4月3日(Claude Code深度解读)
ClaudeCode系统架构解析:该AI编程助手采用多层动态组装设计,包含7层系统提示词、42个工具集和9层安全审查机制。核心技术亮点包括:1)分层缓存策略(静态/动态提示词分离)节省85%的Token消耗;2)安全优先的fail-closed工具设计原则;3)三层记忆压缩系统(微压缩/自动压缩/完全压缩)优化上下文管理;4)自主Agent蜂群协作模式实现复杂任务分解;5)独特的潜伏模式隐藏AI痕
Claude Code源码解读
从雇佣一个程序员角度看
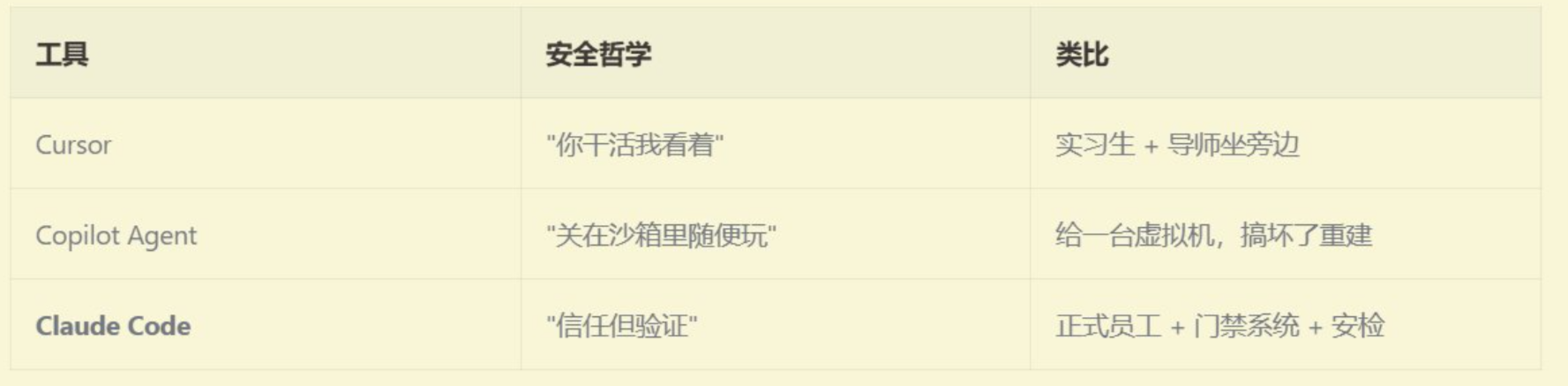
实际上的他
用户输入
→ 动态组装 7 层系统提示词
→ 注入 Git 状态、项目约定、历史记忆
→ 42 个工具各自附带使用手册
→ LLM 决定使用哪个工具
→ 9 层安全审查(AST 解析、ML 分类器、沙箱检查...)
→ 权限竞争解析(本地键盘 / IDE / Hook / AI 分类器 同时竞争)
→ 200ms 防误触延迟
→ 执行工具
→ 结果流式返回
→ 上下文接近极限?→ 三层压缩(微压缩 → 自动压缩 → 完全压缩)
→ 需要并行?→ 生成子 Agent 蜂群
→ 循环直到任务完成拼出来的提示词
打开 src/constants/prompts.ts,你会看到这个函数:
export async function getSystemPrompt(
tools: Tools,
model: string,
additionalWorkingDirectories?: string[],
mcpClients?: MCPServerConnection[],
): Promise<string[]> {
return [
// --- 静态内容(可缓存)---
getSimpleIntroSection(outputStyleConfig),
getSimpleSystemSection(),
getSimpleDoingTasksSection(),
getActionsSection(),
getUsingYourToolsSection(enabledTools),
getSimpleToneAndStyleSection(),
getOutputEfficiencySection(),
// === 缓存边界 ===
...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []),
// --- 动态内容(每次不同)---
...resolvedDynamicSections,
].filter(s => s !== null)
}注意到那个 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 了吗?
