滑跪道歉后,Cursor靠Kimi基模干翻Claude!套壳风波反转:这才是微调的正确姿势?
模型在长任务执行中,会自主总结之前的操作与关键信息,不用全量携带历史上下文,既减少了token消耗,又大幅提升了长周期任务的连贯性,解决了代码Agent最头疼的「做着做着就忘了之前的目标」的问题。Cursor的核心优势,从来不是它有多少算力、多少参数,而是它有全球最大的AI编程用户群体,能从真实用户的使用场景中,拿到最优质的训练数据、最贴合真实需求的基准、最还原的训练环境,形成了。【图5】不同KL
熟悉这场风波的朋友都知道,就在不久前,Cursor还因为被扒出核心模型疑似直接使用Kimi开源模型却未标注来源,陷入了前所未有的信任危机。一边是国内开发者的集体质疑,另一边是海外网友的犀利吐槽:“三步做出一个前沿模型,二步微调一下,第三步声称是自己训练的。”
而这一次,Cursor显然是彻底学乖了。
技术报告开篇第一件事,就是光明正大地致谢:“感谢Kimi K2.5、Ray、ThunderKittens、PyTorch等背后的公司和开源社区,同时感谢Fireworks和Colfax的合作与伙伴关系。”直接把Kimi的名字放在了第一位,态度诚恳到让不少网友调侃:“这滑跪速度,比我跟对象认错还快。”
而这个报告基于Kimi开源基模微调后的模型,在真实代码任务上的准确率,直接超过了Claude 4.6 Opus,直逼行业天花板GPT-5.4。文末附报告链接。
先看成绩单
真实场景里的碾压级表现
Composer 2的核心定位,是专为Agent软件工程设计的专用大模型——它不追求通用能力的全能,而是把所有算力都砸在了真实开发场景下的代码Agent能力上。
先看最核心的成绩,在Cursor团队基于真实开发任务打造的CursorBench基准上,Composer 2拿下了61.3% 的准确率,直接拉开了和主流模型的差距。
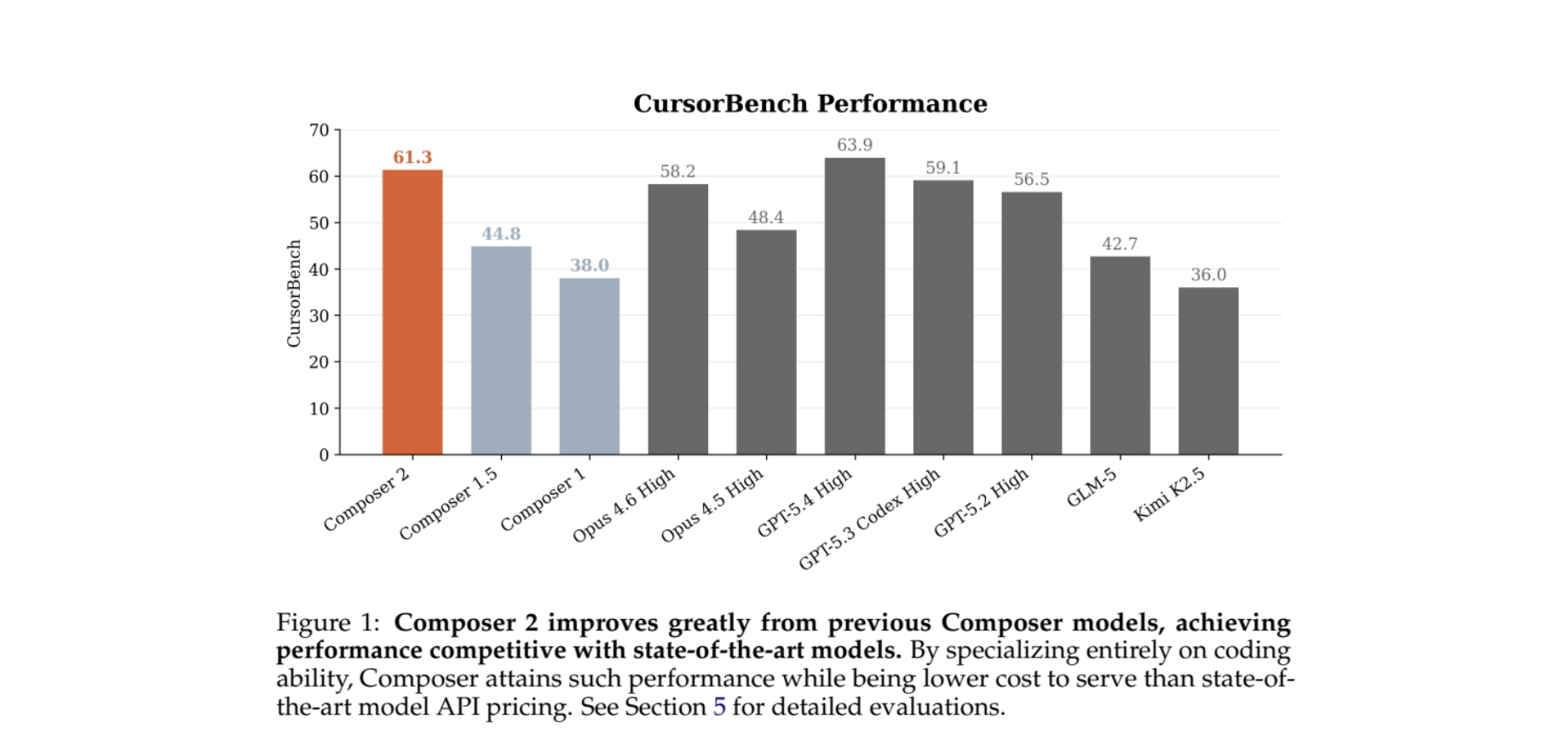
【图1】Composer 2在CursorBench上的得分对比,61.3%的成绩远超前代与主流商用模型,仅次于GPT-5.4(对应报告Figure 1,横轴为参测模型,纵轴为CursorBench准确率,Composer 2以61.3%的得分超过Opus 4.6 High、GPT-5.2、GLM-5等一众模型)
在公开权威基准上,它的表现同样站在了第一梯队:
-
