vllm分析(八)——deepseek v4 Attention (SWA + CSA + HCA)
分析vllm deepseek v4SWA,CSA,HCA的计算过程
DeepseekV4Attention
DeepseekV4Attention
DeepseekV4MultiHeadLatentAttentionWrapper
kv_cache
DeepseekV4IndexerCache
class DeepseekV4Indexer(nn.Module):
def __init__():
assert cache_config is not None, "Deepseek V4 indexer requires cache_config"
# NOTE(yifan): FP8 indxer cache use the same layout as V3.2:
# head_dim bytes = 128 fp8 + 4 fp32 scale = 132.
# For FP4 indexer cache, we still allocate the same amount of memory as FP8,
# but only use the first half of the memory.
k_cache_head_dim = self.head_dim + self.head_dim // self.quant_block_size * 4
self.k_cache = DeepseekV4IndexerCache(
head_dim=k_cache_head_dim,
dtype=torch.uint8,
prefix=f"{prefix}.k_cache",
cache_config=cache_config,
compress_ratio=self.compress_ratio,
)
self.compressor = DeepseekCompressor(
vllm_config=vllm_config,
compress_ratio=self.compress_ratio,
hidden_size=hidden_size,
head_dim=self.head_dim,
rotate=True,
prefix=f"{prefix}.compressor",
k_cache_prefix=self.k_cache.prefix,
use_fp4_cache=self.use_fp4_kv,
)
self.indexer_op = SparseAttnIndexer(
self.k_cache,
self.quant_block_size,
self.scale_fmt,
self.topk_tokens,
self.head_dim,
self.max_model_len,
self.max_total_seq_len,
self.topk_indices_buffer,
skip_k_cache_insert=True,
use_fp4_cache=self.use_fp4_kv,
)
DeepseekV4IndexerCache.kv_cache
在DeepseekV4Indexer中,compressor的压缩的kv entry用于SparseAttnIndexer计算topk索引。 压缩的kv entry存储到DeepseekV4IndexerCache.k_cache。
DeepseekV4SWACache
class DeepseekV4SWACache(torch.nn.Module, AttentionLayerBase):
def __init__(
self,
head_dim: int,
window_size: int,
dtype: torch.dtype,
prefix: str,
cache_config: CacheConfig,
):
super().__init__()
self.kv_cache = torch.tensor([])
self.head_dim = head_dim
self.window_size = window_size
self.prefix = prefix
self.cache_config = cache_config
self.dtype = dtype
compilation_config = get_current_vllm_config().compilation_config
if prefix in compilation_config.static_forward_context:
raise ValueError(f"Duplicate layer name: {prefix}")
compilation_config.static_forward_context[prefix] = self
DeepseekV4MLAAttention
class DeepseekV4MLAAttention(nn.Module, AttentionLayerBase):
def __init__():
self.kv_cache_dtype = kv_cache_dtype
# Register with compilation context for metadata lookup
compilation_config = vllm_config.compilation_config
if prefix and prefix in compilation_config.static_forward_context:
raise ValueError(f"Duplicate layer name: {prefix}")
if prefix:
compilation_config.static_forward_context[prefix] = self
self.kv_cache = torch.tensor([])
DeepseekV4MLAAttention.kv_cache
在CSA和HSA场景,DeepseekCompressor压缩后的kv entry存储到 DeepseekV4MLAAttention.kv_cache。
CompressorStateCache
class CompressorStateCache(torch.nn.Module, AttentionLayerBase):
def __init__(
self,
state_dim: int,
dtype: torch.dtype,
compress_ratio: int,
prefix: str,
):
super().__init__()
self.state_dim = state_dim
self.dtype = dtype
self.prefix = prefix
self.kv_cache = torch.tensor([])
compilation_config = get_current_vllm_config().compilation_config
if prefix in compilation_config.static_forward_context:
raise ValueError(f"Duplicate layer name: {prefix}")
compilation_config.static_forward_context[prefix] = self
kv cache 的tensor分配分析
DeepseekCompressor
DeepseekCompressor:负载kv块的压缩,用于Heavily Compressed Attention (HSA),Compressed Sparse Attention (CSA) 和 DeepseekV4Indexer。
class DeepseekCompressor(nn.Module):
"""DeepSeek V4 KV/score compressor.