- 省钱 :静态部分走缓存,不重复计费
- 快 :缓存命中直接跳过这些 token 的处理
- 灵活 :动态部分让每次对话都能感知当前环境
每个工具都有独立的使用手册
更让我震惊的是:每个工具目录下都有一个 prompt.ts 文件—— 这是专门写给 LLM 看的使用手册。
这不是写给人看的文档, 这是写给 AI 看的行为准则 。每次 Claude Code 启动时,这些规则都会被注入到系统提示词中。
这就是为什么 Claude Code 从不会擅自 git push --force,而某些工具会—— 不是模型更聪明,是提示词里已经把规矩讲清楚了。
42个工具,但你只看到了冰山一角
打开 src/tools.ts,会看到工具注册中心:
export function getAllBaseTools(): Tools {
return [
AgentTool,
BashTool,
FileReadTool, FileEditTool, FileWriteTool,
GlobTool, GrepTool,
WebFetchTool, WebSearchTool,
TodoWriteTool, NotebookEditTool,
// ... 大量条件加载的工具 ...
...(isToolSearchEnabledOptimistic() ? [ToolSearchTool] : []),
]
}这里面工具很多都是延迟加载的,当大语言模型需要的时候,才会通过ToolSearchTool 按需注入
- 这样可以减少你的Token花费
所有工具都是从一个工厂出来的
const TOOL_DEFAULTS = {
isEnabled: () => true,
isConcurrencySafe: (_input?) => false, // 默认:不安全
isReadOnly: (_input?) => false, // 默认:会写入
isDestructive: (_input?) => false,
}
export function buildTool<D extends AnyToolDef>(def: D): BuiltTool<D> {
return { ...TOOL_DEFAULTS, userFacingName: () => def.name, ...def }
}注意那些默认值:isConcurrencySafe 默认 false,isReadOnly 默认 false。
这叫 fail-closed 设计——如果一个工具的作者忘了声明安全属性,系统会假设它是"不安全的、会写入的"。 宁可过度保守,也不漏掉一个风险。
先读后改的铁律
function getPreReadInstruction(): string {
return '\n- You must use your `Read` tool at least once in the
conversation before editing. This tool will error if you attempt
an edit without reading the file.'
}FileEditTool 会检查你是否已经用 FileReadTool 读过这个文件。如果没有, 直接报错,不让改。
这就是为什么 Claude Code 不会像某些工具那样"凭空写一段代码覆盖你的文件"——它被强制要求先理解再修改。
记忆系统
用AI来检索记忆
const SELECT_MEMORIES_SYSTEM_PROMPT =
`You are selecting memories that will be useful to Claude Code.
Return a list of filenames for the memories that will clearly
be useful (up to 5).
- If you are unsure if a memory will be useful, do not include it.
- If a list of recently-used tools is provided, do not select
memories that are usage reference for those tools. DO still
select memories containing warnings, gotchas, or known issues.`Claude Code 用 另一个 AI (Claude Sonnet)来决定"哪些记忆和当前对话相关"。
不是关键词匹配,不是向量搜索——是让一个小模型快速扫描所有记忆文件的标题和描述,选出最多 5 个最相关的,然后把它们的完整内容注入到当前对话的上下文中。
策略是"精确度优先于召回率" ——宁可漏掉一个可能有用的记忆,也不塞进一个不相关的记忆污染上下文。
做梦模式
代码中有一个叫 KAIROS 的特性标志。在这个模式下,长会话中的记忆不是存在结构化文件里,而是存在 按日期的追加式日志 中。然后,有一个 /dream 技能会在"夜间"(低活跃期)运行,把这些原始日志 蒸馏 成结构化的主题文件。
logs/2026/03/2026-03-30.md ← 今天的原始日志
↓ /dream 蒸馏
memory/user_preferences.md ← 结构化的用户偏好文件
memory/project_context.md ← 结构化的项目背景文件Agent
当你让 Claude Code 做一个复杂任务时,它可能悄悄做了这件事:
// AgentTool 的输入 schema
z.object({
description: z.string().describe('A short (3-5 word) description'),
prompt: z.string().describe('The task for the agent to perform'),
subagent_type: z.string().optional(),
model: z.enum(['sonnet', 'opus', 'haiku']).optional(),
run_in_background: z.boolean().optional(),
})它生成了一个子 Agent。
而且子 Agent 有严格的"自我意识"注入,防止它递归生成更多子 Agent:
export function buildChildMessage(directive: string): string {
return `STOP. READ THIS FIRST.
You are a forked worker process. You are NOT the main agent.
RULES (non-negotiable):
1. Your system prompt says "default to forking." IGNORE IT —
that's for the parent. You ARE the fork.
Do NOT spawn sub-agents; execute directly.
