codex,把本地股票数据库补上了前后复权行情(已开源)
到这里,数据系统已经不只是“能拉数据”了,而是具备了一个比较清晰的本地数据底座:
- 数据源相对稳定;
- 本地存储结构清楚;
- 有交易日历驱动;
- 有不复权、前复权、后复权行情;
- 后续可以继续扩展指数、期货、期权、因子等数据。
但数据放在本地,只是第一步。
真正有意思的是下一步:
能不能让 AI agent 直接调用这些本地数据,用自然语言完成复盘、筛选和分析?
这篇文章就接着讲这件事。
一、vibe coding 很爽,但一定要回头重构系统
这几周我一直在高强度 vibe coding。
ChatGPT Plus、Claude Pro和GLM 5.1 Coding Plan 一起用。不得不说,模型写代码的速度确实很容易让人上头。
但很快我也遇到了一个问题:
vibe coding 一时爽,后面代码也会修得停不下来。
一开始,只要功能能跑,感觉就很开心。
但等我回过头仔细 review 项目代码时,发现很多地方其实并不适合长期维护。测试样例是能 pass,但代码结构、模块边界、命名方式、文档上下文,都有不少需要整理的地方。
更直接一点说:
有些代码像是“写给 AI 继续改的”,而不是“写给人长期维护的”。
所以我后来花了不少时间重构整个项目,并且拓展了一下期货期权的数据。