SWE-bench Multilingual:73.7%,相比前代Composer 1.5提升7.8个百分点
-
Terminal-Bench:61.7%,相比前代提升13.8个百分点
最关键的不是分数,而是它实现了成本-性能的帕累托最优。通用大模型要拿到顶级性能,就要付出极高的推理成本;而Composer 2凭借专用优化和MoE架构(1.04T总参数、32B激活参数),在性能对标顶级通用模型的同时,单任务推理成本和小模型的低算力版本相当。
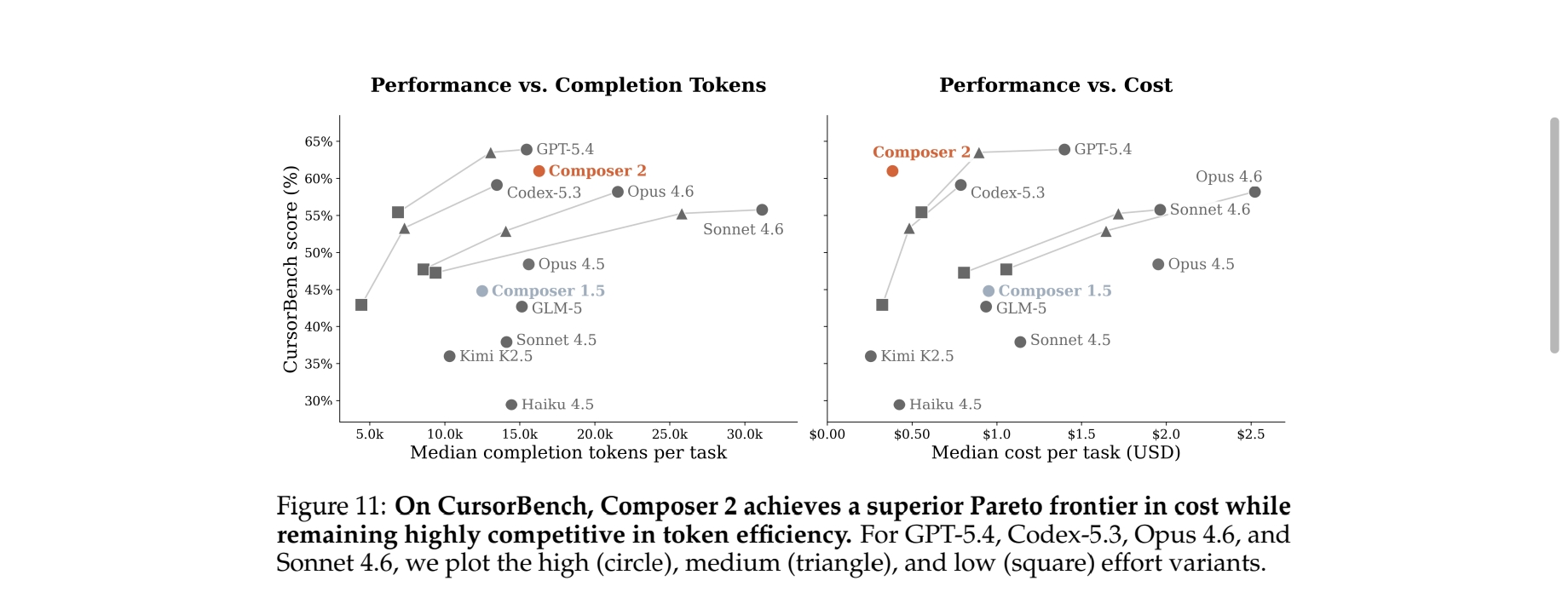
【图2】Composer 2在CursorBench上的成本-性能对比,实现了更高精度的同时,保持了极低的单任务成本(对应报告Figure 11,左图为性能与完成token数的关系,右图为性能与单任务成本的关系,Composer 2位于曲线的最优区间)
核心训练逻辑
两阶段打造专用代码Agent能力
Composer 2的训练分为两个核心阶段:持续预训练筑牢编码知识底座,大规模异步强化学习解锁Agent长周期规划与执行能力。
-
持续预训练:给通用模型「洗个代码澡」
很多人以为代码模型的核心是RL,但报告用数据证明:扎实的领域持续预训练,直接决定了下游RL的上限。
Composer 2没有从零训基座,而是在对比了DeepSeek V3.2、GLM-5等开源模型后,最终选择了Kimi K2.5作为底座——这是一个1.04T总参数、32B激活参数的混合专家(MoE)模型,在编码知识、状态跟踪、代码库困惑度三项核心评估中表现最优。
在此基础上,团队做了三阶段的持续预训练:
-
主体训练:以32k序列长度,在大规模代码主导的数据集上完成核心训练,筑牢编码知识底座
-
长上下文扩展:用更短的训练周期,把上下文窗口扩展到256k,适配大代码库的全量理解需求
-
针对性SFT:在精选的编码任务上做有监督微调,对齐代码Agent的输入输出格式
【图3】持续预训练的效果验证:代码库困惑度的线性下降,直接对应下游强化学习的性能提升(对应报告Figure 2,左图为预训练损失与RL奖励的正相关关系,右图为训练过程中困惑度的稳定下降)
同时,团队还训练了多token预测(MTP)层,配合投机解码大幅提升生产环境的推理速度,让模型在能力提升的同时,保持了流畅的交互体验。
2.异步强化学习:解锁代码Agent的核心能力
如果说持续预训练是给模型打基础,那强化学习(RL)就是让它从代码生成器变成软件工程Agent的核心。
