ClaudeCode源码泄露,我解除了限制
一、前言
2026年3月31日,发现
Anthropic的Claude Code CLI工具通过source map文件暴露了完整源代码。这一发现迅速引发技术社区关注。
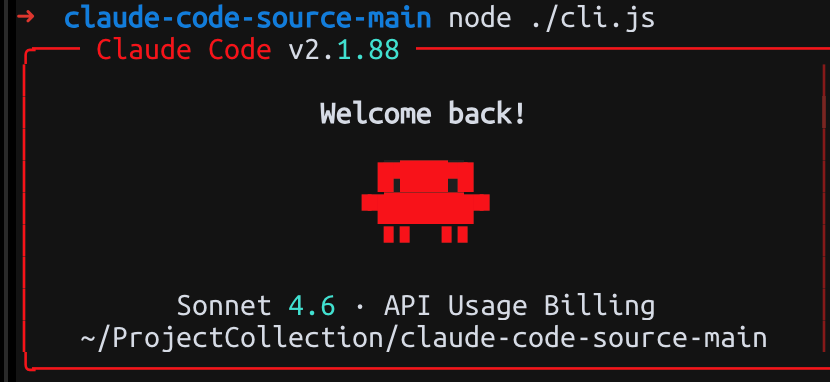
本次泄露的核心价值不在于代码本身,
Claude Code作为客户端工具,其大部分逻辑本就可通过反编译获取,而在于它完整暴露了Anthropic的安全控制架构、提示词工程策略以及权限边界设计。对于安全研究人员而言,这是一份难得一见的商业级AI Agent安全实现参考样本。
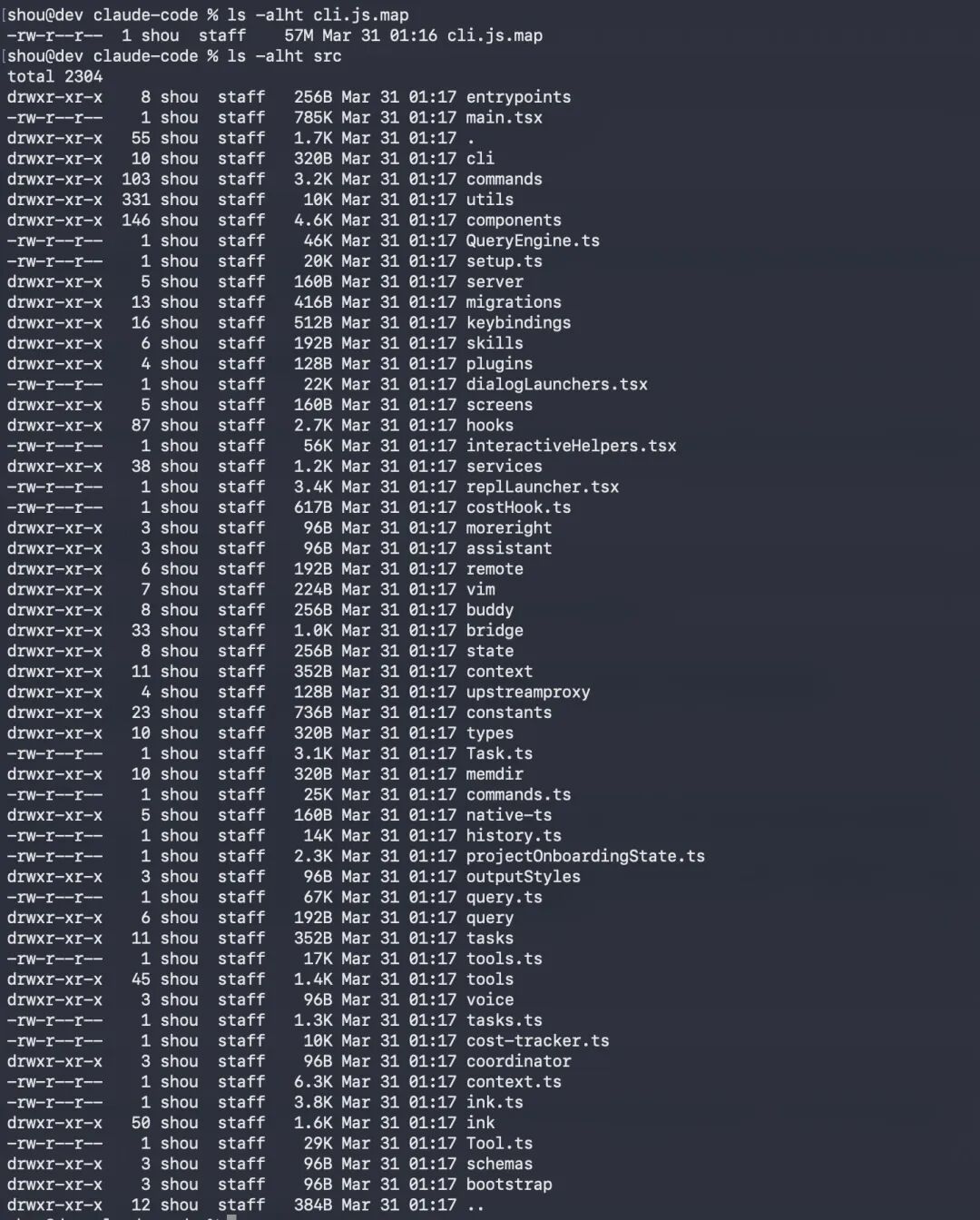
二、源码恢复工程的技术路径
泄露的源码并非原始开发仓库,而是基于已发布包中的cli.js与cli.js.map进行反推恢复。这种恢复方式在技术上具有以下特点:
2.1 恢复方法
ounter(line原始产物 → Source Map解析 → TypeScript源码重构 → 工程化还原-
构建工具:esbuild重新打包,替代官方原始构建链
-
运行时环境:Bun(非Node.js)
-
UI框架:React + Ink(终端渲染框架)
-
架构模式:模块化工具架构,支持懒加载与动态发现
2.2 工程结构
恢复后的代码库呈现典型的分层架构:
|
层级 |
核心模块 |
功能定位 |
|---|---|---|
|
入口层 |
src/entrypoints/
, |
启动分流、全局状态初始化 |
|
交互层 |
src/components/
, |
终端UI渲染、事件处理 |
|
业务层 |
src/services/
, |
API调用、工具实现、任务执行 |
|
基础设施 |
src/utils/
, |
配置管理、权限控制、状态容器 |
三、安全限制机制解构
3.1 提示词级安全边界
泄露代码中最受关注的安全控制点位于src/constants/cyberRiskInstruction.ts。该文件定义了一个系统级指令常量,被注入到所有对话模式的系统提示词中。
原始指令内容(泄露版本):
ounter(lineexport const CYBER_RISK_INSTRUCTION = `IMPORTANT: Assist with authorized security testing, defensive security, CTF challenges, and educational contexts. Refuse requests for destructive techniques, DoS attacks, mass targeting, supply chain compromise, or detection evasion for malicious purposes. Dual-use security tools (C2 frameworks, credential testing, exploit development) require clear authorization context: pentesting engagements, CTF competitions, security research, or defensive use cases.`该指令在src/constants/prompts.ts中被注入到两个关键位置:
-
普通模式:
getSimpleIntroSection()函数(第182行) -
自主代理模式:Proactive模块的系统提示词模板(第474行)
3.2 安全策略的层级设计
Claude Code的安全架构并非单一依赖提示词控制,而是采用多层防御:
┌─────────────────────────────────────────────────────────────┐│ Layer 1: 系统提示词控制 (System Prompt) ││ - CYBER_RISK_INSTRUCTION (网络安全限制) ││ - URL生成限制、提示词注入检测、OWASP防护 │├─────────────────────────────────────────────────────────────┤│ Layer 2: 权限系统 (Permission System) ││ - 危险命令模式匹配 ││ - 权限检查流程 ││ - 自动模式分类器 (yoloClassifier) │├─────────────────────────────────────────────────────────────┤│ Layer 3: 工具级安全检查 (Tool-Level Security) ││ - PowerShell AST安全分析 ││ - Bash破坏性命令警告 ││ - 沙箱文件系统隔离 │├─────────────────────────────────────────────────────────────┤│ Layer 4: 输入清理 (Input Sanitization) ││ - Unicode隐藏字符攻击防护 │└─────────────────────────────────────────────────────────────┘3.3 权限系统的实现细节
权限控制核心位于src/utils/permissions/目录:
|
模块 |
功能 |
|---|---|
dangerousPatterns.ts |
定义危险命令的正则匹配模式 |
permissions.ts |
权限检查主流程 |
yoloClassifier.ts |
自动模式ML分类器 |
权限级别枚举:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineenum PermissionLevel { ALWAYS_ALLOW = "always_allow", // 持久化授权 ALLOW_ONCE = "allow_once", // 单次授权 DENY = "deny", // 拒绝 ASK = "ask" // 需要用户确认(默认)}四、安全限制移除的技术分析
GitHub仓库Ta0ing/claude-code_evil展示了如何通过最小化修改绕过提示词级安全控制。
项目地址:https://github.com/Ta0ing/claude-code_evil
4.1 修改点
文件:src/constants/cyberRiskInstruction.ts
修改前:
ounter(lineexport const CYBER_RISK_INSTRUCTION = `IMPORTANT: Assist with authorized security testing...`修改后:
ounter(lineexport const CYBER_RISK_INSTRUCTION = ``4.2 移除限制
修改仅移除了提示词层面的安全边界,其他安全机制仍然生效:
|
安全机制 |
状态 |
说明 |
|---|---|---|
|
URL生成限制 |
✅ 生效 |
prompts.ts
第183行 |
|
提示词注入检测 |
✅ 生效 |
prompts.ts
第191行 |
|
OWASP安全漏洞防护 |
✅ 生效 |
prompts.ts
第234行 |
|
敏感操作确认 |
✅ 生效 |
prompts.ts
第255-266行 |
|
危险命令模式匹配 |
✅ 生效 |
dangerousPatterns.ts |
|
Bash/PowerShell安全分析 |
✅ 生效 |
工具级检查 |
|
沙箱隔离 |
✅ 生效 |
sandbox-adapter.ts |
扫码进入AI交流群


— 关于我们 —
镇江刺掌信息科技有限公司成立于2020年,公司旗下MS08067安全实验室,专注于网络安全领域教育、培训、认证产品及服务提供商。近两年,线上培训人数近10万人次,培养网络安全人才近6000名。
公司被认定为国家高新技术企业、国家科技型中小企业、江苏省创新性中小企业、江苏省民营科技企业、江苏省软件企业。并荣获机械工业出版社“年度最佳合作伙伴”、电子工业出版社-博文视点“优秀合作伙伴”、镇江市企业发展服务中心优质合作伙伴、镇江市网络安全应急支撑服务单位等荣誉称号。

如果喜欢我们
欢迎 在看丨留言丨分享至朋友圈 三连

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)