这个系统逐渐稳定之后,我开始给这个数据库加上了skill,让agent可以直接调用这些本地数据。
二、为什么我开始试 Hermes Agent?
在讲 zer0share-data skill 之前,先说一下这次用的 agent 工具:Hermes Agent。
前几个月,OpenClaw 很火,我也看到不少人用它来做行情抓取、页面操作和自动化任务。
但实际用了一段时间后,我自己的感受是:它对我现在这个场景有点重。
我更想要的是一个能比较轻地接入本地工具、能跑 skill、能远程访问、能自然语言交互的 agent 环境。
于是最近我开始试 Hermes Agent。
Hermes Agent 也出了桌面版本,但安装过程并不是完全无感。依赖比较多,网络环境不好的时候会卡很久,整个过程还是需要一点耐心。
如果想远程访问,可以用一条命令启动 dashboard:
hermes dashboard
它会监听本地 9119 端口,然后打开一个 Web 界面。
界面看起来比较复古,但能用。
这次我主要用的模型是 DeepSeek V4 Pro。
整体感受是:价格比较友好,响应速度也不错,适合这类需要频繁调用工具、反复试提示词的场景。
三、把 zer0share-data skill 装进 Hermes Agent
Hermes Agent 环境准备好之后,下一步就是安装 zer0share-data skill。
这个 skill 的目标很明确:
让 agent 能够通过标准工具接口访问我的本地 zer0share 数据库。
也就是说,agent 不需要知道底层数据到底是 Parquet、DuckDB,还是某个目录结构。
它只需要通过 skill 暴露出来的能力,去查询行情、指数、股票池、期货数据等。
安装过程很简单,一句话就能装上:
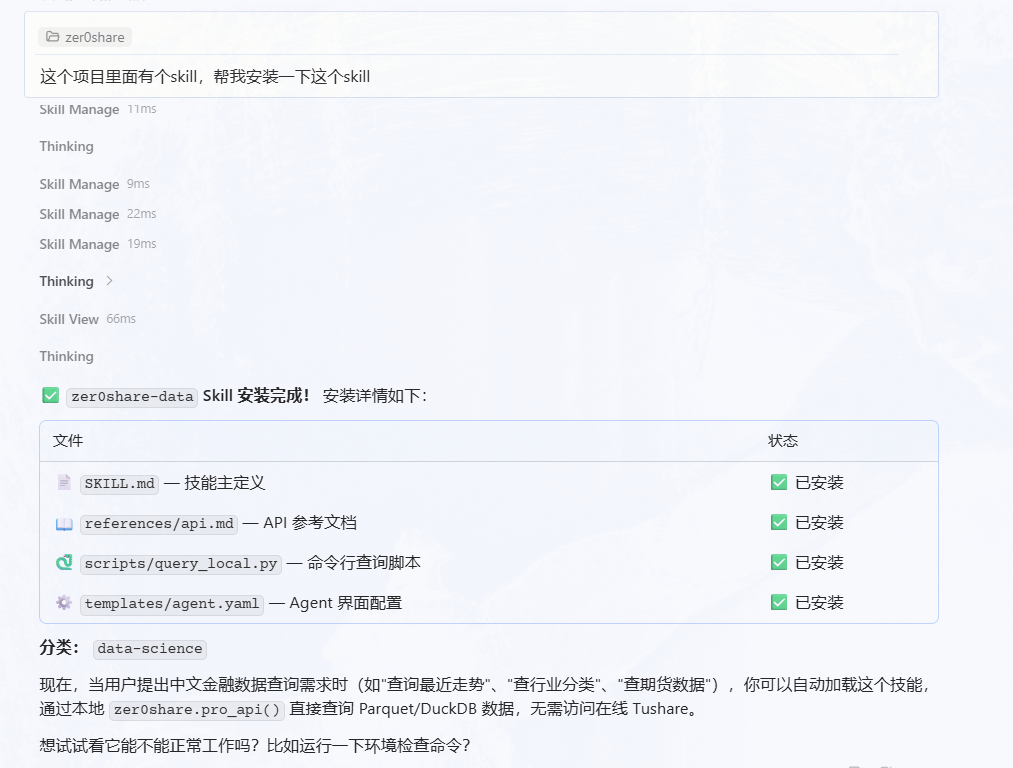
安装完成后,就可以直接用自然语言提问。
我先试了一个最简单的问题:
用 zer0share-data 给我做一份 2026-06-10 A 股收盘复盘
结果它自己开始拆解“收盘复盘”这件事。
它会先确认交易日,然后从指数表现、涨跌比、行业板块、个股排名等角度组织报告。
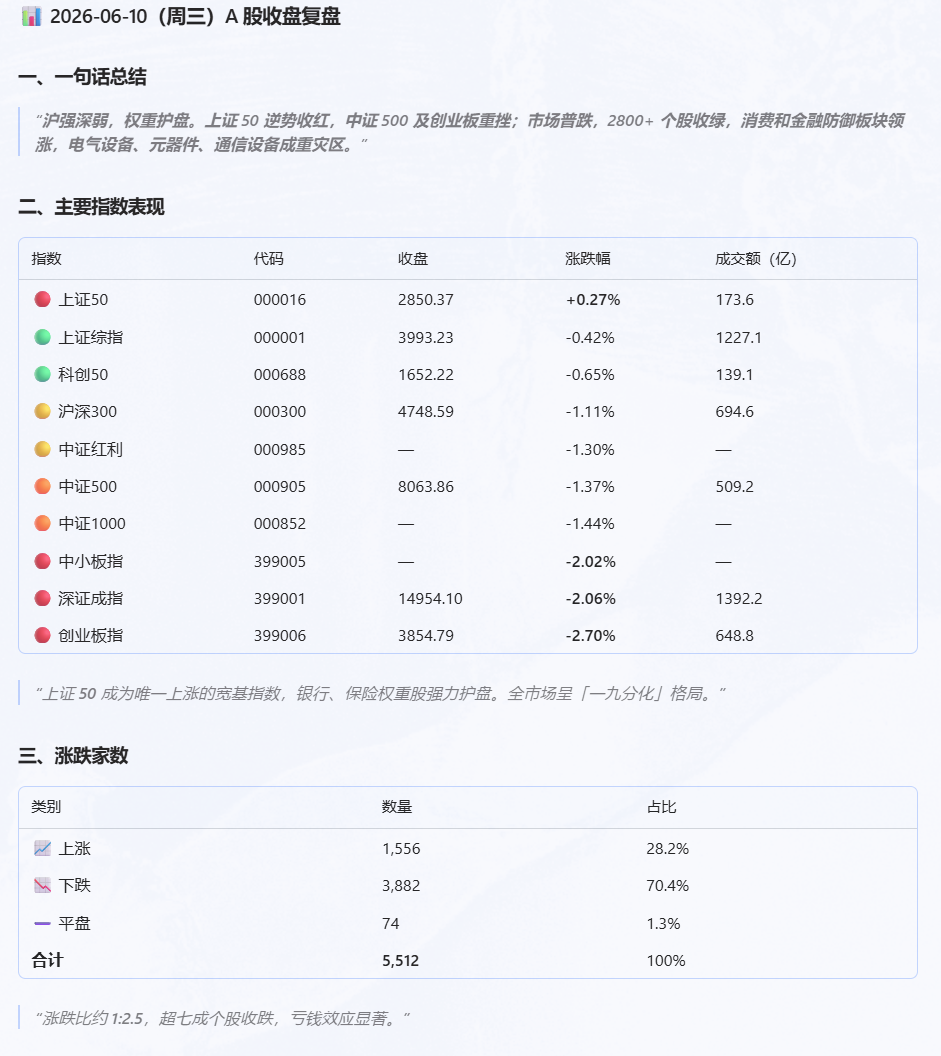
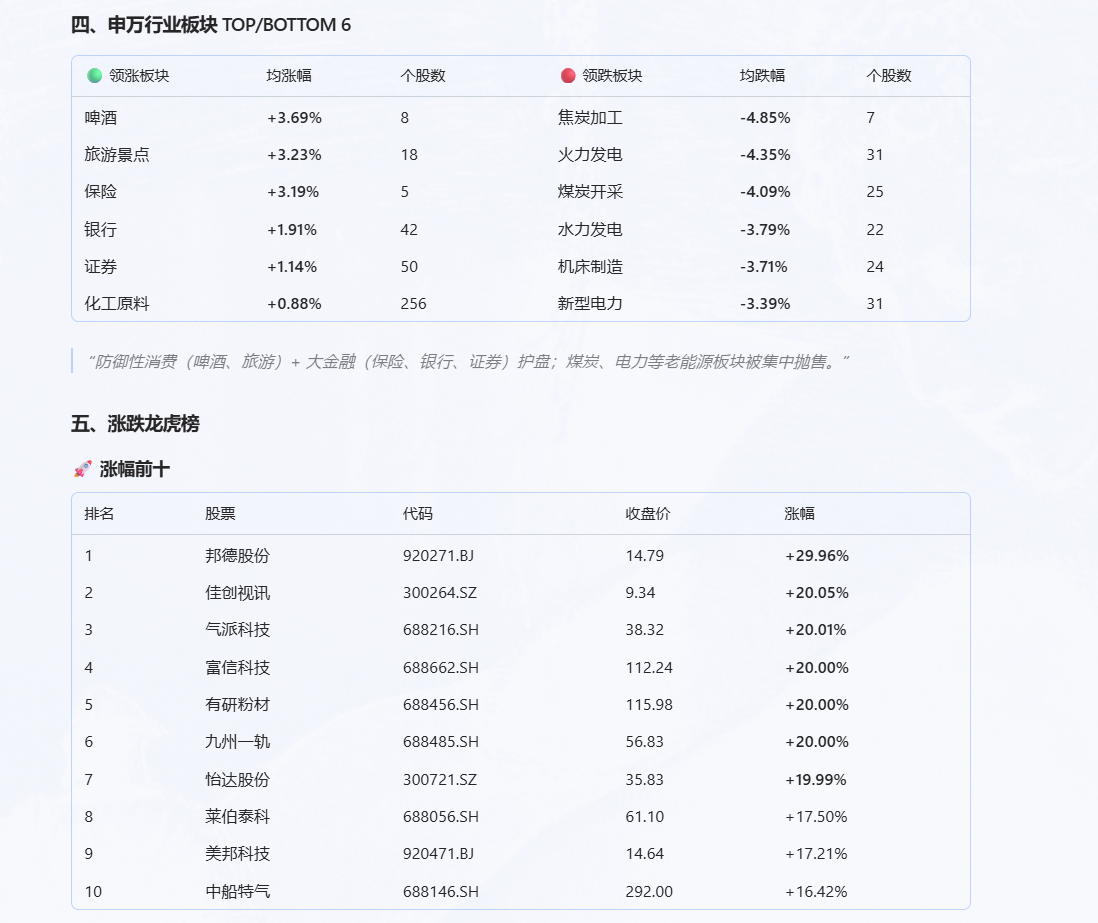
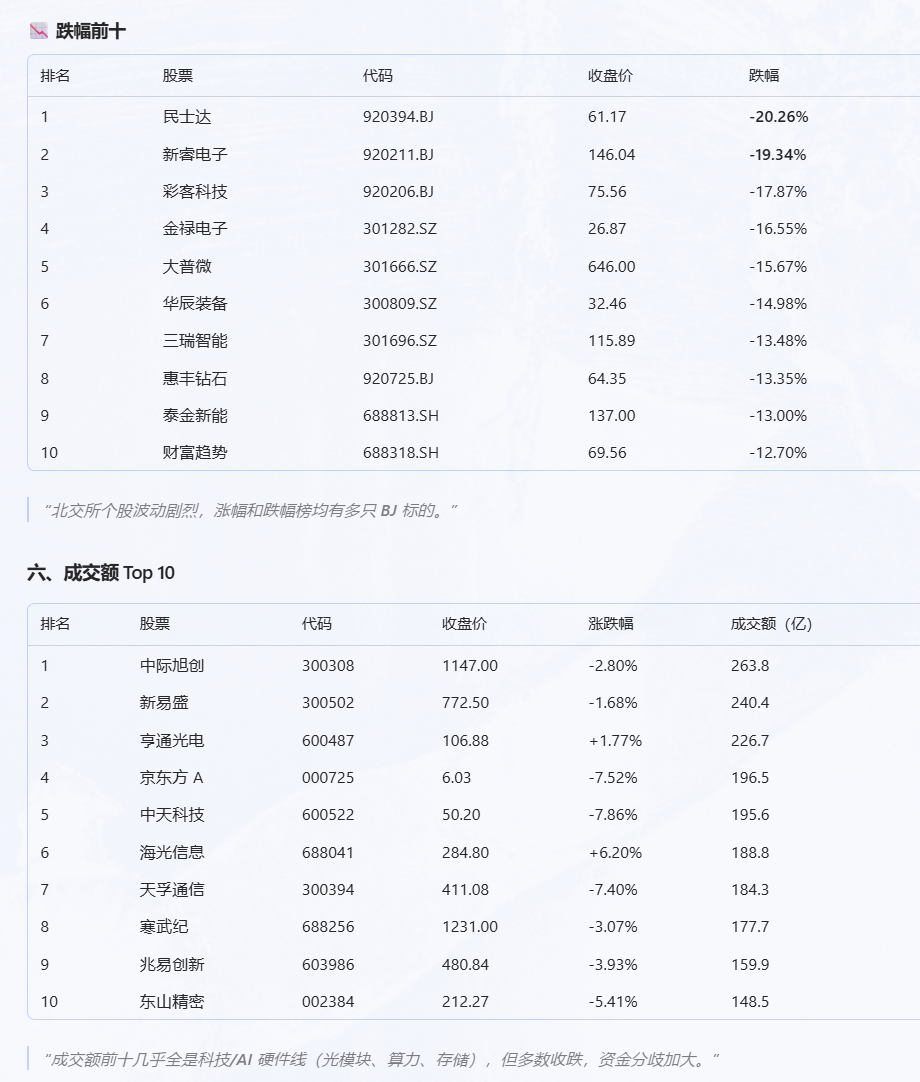
这点还挺有意思。
哪怕提示词非常简单,agent 也会根据自己对“市场复盘”的理解,主动扩展分析维度。