Owns the linear / norm / state-cache / ape state and the shared forward
prologue (kv/score split, save_partial_states launch). The
compress → norm → RoPE → store step is dispatched to a triton kernel
(``compress_norm_rope_store_triton``) by default, except for the NVIDIA
head_dim=128 indexer path which uses the cutedsl kernel
(``compress_norm_rope_store_cutedsl``) for better performance.
"""
def __init__(
self,
vllm_config: VllmConfig,
compress_ratio: int,
hidden_size: int,
head_dim: int,
rotate: bool = False,
prefix: str = "",
k_cache_prefix="",
use_fp4_cache: bool = False,
):
self.overlap = compress_ratio == 4
self.coff = 1 + self.overlap
state_dtype = torch.float32
self.ape = nn.Parameter(
torch.empty(
(compress_ratio, self.coff * self.head_dim),
dtype=state_dtype,
device=self.device,
),
requires_grad=False,
)
self.fused_wkv_wgate = MergedColumnParallelLinear(
self.hidden_size,
[self.coff * self.head_dim, self.coff * self.head_dim],
bias=False,
return_bias=False,
quant_config=None,
disable_tp=True,
prefix=f"{prefix}.fused_wkv_wgate",
)
self.norm = RMSNorm(self.head_dim, self.rms_norm_eps)
self.state_cache = CompressorStateCache(
state_dim=2 * self.coff * self.head_dim, # kv_state + score_state
dtype=state_dtype,
compress_ratio=compress_ratio,
prefix=f"{prefix}.state_cache",
)
def forward(
self,
# [num_tokens, 2 * self.coff * self.head_dim]
kv_score: torch.Tensor,
# [num_tokens]
positions: torch.Tensor,
rotary_emb,
) -> None:
# Each of shape [num_tokens, coff * self.head_dim]
# input bf16, output are fp32
kv, score = kv_score.split(
[self.coff * self.head_dim, self.coff * self.head_dim], dim=-1
)
# Get the metadata and handle dummy profiling run.
attn_metadata = get_forward_context().attn_metadata
if not isinstance(attn_metadata, dict):
return
state_metadata = cast(
CompressorMetadata, attn_metadata[self.state_cache.prefix]
)
token_to_req_indices = state_metadata.token_to_req_indices
slot_mapping = state_metadata.slot_mapping
num_actual = slot_mapping.shape[0]
block_table = state_metadata.block_table
block_size = state_metadata.block_size
# [num_blocks, block_size, kv_dim+score_dim], where kv_dim == score_dim
state_cache = self.state_cache.kv_cache
# kv_state stored in first half, score_state stored in second half
state_width = state_cache.shape[-1] // 2
pdl_kwargs = (
{}
if current_platform.is_rocm() or current_platform.is_xpu()
else {"launch_pdl": False}
)
# Store the KV and score (with fused APE addition) in the state.
# NOTE: PDL is disabled — both this kernel and the compress kernels
# below depend on preceding kernel outputs (kv/score from the cublas
# GEMM; state_cache from this kernel) but neither emits/waits on PDL
# grid dependency primitives, so launch_pdl=True caused a
# read-after-write race and non-deterministic output.
save_partial_states(
kv=kv,
score=score,
ape=self.ape,
positions=positions,
state_cache=state_cache,
slot_mapping=slot_mapping,
block_size=block_size,
state_width=state_width,
compress_ratio=self.compress_ratio,
pdl_kwargs=pdl_kwargs,
)
