揭秘 Claude Code 不跑偏的秘密:从压缩、记忆到续写的 Runtime 设计全解,看完这篇就懂了!
用 Claude Code 跑过长任务的人大概都有这个经历:前半段很顺,到了某个节点突然开始重复读文件、忘了前面做到哪了、甚至把已经改过的东西又改回去。
用 Claude Code 跑过长任务的人大概都有这个经历:前半段很顺,到了某个节点突然开始重复读文件、忘了前面做到哪了、甚至把已经改过的东西又改回去。
你会觉得是模型不行,但其实很多时候不是。
今天想把这条线收一收。
因为顺着 memory、compact 和 session 相关源码继续看下去,有个感觉越来越清楚:Anthropic 最近讲的那些方法论,不只是停在文章里。
它已经写成代码“发”出来了。
而且真正值得看的,也不是某个彩蛋 feature,不是“上下文窗口很大”这类表面能力。
让我比较在意的是另一件事:
Claude Code 没有把“长任务别跑偏”赌在模型自己硬扛,而是把压缩、续写、记忆和信息回灌,做成了一套 Runtime。
用之前聊 Codex 仓库时的话说:OpenAI 更像是把工程经验写进仓库;Claude Code 这次做的,更像是把长任务治理写进了运行时。
太长不看版
- • 如果按更宽的口径看,Claude Code 至少有 6 到 7 层 context / memory 机制;但其中不少层更像上下文治理,和“长期记忆”最好还是分开看。
- • 这套系统真正承重的可以拆成三类:上下文窗口治理、会话级状态续写、跨会话长期记忆。
- • 在
query.ts里,microcompact、autocompact、reactiveCompact被串成了一条正式主链路,不是补丁逻辑。 - • 在它们更前面,还有
toolResultStorage这一层,把超大工具结果先落到tool-results/,上下文里只保留预览和引用。 - •
compact/prompt.ts里明确禁止压缩阶段调用任何工具,说明它把“摘要”当成一个受约束的系统动作,而不是自由发挥。 - •
SessionMemory不是“每次 compact 才补一份摘要”,而是达到阈值后由后台 fork 子代理持续维护的会话笔记。默认阈值是上下文到 10k token 以上后初始化,之后每多 5k token 或满足工具调用条件再更新。 - • 长期记忆的核心不在 compact,而在
