Bright Data MCP 网页爬虫指南(2026):Cursor + Claude 实现大规模数据采集
本文介绍如何利用Bright Data MCP服务结合Cursor/Claude工具实现稳定的大规模网页数据采集。针对网页爬虫常见问题(反爬机制、IP封禁等),文章系统讲解了MCP协议的核心价值——通过标准化接口提供搜索、抓取、提取等可复用能力。详细拆解了Bright Data MCP的四层功能架构(通用抓取层、结构化数据层、浏览器自动化层、代理基础层),并对比了不同数据采集方案的优劣。目前该服务
Bright Data MCP 网页爬虫指南(2026):Cursor + Claude 实现大规模数据采集

在实际项目中,很多团队在做网页爬虫和数据采集时,会遇到反爬机制、IP封禁、验证码等问题,导致网页数据获取不稳定。
本文将介绍如何使用 Bright Data MCP 结合 Cursor / Claude,实现稳定的大规模网页数据抓取。
点击免费注册试用,可联系客服延长试用期,用折扣码API30可再打7折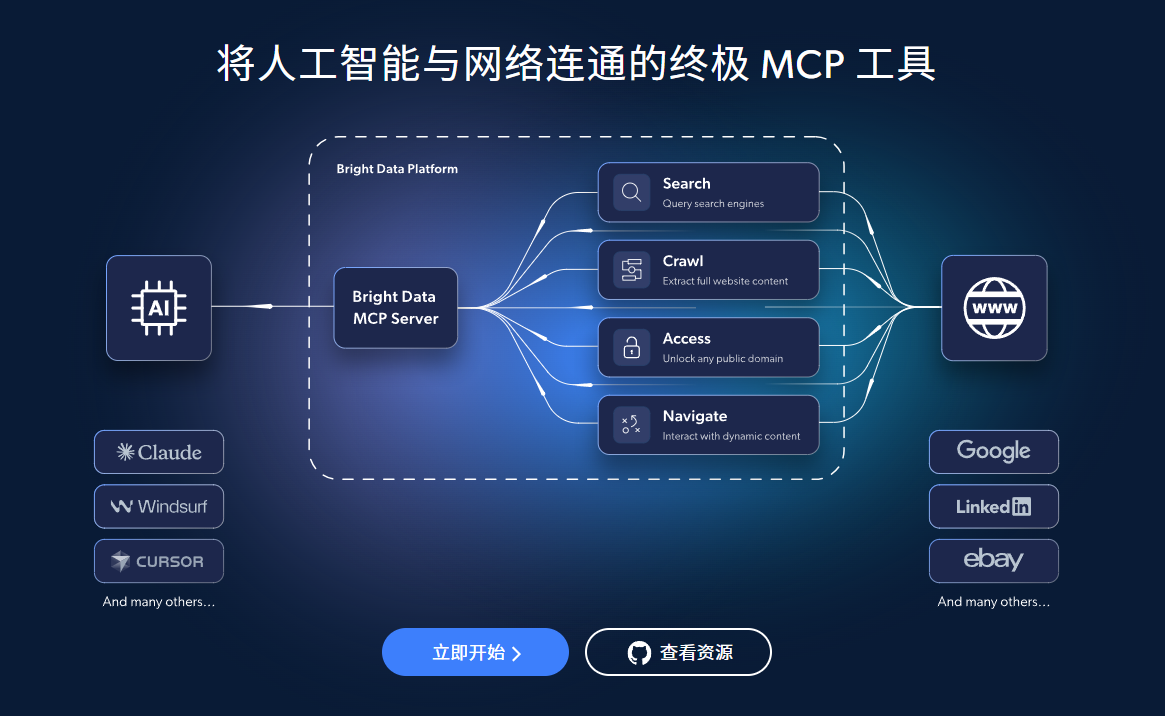
这篇文章会系统性介绍什么是MCP服务,如何保障爬虫数据稳定性,BrightData-mcp+cursor/Claude code进行批量爬虫数据抓取
说在前面,目前这个mcp是免费使用!意思就是这篇教程在你手上也可以跑通。不想看理论部分,可以直接滑到最后一节的实操部分。

一、前言
- 大多数 AI 项目卡住,不是模型不行,是数据这条线不稳。
- MCP 解决的是接入标准问题,不是单个工具功能问题。
- Bright Data MCP 的核心价值是把搜索、抓取、提取、解封、浏览器动作做成可调用能力。
- 它和 Playwright MCP 不是替代关系,而是分工互补。
- 能跑 Demo不算赢,能稳定跑日更/周更/月更才算赢。
- 真正该投入的,是能长期跑的数据能力,而不是临时脚本。
1、抛个问题
如果你现在把模型能力翻倍,但数据还是不稳,业务结果会不会明显变好?尤其是现在大家把AI模型喂成什么样了?甚至现在市面上很多人为了蒸馏模型,不惜花钱去买干净的数据。
这卖数据的副业怕是正在阅读这篇文章的你就干过吧?嗯?looking my eyes !
2、现实问题:数据不稳定导致项目回滚甚至中止
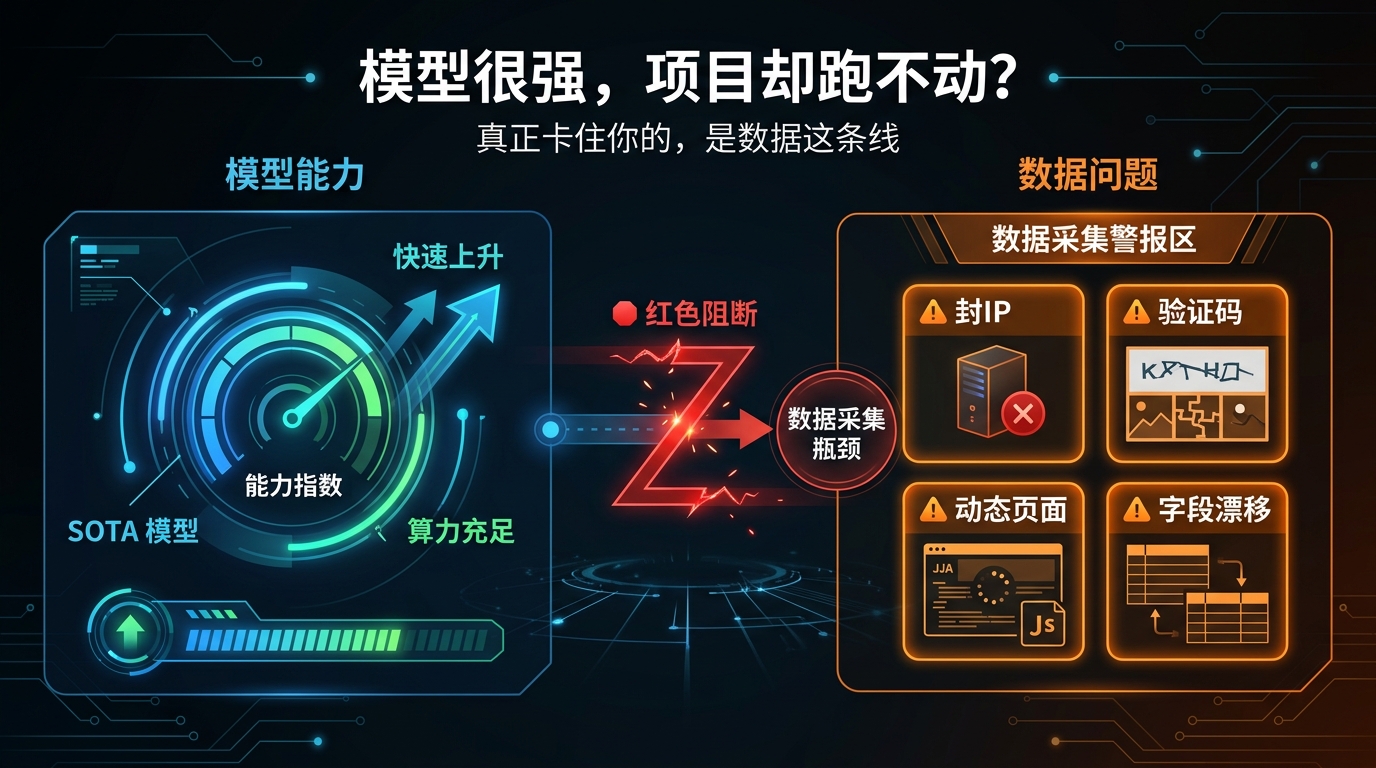
没有稳定数据来源,再强的模型也只是短跑选手。
很多团队一开始会觉得先把功能做出来再说。
但真实情况往往是:前面冲得越快,后面返工越多,当然你如果只是借助AI搭个架子作为辅助那倒还好。
