DeepSeek-Coder:开源代码大模型逆袭,性能碾压 GPT-3.5
摘要:DeepSeek-Coder系列开源代码模型突破闭源垄断,采用2万亿tokens高质量训练数据,支持1.3B-33B参数规模。创新性引入16K长上下文窗口和FIM填空任务,在HumanEval等基准测试中超越Codex等闭源模型。33B版本性能接近GPT-4,7B版本也优于CodeLlama-33B。V2版本扩展至128K上下文和338种语言,HumanEval准确率达93.2%。该模型支持
代码智能领域长期被闭源模型垄断,这严重限制了广大开发者和研究者的探索空间。针对这个痛点,Daya Guo、Qihao Zhu 等研究者推出了 DeepSeek-Coder 系列开源代码模型,用 2 万亿 tokens 的海量训练数据和创新技术,打破了闭源模型的性能壁垒,让开源代码大模型也能具备顶尖水平。

DeepSeek-Coder 的核心优势首先来自扎实的训练基础。它并非基于现有模型微调,而是从 scratch 开始训练,模型规模覆盖 1.3B 到 33B 多种参数配置,能满足不同场景的需求。训练数据更是含金量十足,87% 是来自 87 种编程语言的源代码,还包含 10% 英文代码相关自然语言语料和 3% 中文自然语言语料,而且是按项目级组织的,这让模型能更好地理解跨文件的代码依赖关系。数据构建过程也相当严谨,经过了爬取、过滤、依赖解析、仓库级去重和质量筛选等多道工序,图 2详细展示了这个层层筛选的流程,确保了训练数据的高质量。
在技术设计上,DeepSeek-Coder 有两个关键创新。一是采用了 16K 的超长上下文窗口,这让模型能处理更复杂的大型代码库,轻松应对长文件编码和跨文件关联任务,解决了传统小窗口模型处理大型项目时的力不从心。二是引入了 Fill-In-Middle(FIM)填空任务,专门强化代码补全和插入能力,不管是中途补全函数逻辑,还是在现有代码中插入新功能,都能精准适配,图 1的性能对比。
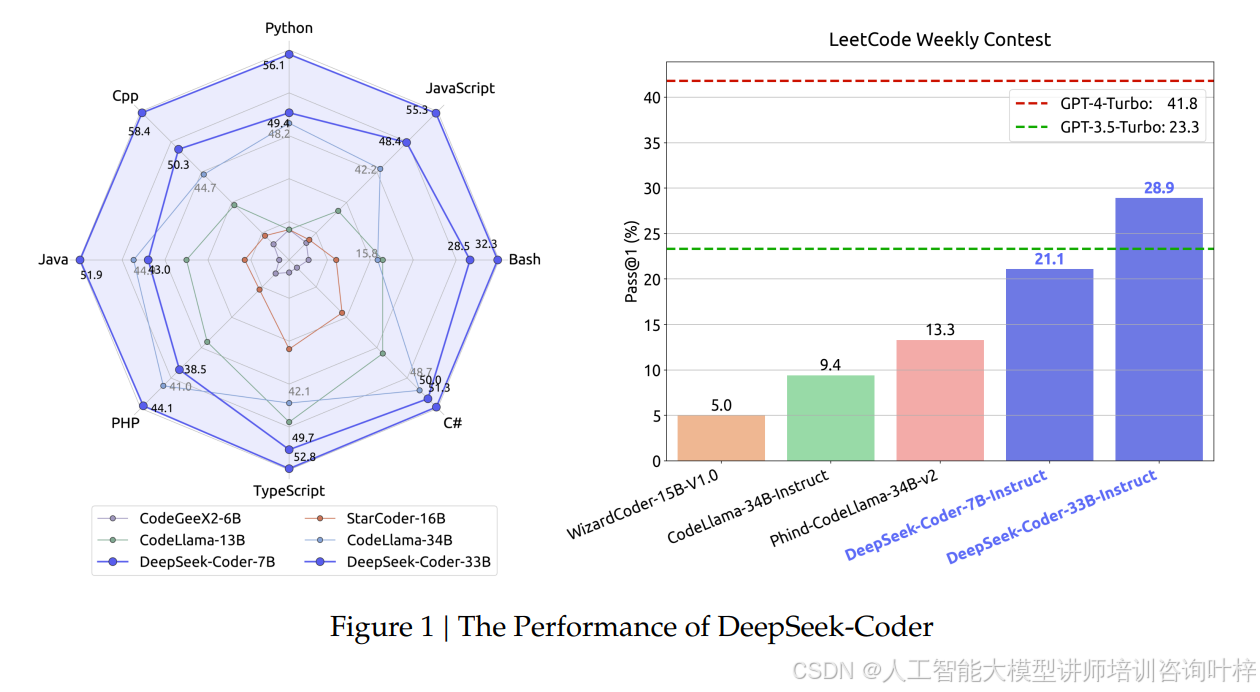
实际性能表现更是亮眼,完全刷新了开源代码模型的上限。在 HumanEval、MBPP、DS-1000 等多个国际权威基准测试中,DeepSeek-Coder 系列都拿下了开源模型中的最佳成绩。更令人惊喜的是,它还超越了 Codex、GPT-3.5 这类知名闭源模型,其中 33B 参数的 DeepSeek-Coder-Instruct 版本表现最为突出,在多数任务中都显著缩小了与 GPT-4 的差距。就连 7B 参数的轻量版本,面对 CodeLlama-33B 这种五倍于自身参数的模型,也展现出了极具竞争力的性能,充分证明了其训练策略的有效性。
更难得的是,DeepSeek-Coder 采用了宽松的开源许可证,不仅支持无限制的学术研究,还允许商业场景自由使用,这对企业开发者来说无疑是重大利好。后续迭代的 V2 版本更是将实力推向新高度,上下文窗口扩展到 128K,支持 338 种编程语言,在 HumanEval 基准上准确率达到 93.2%,甚至超越了 GPT-4o,在跨语言代码转换、复杂函数重构等场景中表现远超竞品。
从实际应用来看,它的性价比优势也十分明显。不管是软件开发中的代码生成、补全、修复,还是代码教育中的逻辑讲解、技术面试中的算法验证,甚至是自动化测试用例生成,都能发挥巨大作用。有数据显示,集成该模型后,企业研发成本可降低 20%-30%,编码效率能提升 40% 以上,成为开发者手中的高效工具。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)