Claude Code 源码泄露,真正值得看的不是“热闹”,而是它为什么这么好用
不是因为它背后只有一个更大的模型,而是因为有人认真搭好了提示词、工具、安全、记忆、上下文这些看起来不那么“性感”,却真正决定体验的基础设施。你可以把大模型想象成一匹很强的野马,它冲得很快,也很有爆发力,但问题是它并不天然稳定,也不天然可控。我们平时总在讨论“哪个模型更强”“哪个 agent 更聪明”,但真正把产品体验拉开差距的,往往不只是模型本身,而是模型外面那一整套工程系统。我很喜欢这种设计,因
前几天看到一则很有戏剧性的消息:围绕 Claude Code 的一次源码泄露,让外界一下子看到了一个顶级 AI 编程工具背后的工程细节。表面上,这像是又一次典型的“发布失误”事件;但如果只把它当成八卦来看,其实有点可惜。
对开发者来说,这次事件更像是一堂难得的公开课。我们平时总在讨论“哪个模型更强”“哪个 agent 更聪明”,但真正把产品体验拉开差距的,往往不只是模型本身,而是模型外面那一整套工程系统。
换句话说,这次最值得看的,不是泄露了多少文件、多少行代码,而是一个问题:Claude Code 为什么会这么好用?
一、真正决定上限的,不只是模型
如果要用一句话概括我看完文稿后的最大感受,那就是:
Claude Code 的强,可能只有一部分来自模型,另一大部分来自工程化。
视频里提到一个词,我觉得特别准确,叫 harness engineering。这个词不好直译,但意思很好懂。你可以把大模型想象成一匹很强的野马,它冲得很快,也很有爆发力,但问题是它并不天然稳定,也不天然可控。你不能只因为马很强,就默认它一定能把你安全、稳定地送到终点。
所以你需要缰绳,需要马鞍,需要方向控制系统,需要护栏,也需要规则。放到 AI 产品里,这些东西就是:
-
提示词系统
-
工具调用机制
-
权限控制
-
安全策略
-
记忆系统
-
上下文压缩
-
项目状态感知
很多人以为 AI 编程工具的竞争,本质是“谁的模型更大”。但从这次文稿里能明显感觉到,真正成熟的产品早就不只是在拼模型了,而是在拼谁更懂得把模型“驯化”为一个可靠的工程协作者。
二、提示词不是一段话,而是一整套运行时系统