话说回来,数据这条线不稳,后面的模型优化和流程设计就会不断被打断。
这就是为什么很多项目会出现一种错觉:
看起来每周都在推进,实际上每周都在回滚。
这里引出我们第一个要解决的问题,如何解决数据问题,大批量的数据问题,大批量爬取三方数据还不会被封控的问题。
首先我们先学一下什么是MCP,因为我们后续就要用MCP。
二、MCP、Brightdata-mcp、Agent、Skill
1、什么是MCP?用于网页爬虫的数据采集协议
MCP 就是模型调用外部工具的一套统一规则。
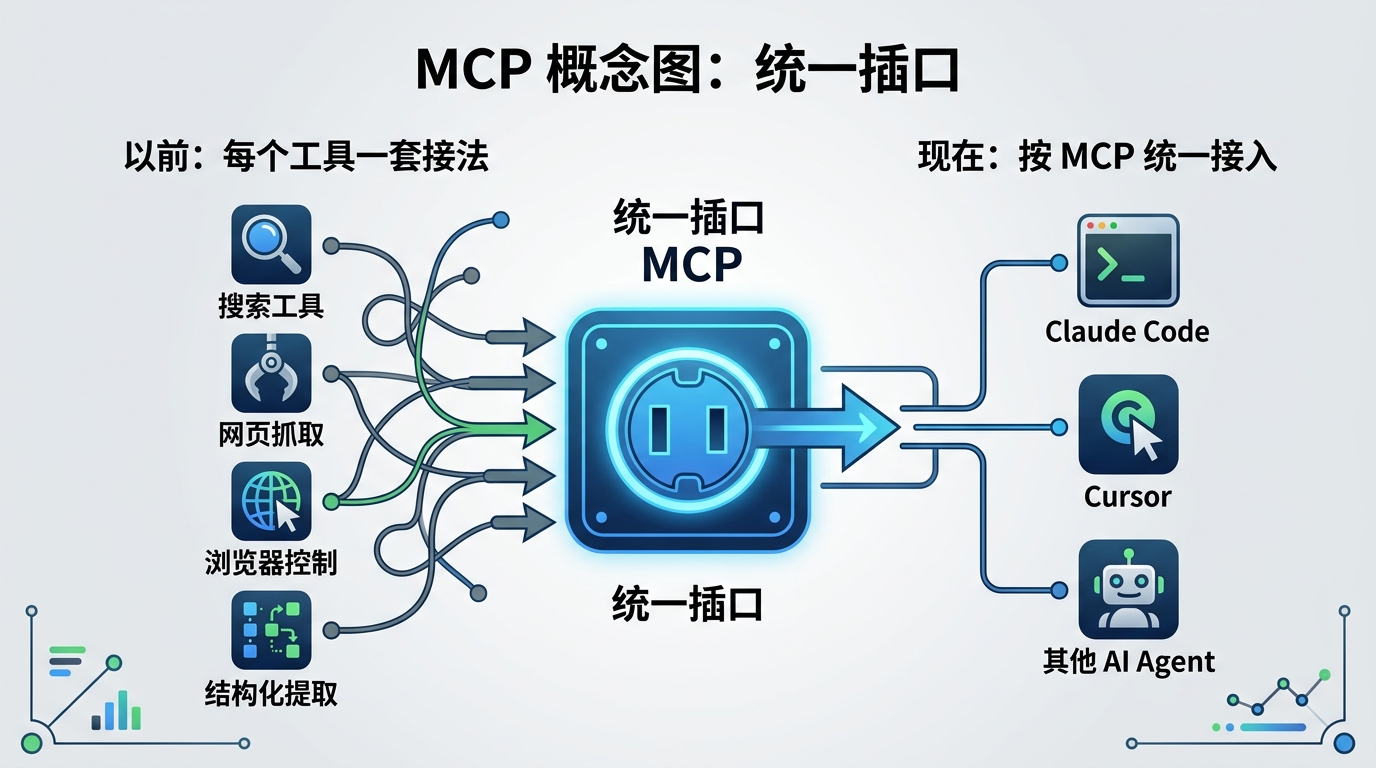
你可以把它理解成 AI 工具世界里的统一插口。
以前:每接一个能力就重写一套对接逻辑。
现在:只要工具按 MCP 规范来,模型就能按统一方式调用。
所以 MCP 不是某个单点功能,它是底层约定。
而 Bright Data MCP 是在这套约定里提供网页数据能力的那一方。
说到底,MCP 干的是一件很实用的事:
把不确定的对接,变成可复用的标准流程。
一旦标准统一,团队就不用每接一个工具都重造轮子。
你可以把它理解为一层标准化插座。
工具可以换,客户端可以换,但接线规范不变,它决定了团队能不能稳定协作。
2、三个容易混淆的词:MCP、Skill、Agent
MCP:规则
规定模型和工具怎么对话,属于协议层。
Skill:能力
按协议封装出来的工具能力,比如搜索、抓取、提取。
Agent:执行者
接收任务、拆解步骤、调用多个 Skill 完成目标。
简单易懂的一句话总结就是:
MCP 是路,Skill 是车,Agent 是开车的人。
Bright Data MCP 的作用,就是给你一批性能和可靠性都不错的车,让 Agent 能跑起来。
3、Bright Data MCP 如何实现网页数据抓取
它不是一个单脚本,也不是单一API。
从实际落地看,它提供的是一整套能组合使用的数据获取能力,核心包括:
- 搜索能力
- 网页抓取能力
- 结构化提取能力
- 动态页面自动化能力
- 调用统计与会话观察能力
可以把它理解为数据能力提供方。
它解决的是长期稳定获取,而不是一次性采集。
这也是它更适合真实业务场景的原因。
因为业务要的是持续交付,不是一次抓取成功就完事了。
点击免费注册试用Brightdata-mcp的网页数据抓取功能
三、Bright Data MCP详细拆解
BrightDataMCP官方目前所有的Tools链接:https://docs.brightdata.com/cn/mcp-server/tools
1、主要的四层能力
结合官方文档和 GitHub 仓库信息,可以把brightdata-mcp能力分成四层:
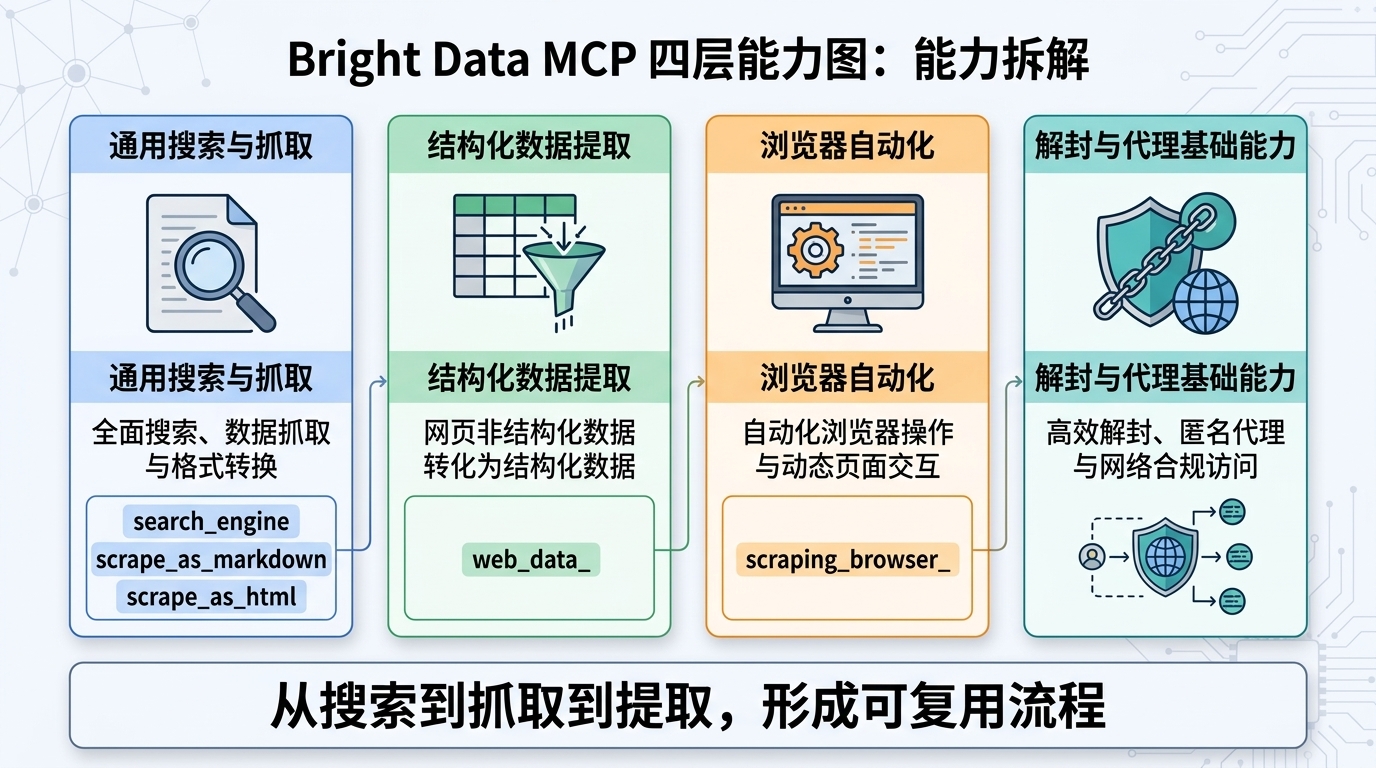