memdir + extractMemories + autoDream。extractMemories/prompts.ts只允许基于最近消息更新 memory,autoDream则是更慢周期的后台巩固。 - •
MEMORY.md只是索引,不是存储本体,而且有 200 行 / 25KB 的硬上限。query 时的 relevant memory 召回也不是 embedding 检索,而是扫描头部描述后用sideQuery选最多 5 个文件。 - • 所以我自己的感觉是,Claude Code 真正厉害的地方,不是“记得多”,而是它认真想过“该忘什么、该保什么、该拿回来什么”,然后把这件事做成了系统。
这篇真正想讲的是什么
说到底就一句话:
长任务真正容易卡住的地方,很多时候不是 context window 不够大,而是系统有没有能力决定什么该留、什么该丢、什么该交接、什么该进入长期记忆。
所以这次让我在意的,不是某个“记忆 feature”,而是一套很清楚的预算纪律。
模型窗口负责装下多少。
Runtime 决定哪些东西配待在里面。
先把“记忆”和“上下文治理”分开
这次补读了一圈 memory 相关源码之后,我觉得有个边界得先说清楚。
外面常说 Claude Code 有“7 层记忆”,这说法不算错,但很容易把两件不同的事混在一起。
更准确地说,Claude Code 至少有两条并行链路:
- • 一条负责当前长任务不断线
- • 一条负责跨会话长期记忆
前者更像 context management,后者才更接近大家平时说的 memory。
先看下面这张图,会更容易把边界对齐:
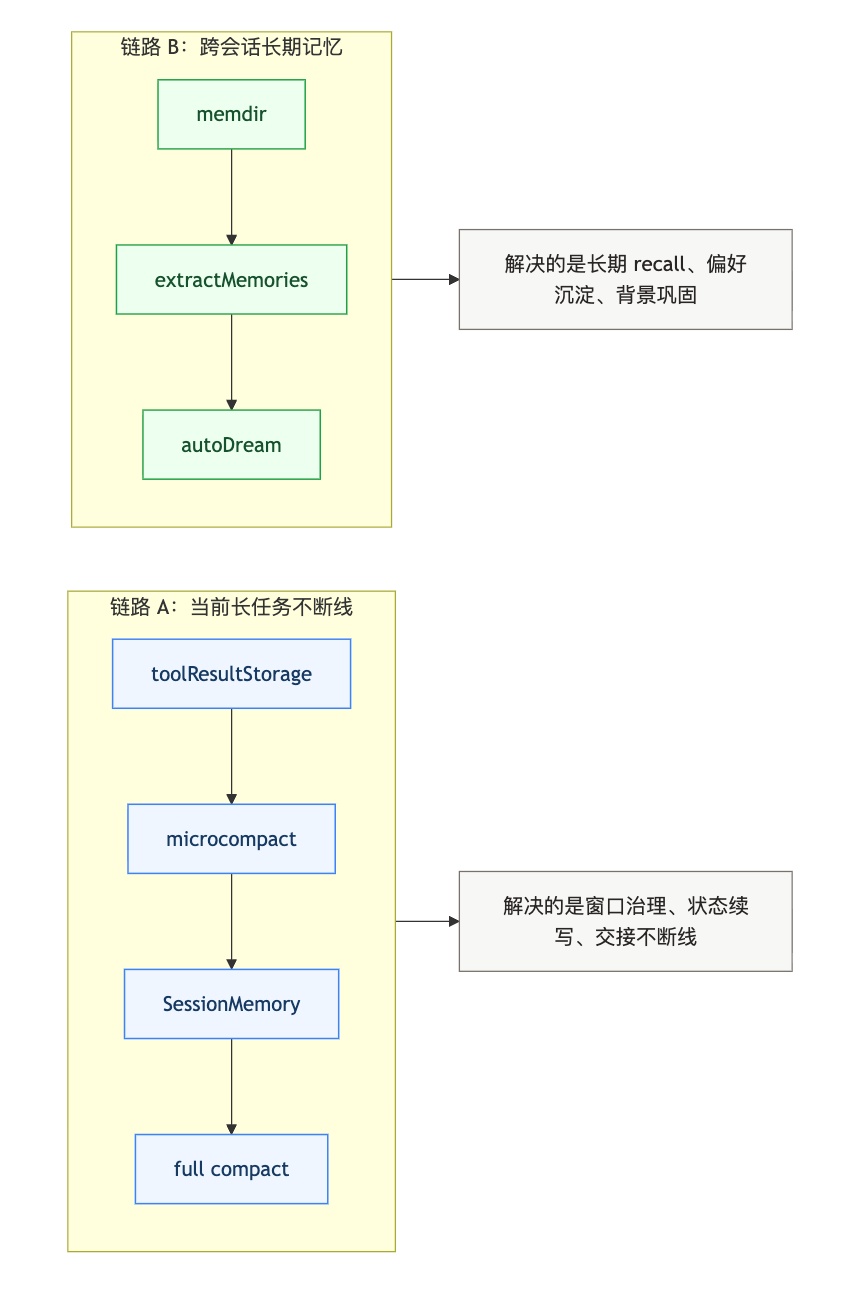
如果按更宽泛的口径去数,大概可以这样看:
- 大工具结果落盘到
tool-results/ microcompactSessionMemory- full compact
memdir文件型长期记忆- turn-end
extractMemories - 后台
autoDream
但这 7 层里,真正属于长期记忆核心的,其实主要是后面三层。
头几层更多是在解决另一件事:
上下文窗口快撑爆时,怎么让当前工作不断线。
这次的主线,也应该收在这里。
先别把“长上下文”当答案
聊长任务,很多人第一反应是看窗口大小。200k 够不够?能不能再大点?
