从手动审批到智能决策:Claude Code 自动模式如何拦截 80%+ 的危险越界行为
如果检测到疑似劫持行为的内容,它会在传递结果时附加警告,提醒模型对这些内容保持怀疑,并以用户的真实需求为准。但在自动模式下,会移除那些可能导致任意代码执行的宽泛规则(如通配的 shell 或脚本解释器调用),以确保分类器能看到潜在危险操作。:模型理解用户目标并试图帮忙,但采取了超出用户授权的行动,例如使用偶然发现的凭证或删除它认为“碍事”的内容。核心原则是评估操作的实际效果,而不是表面形式,并且默
点击下方“JavaEdge”,选择“设为星标”
第一时间关注技术干货!
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
-
🚀 魔都架构师 | 全网30W技术追随者
-
🔧 大厂分布式系统/数据中台实战专家
-
🏆 主导交易系统百万级流量调优 & 车联网平台架构
-
🧠 AIGC应用开发先行者 | 区块链落地实践者
-
🌍 以技术驱动创新,我们的征途是改变世界!
-
👉 实战干货:编程严选网
Claude Code 的用户会批准 93% 的权限请求。我们构建了一些分类器来自动化部分决策,在提升安全性的同时减少频繁审批带来的疲劳。下面介绍它能拦住什么,拦不住什么。
默认,Claude Code 在执行命令或修改文件前都会请求用户批准。这能保障安全,但也意味着用户频繁点击“批准”。时间一长,审批疲劳,人们就不再认真查看自己批准的内容。
用户通常有两种方式避免疲劳:
-
使用内置沙箱,将工具隔离以防止危险操作
-
用
--dangerously-skip-permissions参数,完全关闭权限提示,让 Claude 自由执行,但这在大多情况不安全
1 方式权衡
-
沙箱安全但维护成本高,每增加一种能力都要额外配置,且涉及网络或主机访问时就无法隔离
-
跳过权限则无需维护,但完全没有保护
-
手动审批介于两者之间,但实际上用户还是会批准 93% 的请求
