CLAUDE.md 实战:让 AI 记住你整个项目的“潜规则“
简单说,CLAUDE.md就是你给 AI 写的一份项目入职手册。想象一下,一个新同事入职第一天,你会怎么带他?"我们项目用 React + TypeScript,状态管理用 Zustand,样式方案是 Tailwind,包管理器用 pnpm。代码提交前跑。组件命名用 PascalCase,文件名用 kebab-case。我们的 API 全走/api/v2前缀,鉴权用 JWT。有问题先看docs/目
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
前面我们聊了 Context 工程、Agent Skills、MCP 工具链……但你有没有遇到过这种情况——
你在 Claude Code 里让 AI 帮你改个接口,它改完了,但命名风格不对;你让它新建个页面,它用了你们团队半年前就淘汰的组件库;你让它跑测试,它连你们项目的测试命令都不知道。
每次对话都要重复交代一遍:"我们用 pnpm 不是 npm"、"组件放 src/components 下面"、"commit message 用 conventional commits"……
这些东西,不是 Prompt 能解决的,也不是 Skills 该管的——它们是项目的"潜规则"。
今天我们就来聊聊 CLAUDE.md,一个让 AI 把你项目的潜规则"刻进记忆"的机制。
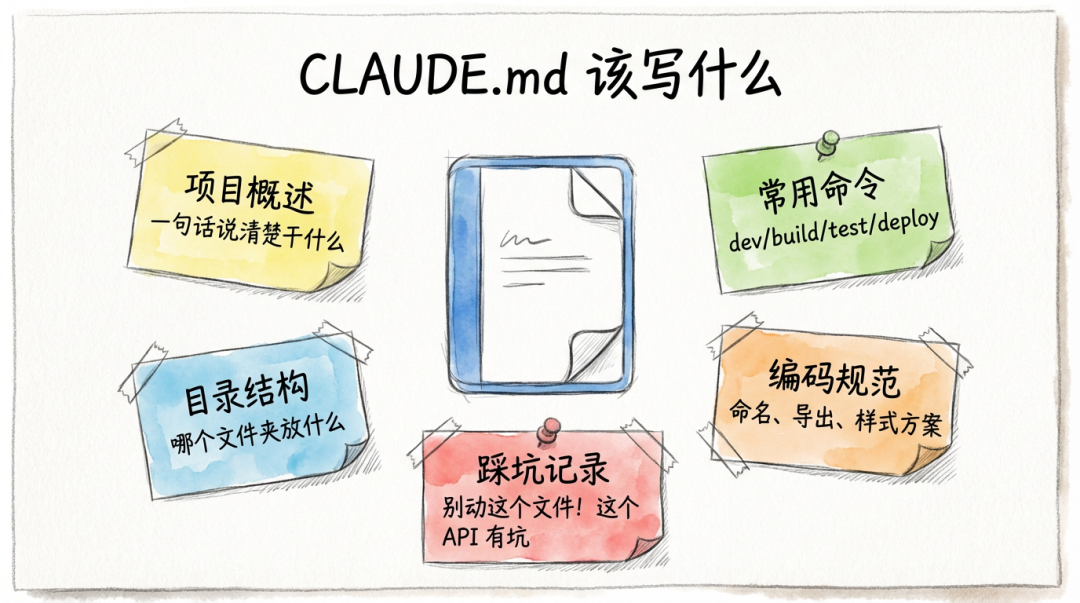
什么是 CLAUDE.md?
简单说,CLAUDE.md 就是你给 AI 写的一份项目入职手册。
想象一下,一个新同事入职第一天,你会怎么带他?