窗口大小当然重要,但它只回答了一个问题:最多能装多少。
没有回答另一个更麻烦的问题:装进去以后,怎么不乱。
之前聊 Harness 时说过,长任务最容易坏掉的,往往不是单轮推理不够聪明,而是跑着跑着就漂了——目标漂移、过早收工、自我评估偏正面。
Claude Code 的源码让我看到,Anthropic 没有把这些问题只留在论文和 blog 里,而是拆成了几条实打实的机制:
- • 对话太重了,先局部清理
- • 再重一点,做正式 compact
- • compact 以后,补一份结构化工作状态
- • 会话之外,再抽真正值得长期保留的 memory
- • 下一轮开跑前,只把相关的那一小部分拿回来
这和“上下文窗口有多大”已经不是一个层级的问题了。
前者是容量,后者是治理。
第一层:先落盘,再清垃圾,最后才是摘要与兜底
很多产品处理长上下文的方式很粗暴:快满了就总结一遍,塞回去继续跑。
Claude Code 不是这样。看 query.ts 就知道,它至少分了四步,而且每一步干的活不一样。
第零步是 toolResultStorage
之前我写轻了,但回头看源码,这一步其实挺关键。
src/utils/toolResultStorage.ts 和 BashTool.tsx 那几处做的事情很直接:
- • 大工具结果先落盘到 session 目录下的
tool-results/ - • 当前上下文只保留预览
- • 再用
<persisted-output>这种引用方式把“完整结果在文件里”这件事告诉模型
这一步解决的不是记忆问题,是爆炸半径。
很多时候上下文不是被推理撑满的,是被 grep、cat、大段 shell 输出先吃掉了。
Claude Code 的第一反应不是总结,而是先把大块结果从 prompt 里搬出去。
第一步是 microcompact
这层我觉得最有意思。它不是总结整段历史,而是先把那些最容易膨胀、又没必要原样保留的内容清掉。
比如:
- • 旧的
Read结果 - • shell 输出
- •
Grep/Glob/WebSearch/WebFetch的结果 - • 文件编辑和写入的工具结果(
FileEdit、FileWrite)
microcompact.ts 里直接把这些工具列成了 COMPACTABLE_TOOLS。说白了就是:
先把低价值的大块结果清理掉,尽量保住对话主线和最近的工作细节。
打个比方,你桌上堆满了外卖盒和快递箱,最该做的不是整理笔记,而是先把垃圾扔了。
microcompact 干的就是这个。
第二步是 autocompact
垃圾清完还是不够用呢?这时候才轮到正式 compact。
autoCompact.ts 里做得挺实在:
- • 先按模型 context window 预留 compact 输出空间
- • 再减掉一段 buffer
- • 只有超过阈值才触发
- • 连续失败还有 circuit breaker,避免 session 在不可恢复状态下疯狂重试
不是“上下文快满了就赌一把摘要”,而是带预算控制的运行时决策。
第三步是 reactiveCompact
如果前面几步都没挡住,真打到了 prompt too long——系统还有最后一道防线:reactive compact。
到了这一步,已经不关心摘要质量了。
它只关心一件事:这轮能不能活下来。
把这几层放在一起看,会更直观:
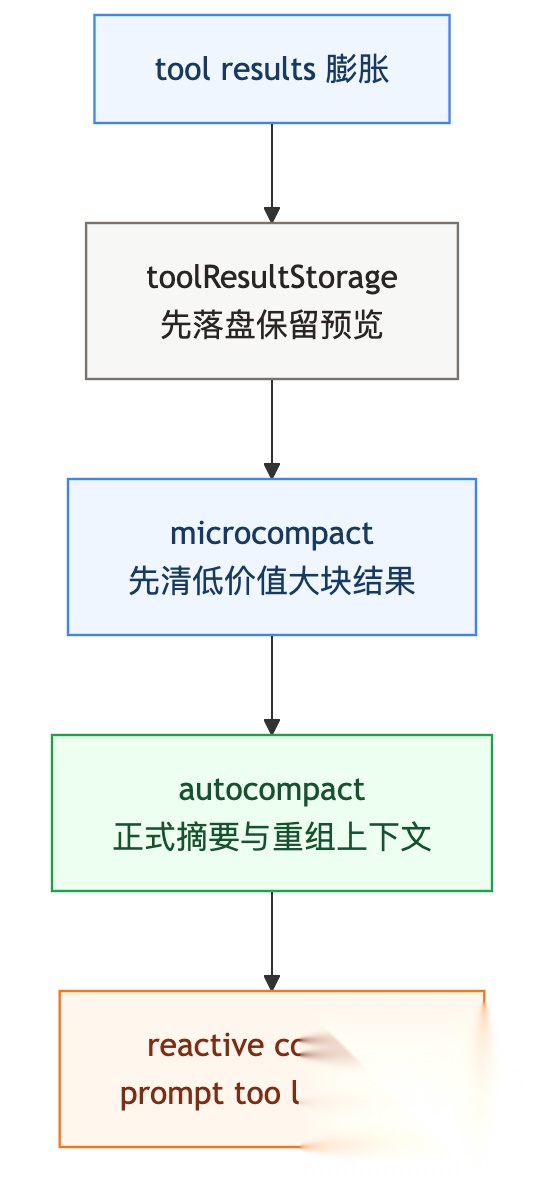
顺便说一个细节,services/compact/prompt.ts 里对 compact agent 的要求非常凶:
- • 只能输出文本
- • 不准调用任何工具