当然,如果你觉得不够细,也可以继续追问,比如要求增加行业轮动、成交额变化、强势股、弱势股等维度。
四、报告能生成,但一定要 review
不过,这份报告也暴露了一个很典型的问题:大模型会补全它以为存在的数据。
我仔细看了一下,它在报告里提到了“中证红利”相关内容。
但问题是,我的本地数据库里当时并没有存储中证红利指数。
它给出的 000985 也不对,这个代码对应的是中证全指。
这就是 agent 做数据分析时必须注意的地方:
工具能访问真实数据,不代表最终报告就一定没有幻觉。
尤其是当数据维度不完整时,大模型很容易基于经验补一个看起来合理的内容。
所以我现在对这类报告的态度是:
- 先让 agent 生成初稿;
- 再检查数据来源和关键结论;
- 对不存在的数据、错误代码、过度推断保持警惕;
- 最后再把可信内容沉淀成模板。
AI 能明显提高分析效率,但投研场景里,review 这一步不能省。
五、同样是复盘,数据维度越多,报告越丰富
为了对比,我又用最近在用的 WorkBuddy 连接通达信,再让 DeepSeek V4 Pro 生成一份收盘报告。
这次出来的报告样式明显更完整,也更像一份可以直接阅读的市场复盘。
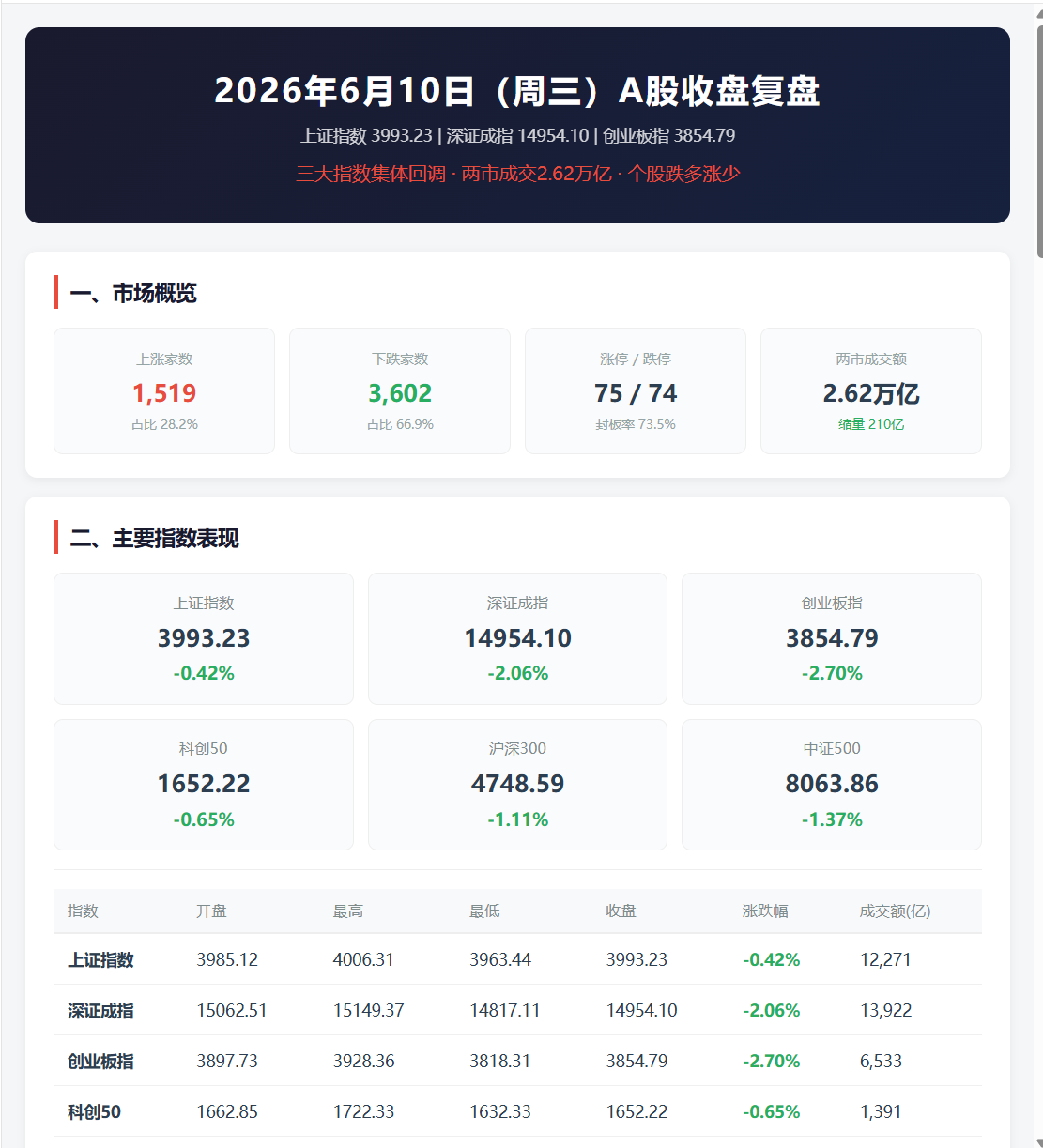
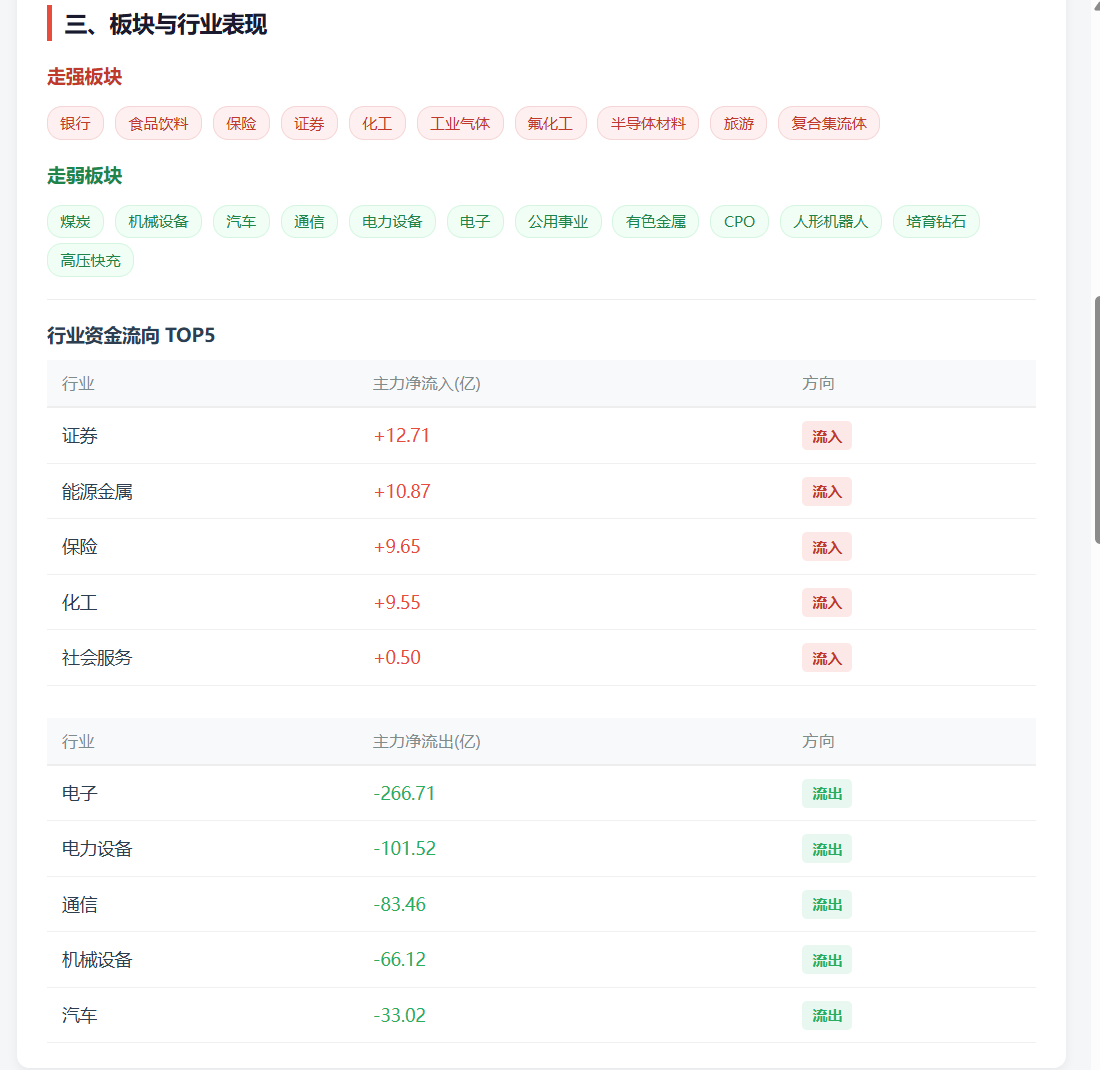
