山东大学软件学院创新实训——MarketClaw(六):从MVP到多入口智能体平台的推进
一、本阶段工作背景
上一篇博客记录的是 MarketClaw 从功能原型走到最小可运行版本的过程。那时系统已经能够完成 Web 端输入、创建营销任务、串联三个 mock Skill、记录 Skill 调用日志、统计 Token,并在前端展示任务列表和任务详情。
本阶段的重点不再是“把主流程跑通”,而是把这个 MVP 往更完整的目标方向推进。MarketClaw 的定位是私人产品营销助理,入口不应该只局限在 Web 页面;Skill 也不应该长期停留在 mock;长期记忆、内容资产和 Token 成本统计也需要从数据表设计进一步变成可操作、可展示的功能。因此,本阶段我主要围绕真实大模型接入、多平台入口、记忆管理、内容资产管理和项目协作规范做了推进。
二、和上一阶段相比的主要变化
对比上一阶段版本,本阶段项目变化比较明显。
上一阶段已完成的内容主要是:
-
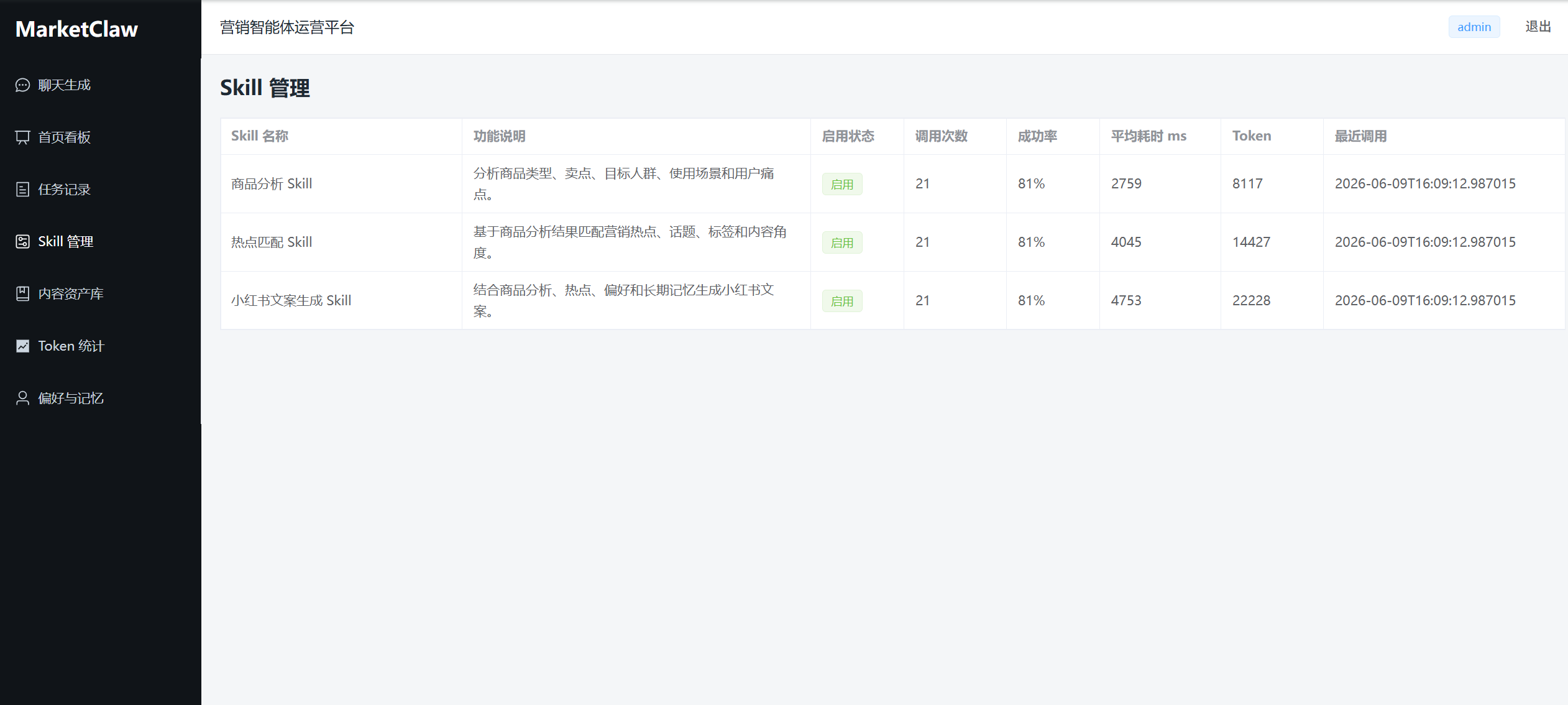
Web 端基础页面:登录、首页看板、聊天生成、任务列表、任务详情、Skill 管理。
-
后端基础接口:登录、仪表盘、聊天生成、任务查询、Skill 查询。
-
核心任务链路:商品分析 → 热点匹配 → 小红书文案生成。
-
数据沉淀:任务、消息、Skill 日志、Token 记录、内容资产和简单记忆。
本阶段新增和完善的内容包括:
-
增加真实大模型调用层,支持 DeepSeek 和 OpenAI-compatible 两种配置方式。
-
增加 LLM 调用失败后的 fallback 机制,失败时自动回退到 mock Skill,并记录错误原因。
-
增加飞书和微信入口,开始把“轻量级对话服务”从规划推进到代码实现。