Composer 2的RL训练,完全模拟了Cursor的真实生产环境——训练用的工具、环境结构、交互逻辑,和用户实际使用的版本完全一致,最大程度缩小了训练和真实场景的gap。
首先是训练任务的分布,完全覆盖了真实软件工程的全流程,而不是像公开基准那样只聚焦单一的Bug修复:

【图4】RL训练的任务类别分布,覆盖功能迭代、Debug、新功能开发、重构、代码理解、文档、测试、Code Review等全场景(对应报告Figure 3,横轴为任务类别,纵轴为任务占比,完整还原了真实开发的工作流)
在算法层面,团队针对代码Agent的长周期、高复杂度特性,做了大量关键优化:
-
基于GRPO算法做了核心改进:去掉了长度标准化项,避免模型偏向短输出;不做组内优势的标准差归一化,避免全正确样本里的微小差异被过度放大
-
放弃了超长序列masking,改用自总结机制解决长上下文问题,避免输出长度不受控的问题
-
KL正则化选用更稳定的k1估计器,解决了常用的k3估计器在策略差异大时方差爆炸的问题,保证了大规模训练的稳定性
【图5】不同KL散度估计器的方差对比,Composer 2选用的k1估计器在KL值较大时,方差远低于行业常用的k3估计器(对应报告Figure 4,横轴为KL值,纵轴为估计器方差,清晰展示了k1估计器的稳定性优势)
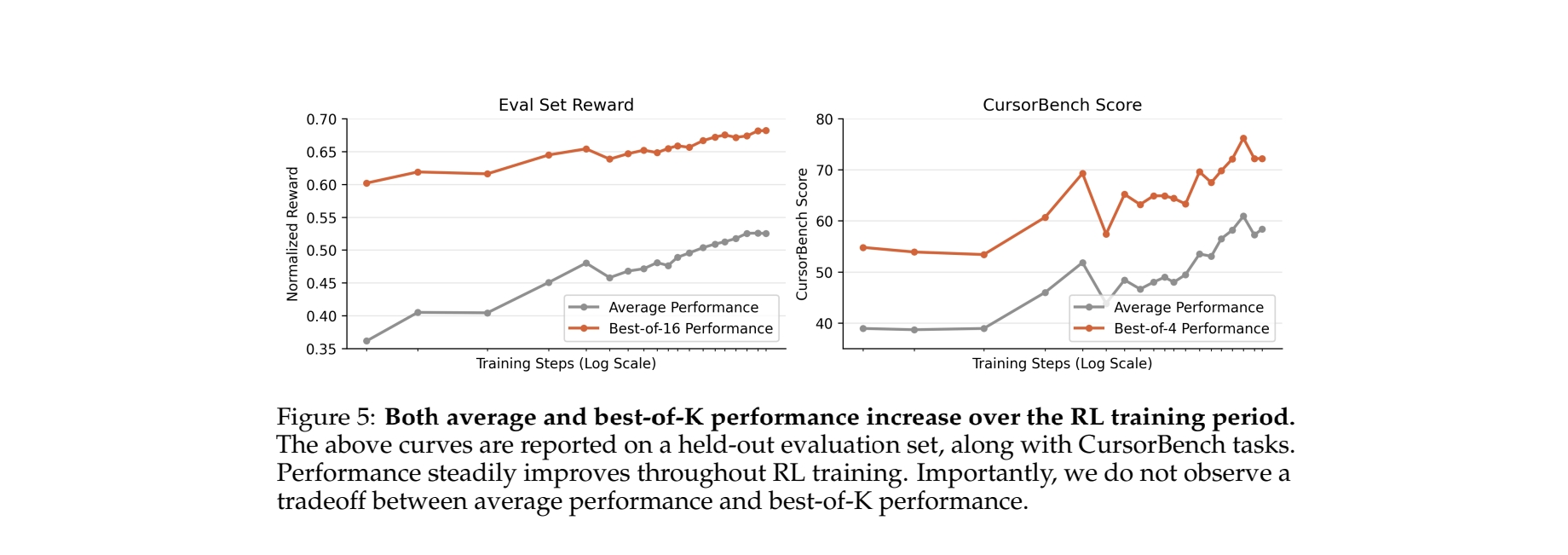
最值得关注的一个突破是:Composer 2的RL训练,同时提升了模型的平均性能和best-of-K性能,打破了行业内RL只会让模型收敛到已知正确路径,牺牲多样性的质疑。
【图6】 RL训练过程中,平均性能与best-of-K性能同步提升,证明RL不仅是收敛路径,更拓展了模型的正确解覆盖范围(对应报告Figure 5,横轴为训练步数,纵轴为奖励/准确率,平均性能与多采样最优性能同步稳定上涨)
除此之外,团队还延续了Composer系列的核心创新——自总结(Self-Summarization)机制:模型在长任务执行中,会自主总结之前的操作与关键信息,不用全量携带历史上下文,既减少了token消耗,又大幅提升了长周期任务的连贯性,解决了代码Agent最头疼的「做着做着就忘了之前的目标」的问题。
为了对齐真实开发体验,团队还设计了非线性长度惩罚:简单任务上,模型会被激励快速输出、减少冗余操作;复杂任务上,模型可以获得更长的思考与操作空间,不会因为步骤多被过度惩罚,真正实现了简单问题不啰嗦,复杂问题不敷衍。