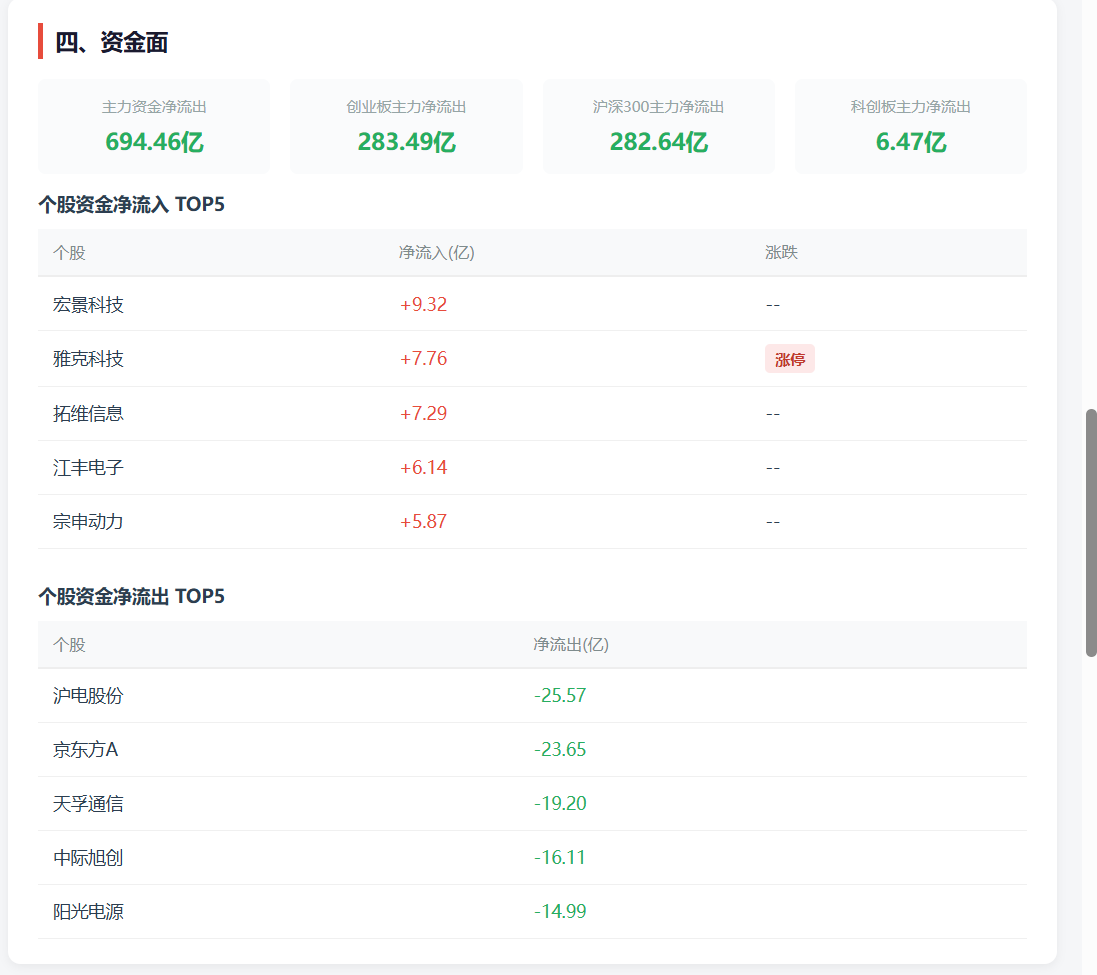
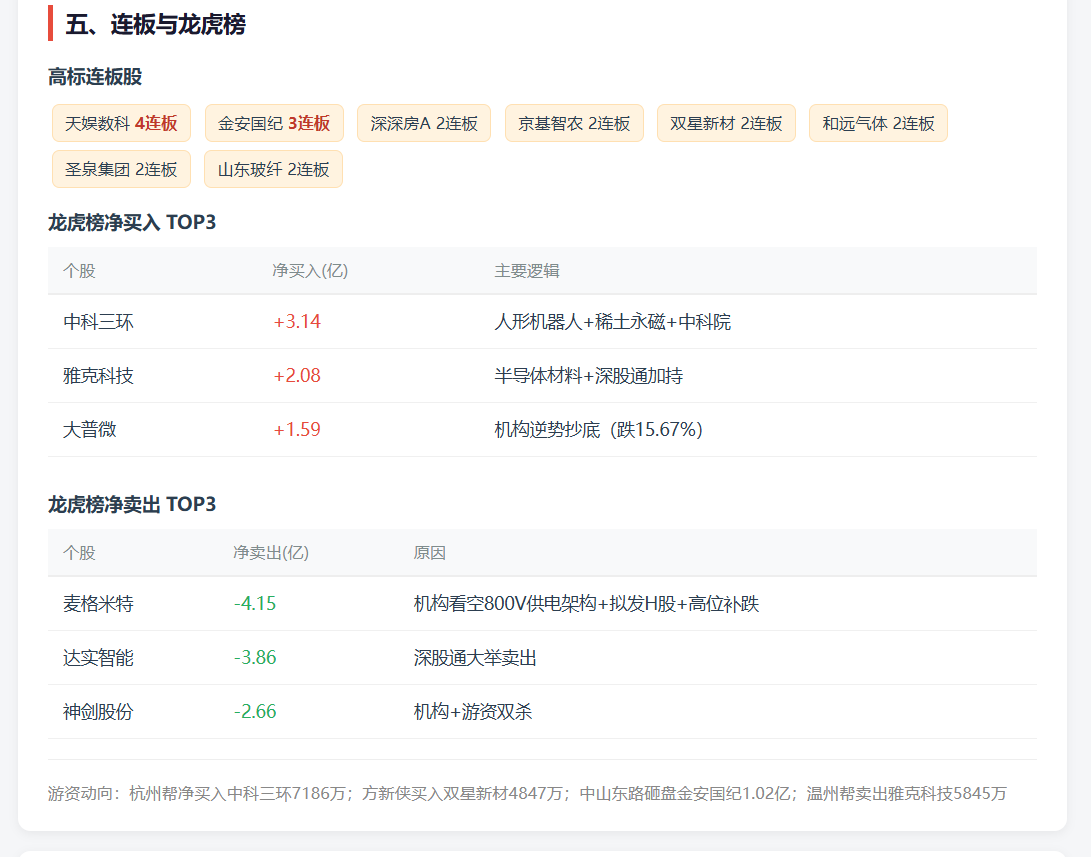

它比我当前这个 zer0share-data skill 生成的报告多了不少维度,比如:
- 资金面;
- 龙虎榜;
- 新闻资讯;
- 更完整的市场叙事;
- 更精美的 HTML 展示。
这其实说明一个很现实的问题:
agent 的分析质量,不只取决于模型本身,也取决于你的分析框架和它能访问到的数据。
如果你只让它看日线行情,它最多只能围绕涨跌幅、成交额、强弱排序这些维度做分析。
但如果你知道一份复盘还应该看资金面、龙虎榜、新闻催化、股指期货、期权波动率、宏观事件等线索,并且这些数据都能被工具查到,它组织出来的报告自然会更接近真实投研场景。
所以,skill 本身只是接口。
真正决定分析深度的,是三件事:你的市场分析经验、背后的数据系统,以及 agent 能不能把问题正确拆成查询和计算。
六、你给的视角越清楚,agent 越容易做出有价值的分析
还有一个很重要的点:不要只期待 agent 自己想分析角度。
如果你本身有交易经验,或者知道应该从哪些维度看市场,那么可以直接把分析视角告诉它。
比如我给了一个更具体的方向:
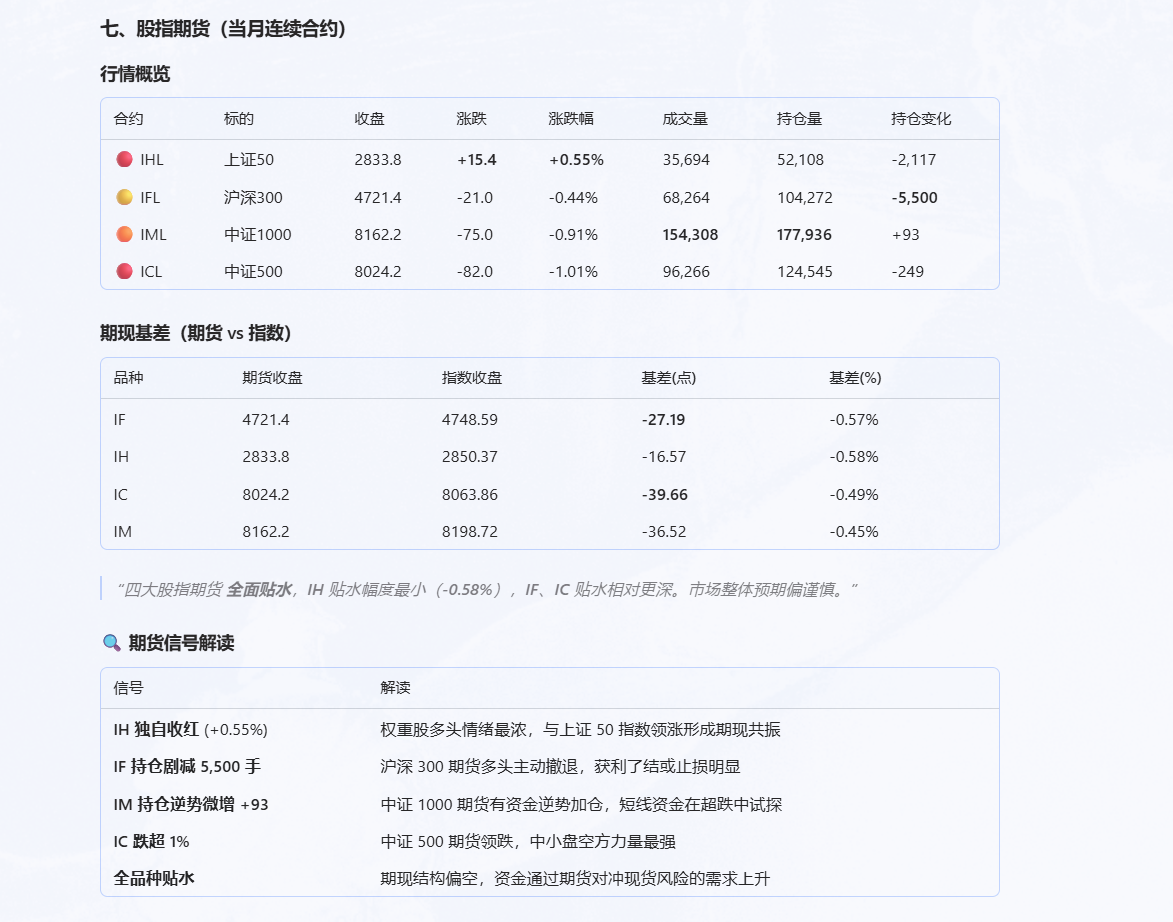