-
增加记忆管理接口和前端页面,可以查看、添加、删除用户偏好和 HOT/WARM/COLD 记忆。
-
增加内容资产库接口和页面,可以按关键词或标签查询生成过的文案资产。
-
增加 Token 统计接口和页面,可以按日期、Skill、用户、模型统计 Token 消耗。
-
优化任务详情返回结构,新增状态流、调用追踪、Token 分布和 fallback 记录。
-
增加团队 Skill 接入规范和模板,方便组员按统一输入输出格式提交 Skill。
-
增加
.env.example和 README 配置说明,让真实模型和机器人入口更容易复现。
从结果上看,项目已经从“一个 Web 端文案生成 MVP”向“有多入口、有模型配置、有记忆和资产沉淀的智能体运营平台”迈了一步。
三、真实大模型接入:从 mock Skill 到可替换模型服务
上一阶段系统的三个 Skill 都是 mock 实现,优点是稳定、方便演示,缺点是不够真实,也无法体现大模型应用开发的核心价值。本阶段我重点梳理并实现了独立的 LLM 服务层。
新的 llm_service 负责统一处理模型调用,包括:
-
判断当前是否启用 DeepSeek。
-
判断是否启用 OpenAI-compatible 模型服务。
-
组装 Chat Completions 请求。
-
要求模型只返回合法 JSON,避免返回 Markdown 代码块或解释文本。
-
解析返回内容中的 JSON。
-
读取真实的 prompt tokens、completion tokens 和 total tokens。
-
对 HTTP 错误、网络错误、JSON 解析错误进行封装。