"我们项目用 React + TypeScript,状态管理用 Zustand,样式方案是 Tailwind,包管理器用 pnpm。代码提交前跑pnpm lint && pnpm test。组件命名用 PascalCase,文件名用 kebab-case。我们的 API 全走/api/v2前缀,鉴权用 JWT。有问题先看docs/目录。"
你不可能每次带新人都从头讲一遍吧?写成文档,放在那,人来了自己看就行。
CLAUDE.md 就是这个文档——只不过读者不是人,是 AI。
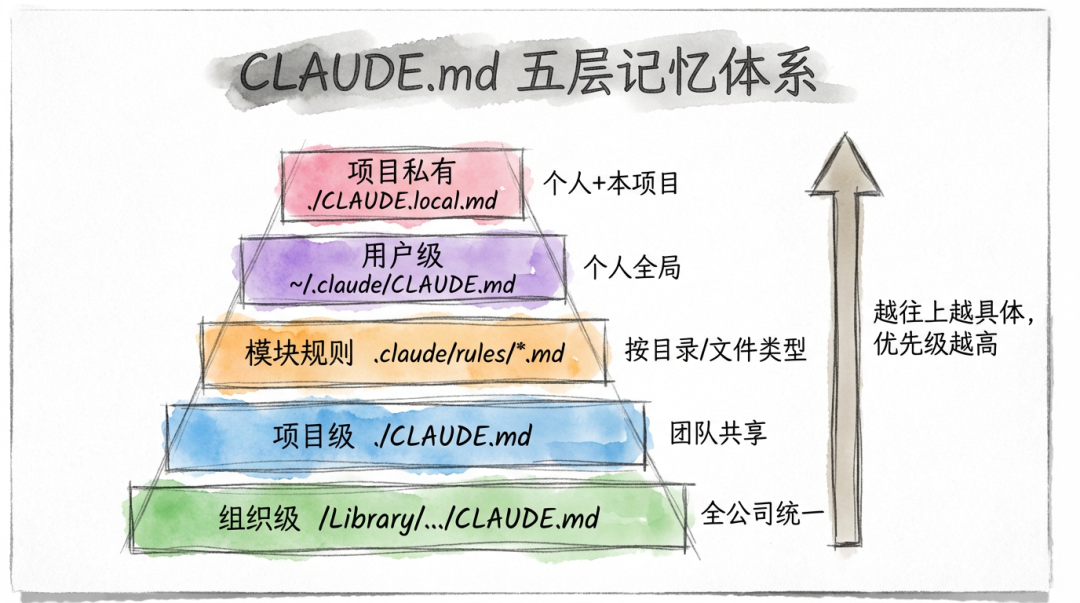
▎CLAUDE.md 的加载机制
Claude Code 启动时,会自动做一件事:从当前目录一路往上扫描,把沿途所有的 CLAUDE.md 和 CLAUDE.local.md 都加载进上下文。
~/.claude/
📄 CLAUDE.md ← 全局配置(所有项目生效)
~/projects/my-app/
📄 CLAUDE.md ← 项目级配置(团队共享,提交到 Git)
📄 CLAUDE.local.md ← 个人配置(gitignore,不提交)
~/projects/my-app/packages/web/
📄 CLAUDE.md ← 子目录配置(进入该目录时按需加载)
这个设计非常讲究,它构成了一个三层记忆体系:
| 层级 | 文件 | 作用 | 是否提交 Git |
|---|---|---|---|
| 全局层 | ~/.claude/CLAUDE.md |
你的个人编码偏好,所有项目通用 | 不提交 |
| 项目层 | 项目根目录/CLAUDE.md |
项目架构、技术栈、团队规范 | ✅ 提交 |
| 项目层(个人) | 项目根目录/CLAUDE.local.md |
个人本地环境配置、临时笔记 | 不提交 |
| 子目录层 | 子目录/CLAUDE.md |
子模块的特殊规则 | ✅ 提交 |
这种分层设计的好处是:团队规范和个人偏好分离,全局配置和项目配置分离。你不用担心自己的个人习惯污染团队规范,也不用每个项目都重复写一遍自己的通用偏好。
CLAUDE.md 里该写什么?