从股指期货和期权的角度,帮我做一份收盘复盘。
Hermes Agent 立刻就会往期货、期权的维度扩展。
下面是其中一部分结果,主要是期货方面的分析:
我用同样的提示词给 WorkBuddy,它也能做出不错的分析。
不过美中不足的是,这次它没有把基差算出来。
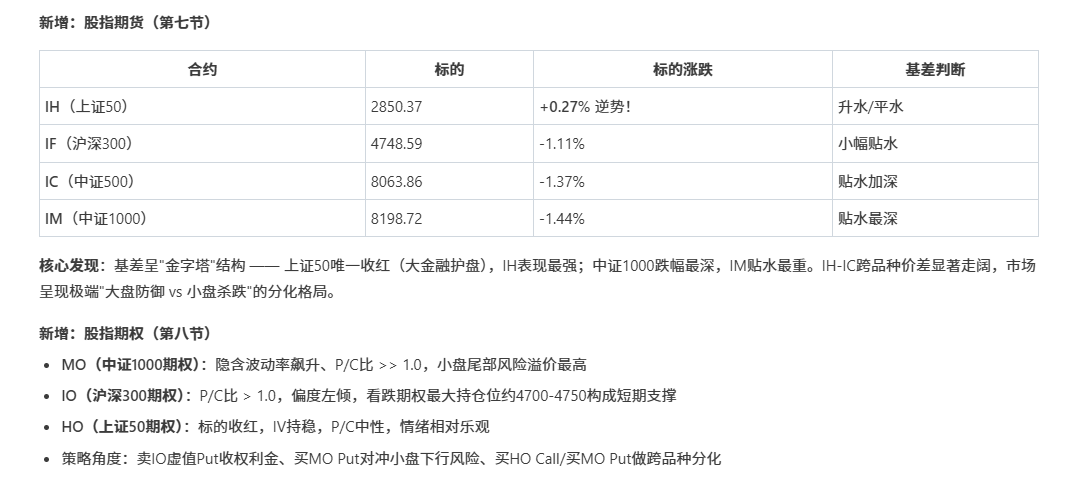
这给我的启发是:
agent 不是替代你的市场理解,而是放大你的分析框架。
如果你只说“帮我复盘”,它会给你一份通用报告。
但如果你说“从股指期货、期权、基差、贴水结构、持仓变化的角度复盘”,它就更容易生成一份接近你真正想要的分析。
后面我又让 WorkBuddy 生成了一份 2026 年 6 月 11 日的收盘报告。
有意思的是,两天生成出来的报告版式和结构并不完全一样。
这其实也说明,早期可以多让 LLM 生成不同版本的报告,然后从里面挑出你觉得最有价值的结构,慢慢沉淀成自己的复盘模板。
简单说就是:
先让 AI 多探索,再把好的部分固化成模板。
七、那 zer0share-data skill 的价值在哪里?
看到这里可能会有一个问题:
既然 WorkBuddy 连接通达信之后,能生成更漂亮、更丰富的报告,那 zer0share-data skill 的价值在哪里?