我认为这里最关键的设计不是“能调通某一个模型”,而是把模型供应商和业务流程解耦。任务编排层不需要关心 DeepSeek 的 base_url、API key、模型名和请求细节,只需要调用一个 complete_json,拿到结构化结果即可。
同时,本阶段还增加了 fast workflow 模式:如果配置了真实 LLM,系统可以用一次大模型请求生成完整的 product_analysis、trend_matching 和 xiaohongshu_copywriting 三段结果,再按照权重拆分为三个 Skill 的 Token 和耗时记录。这样既保留了前端展示中的 Skill 调用链,又减少了真实模型调用次数,降低调试成本。
四、fallback 机制:保证演示稳定性
真实模型接入后,一个实际问题立刻出现:模型 API 可能因为网络、Key、响应格式或余额问题失败。如果失败后整个任务直接中断,演示时会非常不稳定。
因此本阶段任务服务层增加了 fallback 设计:当真实 LLM 可用时,系统优先调用真实模型;如果真实模型调用失败,任务不会直接崩掉,而是回退到本地 mock Skill 继续完成流程。与此同时,Skill 日志会记录状态和错误原因,前端任务详情页可以看到是否发生 fallback。
这个设计让我对工程稳定性有了更具体的认识。对于一个智能体项目来说,调用大模型只是其中一环;真正面向用户或答辩演示时,系统必须能解释失败、记录失败,并尽量给出可用结果。否则模型能力再强,也容易被一次接口波动打断整体展示。
五、多入口能力:从 Web 页面扩展到飞书和微信
MarketClaw 希望用户通过飞书、QQ 等聊天场景完成营销工作。上一阶段项目还停留在 Web 页面,本阶段新增了机器人相关接口,先实现了飞书和微信入口的基础框架。