这是大家最关心的问题。我总结为三个层面:WHAT(是什么)、HOW(怎么做)、WHY(为什么)。
▎1. WHAT:项目是什么
让 AI 快速建立对项目的"全景认知":
## 项目概览
- 这是一个 B2B SaaS 平台的前端项目
- 技术栈:React 18 + TypeScript 5 + Vite 5 + Zustand + Tailwind CSS 3
- 包管理器:pnpm(不要使用 npm 或 yarn)
- Node.js 版本:>= 20
## 项目结构
src/
├── app/ # 路由和页面入口
├── components/ # 通用 UI 组件(Atomic Design 分层)
│ ├── atoms/
│ ├── molecules/
│ └── organisms/
├── features/ # 按业务功能划分的模块
├── hooks/ # 通用自定义 Hooks
├── lib/ # 第三方库的封装和配置
├── stores/ # Zustand store 定义
├── types/ # 全局 TypeScript 类型
└── utils/ # 工具函数
这部分最重要的就是项目结构。在 monorepo 场景下更是如此——AI 必须知道每个 package 是干什么的,代码该去哪找。
▎2. HOW:怎么做
告诉 AI 团队的开发规范和常用命令:
## 常用命令
- 启动开发:`pnpm dev`
- 跑测试:`pnpm test`(单元测试用 Vitest)
- 跑 lint:`pnpm lint`(ESLint + Prettier)
- 构建:`pnpm build`
- 类型检查:`pnpm typecheck`
## 编码规范
- 组件文件命名:PascalCase(如 `UserCard.tsx`)
- 工具函数命名:camelCase(如 `formatDate.ts`)
- 常量命名:UPPER_SNAKE_CASE
- CSS 类名:Tailwind 优先,不写自定义 CSS,除非 Tailwind 搞不定
- 所有组件必须导出 Props 类型,命名格式为 `XxxProps`
- 异步请求统一使用 `src/lib/request.ts` 封装的方法
- 不要使用 `any`,如果暂时无法确定类型,用 `unknown` + 类型收窄
## Git 规范
- commit message 格式:`type(scope): description`
- type 取值:feat / fix / refactor / docs / chore / test
- 提交前必须通过 lint 和 typecheck
▎3. WHY:为什么这么做(避坑指南)
这是很多人忽略的部分,但恰恰是最能体现"潜规则"的地方:
## 注意事项(重要!)
- ❌ 不要用 `moment.js`,项目统一用 `dayjs`(体积差 10 倍)
- ❌ 不要直接操作 DOM,所有 DOM 操作走 React ref
- ❌ 不要在组件内直接 fetch,所有请求走 `src/lib/request.ts`
- ❌ 不要使用 `export default`,统一使用具名导出
- ⚠️ `UserService` 模块正在重构中,新功能请使用 `UserServiceV2`
- ⚠️ 数据库查询走读写分离,写操作用 primary,读操作用 replica
- ✅ 新页面必须添加路由守卫和权限校验
- ✅ 所有表单必须做前端校验 + 后端二次校验
这些"不要做什么"的信息,比"要做什么"更有价值。 因为 AI 默认会用它训练数据中最主流的方案,而你的项目可能有特殊原因选择了不同的方案。
一个完整的 CLAUDE.md 示例
把上面三个层面组合起来,一个实际项目的 CLAUDE.md 大致长这样:
# 项目:Awesome SaaS Dashboard
B2B SaaS 管理后台前端,服务企业客户的数据看板和运营工具。
## 技术栈
- React 18 + TypeScript 5.3 + Vite 5
- 状态管理:Zustand(不要用 Redux)
- 样式:Tailwind CSS 3(不要写自定义 CSS)
- 请求:@tanstack/react-query + 自封装 axios
- 测试:Vitest + Testing Library
- 包管理:pnpm 9(不要用 npm/yarn)
## 项目结构
[略,同上]
## 常用命令
- `pnpm dev` - 启动开发服务
- `pnpm test` - 运行测试
- `pnpm lint` - 代码检查
- `pnpm build` - 生产构建