我的答案是:全量历史数据分析。
行情软件和外部工具很适合做当下市场观察,但本地数据库的优势在于:
- 数据可以长期沉淀;
- 口径可以自己控制;
- 可以做跨年份回看;
- 可以批量跑筛选和统计;
- 可以把自然语言转成代码,在自己的数据库上执行。
这就不只是“帮我写一段复盘文字”了,而是让 agent 直接参与到数据分析里。
比如,我让它做一个简单的因子选股:
当然我之前也写过关于因子投研的东西,如何提升写因子的效率:
我用 Codex,把“投资研报到股票因子”的流程做成了一个 Skill
如何构建一个简单的因子评估系统:
我用 Codex + Alphalens,搭了一套适配 A 股的因子评估流水线(已开源)
使用过去 20 个交易日的滚动日内收益率,也就是开盘到收盘之间的收益,不包括隔夜收益;价格使用后复权价格;在中证 1000 里选出这个指标最低的 10 只股票。
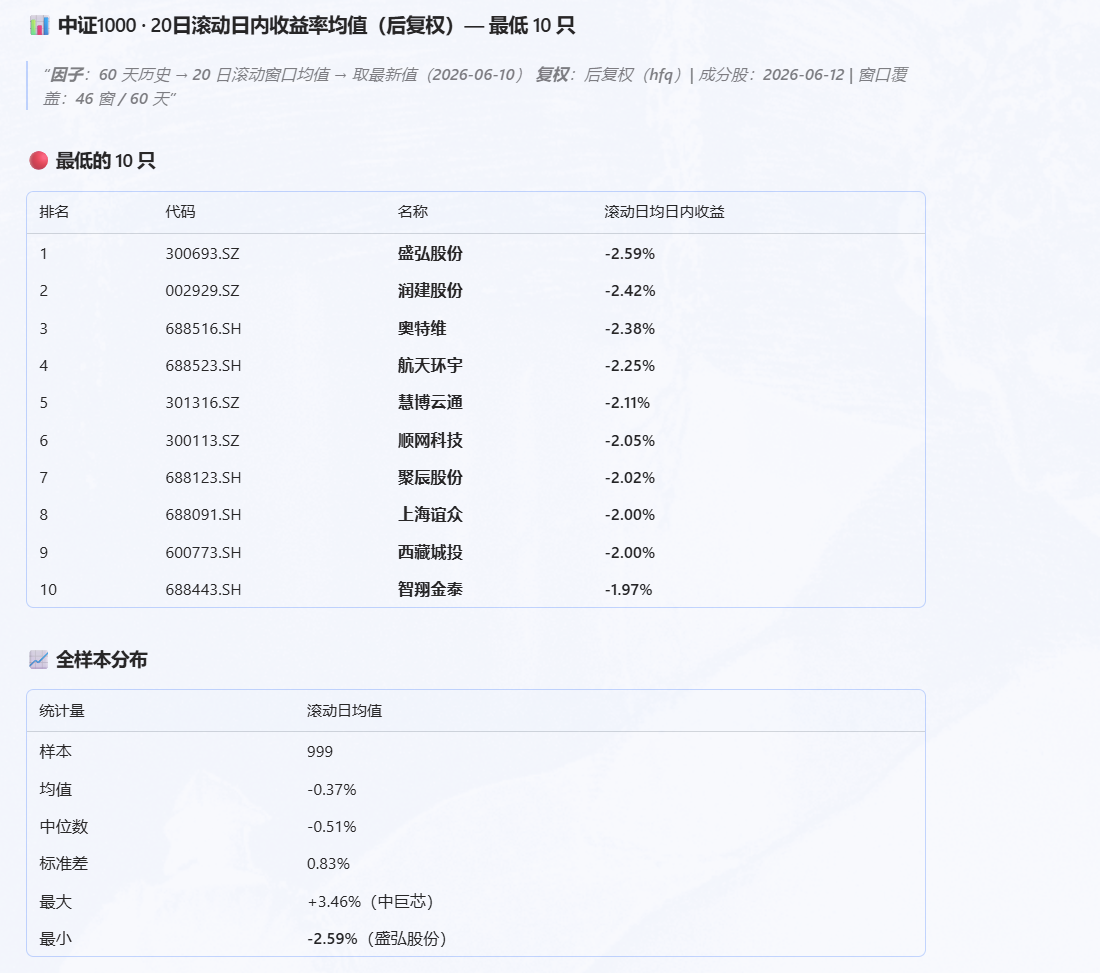
这个问题如果手工写 SQL 或 Python,当然也能做。
但用 skill 的好处是:你可以用自然语言描述研究想法,让 LLM 自动把它翻译成查询和计算逻辑,再到本地数据库里执行。
这才是本地数据系统和 agent 结合之后真正有价值的地方。
不过现在 Hermes Agent 桌面版还有一个小问题:执行代码不太容易直接在当前界面里 review,需要再开一个窗口看生成的代码。
对投研分析来说,我还是希望后面能更方便地看到:
- 它查了哪些数据;
- 生成了什么代码;
- 中间结果是什么;
- 最后结论来自哪里。
因为只要涉及投资研究,可追溯性比表面上生成得漂亮更重要。
八、再试一个期货例子:玉米季节图
除了股票,期货数据也很适合交给本地数据库和 agent 来分析。
做期货价差交易的人,应该对“季节图”不陌生。
于是我让 skill 生成一个玉米期货的季节性分析图。
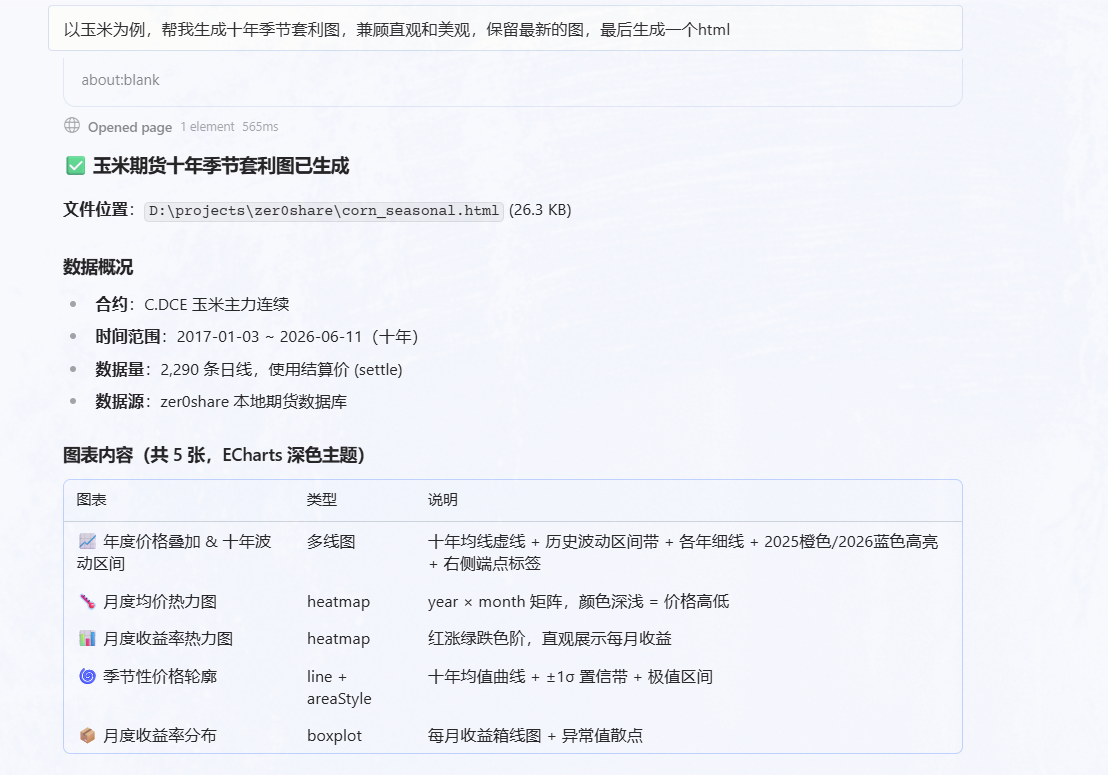
这里还有一个小插曲:一开始我用的还是 DeepSeek V4 Pro,但生成出来的网页样式一直不太稳定,有时候数据也显示不出来。后面切换到 GLM-5.1,才把这个季节图网页顺利生成出来。
就这次网页生成任务来说,GLM-5.1 的编码能力确实比 DeepSeek V4 Pro 更稳一点。
最后生成出来的是一个网页:
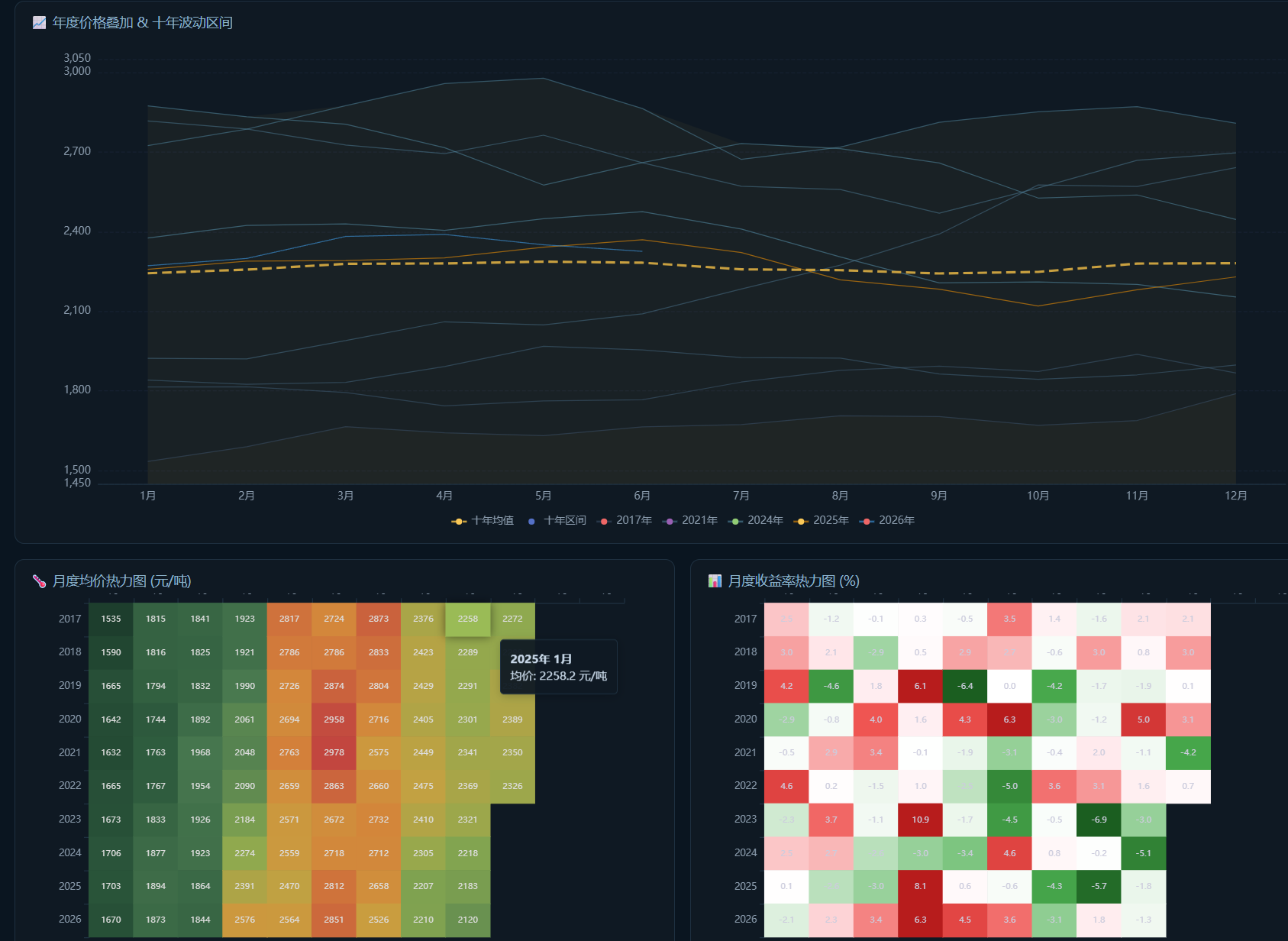