# Fused: compress → RMSNorm → RoPE → FP8 quant → KV cache write.
# RoPE requirements (kernel applies forward GPT-J style rotation):
# - is_neox_style=False (interleaved pairs, NOT split-half)
# - cos_sin_cache layout: [max_pos, rope_head_dim] with first half cos,
# second half sin (per-pair, length rope_head_dim // 2 each)
# - applied to LAST rope_head_dim elements of head_dim
# - position used: (positions // compress_ratio) * compress_ratio
cos_sin_cache = rotary_emb.cos_sin_cache
k_cache_metadata = cast(Any, attn_metadata[self.k_cache_prefix])
kv_cache = self._static_forward_context[self.k_cache_prefix].kv_cache
if current_platform.is_cuda():
# NVIDIA GPUs.
if self.head_dim == 512:
from .nvidia.ops import compress_norm_rope_store_cutedsl
# Main compressor path.
# Use a cutedsl kernel for better performance.
compress_norm_rope_store_fn = compress_norm_rope_store_cutedsl
else:
# Indexer path (head_dim == 128).
# Use a triton kernel.
compress_norm_rope_store_fn = compress_norm_rope_store_triton
else:
# AMD GPUs.
# Always use a triton kernel.
compress_norm_rope_store_fn = compress_norm_rope_store_triton
compress_norm_rope_store_fn(
state_cache=state_cache,
num_actual=num_actual,
token_to_req_indices=token_to_req_indices,
positions=positions,
slot_mapping=slot_mapping,
block_table=block_table,
block_size=block_size,
state_width=state_width,
cos_sin_cache=cos_sin_cache,
kv_cache=kv_cache,
k_cache_metadata=k_cache_metadata,
pdl_kwargs=pdl_kwargs,
head_dim=self.head_dim,
rope_head_dim=self.rope_head_dim,