- • 你已经拥有所需上下文
- • 如果浪费这一次 turn 去调工具,就算失败
这个设计选择挺说明问题的。
Anthropic 没有把 compact 当成“顺便让模型概括一下”,而是当作一段受约束的、必须稳定返回的系统流程。
你再想想那些“上下文太长了,来段总结吧”的产品,就知道差距在哪了。
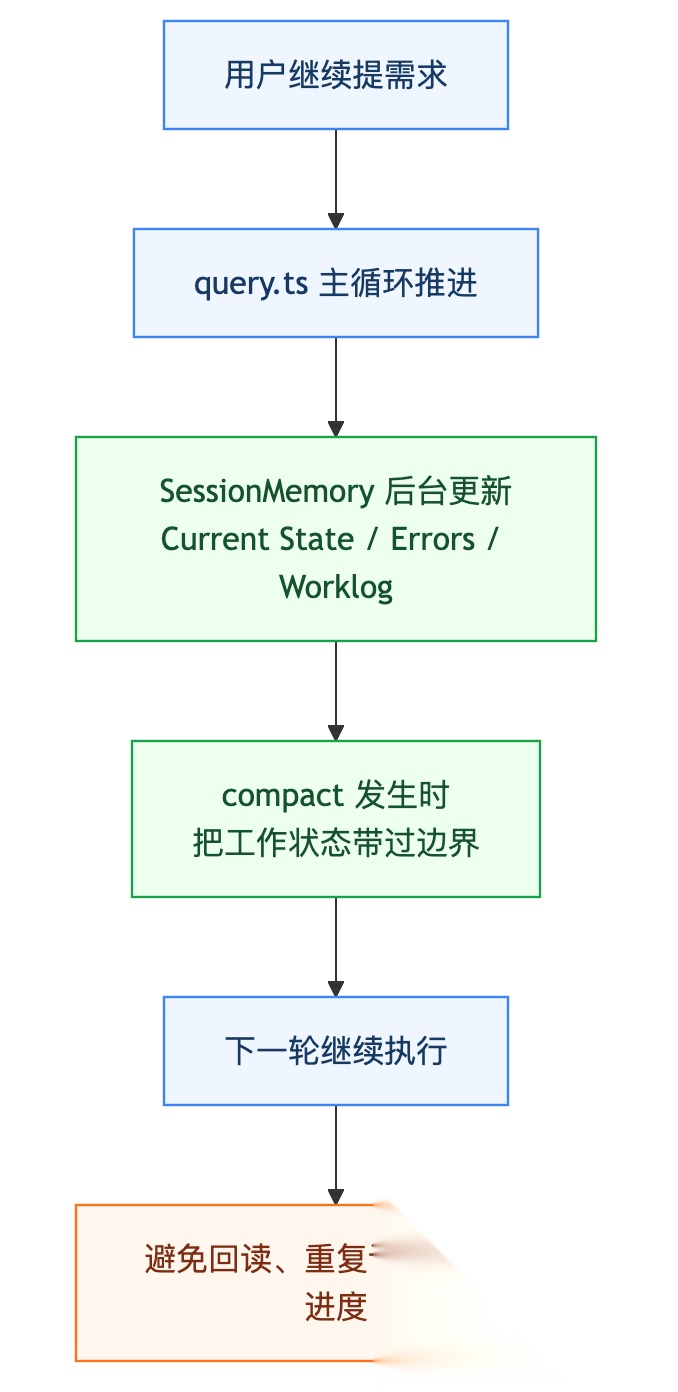
第二层:compact 解决不了交接,所以它又造了 SessionMemory
光有 compact 其实还差一截。
你想想,摘要写得再好,它告诉你的也只是“前面聊了什么”。但长任务跑着跑着丢掉的,往往不是历史,而是“现在做到哪了,下一步该干什么”。
这也是为什么 src/services/SessionMemory/ 这一整组文件值得单独看。
它不负责提供新知识,更像是在维护当前任务的运行状态。
里面那份默认模板很有代表性:
- •
Current State - •
Task specification - •
Files and Functions - •
Workflow - •
Errors & Corrections - •
Codebase and System Documentation - •
Learnings - •
Key results - •
Worklog
更关键的是,它不是到 compact 才临时生成。
从 sessionMemoryUtils.ts 和 sessionMemory.ts 看,默认行为大致是这样:
- • 上下文 token 数先超过 10,000,才初始化 SessionMemory
- • 之后至少再增长 5,000 token,才考虑下一次更新
- • 同时还会看工具调用数,默认是 3 次
- • 如果上一轮已经到了一个相对自然的停顿点,即便没堆满工具调用,也可能触发更新
也就是说,SessionMemory 更像一份后台持续维护的工作笔记,而不是“compact 时顺手补一段摘要”。
看看这些字段就知道了,这哪是什么“会话记忆”。
这就是一份交接文档。给下一个 agent 看的,给下一轮压缩看的,也是给下一个“自己”看的。
这里面我最在意两件事。
一是 Current State 必须反映最新进度。
二是 Errors & Corrections 单独列了一个章节。
这两条一加,整个东西的味道就不一样了。
长任务里最怕丢的,不是最终答案,是过程中那些“做到哪了”和“踩过什么坑”。
一旦丢了,下一轮就会:
- • 又去读同一批文件
- • 又走一遍已经失败的路
- • 把“做到一半”误判成“快完了”
SessionMemory 的价值不是“多存一份摘要”,而是把长任务里最容易丢的那些状态,变成了结构化的东西,丢不了。
再补一点。
SessionMemory 和 compact 不是一回事。
compact 负责缩短历史。SessionMemory 负责续住工作。
虽然都跟“记忆”沾边,但在工程上完全是两个系统。
它们之间的关系,可以压成这样一条链:
第三层:长期记忆不是越多越好,而是只保留以后真会用到的东西
上面两层解决的是“当前任务别断线”。
再往后看,还有更长线的一层:跨会话记忆。
这一层我分成三块看:memdir、extractMemories、autoDream。
先看 memdir
Claude Code 的长期记忆不是数据库,也不是向量库。
从 src/memdir/ 这一层看,它首先就是一套文件系统方案:
- • 每个项目一套 memory 目录
- •
MEMORY.md作为入口索引 - • 具体记忆拆成一个个 topic 文件