飞书入口主要包括:接收飞书事件订阅、处理 URL verification、从事件 payload 中提取用户 id 和文本内容、根据飞书用户自动创建平台用户、调用统一的营销任务流程、将生成结果格式化为适合聊天窗口阅读的文本、在配置可用时调用飞书回复接口。
微信入口主要包括:GET 回调用于服务器验证、POST 回调接收用户消息、校验微信签名、解析 XML 消息、根据 open_id 自动创建微信平台用户、调用统一营销任务流程、构造 XML 文本回复。
我认为这一步很重要,因为它验证了之前任务服务层抽象的价值。无论请求来自 Web、飞书还是微信,最终都可以进入同一个 run_marketing_task 流程,只是在用户身份、source_platform 和回复格式上有所区别。这样后续如果继续接入 QQ 或其他平台,不需要重新写一套营销生成逻辑。
六、长期记忆模块:从数据表走向可管理页面
上一阶段项目中已经有 UserPreference 和 MemoryItem 两张表,但它们更多是“预留结构”。本阶段进一步补充了记忆模块的接口和前端页面。
后端新增了记忆相关接口:获取指定用户的偏好和记忆列表、新增或更新用户偏好、删除用户偏好、新增 HOT/WARM/COLD 三层记忆、删除记忆条目。前端也新增了记忆管理页面,可以查看当前用户的偏好和记忆记录,并手动维护这些内容。
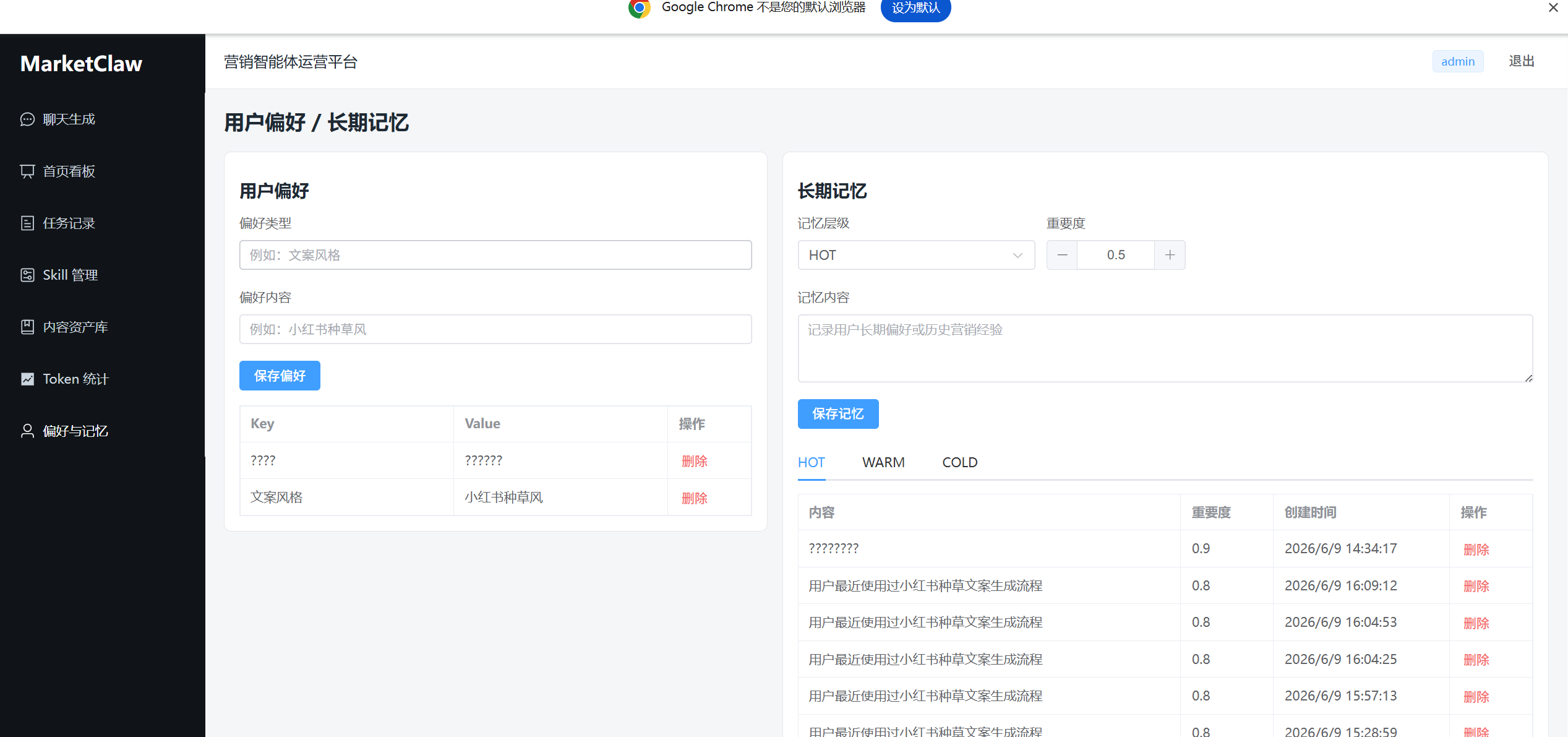
虽然现在还没有完整实现自动分层迁移和记忆衰减,但相比上一阶段“任务结束后简单写一条记忆”,这阶段已经能把长期记忆作为一个独立模块进行展示和管理。当前任务服务中已经会把用户偏好和记忆传给文案生成流程,为后续继续增强记忆召回打下了基础。
七、内容资产和 Token 统计:让结果可复用、成本可观察