## 编码约定
- 组件用具名导出,不用 export default
- Props 类型必须导出,格式:`XxxProps`
- hooks 放在 `src/hooks/`,以 `use` 开头
- 异步请求走 `src/lib/api-client.ts`,不要直接用 axios
- 日期处理用 dayjs,不要用 moment
## 当前注意事项
- UserService 正在迁移到 v2,新功能用 `src/features/user-v2/`
- 图表组件从 echarts 迁移到 recharts 中,新图表用 recharts
- /api/v1 接口将在 Q2 废弃,新接口走 /api/v2
注意这里的风格:简洁、直接、用列表,不要长篇大论。AI 读 markdown 列表比读段落高效得多。
实战技巧
▎技巧 1:用 /init 快速生成
不想从零开始写?在 Claude Code 里直接执行:
/init
Claude 会扫描你的项目,自动生成一份 CLAUDE.md 草稿。你在这个基础上修改补充就行,比自己从头写快多了。
▎技巧 2:用 @import 拆分大文件
如果你的项目很大,一个 CLAUDE.md 写不下,可以用引用语法拆分:
# 项目规范
@docs/architecture.md
@docs/coding-standards.md
@docs/api-conventions.md
Claude 会按需加载这些引用文件,最大支持 5 层嵌套。
▎技巧 3:CLAUDE.local.md 存个人配置
你个人的一些偏好,不适合提交到团队仓库的,放 CLAUDE.local.md:
# 个人偏好
- 我习惯看到详细的代码注释
- 代码修改后先告诉我改了哪些文件,再展示 diff
- 我的本地 API 地址是 http://localhost:3001
- 测试账号:admin@test.com / test123
记得把它加到 .gitignore。
▎技巧 4:子目录级别的精细控制
在 monorepo 中,不同 package 可能有完全不同的规范:
packages/
├── web/
│ └── CLAUDE.md # React + Tailwind 规范
├── mobile/
│ └── CLAUDE.md # React Native 规范
├── server/
│ └── CLAUDE.md # Node.js + Prisma 规范
└── shared/
└── CLAUDE.md # 纯 TypeScript,无框架依赖
当 AI 在某个子目录下工作时,会自动加载对应的 CLAUDE.md,精准匹配上下文。
核心概念辨析:CLAUDE.md、Rules、Skills、Context
前几篇文章我们分别聊了 Skills 和 Context 工程,加上今天的 CLAUDE.md,再算上 Cursor 的 Rules,你可能已经有点晕了——这些概念到底有什么区别?
先说一个很多人的疑惑:CLAUDE.md 和 Rules 不是一回事吗?
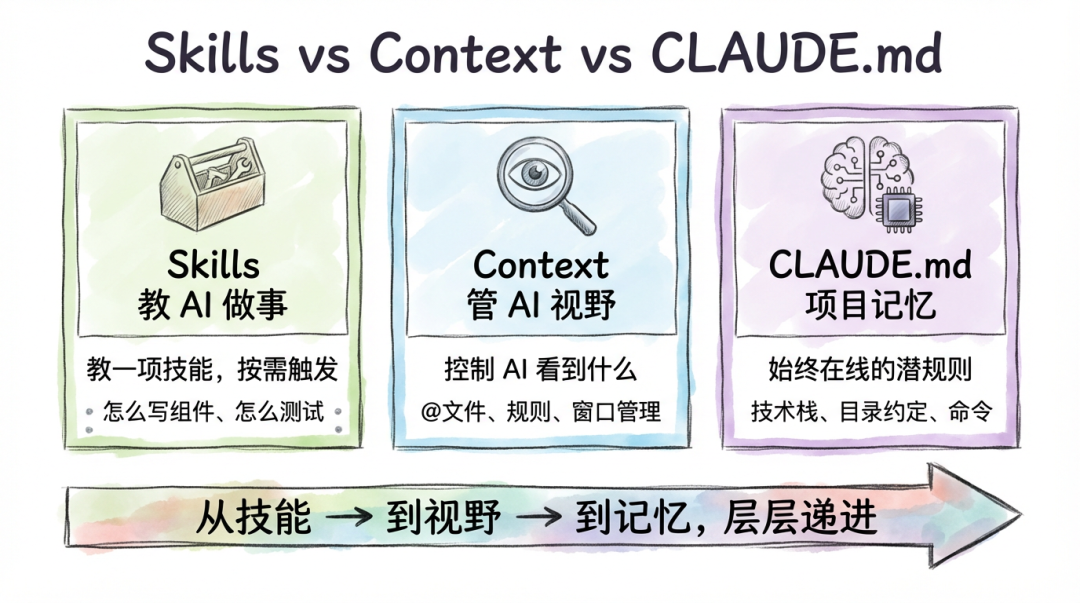
▎CLAUDE.md 和 Rules:本质上是同一个东西
说实话,是的。 它们解决的是完全相同的问题——让 AI 了解你的项目规范,别写出离谱的代码。
你在 CLAUDE.md 里写"不要用 moment.js,用 dayjs",和在 .cursorrules 里写同样的话,效果一模一样。内容上没有任何区别,能写在 CLAUDE.md 里的东西,全都可以写在 Rules 里,反过来也是。
那为什么有两个东西?因为不同的 AI 工具各自造了一套:
| 工具 | "规则"文件 | 它们叫什么 |
|---|---|---|
| Claude Code | CLAUDE.md |
叫"项目记忆" |
| Cursor | .cursorrules / .cursor/rules/ |
叫"Rules" |
| GitHub Copilot | .github/copilot-instructions.md |
叫"Instructions" |
| Windsurf | .windsurfrules |
叫"Rules" |
| 通用新标准 | AGENTS.md |
叫"Agent 指令" |
就像 .eslintrc 和 biome.json 都是做代码检查一样——内容能写的差不多,但你用 ESLint 就得写前者,用 Biome 就得写后者。CLAUDE.md 和 Rules 的关系完全一样:用 Claude Code 就写 CLAUDE.md,用 Cursor 就写 .cursorrules,用 Copilot 就写 copilot-instructions.md。