compress_ratio=self.compress_ratio,
overlap=self.overlap,
use_fp4_cache=self.use_fp4_cache,
rms_norm_weight=self.norm.weight,
rms_norm_eps=self.rms_norm_eps,
quant_block=self._quant_block,
token_stride=self._token_stride,
scale_dim=self._scale_dim,
)
CompressorStateCache
CompressorStateCache的kv_cache空间用到了滑动窗口机制。
SlidingWindowMLASpec到SlidingWindowManager。
滑动窗口滚动时:SlidingWindowManager 会持续计算当前窗口的有效范围。当部分 block 因超出窗口范围被判定为“不再需要”时,便会释放对应的块,remove_skipped_blocks。
save_partial_states
compress_norm_rope_store_triton
CSA 层 Compressor的工作原理
kv entry计算过程动态图,c4a attention illustation
head_dim =512。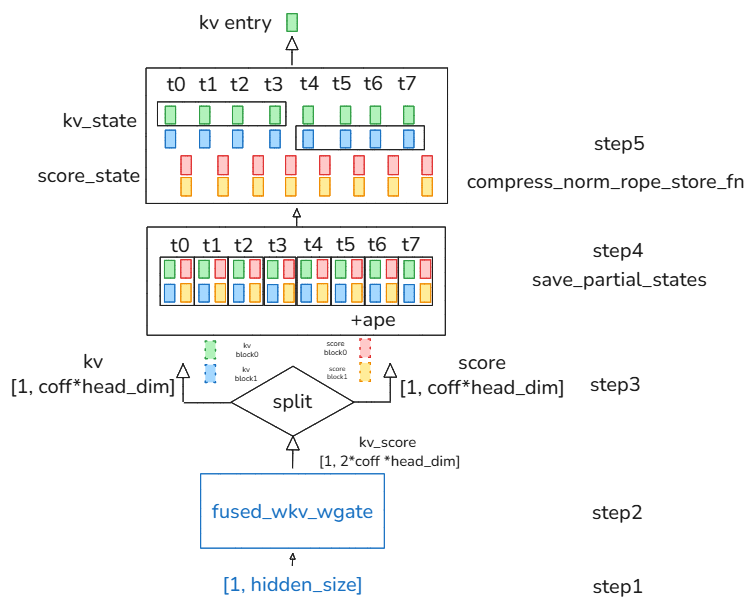
C a = H ⋅ W a K V , C b = H ⋅ W b K V C_a = H \cdot W_{a}^{KV}, \quad C_b = H \cdot W_{b}^{KV} Ca=H⋅WaKV,Cb=H⋅WbKV
Z a = H ⋅ W Z a , Z b = H ⋅ W b Z Z_a = H \cdot W^{a}_{Z}, \quad Z_b = H \cdot W_{b}^{Z} Za=H⋅WZa,Zb=H⋅WbZ
C Comp = Softmax row ( [ Z a + B a Z b + B b ] ) ⊤ ⊙ [ C a C b ] C_{\text{Comp}} = \text{Softmax}_{\text{row}}\left( \begin{bmatrix} Z_a + B_a \\ Z_b + B_b \end{bmatrix} \right)^\top \odot \begin{bmatrix} C_a \\ C_b \end{bmatrix} CComp=Softmaxrow([Za+BaZb+Bb])⊤⊙[CaCb]
wkv包含权重 W a K V W_{a}^{KV} WaKV和 W b K V W_{b}^{KV} WbKV, wgate包含权重 W a Z W_{a}^{Z} WaZ和 W b Z W_{b}^{Z} WbZ。
fuzed_wkv_wgagte融合了: W a K V W_{a}^{KV} WaKV, W b K V W_{b}^{KV} WbKV, W a Z W^{Z}_{a} WaZ, W Z b W^{b}_{Z} WZb。
代码和图片中的ape融合了公式中 B a B_a Ba和 B b B_b Bb。
save_partial_states 将新生成的kv, score存入state_cache.kv_cache 。save_partial_states 在 compress_ratio=4, coff=2 时的状态存储:
┌─────────────────────────────────────┬─────────────────────────────────────┐
