从零实现一个自己的 Agent:从 Agent Loop 到自进化智能体
从零实现一个自己的 Agent:从 Agent Loop 到自进化智能体

过去一年,Agent(智能体)突然火了起来。Claude Code、Codex、OpenCode、OpenClaw、Hermes Agent 这些项目陆续出现,大家开始把大模型从“聊天窗口”推进到真实的开发、搜索、文件操作、自动化和长期任务里。
但对技术人员来说,只是凭感觉使用产品是不够的,我们需要了解它的底层实现才能用得更好。Agent 设计的好坏,往往直接决定了复杂任务的完成度;同样的模型,放在不同 Agent 系统里,表现差异可能会非常大。一个 Agent 到底是怎么跑起来的?它如何拆任务、调工具、保存记忆、压缩上下文?想真正理解这些问题,最好的办法还是自己手搓一个 Agent。
自己实现一个 Agent,至少有三层价值。第一是深度理解 Agent 的工作原理,不再停留在“模型好像会自己干活”的直觉层面;第二是满足特定领域的定制化需求,比如内部系统、私有数据、本地软件、行业流程,这些往往不是通用产品开箱就能覆盖的;第三是培养系统设计能力,因为一个可用的 Agent 牵涉模型、工具、记忆、上下文、权限、安全和失败恢复,它本质上是一个小型软件系统。
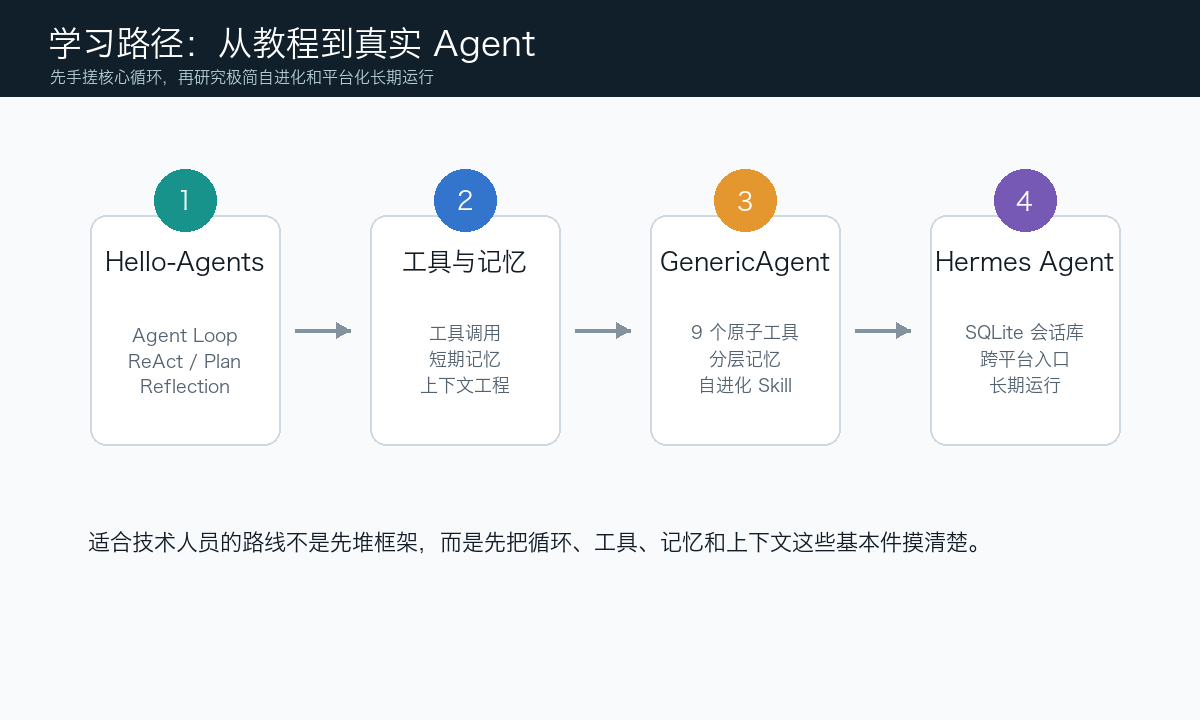
这篇文章选了一条比较适合动手学习的路线:Hello-Agents -> GenericAgent -> Hermes Agent。它们都由 Python 实现,代码相对直接,部署和调试门槛不高。先用 Hello-Agents 理解 Agent Loop、ReAct、Plan-and-Solve、Reflection;再看 GenericAgent 如何用极少的原子工具和分层记忆做自进化;最后对比 Hermes Agent 这种更平台化、产品化的长期运行 Agent。按这个路径走一遍,对 Agent 的理解会扎实很多。
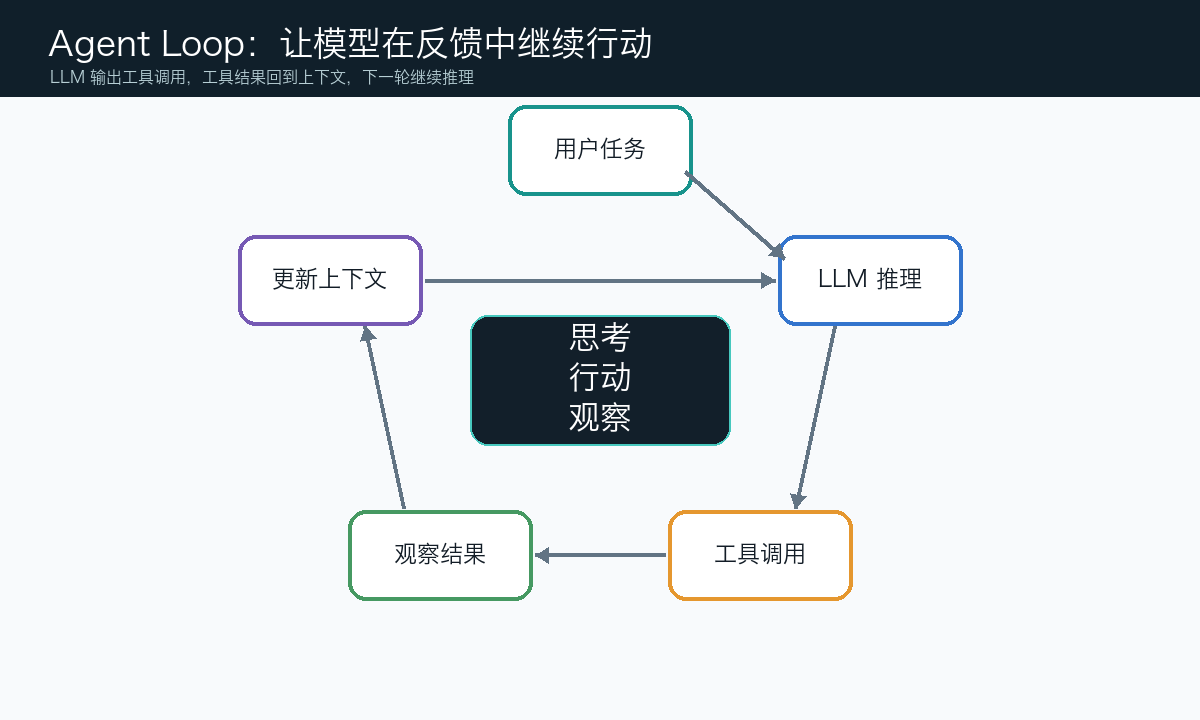
1. Agent 最小内核:Agent Loop
一个最简单的 Agent Loop 可以写成这样:
while not done:
response = llm(messages, tools=tools)
if response.tool_calls:
result = run_tool(response.tool_calls)
messages.append({"role": "tool", "content": result})
else:
done = True
answer = response.content
这段循环里有三个关键点:
第一,LLM 不只是回答问题,而是可以决定下一步要不要调用工具。
第二,工具执行结果会重新进入上下文,成为下一轮推理的依据。
第三,Agent 的智能不只来自模型本身,还来自“循环”带来的反馈。
Hello-Agents 第四章从 ReAct 讲起,本质就是让模型在“思考 -> 行动 -> 观察”的轨迹里运行。模型先思考,再行动,工具返回观察结果,模型再基于观察结果继续思考。这个结构非常适合搜索、查询、API 调用、网页操作这类需要外部信息的任务。
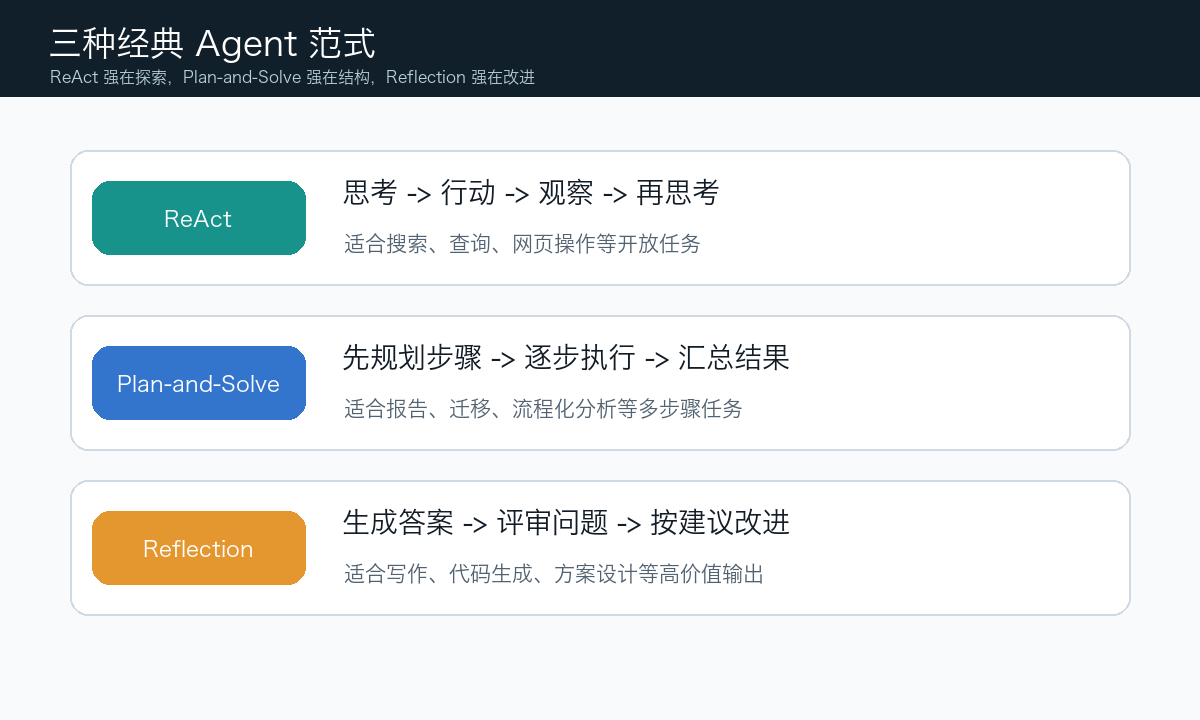
2. 三种经典 Agent 范式
ReAct:边想边做
ReAct 的核心是“推理和行动交替进行”。它适合探索性任务,比如:
帮我查一下某个产品的最新价格,并总结优缺点。
这类任务一开始并不知道答案,需要搜索、读取、比较、再判断。ReAct 的优势是灵活,缺点是容易绕圈,所以工程上必须加最大轮数、工具错误处理、终止条件。
一个极简 ReAct 实现可以写成这样:
def react_agent(question, tools, max_steps=5):
messages = [{"role": "user", "content": question}]
for _ in range(max_steps):
response = llm(messages, tools=tools)
if not response.tool_calls:
return response.content
messages.append({
"role": "assistant",
"content": response.content,
"tool_calls": response.tool_calls,
})
for call in response.tool_calls:
result = run_tool(call.name, call.arguments)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": str(result),
})
return "达到最大步数,任务未完成"
这段代码的关键不是 for 循环本身,而是每次工具调用后都把“观察”放回上下文。模型下一轮看到新观察,再决定继续搜索、换工具,还是输出最终答案。
Plan-and-Solve:先规划再执行
Plan-and-Solve 更像“三思而后行”。模型先把任务拆成计划,然后按步骤执行:
1. 理解目标
2. 拆分子任务
3. 逐步执行
4. 汇总答案
它适合路径比较明确的任务,比如数学推理、报告生成、流程化分析。优点是结构稳定,缺点是如果初始计划错了,后续会一路错下去。所以更强的实现通常会加入“动态重规划”。