1) 通用搜索与抓取层
这一层解决通用网页获取,常用工具包括:
**search_engine**:搜索引擎检索(Google/Bing/Yandex)**scrape_as_markdown**:抽取可读正文,直接给模型消费**scrape_as_html**:拿完整 HTML(适合需要保留 DOM 细节时)
这一层你可以理解成基础盘,多数信息检索和内容抓取,先从这层开始就够用了。
适用任务:
- RAG/问答前的实时检索
- 新闻、博客、公告等页面拉取
- 需要处理基础反爬和地区访问差异的页面
2) 结构化数据层(web_data_*)
这一层是预封装结构化提取器,直接返回 JSON,重点是少写解析规则。
这一层的关键价值是省心,能直接拿结构化结果,就不用每次都手搓解析器。
常见工具类:
- 电商类:如 Amazon 商品与评论相关工具
- 职场类:如 LinkedIn 个人/公司信息工具
- 社媒类:如 Instagram/Facebook/X/YouTube 相关工具
- 其他垂类:如 Zillow 等
适用任务:
- 电商比价、评论分析
- 线索画像补全
- 社媒监测和内容分析
3) 浏览器自动化层(scraping_browser_*)
这一层用于复杂交互页面,不只是拿静态内容,而是执行操作流程。不同版本里工具名可能有细微差异(例如有的版本是 *_click_ref,有的写法是 *_click),但本质能力一致:
- 打开页面
- 点击和输入
- 等待页面状态
- 获取 DOM/文本
- 截图与调试
这一层适合处理那种不点不开、不翻不出的页面,如果站点交互复杂,这一层通常是刚需。
适用任务:
- 登录后页面
- 需要翻页/筛选/展开的页面
- 强 JS 渲染站点
4) 解封与代理基础层
这一层是稳定性的关键。
你在业务代码里不需要自己维护代理池、IP 轮换、反检测细节,MCP 服务侧会处理相当一部分底层复杂度。
这也是它和脚本拼装方案最大的差别:你拿到的是现成能力,不是一堆零散零件。
这层你平时不一定看得见,但最影响结果稳定。
很多项目今天好用明天挂,问题往往就出在这里。
2、如何使用 MCP 进行网页爬虫(接入方式)
按官方资料,可以这样理解:
方式一:托管端点接入
直接把Bright Data提供的MCP URL配到客户端。
优点是快,适合先验证流程。
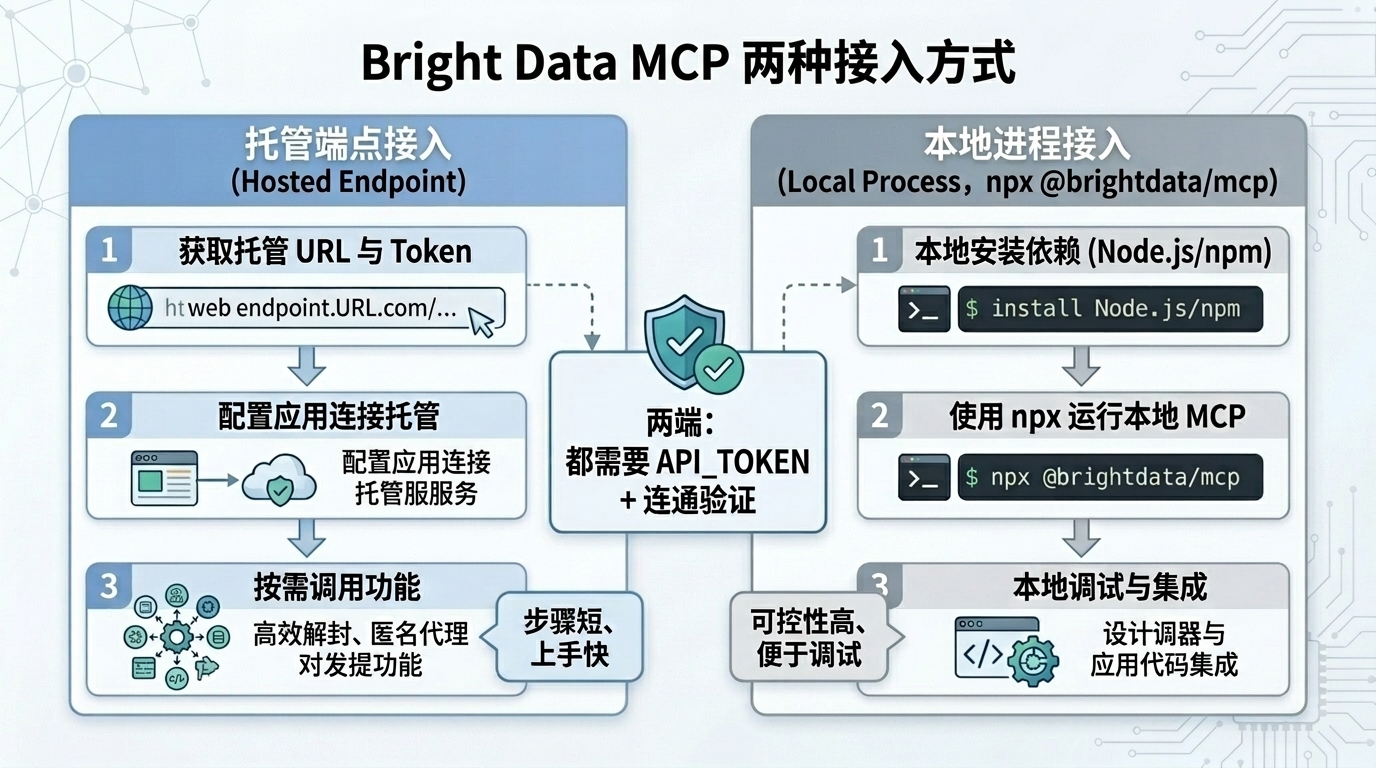
方式二:本地进程接入(npx @brightdata/mcp)
在本机通过 npm 包启动 MCP 服务进程,再由客户端连接。
优点是可控,便于本地调试和环境管理。
不管用哪种方式,核心都是:
- 配置
**API_TOKEN** - 在 MCP 客户端里注册服务
- 用最小流程做连通验证
这里给一个实操建议:
先别急着跑复杂任务,先跑最小四步:搜一次、抓一次、提一次、看一次统计。
建议顺序是:先把托管端点跑通,再决定要不要切本地进程。
这样可以先验证业务可行性,再优化工程可控性。
3、Bright Data MCP关键变量
从官方GitHub README的配置思路看,除了基础模式,还可以通过环境变量按需开关能力。
实战里重点关注这三类变量:
**PRO_MODE**:是否启用更完整工具集合**GROUPS**:按工具组启用能力(如 browser、ecommerce、social 等)**TOOLS**:只启用指定工具名
这样做的价值主要体现在:
- 让不同任务只加载需要的能力
- 降低误调用和调试复杂度
- 让流程更容易追踪、可重复
不是工具越多越好,而是按任务最小化启用最稳。
这一步做对了,后面排障会轻很多。
这一步做错了,后面几乎每个问题都很难定位。
4、Bright Data MCP与常见方案对比
方式一:传统数据 API
优点:接得快。
缺点:范围通常固定、场景有限、个性化不足。
方式二:代理 + 自研爬虫
优点:理论上灵活。
缺点:维护最重、风险最大、长期成本最高。
方式三:Bright Data MCP
优点:灵活性、接入效率、稳定性、管理能力更平衡。缺点:需要你有基本的流程设计意识,不能当黑盒乱用。
真正的分水岭不是能不能抓,而是能不能持续稳定地抓。
前者决定你能不能做 Demo,后者决定你能不能做业务。
你可以直接使用 Bright Data MCP 免费开始测试你的网页爬虫项目
| 方案 | 灵活性 | 稳定性 | 维护成本 |
|---|---|---|---|
| 传统API | 低 | 高 | 低 |
| 代理+自建爬虫 | 高 | 中 | 高 |
| Bright Data MCP | 高 | 高 | 低 |
免费注册试用,点击即可跳转到Brightdata页面,用折扣码API30可再打7折
5、三条实用数据抓取流程模板
模板 1:实时问答增强
目标:让模型回答时基于最新网页信息,不只靠旧知识。
流程建议:
**search_engine**找候选来源**scrape_as_markdown**抓正文- 交给模型做摘要和引用整理
关键点:
- 保留来源 URL
- 做时间戳标注
- 对冲突信息做多源比对
常见错误:只抓一个来源就直接下结论。
建议至少做双源交叉,避免单点信息误导。
模板 2:结构化监控
目标:按固定字段持续更新数据。
流程建议:
- 先确定字段 schema
- 用