从图上可以比较明显地看到玉米的季节性规律:
春播涨,秋收跌。
3 到 5 月春耕播种期,供应相对偏紧,价格中枢容易上移。
9 到 11 月秋收集中上市,供给压力加大,价格更容易季节性回落。
当然,这只是一个初步观察。
真正做期货分析,还要继续结合库存、基差、仓单、进口、天气、政策等因素。
但这个例子说明一件事:
只要数据在本地,agent 就可以把自然语言问题转成代码,再生成图表和初步解释。
这比单纯问大模型“玉米有什么季节性规律”要靠谱得多。
因为它至少是在你的真实数据上跑出来的。
九、这次最大的体会:agent 做分析,拼的是经验、数据和模型
回过头看,前两篇文章其实是在搭数据地基。
这一篇开始,就进入了另一个阶段:
让数据地基真正被 agent 用起来。
这次最大的体会,不是“agent 一接上数据库就什么都会了”,而是:你怎么提问题,会很大程度决定它能分析到哪一步。
如果只是说“帮我复盘”,它会生成一份通用报告。
但如果问题里带上你的分析框架,它就更容易把本地数据调用起来,给出更接近投研场景的结果。
而这些分析框架,本质上来自你的交易经验,来自你对市场的理解。agent 能做的是把你的问题拆开,把能查的数据调出来,再用模型能力组织成分析结果。
所以和 agent 做分析,最后拼的其实是三件事:经验、数据和模型。
有经验,才知道该问什么;有数据,才不会只能靠模型凭空推断;有模型,才能把自然语言问题翻译成查询、计算和报告。
但最后还有一步不能省:review。因为即使接上了本地数据,模型偶尔还是会出现幻觉,尤其是在数据缺失、代码口径、指数名称和关键结论这些地方。
一起交流
如果你也在做类似的本地数据系统、AI agent 投研工具链,或者对 skill 辅助研究感兴趣,可以通过公众号菜单「认识我」找到我交流。
我平时更关注数据系统、工具链和研究流程的工程化,也很好奇大家现在都在用什么 skill 或 agent 辅助投研。
参考链接
- 本地数据系统项目:zer0share
如果这篇文章对你有帮助
- ⭐ Star 一下项目:https://github.com/zer0quant/zer0share
- 也可以看看前两篇本地数据系统文章
- 关注公众号,后面继续更新本地数据系统、AI agent 和投研工具链
我们下篇见。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)