一个简化版实现如下:
import json
def plan_and_solve_agent(task, tools):
plan_prompt = f"""
请把任务拆成可执行步骤,输出 JSON 数组。
每个元素包含 id 和 task 两个字段。
任务:{task}
"""
plan_text = llm([{"role": "user", "content": plan_prompt}]).content
steps = json.loads(plan_text)
results = []
for step in steps:
solve_prompt = f"""
原始任务:{task}
整体计划:
{json.dumps(steps, ensure_ascii=False, indent=2)}
已有结果:
{json.dumps(results, ensure_ascii=False, indent=2)}
现在执行这一步:
{json.dumps(step, ensure_ascii=False)}
"""
messages = [{"role": "user", "content": solve_prompt}]
response = llm(messages, tools=tools)
if response.tool_calls:
messages.append({
"role": "assistant",
"content": response.content,
"tool_calls": response.tool_calls,
})
for call in response.tool_calls:
tool_result = run_tool(call.name, call.arguments)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": str(tool_result),
})
response = llm(messages)
step_result = response.content
results.append({
"step": step,
"result": step_result,
})
final_prompt = f"""
请根据以下执行过程,给出最终答案:
{json.dumps(results, ensure_ascii=False, indent=2)}
"""
return llm([{"role": "user", "content": final_prompt}]).content