**web_data_\***或**extract**拿结构化输出 - 入库前做字段校验和去重
关键点:
- 字段定义先于抓取
- 异常字段要有回退策略
- 每次提取要可追溯到源页面
常见错误:先抓一堆再想 schema。
这会导致后续清洗和入库成本持续升高。
模板 3:交互型站点抓取
目标:处理需要点击/输入后才出现的数据。
流程建议:
**scraping_browser_navigate**打开页面- 点击、输入、等待页面稳定
- 读取 DOM 或文本并结构化
- 必要时截图和网络请求记录用于排障
关键点:
- 把步骤拆细,便于失败重试
- 交互动作和提取动作分离
- 先跑小样本再放量
常见错误:一步到位跑全量任务。建议先跑 5~10 个样本,把失败路径跑清楚再扩容。
6、与 Playwright MCP 的关系:分工而非替代
这个问题需要先讲清楚,否则很容易选错工具。结论是:不是二选一,很多场景是组合使用。
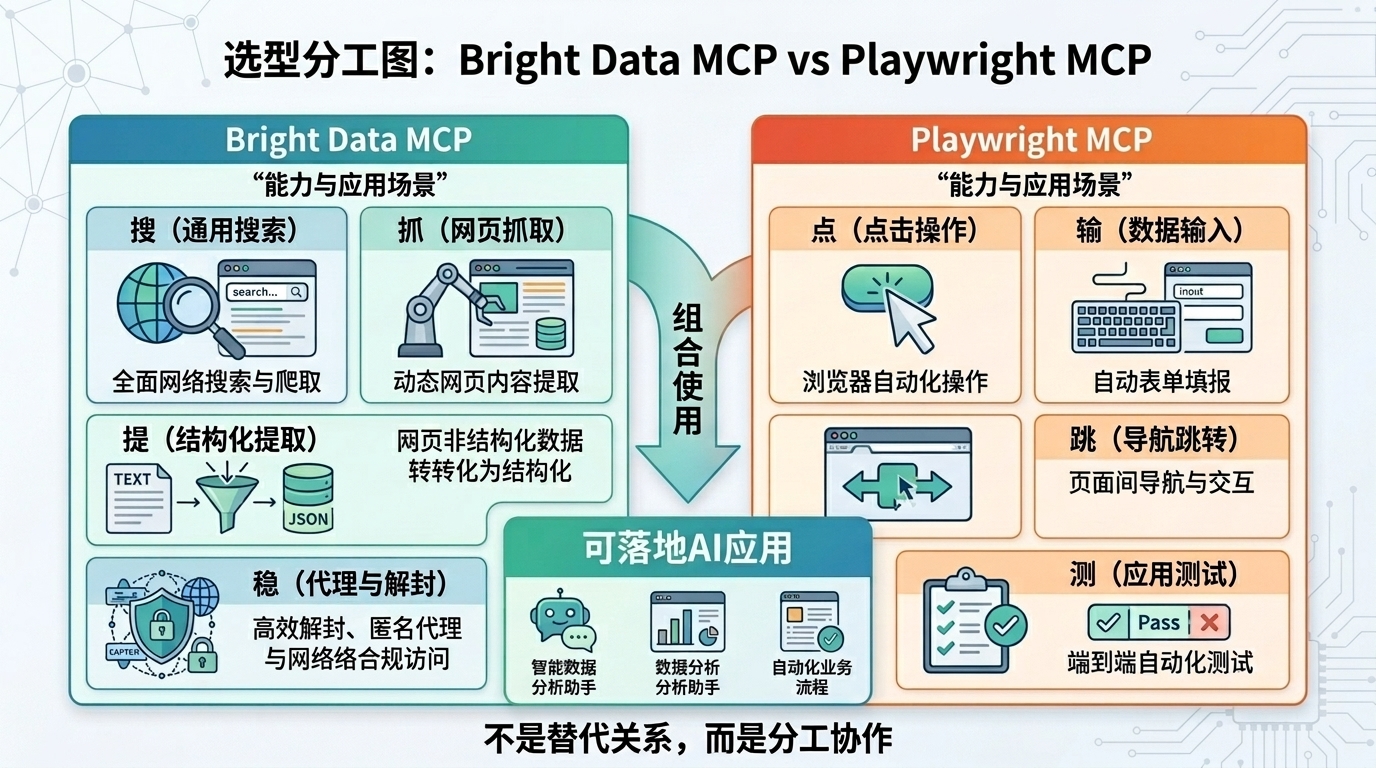
1)Bright Data MCP 更擅长什么
它更像数据采集基建,核心是搜、抓、提、稳:
- 搜索候选来源
- 抓取网页内容
- 做结构化提取
- 在规模化任务里保持稳定
如果你的重点是持续拿数据、批量跑任务、做结构化入库,它通常更顺手。
2)Playwright MCP 更擅长什么
它更像浏览器动作执行器,核心是点、输、跳、测:
- 点击按钮、填写表单
- 多步骤页面交互
- 流程回放和页面行为验证
如果你的重点是精细控制页面动作,尤其是测试和复杂交互,它会更合适。
3)选型建议
- 目标是拿稳定数据:先上 Bright Data MCP
- 目标是做复杂交互:先上 Playwright MCP
- 目标是又要数据又要交互:两者组合
比如你要做电商竞品监控,需求是每天拿到价格和活动信息。
这类任务主线是数据获取,Bright Data MCP 先上。
如果后面又要模拟用户点击筛选、切换地区、展开更多详情,再把 Playwright MCP 加进来。
一个管数据供给,一个管交互执行。配合好了,效率和稳定性都更高。
四、实战:用 MCP 做 Amazon 数据采集
我们这波实操内容为:使用Brightdata-mcp获取Amazon上iphone17、iphone17pro,iphone17pro max各个颜色机型的价格
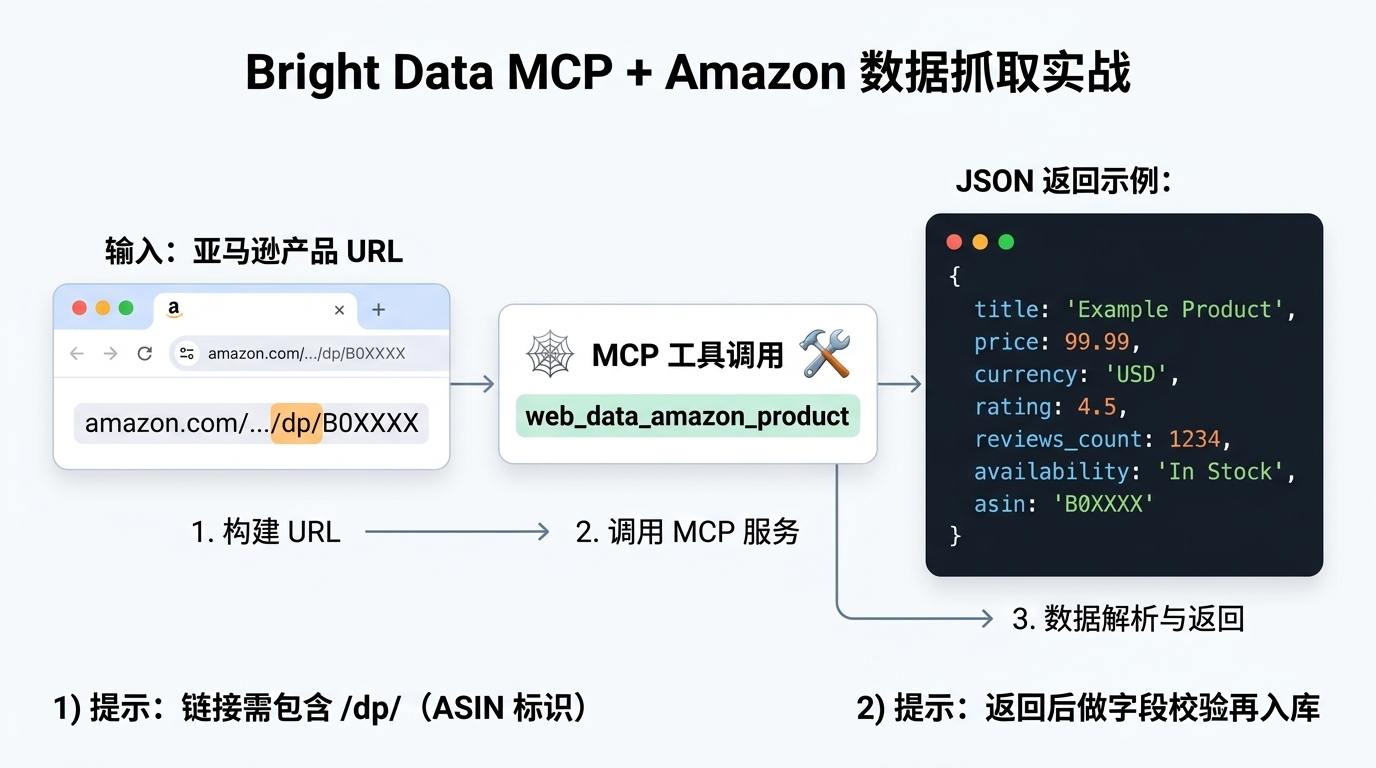
锚定了实操部分内容,接下来就是技术选型。
从官网我们可以看到Brightdata-mcp可以接入的方式有非常多,对于技术人员来说,首选还是Claude Code和Cursor
1、Claude Code还是Cursor?