│ kv_state │ score_state │
│ (STATE_WIDTH 个元素) │ (STATE_WIDTH 个元素) │
├─────────────────┬───────────────────┼─────────────────┬───────────────────┤
│ block0 │ block1 │ block0 │ block1 │
│ (head_dim 个) │ (head_dim 个) │ (head_dim 个) │ (head_dim 个) │
└─────────────────┴───────────────────┴─────────────────┴───────────────────┘
offset: 0 head_dim STATE_WIDTH STATE_WIDTH+head_dim
假设 token 位置:0,1,2,3,4,5,6,7,8,9,10,11,…
压缩边界在 3,7,11,…(即 position+1 是 4 的倍数)。
在压缩边界((position+1) % 4 == 0)时,会触发一次压缩,其窗口包含 (1+overlap)*compress_ratio = 8 个 token。
| 压缩边界 | 窗口位置(实际位置) | 使用的块(每个 token 贡献的块) |
|---|---|---|
| pos=3 | [-4,-3,-2,-1,0,1,2,3] | token -4…-1: 块0(旧组) token 0…3: 块1(新组) |
| pos=7 | [0,1,2,3,4,5,6,7] | token 0…3: 块0(旧组)token 4…7: 块1(新组) |
针对csa,compress_norm_rope_store_triton调用 _fused_kv_compress_norm_rope_insert_sparse_attn
计算过程:
[state_cache] ──┐
[score] ──┼─ softmax + weighted sum → compressed KV
[block_table] ──┘
↓
[RMSNorm]
↓
┌───────────┴───────────┐
↓ ↓
nope (448) rope (64)
↓ ↓
FP8 量化块 RoPE (GPT-J style)
↓ ↓
[FP8 data] [scale] [bf16 data]
└───────────┬───────────┘
↓
[k_cache] (逐 token 布局)
输出维度:
Cache block layout:
[0, bs*576): token data (448 fp8 + 128 bf16 each)
[bs*576, +bs*8): uint8 UE8M0 scales (7 real + 1 pad each)
前 448 字节:uint8 类型的 FP8 (E4M3) 数据(nope 部分)
后 128 字节:bfloat16 类型的 RoPE 数据(rope 部分)
紧接着 kv_cache_block_size * 8 字节:每个 token 的 scale 因子(7 个有效 uint8 + 1 个填充),用于反量化 FP8。
HSA Compressor的工作流程示意
博客[2]的流程图,说明了HSA的压缩过程。
针对HSA,compress_ratio=128,每128个kv条目压缩为1个kv entry。