Plan-and-Solve 的重点是把“规划”和“执行”拆开。规划阶段让模型先获得全局视角,执行阶段再逐步推进。这里让计划输出 JSON,是为了避免 parse_steps() 依赖自然语言格式;工具调用后再把工具结果回灌给模型,是为了让模型基于“观察”形成这一步的结论。真实工程里,还可以在每一步后检查计划是否需要调整。
Reflection:执行后自我反思
Reflection 给 Agent 加了一个自我修正回路:
执行 -> 反思 -> 优化
例如让 Agent 写代码,第一版可能能跑但效率低;反思阶段可以让模型扮演代码评审者,指出复杂度、边界条件、可读性问题;优化阶段再生成新版。Hello-Agents 也强调,Reflection 往往要配合短期记忆,因为它需要保存每轮执行和反馈轨迹。
一个极简 Reflection 实现如下:
def reflection_agent(task, max_rounds=3):
answer = llm([
{"role": "user", "content": f"请完成任务:{task}"}
]).content
for _ in range(max_rounds):
critique = llm([
{"role": "system", "content": "你是严格的评审者,只检查答案是否满足任务。"},
{"role": "user", "content": f"""
请评审下面的答案。
如果已经足够好,只输出:无需修改
否则输出具体问题和修改建议。
任务:
{task}
答案:
{answer}
"""}
]).content
if "无需修改" in critique:
break
answer = llm([
{"role": "system", "content": "你是谨慎的修改者,只根据评审意见改进答案。"},
{"role": "user", "content": f"""
请根据评审意见改进答案。
必须保留原任务要求,不要引入无关内容。
任务:
{task}
原答案:
{answer}
评审意见:
{critique}
"""}
]).content
return answer
Reflection 的关键是把模型分成两个角色:一个负责生成,一个负责评审和改进。这里让评审者可以输出“无需修改”,是为了避免无意义的循环改写;修改提示里强调“保留原任务要求”,是为了减少答案越改越偏。它适合写作、代码生成、方案设计等需要打磨质量的任务,但会增加调用成本和延迟。
这三种范式不是互斥关系。真实 Agent 往往会组合使用:先 Plan-and-Solve 拆解任务,再用 ReAct 执行每个子任务,最后用 Reflection 检查质量并沉淀经验。
3. 工具调用:Agent 的手和脚