本阶段还补充了两个面向运营视角的模块:内容资产库和 Token 统计。
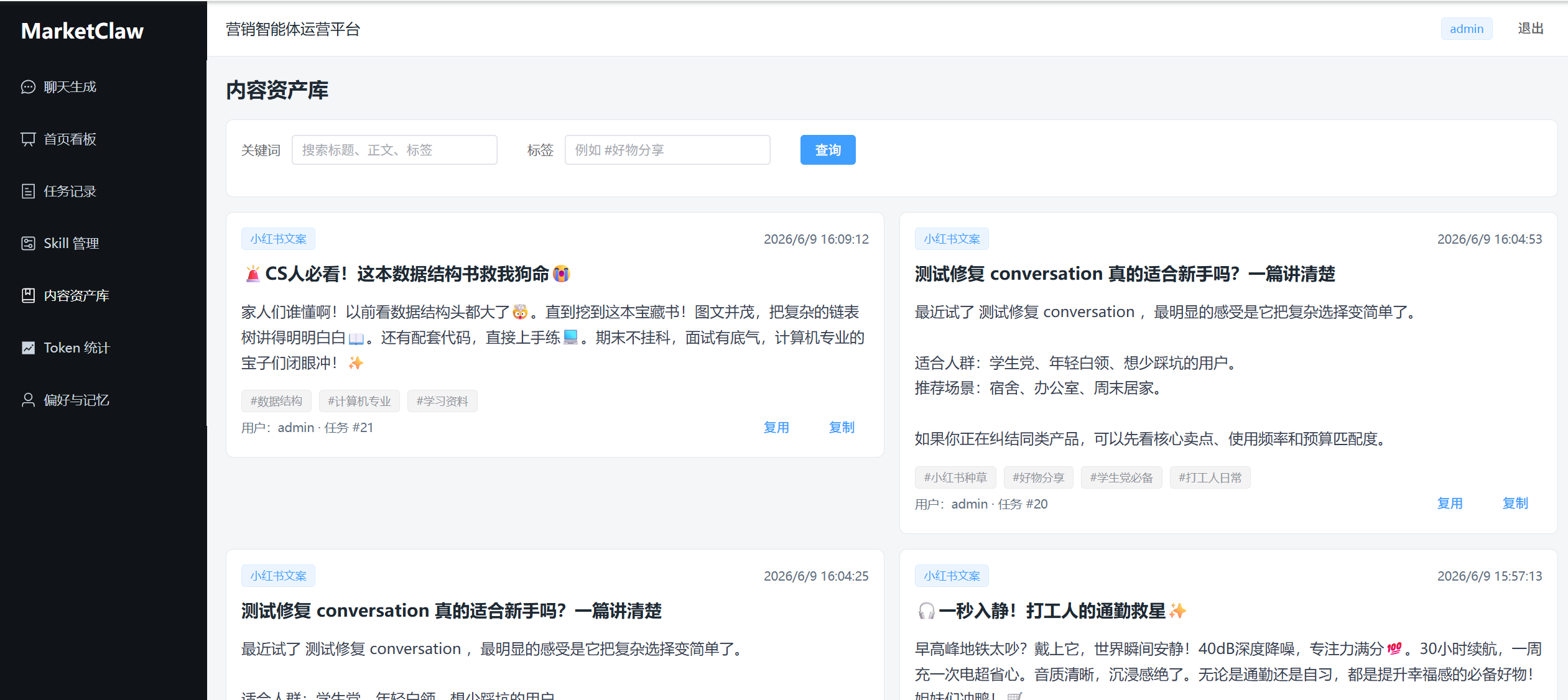
内容资产库解决的是“生成结果如何复用”的问题。以前用户生成一篇文案后,只能在任务详情里查看;现在系统提供了资产列表接口和前端页面,可以按关键词、标签查询历史生成内容。这样 MarketClaw 更像一个营销内容工作台,而不是一次性生成工具。
Token 统计解决的是“模型成本如何观察”的问题。新增接口可以从多个维度统计 Token:
-
总 Token、今日 Token、估算成本、平均每次调用 Token。
-
最近几天的 Token 使用趋势。
-
按 Skill 统计调用次数、prompt tokens、completion tokens、总 Token 和平均耗时。
-
按用户统计 Token 消耗。
-
按模型统计 Token 消耗和估算成本。
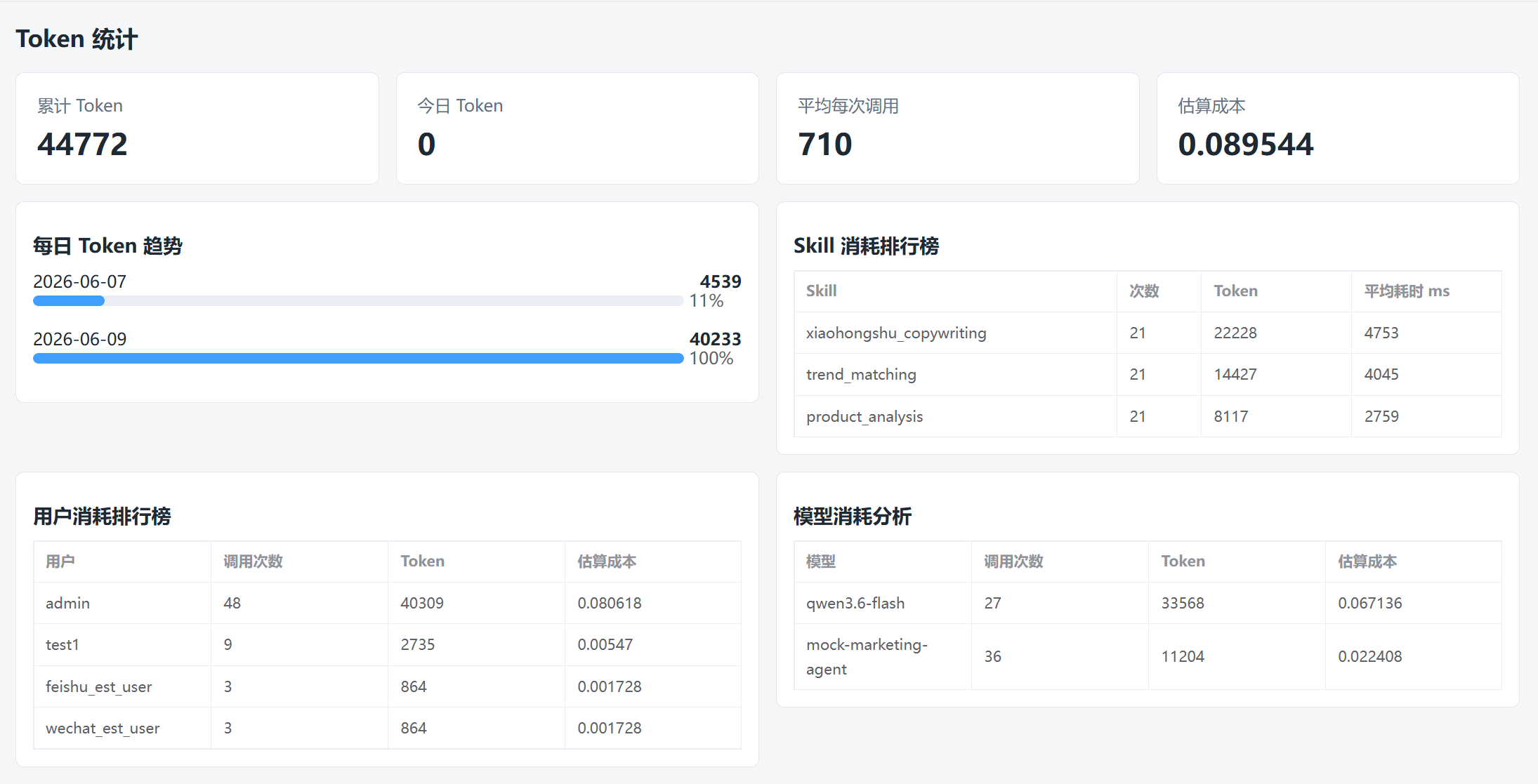
这部分能清晰展示调用成本、调用分布和每个 Skill 的资源占用。
八、任务详情增强:从结果展示到过程追踪
本阶段我还注意到任务详情结构变得更完整。除了上一阶段已有的最终输出、Skill 日志和内容资产,现在后端序列化任务详情时还增加了:
-
status_flow:展示任务创建、Skill 编排、内容生成、任务完成等状态。 -
trace:按步骤展示每个 Skill 的输入、输出、耗时、Token 和错误信息。 -
token_distribution:展示每个 Skill 在总 Token 中的占比。 -
retry_records:记录 fallback 或异常信息。 -
source_platform:区分任务来自 Web、飞书还是微信。