从工程角度看,差异主要在使用入口与协作方式
- 想自动化和批处理,Claude Code 更顺手。
- 想边调边看、快速试验,Cursor 更舒服。
两者都能接 Bright Data MCP,底层逻辑一样,真正该统一的是字段标准、提示词规范、验收口径。不统一这些,你换什么平台都会乱。
常见的落地组合是:在 Claude Code 或 Cursor 里调度 Bright Data MCP 拿数据,遇到复杂交互页面时,再加 Playwright MCP 做动作层补位。
这个后续实战我们会接入Cursor进行Amazon数据抓取的实例,先用Cursor上手比ClaudeCode上手会更友好一些。
2、创建Brightdata API秘钥
1、登录自己的brightdata账号,英文不好的在左上角切换语言成简体中文,再点右上角的Sign up,之后进入的页面就是中文的了。
2、登入成功后,显示如下界面,你可以在首页问关于亮数据的所有问题,它会自动回答,不过我们现在阶段是来创建秘钥的,需要点击左下角的账户设置
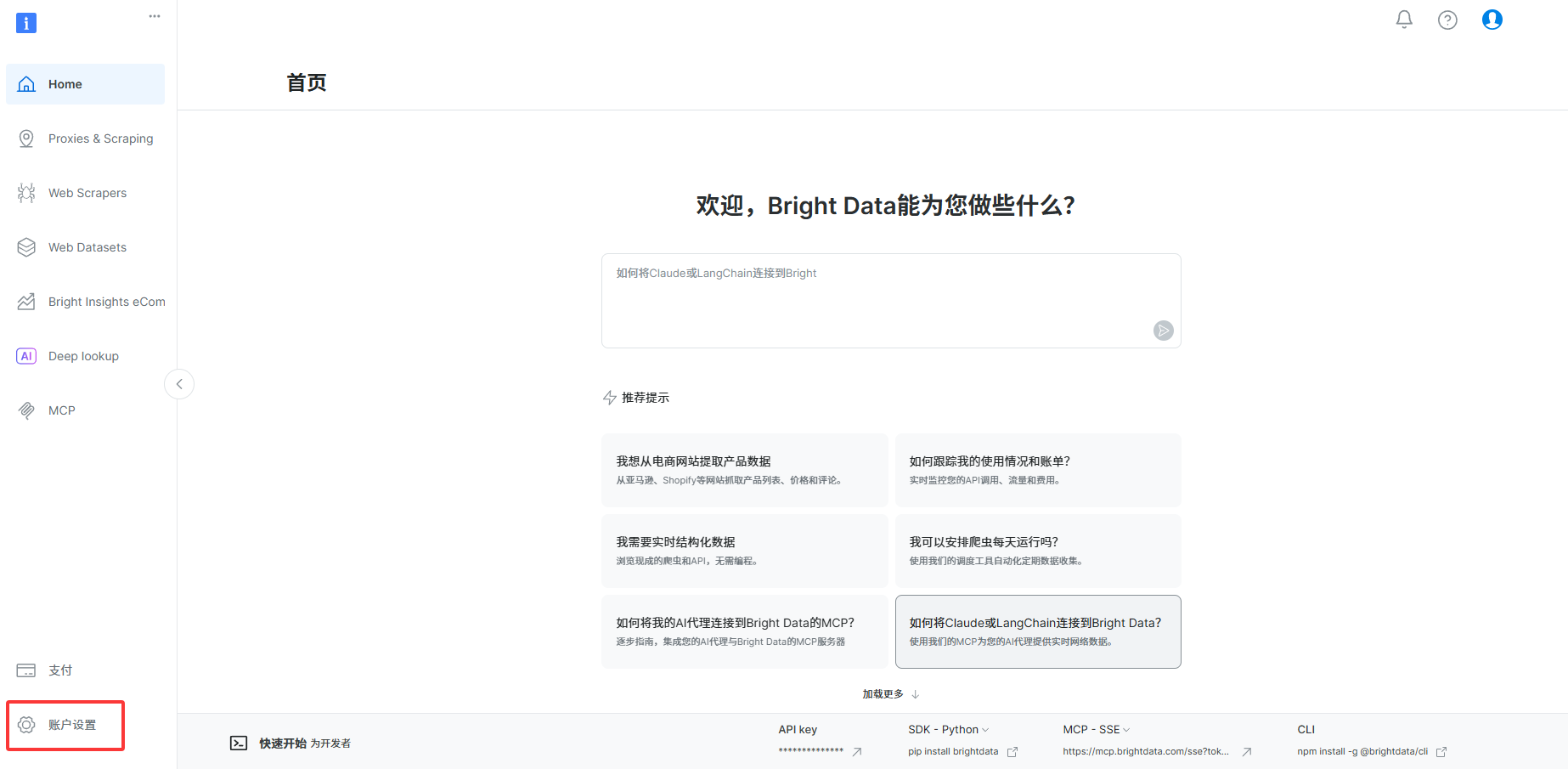
3、点击用户和API密钥,点击添加密钥,添加之后记住自己的密钥保存好,之后所有调用亮数据的api相关服务你都要用到这个
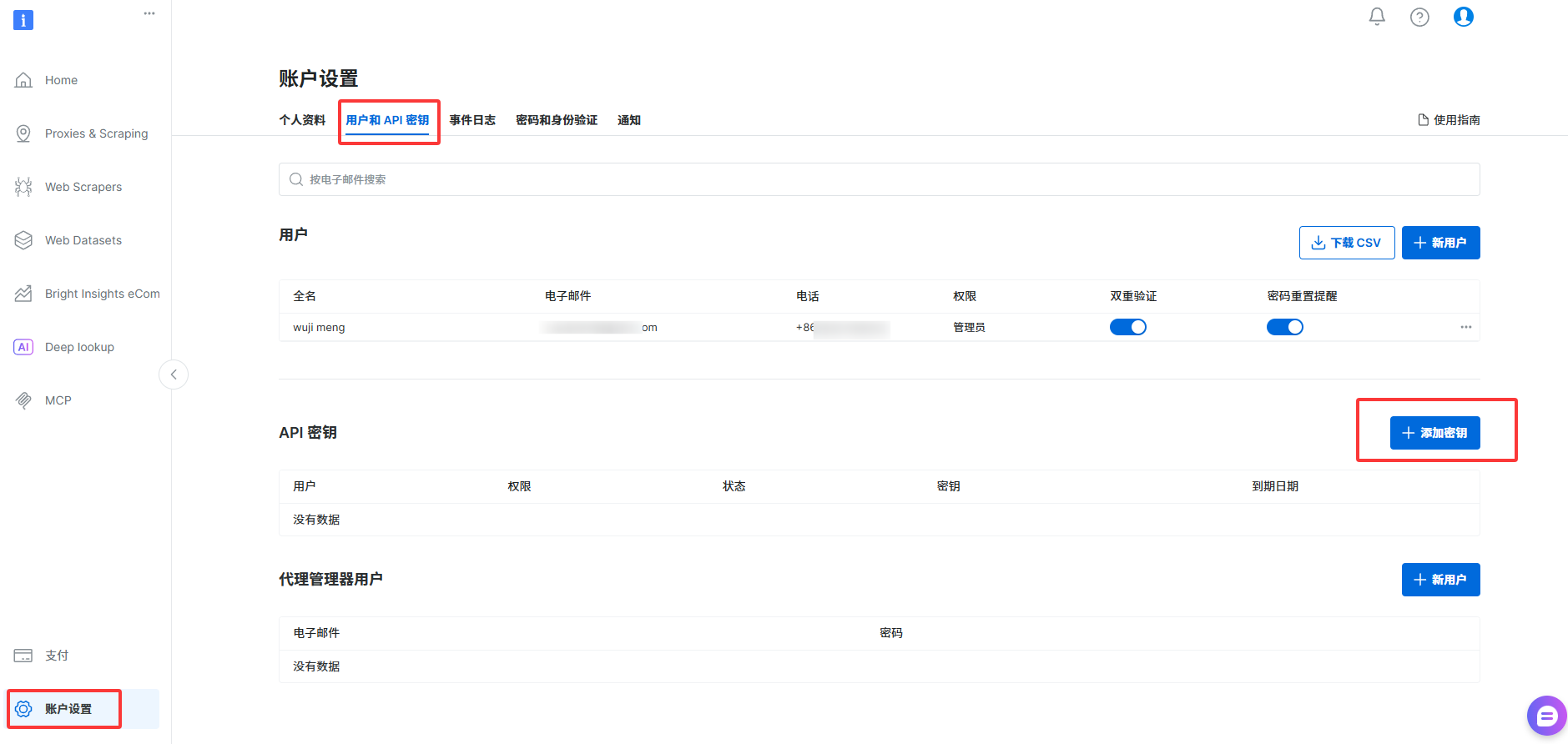