没有工具的 Agent,只是一个会聊天的模型。有工具之后,它才开始能“做事”。
最基础的工具系统包括三层:
Tool Schema:告诉模型有哪些工具、参数是什么
Tool Router:把模型输出的工具调用分发到对应函数
Tool Result:把执行结果返回给模型
Hello-Agents 在第七章里把工具调用做成框架能力,还提出“万物皆为工具”:搜索是工具,记忆是工具,终端是工具,RAG 也可以是工具。
一个最小工具路由器大概长这样:
def run_tool(name, arguments):
if name == "search":
return search_web(arguments["query"])
if name == "calculator":
return eval_math(arguments["expression"])
if name == "read_file":
return read_file(arguments["path"])
raise ValueError(f"未知工具:{name}")
这里的关键不是工具越多越好,而是工具边界要清楚。一个好工具应该满足:
- 名字清晰,模型一看知道什么时候用
- 参数结构稳定,最好能被 function calling schema 描述
- 返回结果简洁,不把无关信息塞回上下文
- 失败时有明确错误信息,方便模型修正
4. 记忆:让 Agent 不再每轮重开人生
LLM API 本身是无状态的。你不把历史传进去,它就不知道之前发生了什么。Agent 要长期可用,必须有记忆。
Hello-Agents把记忆拆成几类:
- 工作记忆:当前任务上下文,生命周期短
- 情景记忆:过去发生过的交互和经验
- 语义记忆:长期稳定的知识、偏好、规则
- 感知记忆:图像、音频等多模态信息
一个简单实现可以先从两层开始:
class Memory:
def __init__(self):
self.working = {}
self.long_term = []
def update_working(self, key, value):
self.working[key] = value
def remember(self, text):
self.long_term.append(text)
def build_context(self):
return {
"working_memory": self.working,
"long_term_memory": self.long_term[-5:],
}
更进一步,记忆不是“越多越好”。真正困难的是:什么时候写入?写到哪里?下次什么时候召回?错误记忆会长期污染 Agent,所以记忆系统必须谨慎。