这些字段让任务详情页从“展示结果”升级为“展示执行过程”。
九、团队协作规范:Skill 接入模板
随着项目功能增多,不同组员如果各自开发 Skill,输入输出格式不统一,主平台就很难整合。因此本阶段新增了 docs/SKILL_INTEGRATION.md 和 skill_template.py,明确了每个 Skill 统一暴露 run(input_data) 函数、返回 SkillResult 结构、商品分析/热点匹配/文案生成分别需要的固定字段,以及 Skill 注册到 SKILL_REGISTRY 的规范。这为团队并行开发提供了可执行的接口约定。
十、本阶段测试与联调情况
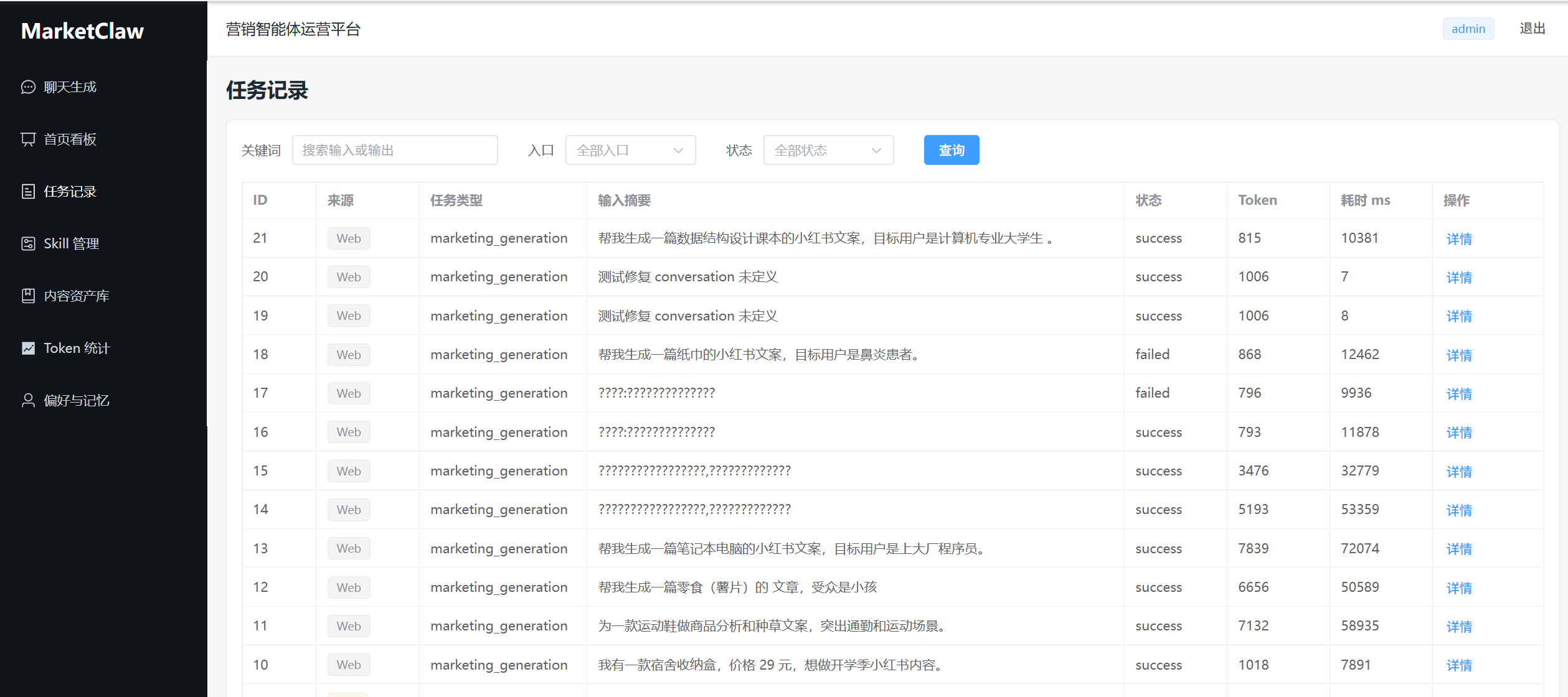
从当前数据库记录看,本阶段已经进行了较多轮联调。上一阶段数据库中只有少量任务记录,而现在已有 21 条营销任务、63 条 Skill 调用记录、63 条 Token 记录、19 条内容资产、20 条记忆记录。测试过程中也暴露了真实 LLM 调用失败、任务中途失败、部分中文显示编码等问题,当前通过 fallback、日志记录、状态追踪和多维统计,已经比之前更容易定位问题。
十一、AI 辅助开发记录
本阶段我继续使用 AI 作为工程协作工具,典型提示词包括:
-
“设计一个独立的 LLM 服务层,支持 DeepSeek 和 OpenAI-compatible API,要求返回 JSON,并记录 token 消耗。”
-
“设计 fallback 机制:优先调用真实模型,失败后回退 mock Skill,同时在日志中记录错误原因。”
-
“把 Web 端营销任务流程复用到飞书和微信机器人,拆分用户识别、消息解析、任务调用、回复格式化、回调验证。”