head_dim =512。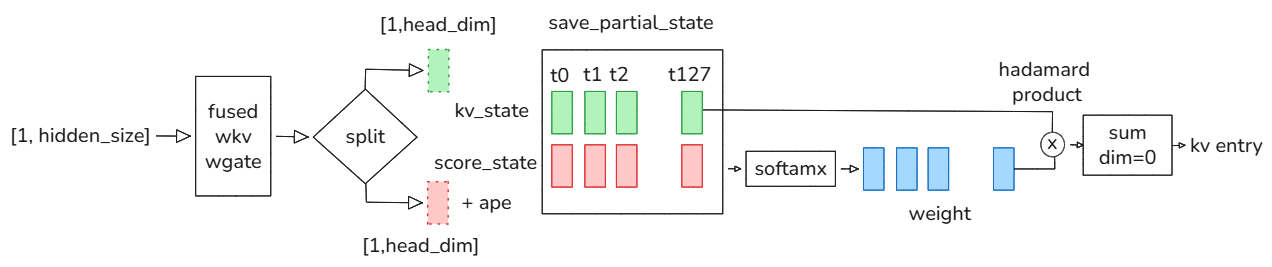
DeepseekV4Indexer
qr ──→ wq_b ──→ Q ──→ fused_indexer_q_rope_quant ──→ (q_quant, weights)
↑ │
indexer_weights │
positions │
compressed_kv_score ──→ compressor ──→ k ─────────────────────┤
│ │
└──→ self.k_cache (写入) │
▼
hidden_states ─────────────────────────────────────→ SparseAttnIndexer
│
▼
输出张量
fused_indexer_q_rope_quant 和 DeepseekCompressor并行运算。maybe_execute_in_parallel使用不同的stream。
SparseAttnIndexer对每个 query 执行 top‑k 选择(topk_tokens),将选出的索引写入 self.topk_indices_buffer(供外部使用)。
DeepseekV4Indexer计算示意,图片来源。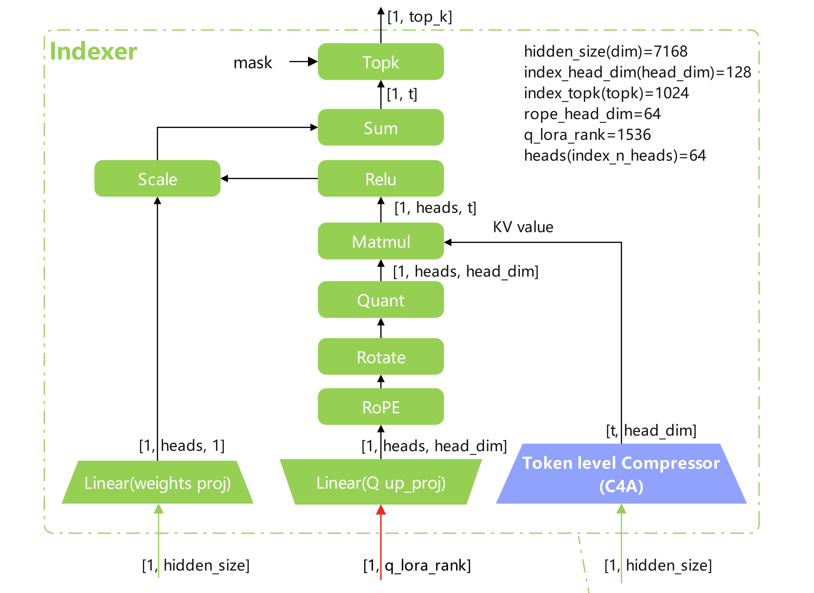
token level Compressor 计算过程:CSA 层 Compressor的工作原理。
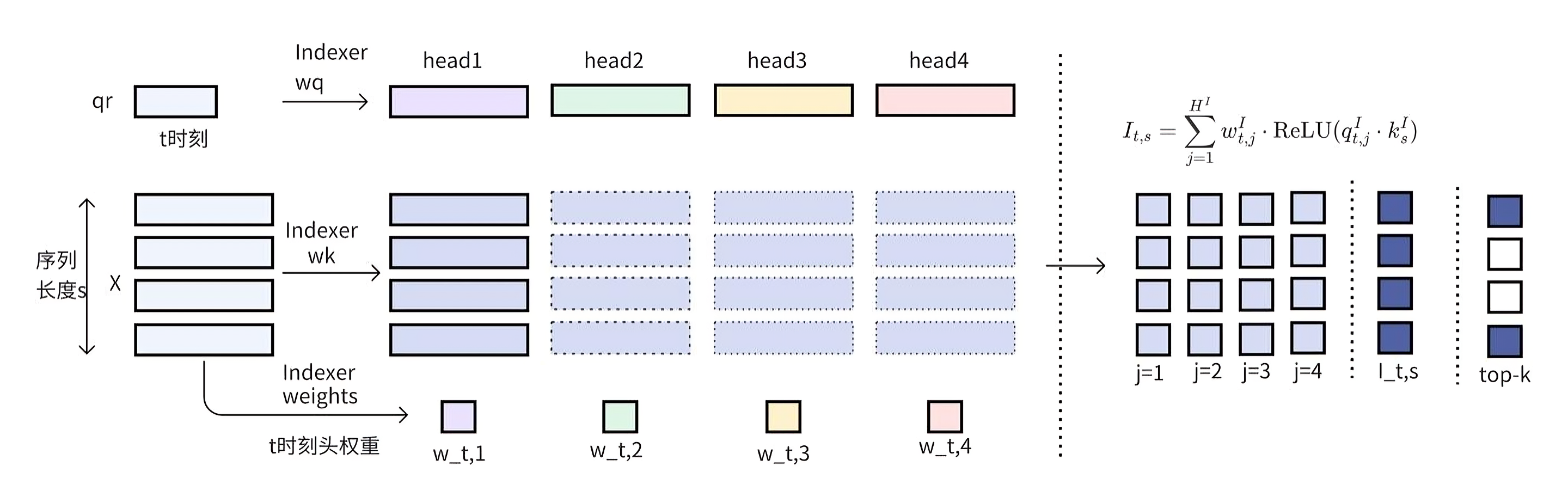
SparseAttnIndexer计算示意,图片来源
SparseAttnIndexer用于为每个 query token 选出最相关的 key-value tokens。
对于第 t个 query token与历史上的每个 token 的 k s I k_s^{I} ksI计算相关性得分:
I t , s = ∑ j = 1 H I w t , j I ⋅ ReLU ( q t , j I ⋅ k s I ) I_{t,s} = \sum_{j=1}^{H_I} w_{t,j}^I \cdot \text{ReLU}\left( \mathbf{q}_{t,j}^{I} \cdot \mathbf{k}_{s}^{I} \right) It,s=j=1∑HIwt,jI⋅ReLU(qt,jI⋅ksI)
- H I H_I HI:indexer 头数(固定为 64)
- q t , j I q_{t,j}^{I} qt,jI: 第t个 Token 在第j个索引头(Indexer Head)的 Query 向量。
- k s I k_{s}^{I} ksI: 第 s个 Token 的 Key 向量。该 Key 向量只有一个,被所有 64 个索引头共享。图片中的indexer wk后的箭头,方框为虚线形式。
- w t , j I w_{t,j}^I wt,jI:表示第 j个头的重要性。
- R e L U ReLU ReLU:激活函数,具备高吞吐量的计算优势。
Attention计算过程
DeepseekV4MultiHeadLatentAttentionWrapper.forward
deepseek_v4_attention
DeepseekV4MultiHeadLatentAttentionWrapper.attention_impl
[输入] hidden_states, positions
│
▼