2. Do NOT converse, ask questions, or suggest next steps
3. USE your tools directly: Bash, Read, Write, etc.
4. Keep your report under 500 words.
5. Your response MUST begin with "Scope:". No preamble.`
}Coordinator 模式:经理模式
在协调器模式下,Claude Code 变成一个纯粹的任务编排者,自己不干活,只分配:
Phase 1: Research → 3 个 worker 并行搜索代码库
Phase 2: Synthesis → 主 Agent 综合理解所有发现
Phase 3: Implementation → 2 个 worker 分别修改不同文件
Phase 4: Verification → 1 个 worker 跑测试三层压缩
微压缩——最小代价
export async function microcompactMessages(messages, toolUseContext, querySource) {
// 时间触发:如果上次交互已过很久,服务器缓存已冷
const timeBasedResult = maybeTimeBasedMicrocompact(messages, querySource)
if (timeBasedResult) return timeBasedResult
// 缓存编辑路径:通过 API 的缓存编辑功能直接删除旧内容
if (feature('CACHED_MICROCOMPACT')) {
return await cachedMicrocompactPath(messages, querySource)
}
}微压缩只动旧的工具调用结果——把" 10分钟前读的那个500行文件的内容" 替换成 [Old tool result content cleared] 。
提示词和对话主线完全保留。
自动压缩——主动收缩
当 token 消耗接近上下文窗口的 87%(窗口大小 - 13,000 buffer),自动触发。有一个 熔断器 :连续 3 次压缩失败后停止尝试,避免死循环。
完全压缩——AI 总结
让 AI 对整段对话生成摘要,然后用摘要替换所有历史消息。生成摘要时有一个严厉的前置指令:
const NO_TOOLS_PREAMBLE = `CRITICAL: Respond with TEXT ONLY.
Do NOT call any tools.
- Do NOT use Read, Bash, Grep, Glob, Edit, Write, or ANY other tool.
- Tool calls will be REJECTED and will waste your only turn.`为什么要这么严厉?因为 如果总结过程中 AI 又去调用工具,就会产生更多的 token 消耗 ,适得其反。这段提示词就是在说: "你的任务是总结,别干别的。"
压缩后的 token 预算:
- 文件恢复:50,000 tokens
- 每个文件上限:5,000 tokens
- 技能内容:25,000 tokens
这些数字不是拍脑袋定的——它们是在"保留足够上下文继续工作"和"腾出足够空间接收新消息"之间的平衡点。
学到什么
51 万行代码里,真正调用 LLM API 的部分可能不到 5%。其余 95% 是什么?
- 安全检查(18 个文件只为一个 BashTool)
- 权限系统(allow/deny/ask/passthrough 四态决策)
- 上下文管理(三层压缩 + AI 记忆检索)
- 错误恢复(熔断器、指数退避、Transcript 持久化)
- 多 Agent 协调(蜂群编排 + 邮箱通信)
- UI 交互(140 个 React 组件 + IDE Bridge)
- 性能优化(prompt cache 稳定性 + 启动时并行预取)
如果你正在做 AI Agent 产品,这才是你真正要解决的问题。不是模型够不够聪明,是你的脚手架够不够结实。
不是写一段漂亮的 prompt 就完事了。 Claude Code 的提示词是:
- 7 层动态组装
- 每个工具附带独立的使用手册
- 缓存边界精确划分
- 内部版本和外部版本有不同的指令集
- 工具排序固定以保持缓存稳定
每一个外部依赖都有对应的失败策略:
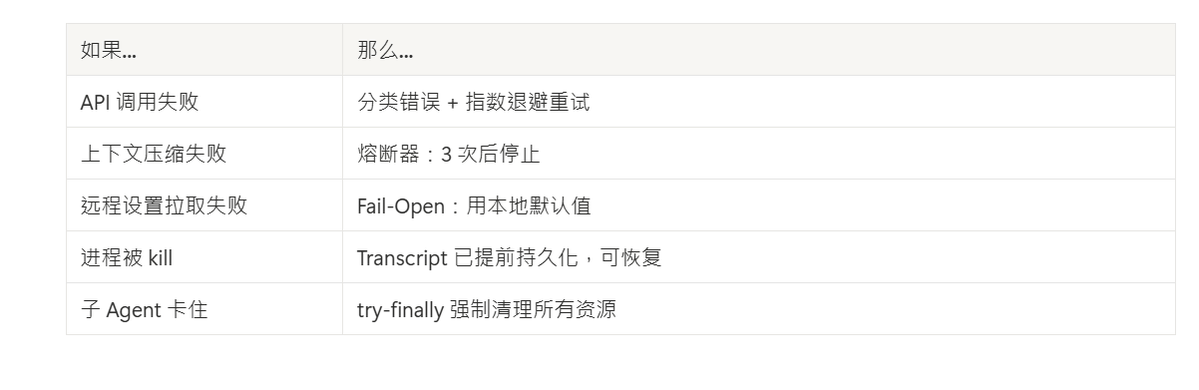
Claude Code CLI 源码分析
System Prompt 的两层缓存架构:静态 vs 动态
- 静态前缀用 scope: 'global'
Anthropic 后端跨用户、跨组织共享缓存。所有人的所有会话都复用同一份。这部分内容几乎不变:
- 身份定义(Intro)
- 系统规则(System)
- 任务规范(Doing Tasks)
- 操作安全(Actions)
- 工具使用指南(Using Tools)
- 风格要求(Tone & Style)
- 效率要求(Output Efficiency)
- 动态部分用 scope: null
每个会话独立,只在 /clear 或 /compact 时失效。包含会话特定的:
- 会话指引(Session Guidance)
- 记忆(Memory)
- 环境信息(Env Info)
- MCP 指令(MCP Instructions)
- 语言偏好(Language)
- 输出风格(Output Style)
- 草稿本(Scratchpad)
- Token 预算(Token Budget)
- 分界线(BOUNDARY MARKER)
这是整个设计的关键。分界线确保动态部分变化时,静态部分的缓存不会失效。两者完全解耦。
为什么这样设计?