【图7】非线性长度惩罚曲线,横轴为加权token数,纵轴为惩罚权重,让模型在不同难度任务上有合理的行为选择(对应报告Figure 6,展示了不同曲率的非线性惩罚曲线,实现了对模型行为的精细化调控)
CursorBench
戳破公开基准的「刷分泡沫」
这份报告里最有行业价值的部分,除了模型本身,就是Cursor团队推出的CursorBench基准——它直接解决了当前代码模型公开基准的四大核心痛点:
-
领域不匹配:SWE-bench等基准只聚焦孤立的Bug修复,完全覆盖不了真实开发的重构、新功能开发、DevOps等全场景
-
Prompt过度指定:公开基准的任务描述极其详细,甚至直接给出了解决方向,而真实用户的需求往往是模糊、不完整的
-
数据污染:公开基准的任务都来自开源仓库的历史数据,早已被各大模型的训练集收录,OpenAI甚至已经停更了SWE-bench Verified的结果,因为模型已经能靠记忆生成标准答案
-
评估维度窄:只看功能是否正确,完全忽略了代码质量、可读性、执行效率、交互体验等真实开发中最看重的维度
而CursorBench的所有任务,都来自Cursor工程团队的真实编码会话,完全避免了训练集污染,同时更贴近真实开发的本质:
-
任务修改量更大:中位数修改181行代码,而SWE-bench只有7-10行,差了整整一个数量级
-
需求更真实:Prompt中位数只有390个字符,而公开基准是1185-3055个,更像真实用户的极简需求描述
-
评估维度更全:除了功能正确性,还覆盖代码质量、执行效率、交互行为、指令遵循能力等多个维度
【图8】CursorBench与公开基准的核心差异对比,左图为参考diff的代码修改行数,右图为问题描述长度(对应报告Figure 7,清晰展示了CursorBench任务修改量更大、prompt更短的核心特点)
我们可以通过两个示例任务,直观感受到CursorBench的难度与真实性:
【图9】CursorBench示例任务1:仅通过极简Bug报告+生产日志,需要模型定位esbuild转译导致的重试循环状态污染问题(对应报告Figure 8,展示了真实生产环境中的复杂Bug诊断任务)
更重要的是,CursorBench一直在持续迭代,最新的CursorBench-3,平均修改代码行数比初始版本翻了一倍多,始终匹配真实开发的难度提升,不会出现模型刷分饱和的问题。
【图10】CursorBench的迭代演进,最新版本的平均修改代码行数、修改文件数,相比初始版本均有翻倍提升(对应报告Figure 9,展示了CursorBench随开发场景演进的难度升级)