很多人对系统提示词的理解,还停留在“写一段像咒语一样的提示词,模型就会变聪明”。但从文稿描述来看,Claude Code 背后的提示词系统更像一个动态装配系统,而不是一段固定文本。
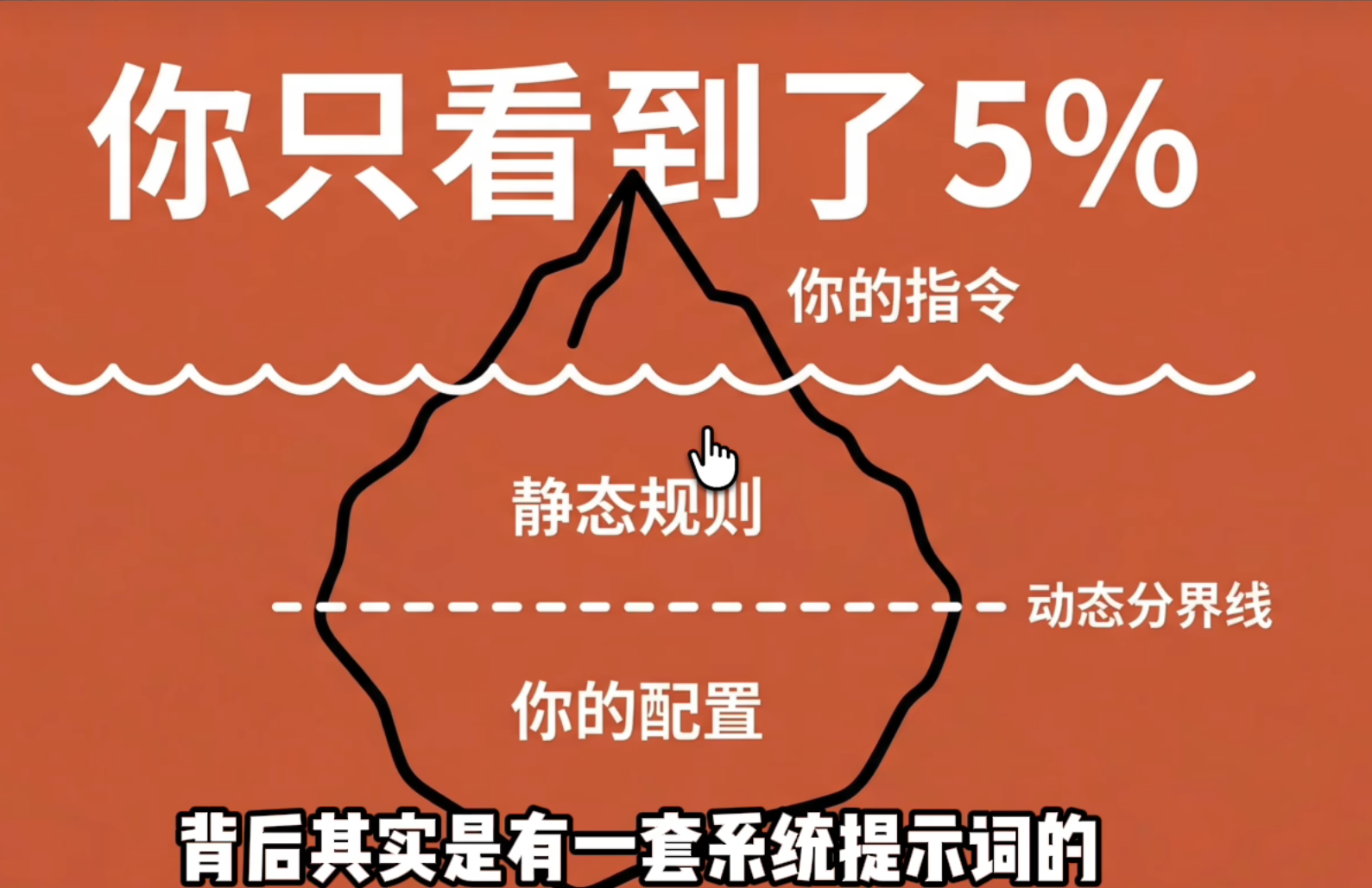
这里面至少有两层东西:
-
一层是所有用户共享的静态规则,比如不要编造、不要乱删文件、优先用合适的工具、不要过度工程化。
-
另一层是根据当前用户、当前项目、当前环境动态注入的信息,比如项目里的
CLAUDE.md、连接的 MCP 工具、用户偏好、仓库状态等。
我觉得这里最有意思的,不是“规则很多”,而是它把静态和动态分开了。视频里提到一个词叫 dynamic boundaries,本质上是在工程上划了一条边界:

-
不变的部分尽量共享缓存,节省成本、提升速度。
-
变化的部分按用户和项目单独加载,保证个性化。
这其实是一个特别典型、也特别高级的工程思路。很多系统做不稳,不是因为没有规则,而是把所有东西都混在一起。结果就是缓存失效、上下文臃肿、定制化困难、成本越来越高。
所以第一点启发很明确:好的 Agent 提示词,从来不是“写得像不像大师”,而是“有没有被做成系统”。
三、工具不是越多越强,MCP 也有真实成本
现在谈 AI Agent,大家很容易陷入一个思路:工具越多越强,连接越全越高级。但视频里提到的一个细节让我印象很深,就是 MCP 的上下文成本。(每个工具的定义都会消耗4000到6000个tokens,MCP的描绘文件可能就占了上下文的12%,很多人用skill来替代)
每接入一个工具,不只是“多了一个能力”,也意味着:
-
要给模型解释这个工具是什么
-
要告诉模型怎么调用
-
要把工具的接口描述带进上下文
这些都要消耗 token。
如果你只从功能表来看,当然会觉得“工具越全越好”;但如果你从上下文预算来看,情况就完全不同了。工具多了,模型可用于真正思考和执行任务的上下文反而变少了。
这给我的第二个启发是:Agent 的工具设计,本质上也是资源管理问题。
你不是在拼“我能接多少个工具”,而是在拼:
-
哪些工具值得放进默认链路
-
哪些工具应该延迟加载
-
哪些工具虽然有用,但不值得长期占用上下文