5. 上下文工程:把正确的信息放进有限窗口
很多人以为上下文工程就是写 prompt。其实它更像一个运行时信息管理系统。
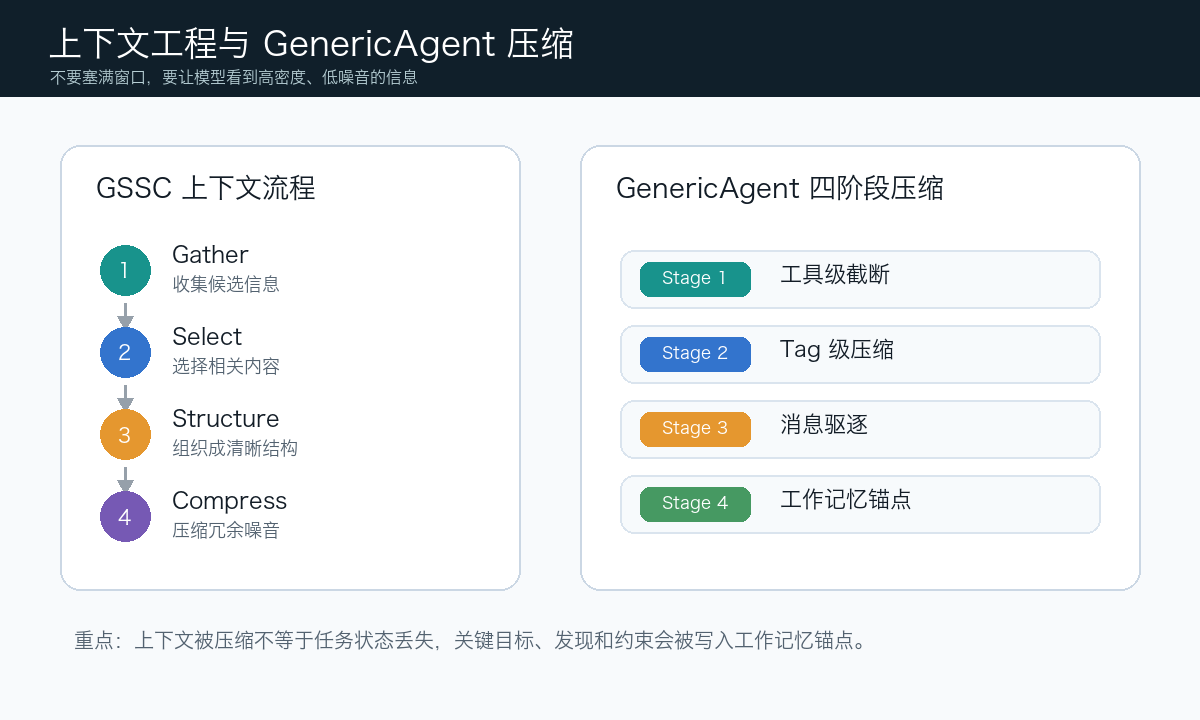
Hello-Agents提到的 GSSC 思路很实用:
Gather:收集候选信息
Select:选择当前最相关的信息
Structure:组织成模型容易理解的结构
Compress:压缩冗余内容
Agent Loop 跑久以后,历史、工具结果、文件内容、用户偏好都会膨胀。如果直接全塞给模型,首先会挤占有限的上下文窗口。大语言模型再长的上下文,也不是无限的;一旦无关内容占满窗口,真正关键的任务约束、工具结果、代码片段反而可能被截掉。
更麻烦的是,就算还没达到最大上下文长度,过多的无关信息也会稀释模型注意力。模型需要在一堆噪音里找重点,越找越容易偏。最后表现出来就是:该遵守的约束漏掉了,该引用的工具结果没用上,甚至开始根据上下文里的碎片信息编造一个看似合理但实际错误的答案。
所以,上下文工程不是简单地“塞更多资料”,而是每次模型调用前,拼出最有用、最少干扰的那一小包信息。
这也是很多 Agent 从 Demo 走向真实可用时绕不开的分水岭。
6. GenericAgent:极简种子如何长成自进化 Agent
理解完上面的基础,再看 GenericAgent 会很有意思。
GenericAgent 的 README 把自己定位为“极简、自进化的自主 Agent 框架”:核心约 3K 行代码,9 个原子工具,一个约百行的 Agent Loop。它的设计哲学很鲜明:
不预设技能,靠进化获得能力。
GenericAgent 的能力不是靠一开始内置大量专用插件,而是靠少量原子工具获得系统级控制能力:
code_run:执行代码
file_read / file_write / file_patch:读写修改文件
web_scan / web_execute_js:观察和控制网页
ask_user:必要时请求人类确认
update_working_checkpoint:短期工作记忆
start_long_term_update:长期记忆沉淀
这里容易有个误解:工具少,并不等于能力弱。GenericAgent 的厉害之处恰恰在于,它把工具设计得很原子,然后让模型自己组合。code_run 可以写脚本、装依赖、调用系统命令;文件工具可以读代码、改配置、沉淀 SOP;浏览器工具可以观察页面、执行 JS、保留真实登录态。几个工具组合起来,就能做网页自动化、数据抓取、文件整理、代码修改、定时任务、桌面流程自动化这类高级任务。