AI 的建议帮助我更快确认了模块边界,但最终仍需根据项目已有代码调整,例如 fast workflow 模式下如何将一次大模型调用拆分为三个 Skill 的记录。
十二、遇到的问题与反思
本阶段最大的挑战是功能扩展后,系统复杂度明显上升。上一阶段只有 Web 入口和 mock Skill,链路直观;本阶段加入真实模型、机器人入口、fallback、统计、记忆管理后,问题跨越配置、服务层、数据库和前端页面。我的体会是:智能体项目不能只追求“多接几个 API”,必须靠统一任务模型、统一日志结构和统一 Skill 接口来维护可扩展性。
另一个反思是真实模型接入后必须重视稳定性。为模型调用增加 JSON 约束、异常封装、fallback 和错误日志,是从 demo 走向可验收系统必须补上的工程能力。
十三、下一步计划
下一阶段计划:
-
继续优化中文显示和前端交互,提高演示效果。
-
继续验证真实大模型调用效果,补充更稳定的提示词。
-
完善飞书/微信入口的实际联调流程,准备可演示的聊天端用例。
-
增强长期记忆的实际作用,让用户偏好更明显地影响文案生成。
十四、本阶段总结
本阶段的工作让 MarketClaw 从“能在 Web 页面生成文案”的 MVP,进一步发展为一个更完整的智能体运营平台雏形。真实大模型接入、多平台机器人入口、长期记忆管理、内容资产库、Token 成本统计和 Skill 接入规范,都在向完整目标靠近。对我个人而言,最大的收获是理解了智能体工程化的重点:不只是调用模型,而是围绕模型构建稳定的任务编排、过程追踪、失败兜底、成本观察和团队协作机制。后续我会继续围绕真实模型效果、聊天端联调和演示稳定性推进个人工作。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)