╔════════════════════════════════════════════════════════════╗
║ 阶段1:并行 GEMM 投影 (attn_gemm_parallel_execute) ║
╠════════════════════════════════════════════════════════════╣
║ default stream: fused_wqa_wkv → qr_kv (主投影) ║
║ ↓ ║
║ aux_streams (最多3个,可选并行): ║
║ - compressor_kv_score (如果 compress_ratio > 1) ║
║ - indexer_weights_proj (如果 indexer exists) ║
║ - indexer_compressor_kv_score (如果 indexer exists) ║
║ ║
║ 同步: start_event 广播 → aux等待 → done_events等待 ║
╚════════════════════════════════════════════════════════════╝
│
▼
qr_kv, kv_score, indexer_kv_score, indexer_weights
│
▼
╔════════════════════════════════════════════════════════════╗
║ 阶段2:RMSNorm 归一化 (fused_q_kv_rmsnorm) ║
╠════════════════════════════════════════════════════════════╣
║ qr, kv = split(qr_kv, [q_lora_rank, head_dim]) ║
║ qr ← RMSNorm(qr, q_norm.weight) ║
║ kv ← RMSNorm(kv, kv_norm.weight) ║
╚════════════════════════════════════════════════════════════╝
│
▼
╔════════════════════════════════════════════════════════════╗
║ 阶段3:Q/KV 变换 + 缓存写入 (带多流分支) ║
╠════════════════════════════════════════════════════════════╣
║ ┌─────────────────────────────────────────────────────────┐
║ │ 分支 A: 存在 indexer (压缩器必然存在) │
║ │ default: wq_b_kv_insert │
║ │ → wq_b(qr) → [n_heads, head_dim] │
║ │ → (融合kernel): │
║ │ - Q: per-head RMSNorm + RoPE + 填充至padded_heads│
║ │ - KV: RoPE + FP8量化 + 写入SWA缓存 │
║ │ aux0: indexer.forward (含其内部wq_b+量化+稀疏索引) │
║ │ aux1: compressor.forward (压缩kv_score写索引器K缓存) │
║ │ 同步: default等待aux0,aux1完成 → 返回 q_padded │
║ ├─────────────────────────────────────────────────────────┤