当然,机制上有一些微小差异:
- ▸
CLAUDE.md支持目录级分层(全局 → 项目 → 子目录)和CLAUDE.local.md个人隔离,这点比 Cursor Rules 更灵活 - ▸Cursor Rules 支持条件触发(比如只在编辑
.tsx文件时生效某条规则),这点比 CLAUDE.md 更精细 - ▸如果你同时用多个工具,可能需要两边都写一份(或者用
AGENTS.md这个通用标准,越来越多工具开始支持了)
但说到底,不要被名字迷惑了——CLAUDE.md 就是 Claude Code 版的 Rules。
▎那 Skills 和 Context 呢?
理清了 CLAUDE.md ≈ Rules 之后,我们再看 Skills 和 Context,这两个跟前者是真不一样。
Skills —— "遇到这种情况,按这个流程来"
Skills 解决的核心问题是:AI 不会做某个特定任务的完整流程。
CLAUDE.md / Rules 告诉 AI 的是"背景知识和约定",而 Skills 告诉 AI 的是"一套完整的操作步骤"。
比如你写一个 "create-react-component" 的 Skill:
name: create-react-component
description: 创建符合团队规范的 React 组件
## 步骤
1. 在 src/components/ 下创建组件目录
2. 创建 index.tsx(组件代码)、index.test.tsx(测试)、index.stories.tsx(Storybook)
3. 在 src/components/index.ts 中添加导出
4. 运行 pnpm test 确认测试通过
关键区别在于加载方式:
- ▸CLAUDE.md / Rules 是始终加载的——每次对话都在,不管你聊什么话题
- ▸Skills 是按需触发的——只有当 AI 判断当前任务匹配某个 Skill 时才加载
这就是为什么不把所有东西都塞进 CLAUDE.md 的原因。你可以有 50 个 Skills,但每次对话只加载匹配的 1-2 个,节省了上下文窗口的宝贵空间。
打个比方:CLAUDE.md 是贴在工位上的便签纸(始终能看到),Skills 是放在抽屉里的操作手册(需要的时候才拿出来翻)。
Context —— "AI 当前能看到的一切"
Context 不是一个文件,而是一个运行时概念。它指的是 AI 在某一次对话中,能"看到"的所有信息的总和。
包括但不限于:
- ▸CLAUDE.md / Rules 的内容
- ▸触发的 Skills 内容
- ▸你的 Prompt(本轮对话的指令)
- ▸当前打开的文件、选中的代码
- ▸终端输出、lint 报错、Git diff
- ▸……
所以,Context 是一个容器,其他都是往容器里放东西的手段。
▎用一张图理清关系
┌──────────────────────────────────────────────────┐
│ Context(上下文容器) │
│ │
│ ┌──────────────────────────────────┐ │
│ │ CLAUDE.md / Rules / AGENTS.md │ ← 始终加载 │
│ │ (项目规范,各工具叫法不同而已) │ │
│ └──────────────────────────────────┘ │
│ │
│ ┌──────────────┐ │
│ │ Skills │ ← 按需加载 │
│ │ (操作流程) │ │
│ └──────────────┘ │
│ │
│ ┌──────────────────────────────────┐ │
│ │ Prompt + 文件 + 报错 + Git... │ ← 实时生成 │
│ │ (当次会话的动态信息) │ │
│ └──────────────────────────────────┘ │
└──────────────────────────────────────────────────┘
Context 是池子,其他都是往池子里注水的管道。好的 Context 工程,就是在有限的池子容量内,注入最有价值的水。
▎总结:三个真正不同的概念
| 概念 | 是什么 | 加载方式 | 类比 |
|---|---|---|---|
| CLAUDE.md / Rules | 项目规范和约定(各工具的不同实现) | 始终加载 | 贴在工位上的便签 |
| Skills | 具体任务的操作流程 | 按需触发 | 抽屉里的操作手册 |
| Context | AI 当前能看到的所有信息 | 运行时动态组装 | 同事桌上的全部材料 |
实际项目中怎么放?