这也是为什么顶级产品往往看起来没有那么“炫技”。它们不是不会堆,而是知道什么时候该克制。
四、自动模式真正可用,前提是它背后有第二层安全大脑
很多人对 AI 自动执行最大的担心,不是它“不够聪明”,而是它“太敢动手”。
比如:
-
它会不会误删文件
-
会不会跑危险命令
-
会不会在我没注意的时候把项目改坏
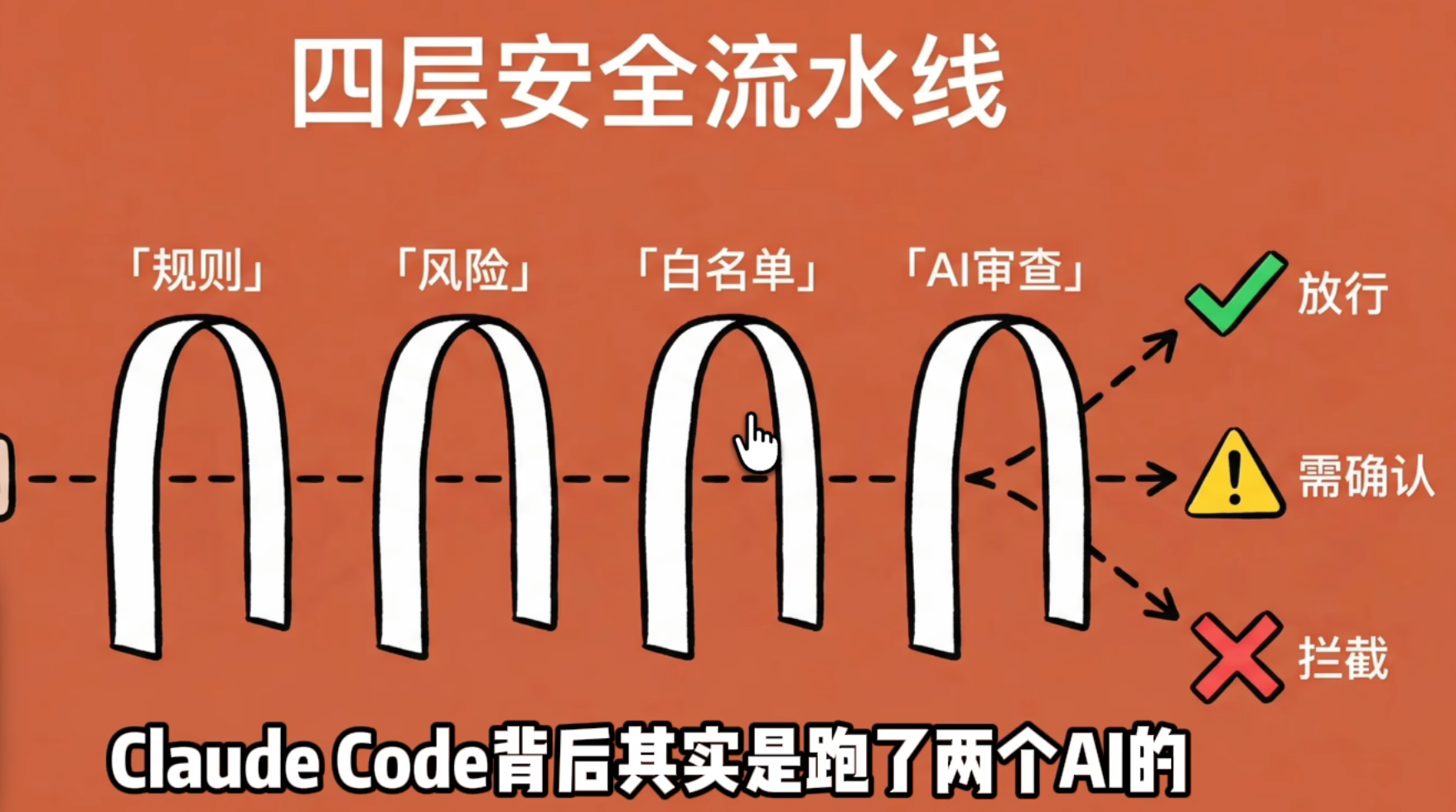
而文稿里提到的一个设计非常关键:Claude Code 的自动模式背后,似乎并不是单一模型直接拍板,而是还有一个独立的安全分类器,专门判断某个动作能不能执行。
有一个yoloClassifier这个文件,专门做安全审查的, 有自己的提示词。这很像给主 agent 再加一层“安保系统”。
主模型负责做事,但不是它想做什么就做什么。每当它准备执行命令、修改文件或做高风险操作时,还会有另一个机制去判断:
-
这是否可以直接放行
-
这是否需要用户确认
-
这是否应该被硬性拦截
我很喜欢这种设计,因为它说明一个成熟的 agent 产品,核心不是“让 AI 尽可能自由”,而是“让 AI 在可控边界内自由”。
这两者的差别非常大。
前者容易制造惊艳时刻,也容易制造事故。后者看起来没那么激进,但更适合真正长期协作。对绝大多数开发者来说,后者显然更重要。
五、记忆系统最聪明的地方,是它不记代码
文稿里还有一个我特别认同的观点:长期记忆最应该记住的,不是代码,而是人。
这句话听起来有点反直觉,因为大家总以为“记忆”就是要记住更多事实。但代码这种东西变化太快了,今天还在第 30 行的函数,明天可能就被重构、拆分或者删除了。如果系统把这种信息当成长期记忆保存下来,过几天它就会从“知识”变成“误导”。
所以更合理的设计反而是:
-
记住用户偏好
-
记住沟通风格
-
记住项目约定
-
记住外部资源和长期稳定的信息
至于具体代码长什么样、某个函数现在在哪、某个实现是否已改动,这些都应该每次从真实代码里重新读取。
这背后其实体现了一种很成熟的系统观:
-
变化快的事实,不做长期缓存
-
稳定的人类偏好,才值得沉淀成长期记忆
这不仅适用于 AI 编程工具,几乎适用于所有带长期记忆能力的 Agent 产品。

六、真正的高手,未必迷信复杂 RAG
