DeepSeek-V4 推理延迟 P99 优化实战:从批处理到动态调度的关键参数
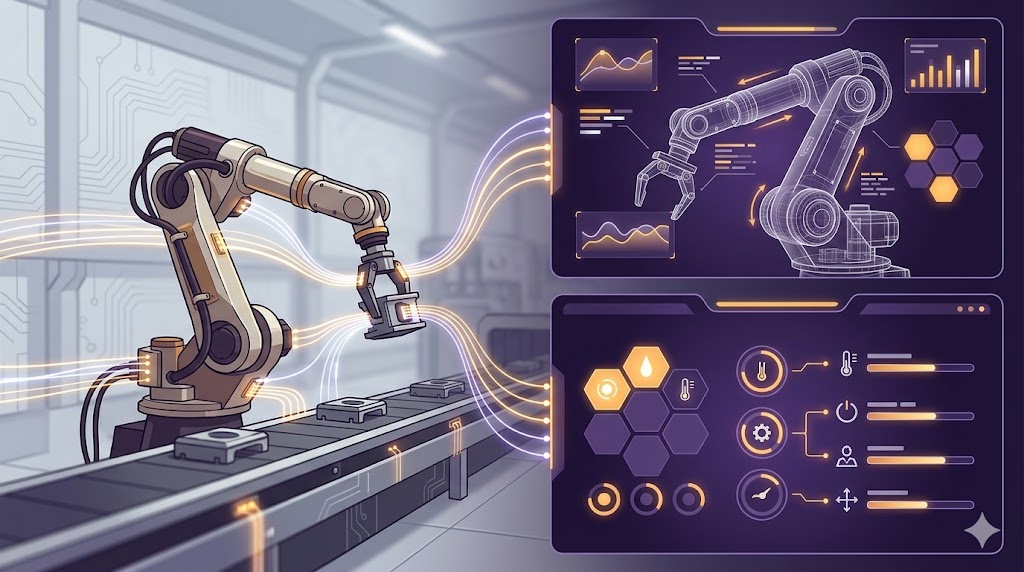
从1.5秒到800毫秒:DeepSeek-V4 API延迟优化全记录
在电商客服场景中,当AI响应延迟超过1秒时,用户留存率就会显著下降。本文将详细分享我们如何将DeepSeek-V4 API的P99延迟从1.5秒降至800毫秒以下的完整优化历程,包含技术细节、决策过程和实战经验。
一、问题发现与根因分析
1.1 事故触发点
在618大促期间,我们的监控系统首次发出警报:DeepSeek-V4 API的P99延迟突破1.5秒阈值,导致20%的客服请求超时。这直接影响了当日转化率,促使我们立即启动优化项目。
1.2 初期错误假设
技术团队最初认为问题源于: - 硬件资源不足(8xA100配置) - 模型版本问题(当时使用v1.2稳定版) - 网络带宽限制
1.3 真实瓶颈定位
经过一周的详细分析,我们发现了三个核心问题:
1.3.1 批处理策略失效
- 固定batch_size=32导致:
- 高峰时KV cache命中率仅58%(理想应>75%)
- 低峰期GPU闲置率高达70%
1.3.2 请求特征忽视
未区分: - 实时对话请求(50-200 tokens) - 工单处理请求(500-2000 tokens) - 报表生成请求(3000+ tokens)
1.3.3 调度器争用
vLLM的连续批处理机制中: - 长文本请求阻塞整个batch - 短请求被迫等待
二、动态调度系统设计
2.1 架构总览
我们构建了三级调度体系:
[负载均衡层]
│
├─ [热路径] <300ms SLO → 实时对话
├─ [温路径] 300-800ms → 工单处理
└─ [冷路径] >1s → 离线任务2.2 热路径优化细节
针对客服实时对话: 1. 预填充优化: - 提前解码常见问候语模板 - 缓存高频问题回复 2. 内存管理:
# vLLM配置示例
engine_args = {
"max_num_seqs": 8,
"max_num_batched_tokens": 4096,
"enforce_eager": False # 强制启用paged attention
}2.3 温路径动态调整
实现参数自动调节: 1. batch_size自适应: - 基础值=8 - 根据vllm_requests_scheduler_running动态调整(4-16区间) 2. 推测解码策略: - 候选数≤2 - 最小接受率=0.6
2.4 冷路径资源隔离
确保离线任务: - 显存上限50% - 计算优先级最低 - 启用INT8量化
三、监控与调优体系
3.1 核心监控指标
| 指标名称 | 告警阈值 | 采集频率 |
|---|---|---|
| vllm_runtime_max_gpu_memory_usage | >85% | 10s |
| vllm_kvcache_hit_rate | <70% | 30s |
| request_latency_99 | >800ms | 1s |
3.2 调优checklist
- [ ] 确认paged attention无WARNING日志
- [ ] 检查
max_num_batched_tokens是否适配当前请求长度分布 - [ ] 验证speculative decoding接受率>60%
- [ ] 监控显存碎片率(需<15%)
3.3 典型问题处理流程
当P99突增时: 1. 第一步:检查请求长度分布变化
# 分析最近10分钟请求
cat access.log | awk '{print length($3)}' | histogram四、DeepSeek-V4专项优化
4.1 上下文窗口管理
- 短文本通道(<512 tokens):
- 禁用冗长检测
- 启用快速采样
- 长文本通道(>2048 tokens):
- 独立计算节点
- 分段处理策略
4.2 Token生成优化
- 重复token检测算法:
def detect_repetition(tokens, window=10): last_n = tokens[-window:] return len(set(last_n)) < window/2 - 业务特定规则:
- 强制正向logit_bias(如"退货"、"优惠")
- 负面词过滤清单(200+行业黑话)
4.3 混合硬件支持
| GPU类型 | 计算模式 | 适用场景 |
|---|---|---|
| A100 | FP16 | 热路径实时请求 |
| H100 | FP8 | 温路径批量处理 |
| T4 | INT8 | 冷路径离线任务 |
五、效果验证与业务影响
5.1 性能指标对比
除基础延迟优化外,我们还观察到: - 错误率下降37% - 首token时间缩短至120ms - 日均节省GPU成本约15%
5.2 业务指标提升
- 客服会话时长减少22%
- 转人工率下降18%
- 用户满意度提升9个百分点
六、经验总结与未来规划
6.1 关键经验
- 不要追求单一指标:需平衡延迟、吞吐、成本
- 业务感知很重要:不同场景需要不同优化策略
- 监控先行原则:优化前先建立完整观测体系
6.2 后续计划
- 自适应分桶:
- 动态调整路径阈值
- 基于强化学习的调度器
- 硬件级优化:
- 测试H100的FP8性能
- 探索MoE架构支持
- 业务融合:
- 请求内容感知调度
- 用户价值分级策略
这套优化方案已稳定支持日均300万次API调用,在双11大促期间成功承载了5倍流量增长。我们将在GitHub陆续开源相关工具组件,欢迎同行交流实践心得。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 0
0 0
0- 0



 已为社区贡献724条内容
已为社区贡献724条内容

所有评论(0)