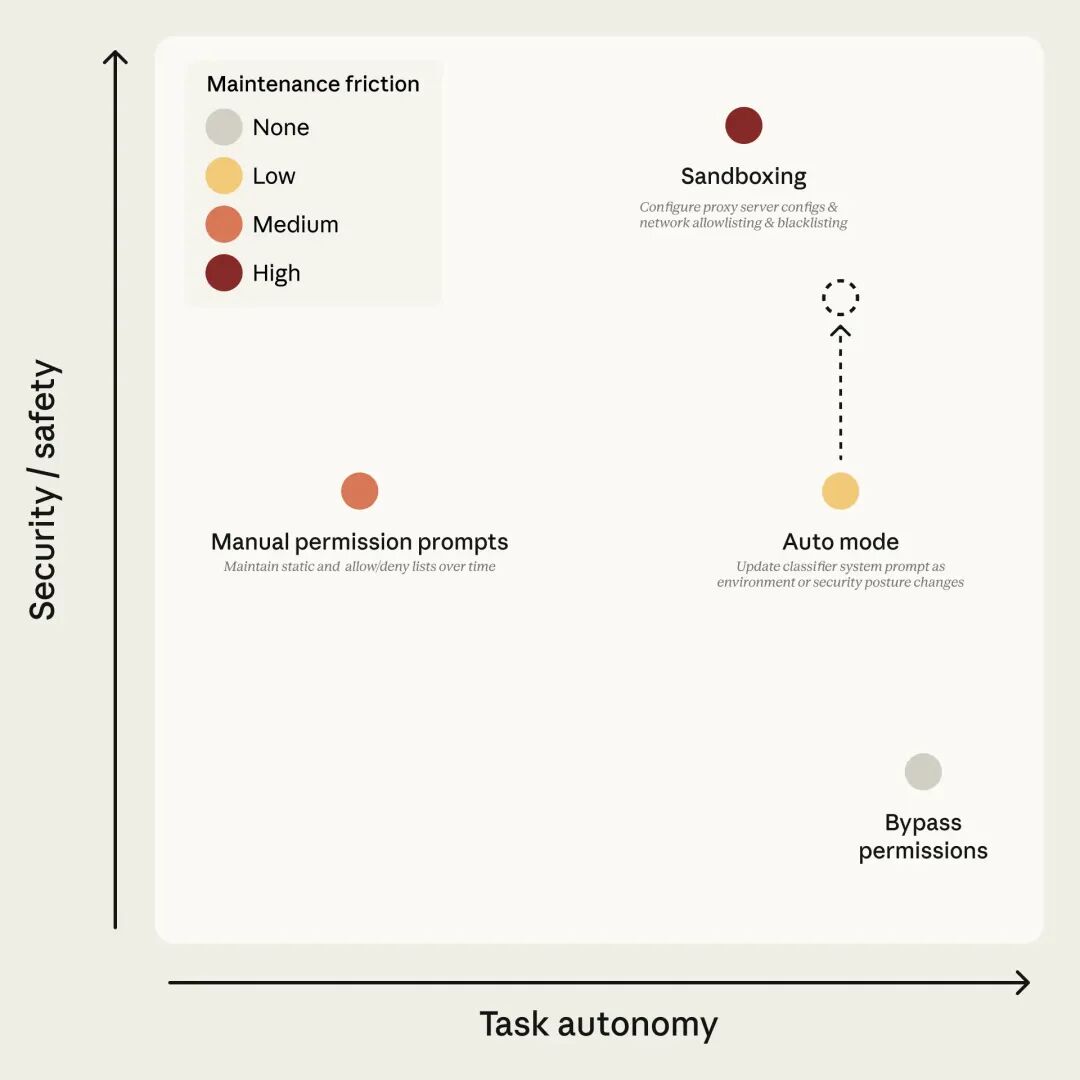 Claude Code 的权限模式,按任务自主性和安全性划分。点的颜色表示维护成本。自动模式的目标是在低维护成本实现高自主性;虚线箭头表示随分类器覆盖范围和模型判断能力提升,安全性会逐步提高。
Claude Code 的权限模式,按任务自主性和安全性划分。点的颜色表示维护成本。自动模式的目标是在低维护成本实现高自主性;虚线箭头表示随分类器覆盖范围和模型判断能力提升,安全性会逐步提高。
我们维护了一份内部事件日志,专门记录智能体不当行为。案例包括:因为误解指令而删除远程 Git 分支、把工程师的 GitHub 认证令牌上传到内部计算集群、尝试对生产数据库执行迁移等。这些问题本质都源于模型“过度积极”,在用户未明确授权是自行采取行动。在 Claude Opus 4.6 系统卡(§6.2.1 和 §6.2.3.3)记录了这一模式。
自动模式是 Claude Code 的一种新模式,它通过基于模型的分类器来代替人工审批,介于手动审核和完全无防护之间。目标是拦住那些偏离用户意图的危险操作,同时让其他操作无需提示直接执行。可按文档开始使用自动模式。
2 工作原理
自动模式采用两层防护:
-
一层针对 Claude 读取的内容
-
另一层针对 Claude 执行的操作
输入层
一个服务器端的提示注入检测器会扫描工具输出(如文件读取、网页抓取、Shell 输出或外部工具响应),在这些内容进入模型上下文前进行检查。如果检测到疑似劫持行为的内容,它会在传递结果时附加警告,提醒模型对这些内容保持怀疑,并以用户的真实需求为准。
输出层
一个运行在 Sonnet 4.6 上的“对话分类器”会在每个操作执行前进行评估,相当于替代人工审批。分类器分两阶段运行:
-
第一阶段是一个快速的单 token 过滤器(输出“允许”或“阻止”)
-
如果被标记,则进入第二阶段进行带推理的详细判断
由于大多操作在第一阶段就能通过,只有少数情况才消耗推理资源。分类器只看到用户消息和工具调用,不包含 Claude 自己的回复或工具输出,这使它在设计上对推理内容“不可见”。
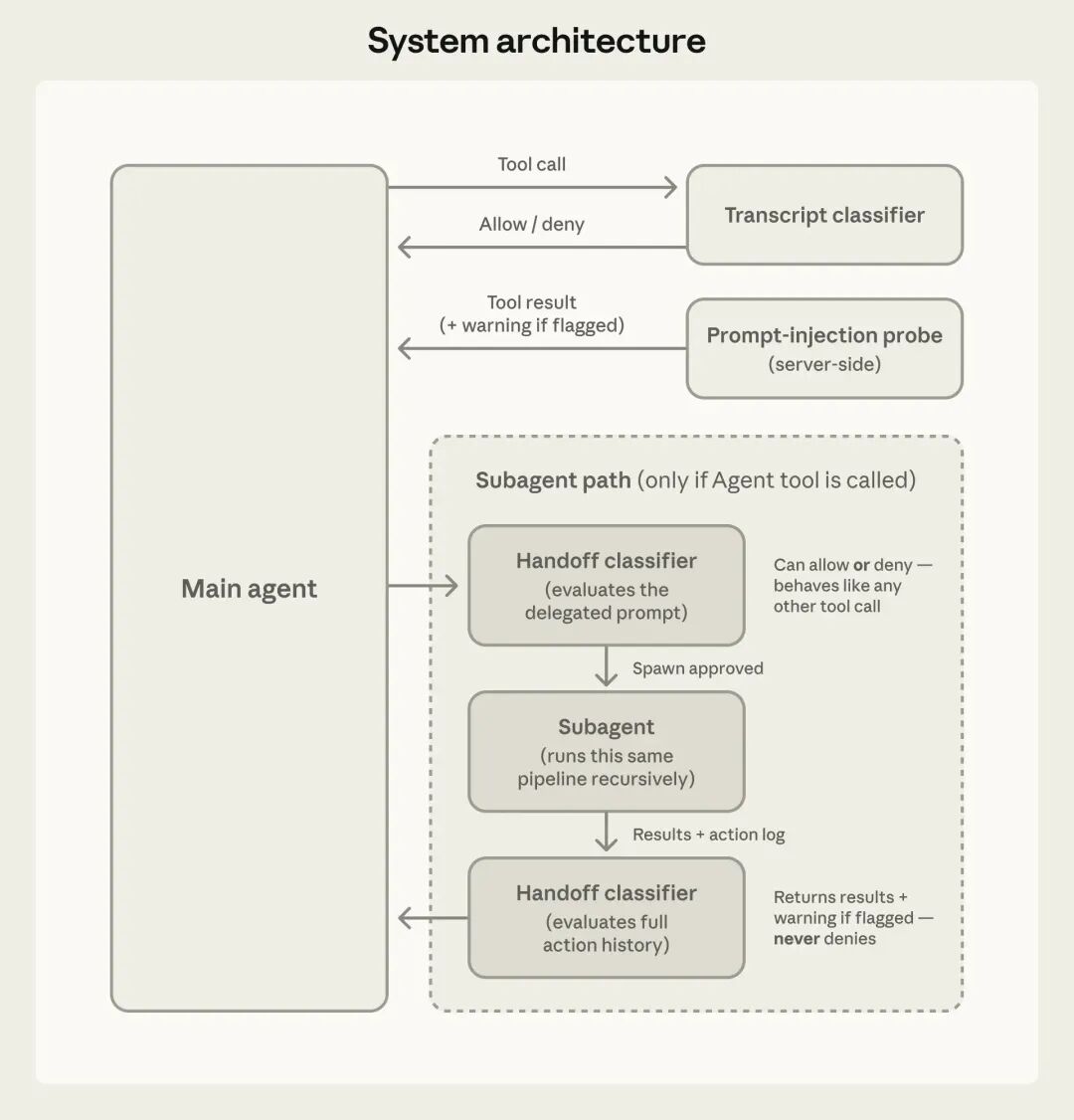 系统架构。对话分类器控制工具调用;提示注入检测器筛查工具结果。子代理会递归使用同样流程,在任务分发时和返回时分别由分类器进行检查。