这里有两个事实,源码里直接就能看到:
第一,MEMORY.md 只是 index,不是正文存储。
第二,它有 200 行和 25KB 的硬上限,超了就会被截断。
你可以把它想象成一本很薄的目录——不是百科全书,只是一页纸的索引,指向真正值得翻的东西。
另外,memory type 也不是开放式的。
memoryTypes.ts 只给了 4 类:
- •
user - •
feedback - •
project - •
reference
而且它还明确写了哪些东西不要存:
- • 代码模式
- • 架构结构
- • 文件路径
- • git 历史
- • debugging fix recipe
- • 当前会话里的临时任务状态
这说明 Claude Code 的长期记忆不是“第二份代码库”,而是:
只存那些你没法靠当前 repo、git 和 CLAUDE.md 重新推导出来的信息。
再看 query 时怎么召回
这个点我觉得值得单独说。
Claude Code 的 relevant memory 召回,并不是 embedding 检索。
findRelevantMemories.ts 的做法是:
- • 先扫描 memory 文件头部信息
- • 形成一份 manifest
- • 再发起一次
sideQuery - • 让 Sonnet 从文件名和描述里选出最多 5 个真正相关的 memory
这套方法不如向量库“酷”,但有个好处不能忽略:
它的行为边界很清楚,也很省。
当然,它也有代价。
比如 MEMORY.md 入口太长会被截断,单轮 relevant memory 也只取最多 5 个。这些都意味着 Claude Code 的长期记忆不是无上限的。
但反过来想,Anthropic 要的就不是“永远记住全部”,而是把 recall 预算也控制在系统能承受的范围里。
最后才是 extractMemories
src/services/extractMemories/prompts.ts 里有几个细节,我觉得挺值得琢磨的。
它把 memory 提取交给了单独子代理
而且这个子代理的权限被限制得很清楚:
- • 可以读 memory 目录
- • 可以做受限的只读 bash
- • 可以写 memory 文件
- • 不允许乱跑其他工具
- • 明确说了不要再去 grep 源码,不要做额外验证
意思很明确:
你这次的任务不是继续工作,而是整理记忆。
它只允许基于最近消息更新 memory
prompt 里写得很死:只看最近一段消息,不要重新调查全局。
这个约束特别重要。
因为 memory 系统一旦没有边界,很容易从“提炼经验”变成“重复搬运上下文”,最后越存越多,越存越脏。
它强调“更新已有 memory,不要造重复项”
这背后是一个常被忽略的问题:
很多系统觉得记忆的敌人是“忘了”。但用过就知道,更常见的敌人其实是重复、过时、互相矛盾——记了一堆,到最后不知道该信哪条。
Anthropic 在 prompt 里要求先检查已有记忆,再决定更新还是新增。说白了就是在防 memory 腐烂。
把 query.ts、attachments.ts 和 query/stopHooks.ts 合起来看,链路就更完整了。
Claude Code 在每个 user turn 开始时会 startRelevantMemoryPrefetch,在 stop hook 阶段则会异步触发 extractMemories,两者一前一后。
前者负责 recall,后者负责写入。
而 recall 这一侧,还会通过 filterDuplicateMemoryAttachments 去掉重复项,把真正相关的 memory 以 attachment 的方式回灌给当前这一轮。