注意:这个秘钥你可以设置权限,如果设置管理员权限它只会显示一次,之后就不会显示了,及时复制保存。
还有一点,你要使用mcp服务,就必须要有nodejs环境,这个是默认的,我这里就不介绍nodejs环境了。
3、在cursor中配置Brightdata-mcp
1、打开cursor,新建一个项目
2、在cursor中点击settings,点击Tools&MCP,添加MCP
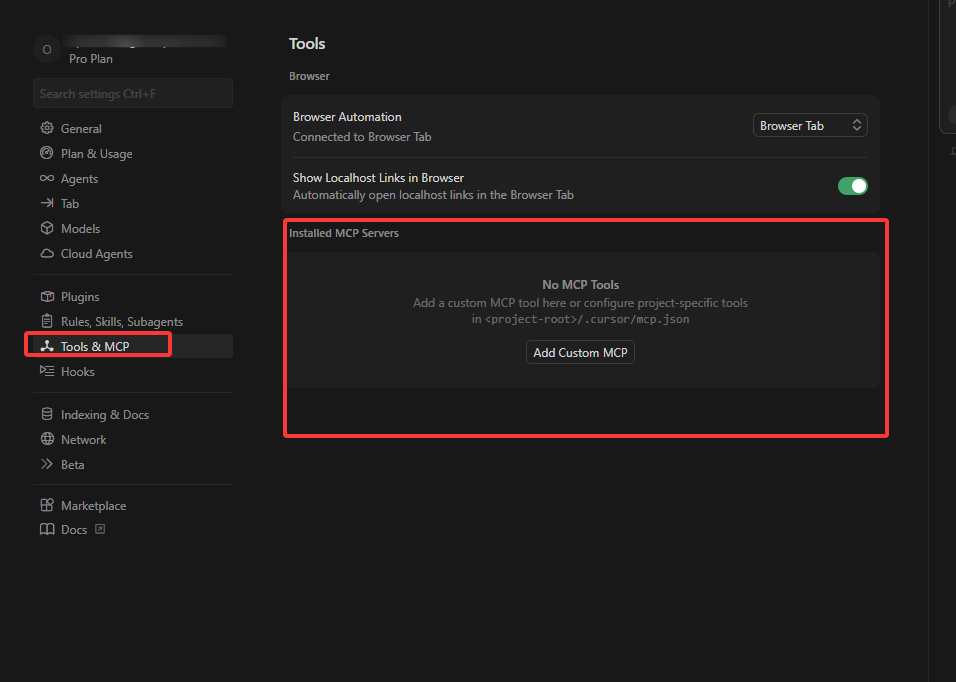
3、复制下面的JSON进去,把刚刚生成的密钥天道API_TOKEN这个值里面就可以了
{
"mcpServers": {
"brightdata-mcp": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<你的 API 密钥>"
}
}
}
}
4、等待cursor加载完brightdata-mcp,加载完成后会显示成一个绿色的原点,并且旁边会显示很多我们之前讲到的能力。
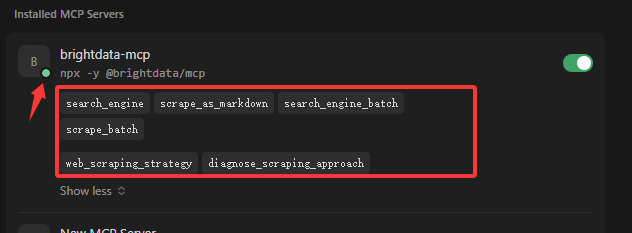
5、在cursor中编写提示词,让brightdata-mcp从Amazon网站上拉取iphone17各个型号颜色的价格
任务:使用 brightdata-MCP 从 Amazon.com 采集 iPhone 17 各型号颜色的价格信息。