尤其是浏览器控制和电脑控制这一块,GenericAgent 的执行力很强。它不是只在一个沙盒网页里点点按钮,而是尽量接管真实环境:浏览器、终端、文件系统,甚至可以继续扩展到键鼠、屏幕视觉和移动设备。对个人自动化来说,这种“能碰到真实电脑”的能力,比预置一堆漂亮但封闭的插件更有想象空间。
它的核心架构可以概括为:
分层记忆 × 最小工具集 × 自主执行循环
记忆层也很有意思:
L0:元规则
L1:记忆索引
L2:全局事实
L3:任务 Skills / SOPs
L4:会话归档
也就是说,GenericAgent 不是只把聊天记录塞进数据库,而是把经验分层管理。高频规则、稳定事实、任务 SOP、历史会话各自有位置。
除了记忆分层,GenericAgent 还专门做了上下文预算管理。它的思路不是一味追求更大的上下文窗口,而是把每一轮的信息密度做高:宁可让模型看到少一点、但更关键的信息,也不要把低价值历史全塞进去。
GenericAgent把这套机制总结成四阶段压缩流水线:
Stage 1:工具级截断,先控制每次工具返回值的大小
Stage 2:Tag 级压缩,把旧轮次里的 thinking、tool_use、tool_result 等标签压短
Stage 3:消息驱逐,超预算时先激进压缩,再按时间移除最早的消息
Stage 4:工作记忆锚点,用最近轮次摘要、轮次号和 key_info 保留任务状态
这里最值得注意的是 Stage 4。早期消息被驱逐以后,模型并不是完全“失忆”,而是依靠工作记忆锚点继续知道当前目标、关键发现和约束条件。也就是说,GenericAgent 不是把所有历史都留下,而是把真正影响下一步行动的信息留下。
它还在信息进入上下文之前就做过滤。比如网页工具 web_scan 不会把完整 HTML 原样塞给模型,而是先做 DOM 级选择性提取,尽量移除脚本、样式、隐藏元素、广告和无关导航,只保留对当前决策更有价值的页面内容。工具 Schema 也会在合适场景下做省略优化,避免每一轮重复发送完整工具定义。
这套机制和前面讲的上下文工程是一脉相承的:Agent 不是靠“记住一切”变强,而是靠主动管理信息预算,让模型每一轮都看到高密度、低噪音的上下文。
它的自进化路径大概是:
新任务
-> 自主探索
-> 安装依赖 / 写脚本 / 调试 / 验证
-> 把成功路径固化成 Skill 或 SOP
-> 下次遇到类似任务直接召回
这就把 Reflection、记忆、上下文工程串起来了:执行过程中积累轨迹,任务结束后压缩成经验,下次通过记忆索引召回,进入新的上下文。
GenericAgent 的 agent_loop.py 里可以看到一个很直接的 Agent Loop:模型输出工具调用,框架把工具调用 dispatch 到 handler,工具结果和下一轮提示再回到模型。它没有把复杂性藏进庞大的调度框架,而是把核心控制流暴露得很清楚。