| 你想要 AI 知道的 | 放哪里 | 为什么 |
|---|---|---|
| 项目用什么技术栈 | CLAUDE.md / Rules | 背景信息,始终需要 |
| 不要用 moment.js | CLAUDE.md / Rules | 始终需要知道的约定 |
| 怎么创建一个新页面 | Skills | 完整操作流程,按需触发 |
| 当前 bug 的报错信息 | Prompt / Context | 当次对话的动态信息 |
| 本地开发的测试账号 | CLAUDE.local.md | 个人信息,不提交 Git |
常见误区
▎误区 1:写得越多越好
不是!上下文窗口是有限的。CLAUDE.md 写 3000 行,AI 的有效注意力反而会被稀释。
建议控制在 200-500 行以内,聚焦最核心的信息。就像入职手册不会把公司所有制度都塞进去一样——新人第一天只需要知道最重要的事。
▎误区 2:只写一次就不管了
项目在演进,CLAUDE.md 也要跟着更新。技术栈升级了、规范变了、新的坑出现了,都应该同步更新。
一个好的实践是:在 code review 流程中,把 CLAUDE.md 的更新纳入检查项。
▎误区 3:把 Skills 该做的事塞进 CLAUDE.md
CLAUDE.md 适合放"背景信息和约定",不适合放"完整的操作流程"。如果你发现自己在 CLAUDE.md 里写了大段的"第一步做 xxx,第二步做 xxx",那这些内容应该拆成 Skills——按需加载,省上下文窗口。
一个判断标准:如果这条信息每次对话都需要 AI 知道,放 CLAUDE.md;如果只有特定任务才用到,做成 Skill。
总结
回到文章开头的问题——AI 不了解你项目的"潜规则"怎么办?
CLAUDE.md 就是答案。它不是什么高深的技术,本质上就是把你脑子里那些"大家都知道但没人写下来"的项目约定,变成 AI 能读到的文档。
核心要点:
- CLAUDE.md 是项目的入职手册,写清 WHAT(项目是什么)、HOW(怎么做)、WHY(为什么)
- 分层管理:全局 → 项目 → 个人 → 子目录,各管各的
- CLAUDE.md ≈ Rules ≈ Instructions,各工具叫法不同,本质是一回事;真正不同的是 Skills(按需触发的操作流程)和 Context(运行时的信息总和)
- 保持精简,200-500 行就够了,定期更新
当你把项目的"潜规则"都写进 CLAUDE.md,你会发现 AI 突然变得"懂事"了——它会用对技术栈、遵守规范、知道哪些坑不能踩。这不是 AI 变聪明了,而是它终于"看到"了你项目的全貌。
最后
欢迎扫码加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个有专业的技术人...


往期推荐
Multi-Agent Teams:让多个专家 Agent 像团队一样协作

AI Agent 是怎么"想一步做一步"的?拆解 ReAct 模式

从零开始:用 LangChain.js 构建你的第一个 Tool-Calling Agent

最后

点个在看支持我吧


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)