也就是说,它不是:
- • 把所有历史记忆全塞回 prompt
而是:
- • 先抽 memory
- • 再筛 relevant
- • 再去重
- • 最后只注入这轮真正需要的那部分
整套做法很像检索系统,但它服务的不是知识问答,而是任务续航。
Claude Code 在做的事,是把“记忆”从一个堆料动作,慢慢收成一个有写入规则、有更新规则、有召回预算的子系统。
autoDream 在更慢的周期里做巩固
还有一层,容易被当成彩蛋,但源码里是正式路径:autoDream。
stopHooks.ts 会在主线程 turn 结束后尝试触发它,而 autoDream.ts 里又明确写了三道 gate:
- 距离上次 consolidation 的时间阈值
- 自上次以来累计了足够多的 session
- 当前没有其他 consolidation 在跑
默认值是至少 24 小时、至少 5 个 session。
所以 autoDream 更像后台慢速整理,不属于这篇“当前长任务怎么不断线”的主路径,但它确实是长期记忆体系的一部分。
前面聊过的 Harness 方法论,到这里差不多落地了
把之前写的几篇连起来看:
之前讲的是原则,这次看到的是实现。
前者说,长任务的核心风险是上下文焦虑、自我评估偏差、交接失真。
后者说,好,那我把它拆成 toolResultStorage、microcompact、autocompact、SessionMemory、memdir、extractMemories、autoDream 这一整套机制。
所以这次真正让我觉得值的,不是“又发现几个隐藏功能”。
是看到 Anthropic 怎么把自己讲过的道理,用代码落地的:
不要把长期稳定性寄托在模型临场发挥上。
能外移成机制的,就外移成机制。
能拆成独立子任务的,就别让主循环全背。
能结构化保存的,就不要只留一段自然语言总结。
能按相关性回灌的,就别把全部历史重新塞回去。
这套思路,和之前聊的 Skills、Spec、Harness、权限管道,其实是同一件事:
把“必须靠模型自己自觉”的那部分面积,尽量缩小。
如果你也在做 Agent,这 6 条可以直接拿走
Claude Code 这套东西不用原样照搬,但里面有几条思路,拿来就能用。
1. 把“压缩历史”和“续写状态”拆成两个系统
很多团队会把这两件事揉成一个“summary”。
Anthropic 明显不这么干。历史摘要和当前状态,服务的是两个完全不同的目标。
2. compact 阶段严格禁工具
compact agent 一旦还能继续读文件、跑命令,就很容易从“收敛上下文”变成“顺便再干点活”,最后把系统拖进不稳定的状态。
3. 给状态续写一个固定骨架
Current State、Errors & Corrections、Worklog 这些字段不是装饰。
它们直接决定了下一轮还能不能沿着正确方向继续跑。
4. memory 只基于最近消息更新
别让记忆提取器拥有“重新理解整个世界”的权限。
那样做听起来更聪明,实际上更容易把噪音、重复和幻觉写进长期记忆。
5. relevant memory 要做召回,不要全量注入
大多数系统的问题不是“没有历史”,而是“历史太多,混在一起”。
先筛,再注入,系统才可能越跑越稳。
再多说一条:
6. 给长期记忆入口加硬预算
MEMORY.md 的 200 行 / 25KB 看起来像限制,其实是一种纪律。
没有入口预算,长期记忆很快就会从“帮助 recall”变成“新的噪音源”。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)