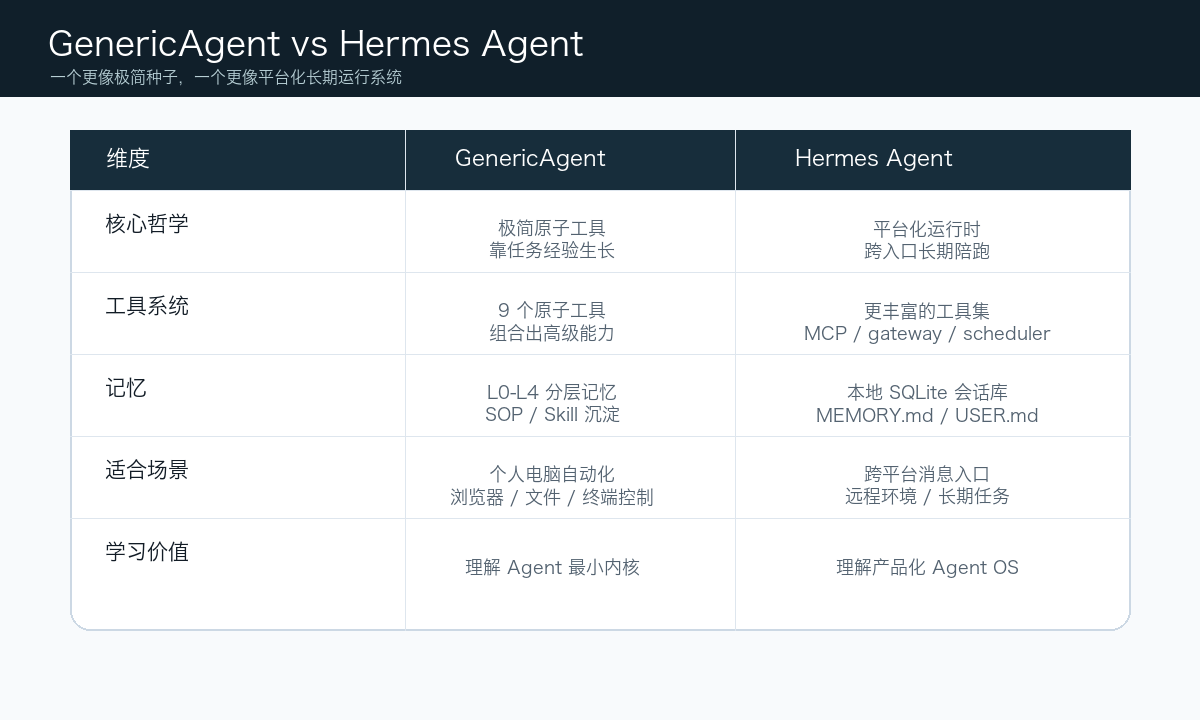
7. GenericAgent 和 Hermes Agent 有什么不同?
Hermes Agent 也强调 self-improving。官方介绍为 built-in learning loop:从经验创建 skills,在使用中改进 skills,持久化知识,搜索过去对话,并跨 session 建立用户模型。
两者相似点很明显:
- 都重视长期记忆
- 都强调 skill / procedure 的沉淀
- 都不是一次性聊天机器人,而是面向长期使用
- 都希望 Agent 能从过往任务中变强
但它们的气质不同。
GenericAgent 更像“极简种子”。它用很少的工具,让模型自己探索环境、写脚本、沉淀 SOP。它适合个人电脑、本地浏览器、文件系统、真实 GUI 操作这类场景。它追求的是:给模型一个足够底层的控制面,让能力自己长出来。
Hermes Agent 更像“Agent OS / 平台化产品”。它支持 CLI、Telegram、Discord、飞书、钉钉、微信 等多入口;有定时任务;能生成 subagents 并行处理任务;支持本地、Docker、SSH、Singularity、Modal、Daytona 等终端后端;还有更丰富的工具系统、MCP、Skills Hub、持久记忆和用户画像。
它的记忆实现也更偏产品化。Hermes 默认会把会话历史保存在本地 SQLite 里,并提供 session_search,让 Agent 可以按需搜索过去会话,而不是把所有历史一次性塞进当前上下文。除此之外,它还会在工作目录里维护可编辑的上下文文件,比如 MEMORY.md 用来记录项目知识、长期偏好和操作经验,USER.md 用来保存用户画像和个人偏好;也支持接入外部记忆系统,把长期记忆从本地文件扩展到更独立的后端。简单说,Hermes 的记忆不是单一数据库,而是一组“本地 SQLite 会话库 + 可读写上下文文件 + 历史会话检索 + 外部记忆后端”的组合。
简单说:
GenericAgent:seed-first,少量原子工具 + 自我演化
Hermes Agent:platform-first,完整运行时 + 跨平台长期服务
8. 如果你要自己写一个 Agent,建议路线
第一步,不要急着接框架。先写一个最小 Agent Loop。
第二步,加工具调用。先支持 2 到 3 个工具,比如搜索、计算器、文件读取。
第三步,实现 ReAct。让模型学会在“思考、行动、观察”之间循环。
第四步,加 Plan-and-Solve。让复杂任务先生成计划,再执行。
第五步,加 Reflection。对高价值任务做自我评审和优化。
第六步,加记忆。先做工作记忆和长期偏好,再考虑向量检索、会话归档、Skill 沉淀。
第七步,做上下文工程。不要把所有历史都塞给模型,而是学会选择、组织和压缩。
第八步,学习 GenericAgent 或 Hermes Agent。前者帮你理解极简自进化,后者帮你理解平台化 Agent 工程。
真正的 Agent,不是一个 prompt,也不是一个模型 API 封装。它是一套闭环系统:
理解目标
-> 构造上下文
-> 调用模型
-> 选择工具
-> 执行动作
-> 观察反馈
-> 更新记忆
-> 继续循环
当这个循环能稳定运行、能从失败中恢复、能把经验沉淀为下一次的捷径时,一个“自己的 Agent”才算真正开始长出来。
参考资料

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)