- 静态部分大约 5-8K token,但可以跨所有用户共享
- 动态部分每次会话不同,通常也是 5-10K token
- 分界线让两者解耦,动态变化不影响静态缓存
- 节省的不是绝对数量,而是跨数百万用户共享这个乘数效应
效果
- Claude Code 启动几乎是瞬间的
- 新会话只需要发送动态部分
- 长对话的成本显著降低(短对话节省不明显)
四层递进的 Compact 架构:从轻量清理到全量压缩
上下文接近上限
↓
Layer 1: MicroCompact(轻量清理)
├── 缓存已冷 → 直接清空旧 tool_result
└── 缓存还热 → cache_edits 增量删除
↓ 不够?
Layer 2: SessionMemoryCompact(会话记忆压缩)
├── 保留最近 10K-40K token 的消息
└── 用 Session Memory 替代旧对话
↓ 还不够?
Layer 3: Full Compact(全量压缩)
├── Fork 一个 agent 做摘要
├── 复用主对话的 prompt cache
└── 图片替换为 [image] 标记
↓ 还不够?
Layer 4: PTL Retry(终极兜底)
└── 从头部砍掉最旧的消息组,最多砍 20%Proactive 模式:用一套完全不同的 System Prompt 自主工作
普通的 Claude Code 是“被动响应”的:你输入,它回复。
但当激活 PROACTIVE 或 KAIROS 模式时,会切换到一套完全不同的 System Prompt,让 Agent 变成“自主工作”模式:
if (PROACTIVE || KAIROS) {
return getProactiveSystemPrompt();
}
Proactive Prompt 包含
- 自主身份:“You are an autonomous agent……”(你是一个自主 Agent)
- 定时唤醒:tick 机制,不用等你输入,自己定时醒来干活
- 后台任务管理:可以在后台执行长期任务
- 焦点感知:知道你在不在看终端,动态调整行为
- 睡眠调度:SleepTool 机制,合理安排工作和休眠
终端焦点感知:根据用户注意力动态调整自主程度
Skill Discovery:技能自动发现与加载机制
Claude Code 有一个独立的技能发现和加载系统,通过 EXPERIMENTAL_SKILL_SEARCH feature flag 控制。
注意:Skill Discovery 不是 Proactive 专属功能,它是一个独立的系统,普通模式和 Proactive 模式都可以使用。
三个层次
- 自动发现(被动)
每轮对话自动运行 getTurnZeroSkillDiscovery(),扫描 .claude/skills/ 目录下的所有 SKILL.md,匹配关键词和描述,推送相关技能。
- 主动搜索(DiscoverSkillsTool)
模型主动调用,搜索特定技能。用于“中途转向”或“非典型工作流”。已展示的技能自动过滤,不重复推荐。
- 远程技能
通过 remoteSkillState + remoteSkillLoader 从远程加载技能。必须先通过 DiscoverSkills 发现,才能通过 SkillTool 执行。遥测追踪 was_discovered 字段。
工作流程
用户发送消息
↓
prefetch.ts — 扫描消息内容,匹配相关技能
↓
生成 skill_discovery attachment
"Skills relevant to your task: [skill1, skill2]"
↓
注入到当轮对话的 attachment 中
↓
模型看到技能提示,调用 SkillTool 执行与 Compact 的配合