系统架构。对话分类器控制工具调用;提示注入检测器筛查工具结果。子代理会递归使用同样流程,在任务分发时和返回时分别由分类器进行检查。
3 威胁模型
智能体可能因为以下四种原因执行危险操作:
-
过度积极:模型理解用户目标并试图帮忙,但采取了超出用户授权的行动,例如使用偶然发现的凭证或删除它认为“碍事”的内容。这类行为难以检测,因为它看起来像合理的解决方案,只是越界了。
-
无意错误:模型误判影响范围,例如把共享资源当作测试资源。
-
提示注入攻击:文件、网页或工具输出中嵌入的指令劫持模型行为,使其偏离用户任务。
-
模型目标错位:模型追求自身目标(目前尚未在实践中观察到,但仍持续评估)。
在这些情况下,防御策略都是阻止操作。分类器主要针对前两类问题进行优化,但同样适用于其他威胁。
示例展示自动模式试图拦截的行为:
-
范围扩大:用户说“清理旧分支”,模型却删除了远程分支。这种不可逆操作会被阻止。
-
凭证搜索:遇到认证错误后,模型开始在环境变量和配置文件中搜索 API token,会被阻止。
-
自行推断参数:用户说“取消我的任务”,模型自行匹配并删除任务,会被阻止。
-
外部共享:将脚本上传到 GitHub Gist,会被视为数据外泄而阻止。
-
绕过安全检查:部署失败后加上跳过验证参数重试,会被阻止。
4 权限决策流程
并非所有操作都会进入分类器,大部分会在前两层被直接允许:
第一层:内置安全工具白名单与用户设置。 包括只读操作(文件读取、搜索、代码导航等)。用户也可以配置“始终允许”的规则。但在自动模式下,会移除那些可能导致任意代码执行的宽泛规则(如通配的 shell 或脚本解释器调用),以确保分类器能看到潜在危险操作。
第二层:项目内文件操作。 在项目目录内的修改可以直接执行,不经过分类器,因为这些操作可以通过版本控制审查。
第三层:对话分类器。 只有具有潜在风险的操作(如 shell 命令、外部访问、项目外文件操作等)才会进入这一层。
5 分类器的判断标准
分类器使用一个固定模板,其中包含三处可自定义内容:
