千问0.5B实现简单的对话机器人
千问0.5B实现简单的对话机器人
·
文章目录
电脑2G显存,问了下,可以跑0.5B。
环境准备
复用模型微调的环境,见另外一篇笔记。
代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 配置
MODEL_NAME = "Qwen/Qwen2.5-0.5B-Instruct"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(f"正在加载模型到 {DEVICE} ...")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
# 加载模型 (关键:使用 float16 或 int8/int4 量化以节省显存)
# 2G 显存建议:如果报错显存不足,添加 load_in_8bit=True (需安装 bitsandbytes)
if DEVICE == "cuda":
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16, # 半精度,省一半显存
device_map="auto", # 自动分配设备
trust_remote_code=True
)
else:
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float32,
device_map="auto",
trust_remote_code=True
)
print("模型加载完成!开始对话 (输入 'exit' 退出)...")
# 对话历史
messages = []
while True:
user_input = input("\n👤 你: ")
if user_input.lower() in ['exit', 'quit', '退出']:
break
# 构建消息列表
messages.append({"role": "user", "content": user_input})
# 应用 Chat Template (Qwen 必需)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成回答
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512, # 限制输出长度,防止显存爆掉
do_sample=True,
temperature=0.7,
top_p=0.9
)
# 提取回复
generated_ids = [
output_ids[len(input_ids):]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"🤖 AI: {response}")
# 将回复加入历史
messages.append({"role": "assistant", "content": response})
效果
1、回答问题比较慢。
2、答得不准,复现了一本正经的胡说八道。
2、答得不准,复现了一本正经的胡说八道。
问:2 + 3 + 4 + 5 + 89 等于多少?
应该是103,居然答的100,如图: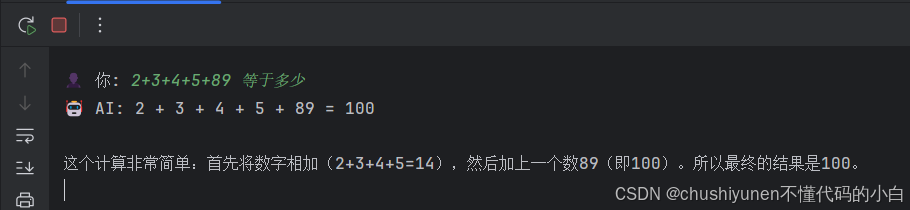

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)