代码模型的未来,是「专用化」
看完这份完整的技术报告,我们能得到三个最核心的行业启示:
第一,垂直领域的专用模型,正在迎来爆发期。Composer 2用事实证明,在代码这个垂直领域,基于优质通用底座,加上领域持续预训练+针对性强化学习,完全可以做出「性能对标顶级通用模型、成本低一个数量级、体验更贴合场景」的专用模型。未来,不止是代码,法律、医疗、教育等各个垂直领域,都会出现这样的专用模型。
第二,代码Agent的核心,是长周期规划与执行能力,而不是单步代码生成。现在很多AI编程工具,还停留在「用户写一句,模型补一段」的autocomplete阶段,而Composer 2的所有优化,都围绕着「让模型自主完成一个完整的、长周期的软件工程任务」——这才是AI编程的下一个时代。
第三,真实场景的闭环,才是模型的核心护城河。Cursor的核心优势,从来不是它有多少算力、多少参数,而是它有全球最大的AI编程用户群体,能从真实用户的使用场景中,拿到最优质的训练数据、最贴合真实需求的基准、最还原的训练环境,形成了「产品-数据-训练-产品」的正向闭环。这是只做通用大模型的厂商,永远无法比拟的优势。
写在最后
其实回看Cursor这场风波,从被全网群嘲的“套壳者”,到被业内认可的“微调标杆”,核心的转变从来不是技术本身,而是对开源的敬畏之心。Cursor用一份署名清晰、数据详实的技术报告证明了:好的二次开发,同样值得被尊重。
AI工具的进化永远不会停止,手写代码的时代或许终将改写,但开源世界最核心的精神——对技术的敬畏,对同行的尊重,对分享的初心,永远不会过时。
-
官方原版PDF指南:https://cursor.com/resources/Composer2.pdf
从开源底座的二次创新,到代码Agent的落地突破,AI行业的每一步进阶都离不开同行者的交流与共建。AES峰会,正是为所有心怀热爱的从业者打造的交流平台,邀你一同共探AI技术的无限可能
现在,我们诚邀您亲临2026 智能体工程峰会(Agent Engineering Summit 2026)现场,与数千位技术管理者、一线AI实践者共同探讨AI时代研发体系的进化之路。
与其旁观智能体浪潮,不如站在风口躬身入局
AES峰会早鸟票开售,邀你共赴这场技术盛宴

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)