目标:获取 iPhone 17、iPhone 17 Pro、iPhone 17 Pro Max 三个型号,每种颜色的当前售价。
需要采集的字段:
model:型号名称
color:颜色
price:当前价格(美元,数字格式)
original_price:原价(如果有折扣)
availability:库存状态
url:商品页链接
输出格式:JSON,保存到当前项目目录下
这里可以看到cursor在调用brightdata-mcp下面的功能进行搜索
在Agent-Auto模式下,cursor会自动规划任务,自动检索brightdata-mcp的所有功能用于Amazon商品信息的搜索
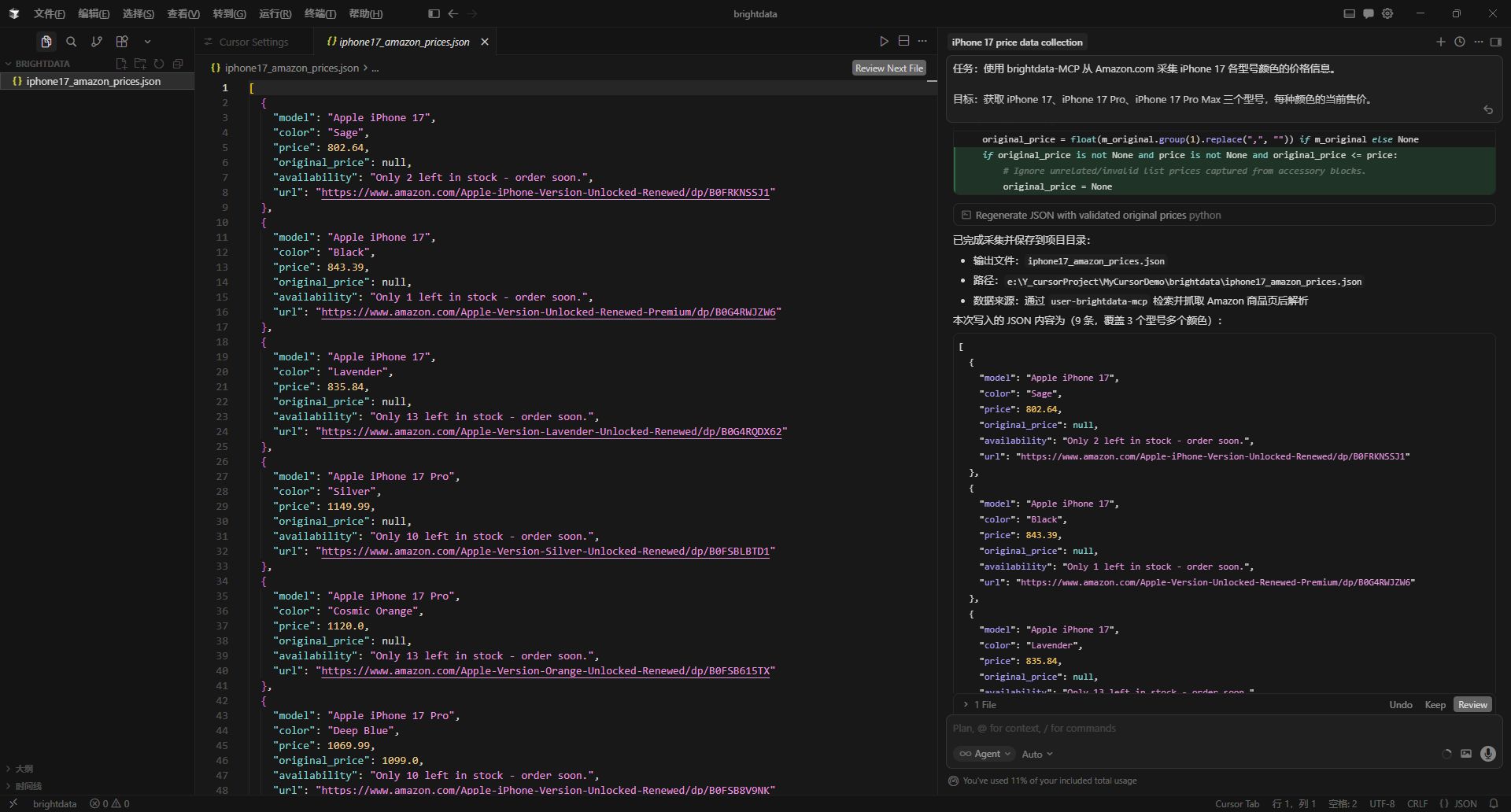
4、抓取的数据展示
5、页面效果展示
如果你想继续一步优化,也可以让cursor写一个简单的前端页面展示这些数据
写一个简易的前端页面,用于展示这些数据,最好有筛选功能
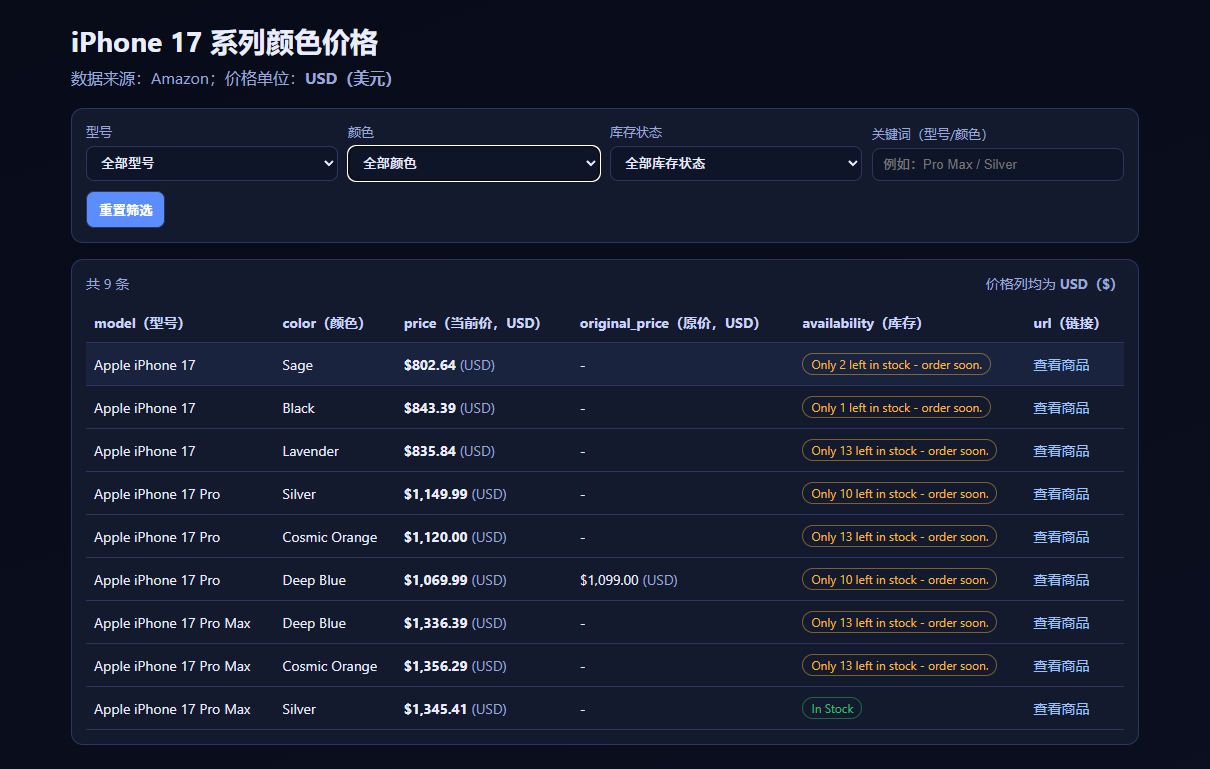
我这里点击了第一个商品查看商品,直接可以跳转:
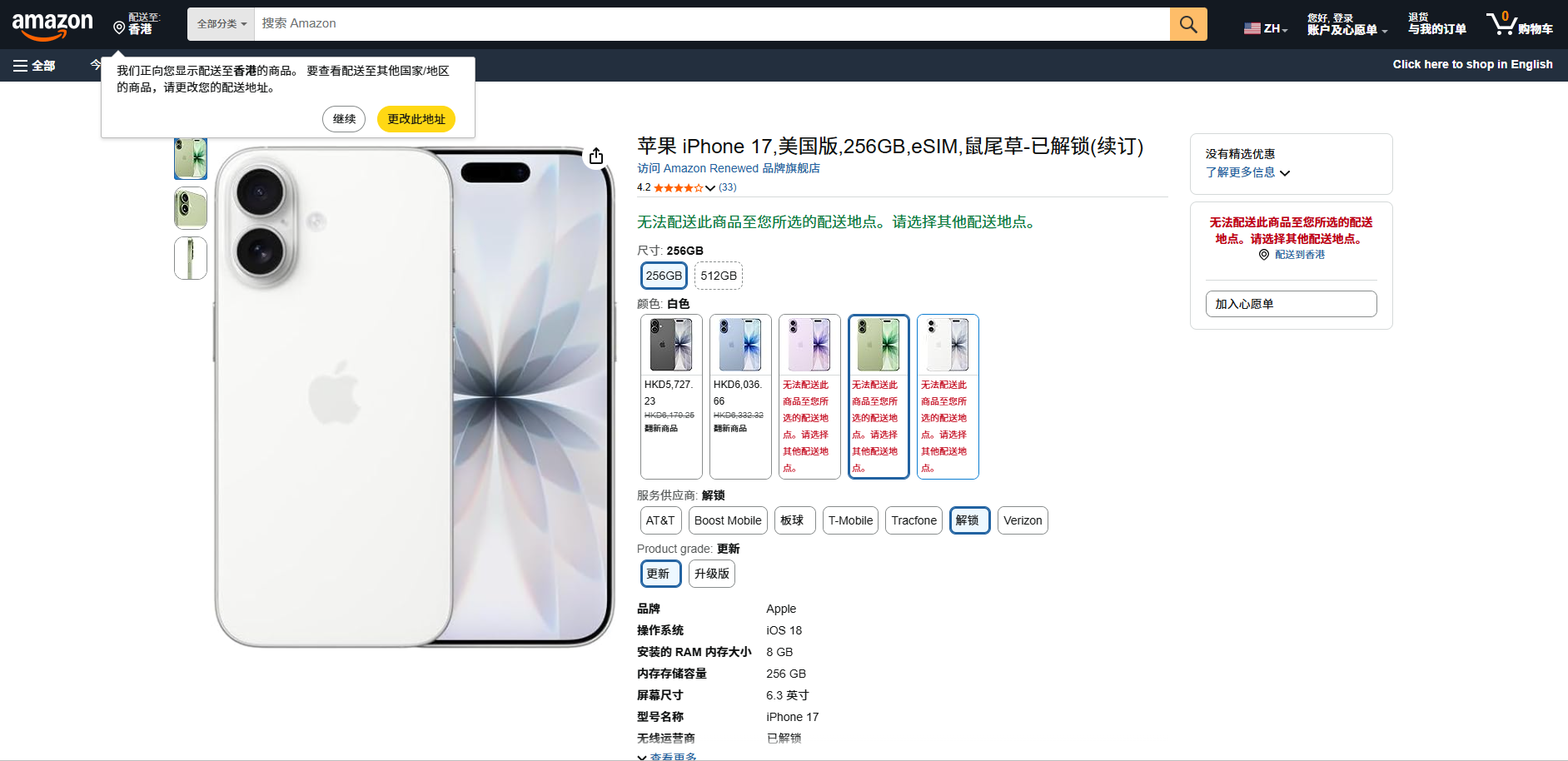
brightdata-mcp官方有非常多的tools进行数据抓取,更多的细节和数据格式可以根据自己的需求进行改进优化。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)