现在一谈 AI 工具,很多人就会往 RAG、向量数据库、Embedding 这些方向想,仿佛系统越复杂就越先进。但视频里提到一个相当“反常识”的点:像 Claude Code 这样的顶级 AI 编程工具,在代码检索上未必高度依赖复杂 RAG,它可能更多依赖朴素的文本搜索。

这其实一点也不奇怪。
代码本身就是高度结构化、可搜索、可验证的文本。很多时候,你真正需要的不是“语义上大概相近的段落”,而是快速、准确地把相关文件和符号定位出来。这个时候,简单直接的搜索反而更稳定、更便宜,也更容易被模型接管。
所以这里的关键不是“高级技术名词有没有上”,而是整个链路是否足够有效。
这也是这次文稿给我的另一个提醒:很多时候,系统做复杂了,并不意味着它更强;有时只是意味着它更难维护。
七、这次事件真正暴露出来的,是 AI 编程赛道的竞争逻辑变了
如果把视角再拉高一点,这次事件最有价值的地方,可能是它让更多人第一次比较具体地看到:一个顶级 AI 编程产品,原来是这样被搭出来的。

这意味着什么?
意味着接下来行业竞争的重点,可能不再只是:
-
谁先发了一个更强的模型
-
谁先把“自动写代码”做成演示视频
而是:
-
谁能把模型、工具、安全、记忆、上下文管理整合成稳定系统
-
谁能让 Agent 不只是“能回答”,而是真的“能交付”
这其实会把很多团队重新拉回同一起跑线。因为模型有门槛,但工程方法同样可以学习、吸收、模仿、迭代。真正的壁垒,最后往往来自持续构建能力,而不是一次性的灵感。
八、写在最后
如果只把这次源码泄露当成一个吃瓜事件,那它很快就会过去。但如果把它当成一个产品解剖样本来看,它的价值就完全不同了。
它让我们更清楚地看到,一款优秀的 AI 编程工具为什么优秀。不是因为它背后只有一个更大的模型,而是因为有人认真搭好了提示词、工具、安全、记忆、上下文这些看起来不那么“性感”,却真正决定体验的基础设施。
说到底,AI 编程工具的未来,拼的不是谁更会表演“魔法”,而是谁更会做工程。
而从这个角度看,这次事件真正泄露出来的,可能不只是代码本身,而是下一代 Agent 产品的设计思路。
文稿来自B站AI进化论-花生

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)