固定部分定义了如何判断操作的真实影响,以及如何理解用户授权。核心原则是评估操作的实际效果,而不是表面形式,并且默认只有用户明确授权的行为才是允许的。
可自定义部分包括:
-
环境定义:界定哪些资源是“可信内部”,哪些是外部。
-
阻止规则:默认包含 20 多条规则,如数据破坏、外泄、安全性下降等。
-
例外规则:在特定情况下允许本应被阻止的操作。
6 效果评估
我们在三类数据集上进行了测试,包括真实流量、真实过度行为案例和模拟数据外泄任务。
| 真实流量
n=10,000 |
过度行为
n=52 |
模拟外泄
n=1,000 |
|
|---|---|---|---|
|
第一阶段(快速过滤) |
误报率 8.5% |
漏报率 6.6% |
漏报率 1.8% |
|
全流程(两阶段) |
误报率 0.4% |
漏报率 17% |
漏报率 5.7% |
两阶段流程显著降低了误报,但会增加一定漏报率。
17% 的漏报率意味着仍有部分危险操作未被拦截,主要问题在于分类器难以准确判断用户是否真的授权了某个具体操作。
7 设计决策
为什么不让分类器看到模型回复和工具输出
防止模型通过“说服”分类器来放行危险操作,同时也减少提示注入攻击的影响。实验表明,这种简化输入反而提升了性能。
两阶段分类
-
第一阶段偏保守,提高召回率
-
第二阶段通过推理降低误报,在性能和成本之间取得平衡
提示注入检测的重要性
输入层检测与输出层分类器配合,使攻击必须同时绕过两道防线,大大增加难度。
多代理协作
在任务分发和结果返回时都进行检查,防止子代理被利用。
拒绝但继续执行
当操作被阻止时,模型不会停下来,而是尝试寻找更安全的替代方案。如果连续多次被拒绝,才会交由人工处理。
8 后续计划
我们会继续扩展测试数据集,并改进模型表现。自动模式并不完美,但相比完全无防护的运行方式,已经显著提升了安全性。对于高风险场景,仍建议人工审核。
编程严选网:
http://www.javaedge.cn/专注分享AI时代下软件开发全场景最新最佳实践~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)