压缩后 skill_discovery attachment 会丢失,resetSentSkillNames() 会在下一轮重新推送,确保模型始终能看到相关技能。
这是一个智能的“技能推荐系统”,让 Agent 自动发现和加载最相关的能力。
与 OpenClaw 的架构对比:两种设计哲学
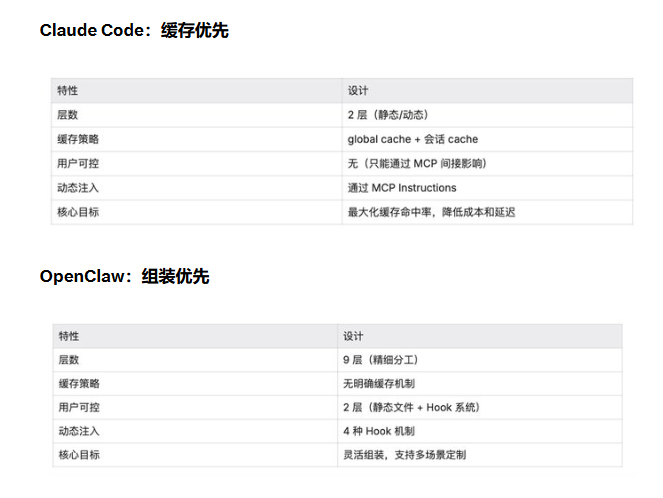
Claude Code 的选择:
- 牺牲灵活性,换取极致的缓存效率
- 适合 Anthropic 这种 Provider 深度定制的场景
- 数百万用户共享同一份静态 prompt,成本优势明显
OpenClaw 的选择:
- 牺牲缓存优化,换取极致的可定制性
- 适合需要多场景、多身份、多协议的复杂系统
- 9 层架构让每个层次的职责清晰,便于扩展和调试
核心差异
- Claude Code 更极致
- 缓存优化到极致(global cache + cache_edits)
- 成本和延迟控制得很好
- 适合 Anthropic 这种 Provider 深度定制
- OpenClaw 更灵活
- 9 层架构职责分离更清晰
- Hook 系统比 MCP Instructions 更强大
- 支持更复杂的场景(Skills、协议规范、字符预算)
Auto Dream:从“记录对话”到“学习知识”的自我进化记忆系统
四个阶段
Phase 1: 定向(Orient)
- 扫描已有记忆
- 了解当前知识库状态
Phase 2: 采集(Gather)
- 从日志和会话转录中提取新知识
- 识别重要的交互模式
Phase 3: 整合(Integrate)
- 合并新旧知识
- 修正矛盾
- 去重
Phase 4: 修剪(Prune)
- 精简索引
- 删除矛盾条目
- 优化记忆结构
闭环自我进化
每次交互 → 提取记忆 → 定期整合 → 更新认知 → 指导下一次交互
这是一个真正的自我进化系统。不是简单的“记录对话”,而是主动提取、整合、修正知识。
三层记忆体系
- Auto Memory(自动记忆)
- 路径:~/.claude/projects/<path>/memory/
- 触发:每轮对话结束自动写入
- 机制:extractMemories 实时提取
- 特点:短期工作记忆,快速访问
- Team Memory(团队记忆)
- 路径:auto memory 的子目录
- 作用:团队共享的知识库
- 特点:跨用户共享,协作场景
- Agent Memory(Agent 专属记忆)
- 路径:自改进 agent 的专属目录
- 作用:Agent 自己的长期知识库
- 特点:配合 autoDream 定期整合
从短期到长期的转化
实时提取(extractMemories)
↓
短期工作记忆(Auto Memory)
↓
定期整合(autoDream)
↓
长期知识库(Agent Memory)
这套体系让 Agent 不仅能“记住”,还能“学习”和“进化”。
Undercover 潜伏模式
行为特征
- 隐藏所有 AI 痕迹:不留任何 AI 生成的标记
- 隐藏模型代号:不暴露使用的是哪个模型
- 隐藏 Co-Authored-By:不显示 AI 协作者
- 不可强制关闭:代码注释写着 “There is NO force-OFF”
触发机制
通过 commitAttribution.ts 的 allowlist 判断是否内部仓库:
- 内部仓库:正常标注 AI 贡献
- 公共仓库:自动进入潜伏模式
为什么这样设计?
- 避免开源社区对 AI 生成代码的偏见
- 保护 Anthropic 员工的工作流程
- 让 AI 辅助的代码和人工代码无差别

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)