║ │ 分支 B: 仅存在压缩器 (无 indexer) │
║ │ default: wq_b_kv_insert (同上) │
║ │ aux: compressor.forward │
║ │ 同步: maybe_execute_in_parallel │
║ ├─────────────────────────────────────────────────────────┤
║ │ 分支 C: 无压缩器 & 无 indexer (纯SWA) │
║ │ 顺序执行 wq_b_kv_insert │
║ └─────────────────────────────────────────────────────────┘
╚════════════════════════════════════════════════════════════╝
│
▼
q_padded ( [num_tokens, padded_heads, head_dim] )
kv (原始, 实际读缓存)
│
▼
╔════════════════════════════════════════════════════════════╗
║ 阶段4:稀疏注意力计算 (mla_attn) ║
╠════════════════════════════════════════════════════════════╣
║ backend: FlashMLASparseBackend (NVIDIA) / ROCm AITER ║
║ 输入: q_padded, kv, positions ║
║ 缓存: SWA缓存(FP8) + 索引器提供的稀疏索引(若存在) ║
║ 输出: out [num_tokens, padded_heads, head_dim] (预分配) ║
║ 注意: 仅使用SWA缓存中的KV,忽略输入的kv tensor ║
╚════════════════════════════════════════════════════════════╝
│
▼
[输出] out (后续经过逆RoPE + FP8 einsum + wo_b 得到最终结果)
结合vllm代码,画出csa计算过程示意图,图片参考了:图片源。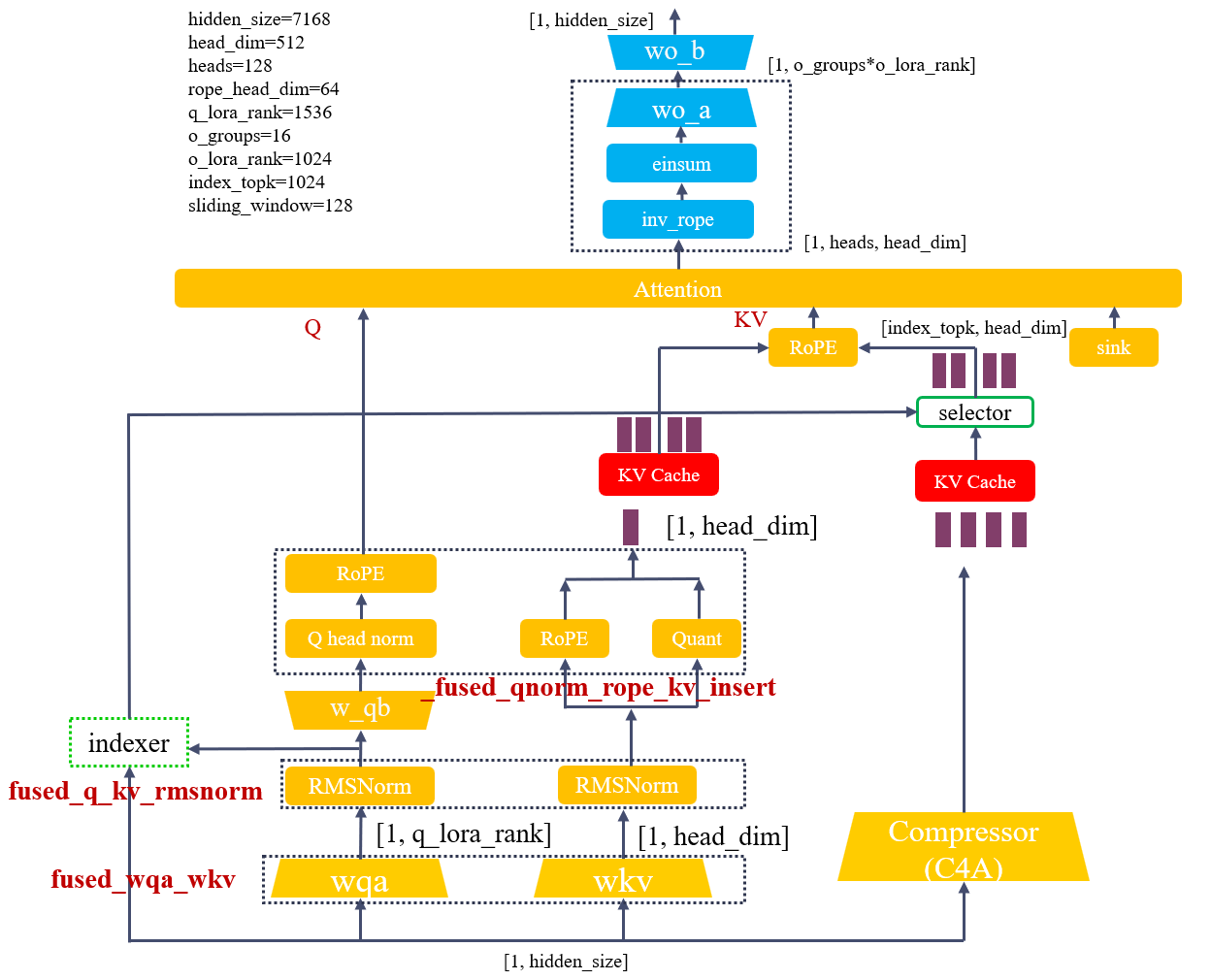
wqa和wkv的权重融合为 fused_wqa_wkv
q rmsnorm和 kv rmsnorm 融合为 fused_q_kv_rmsnorm。
w_qb的投影计算,self.wq_b(qr).view(-1, self.n_local_heads, self.head_dim)
qnorm rope 和 kv rope quant insert 融合为 _fused_qnorm_rope_kv_insert。
inv RoPE + FP8 einsum + wo_b 对应的代码位置
reference
[1] DeepSeek V4 in vLLM: Efficient Long-context Attention
[2] 手撕 DeepSeek-V4 (3): HCA
[3] DeepSeek v4 Compressor kv cache压缩模块
[4] DeepSeek V4-vLLM预览
[5] 图解DeepSeek V4:详细计算流程解析
[6] Deepseek-V4模型结构与源码解析

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)