claude省钱方式-怎么花更少的tokens获得更好的体验?
假设它们是公用的,那为什么不放到总的环境设置中进行维护?假设,你现在两次发给claude的问题本就是上下文相关的,比如第一个问题要求完成功能1.1 第二个问题要求完成功能1.2,而功能1.1和1.2是强相关的,这下子,/clear就不合适了。对于不同的project,在不同的project维护各自的CLAUDE.md文件、.claude文件夹。这是最有效的指令,直接一键清空上下文,当然(它和重新打
文章目录
使用大模型怎么用更少的tokens办好事??
1.首先,怎么知道自己的tokens都花在什么地方了?
我们先/clear下,清空上下文信息,然后输入/context查看什么都不干的情况下,大模型需要多少的tokens:
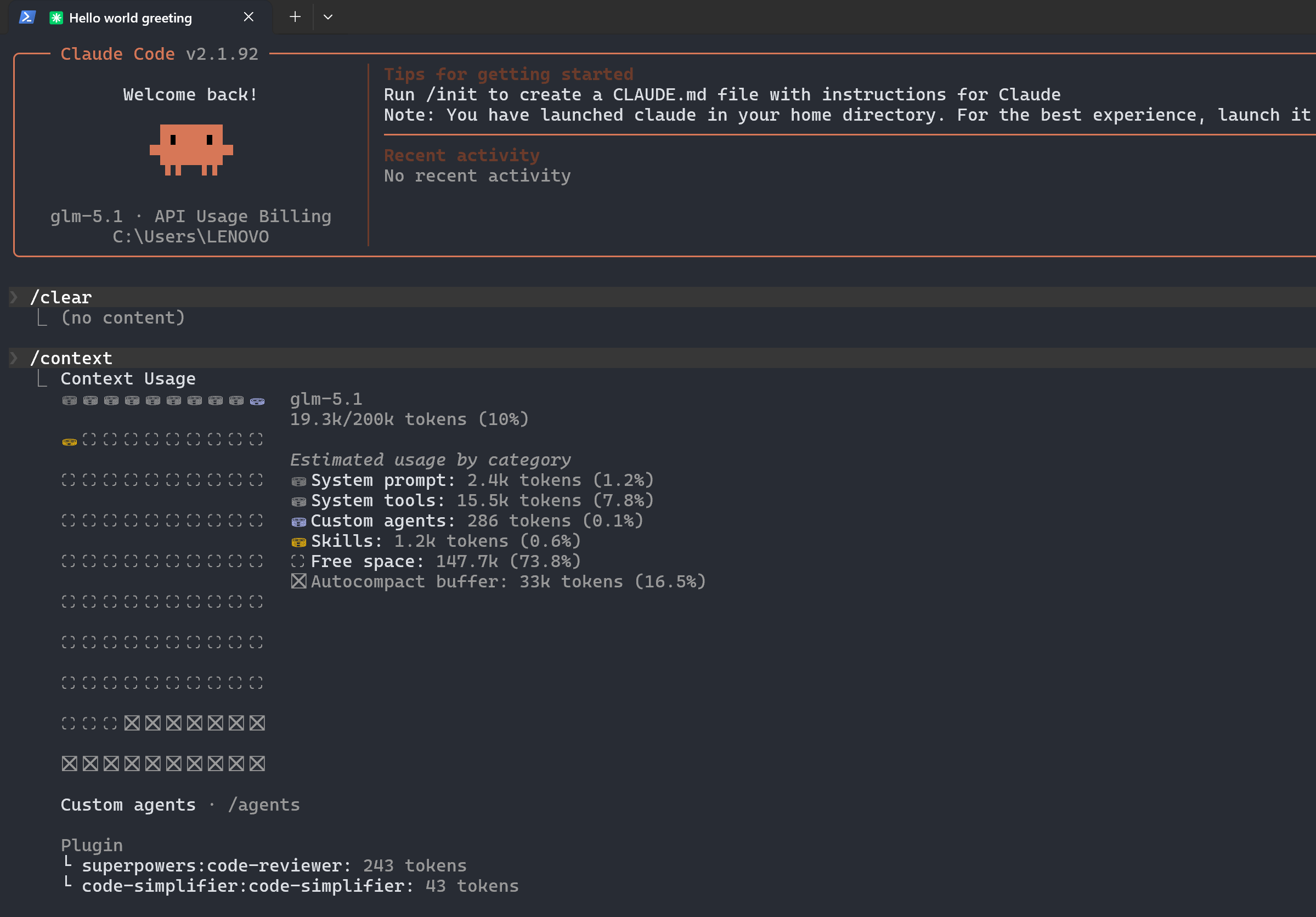
好了,这下我们就能知道,哪怕什么都不用,我们其实就会花费
2.4k+15.5k+1.2k + 286 = 19.3k tokens!
让我们简单操作下,看下执行依据 hello要花费多少:
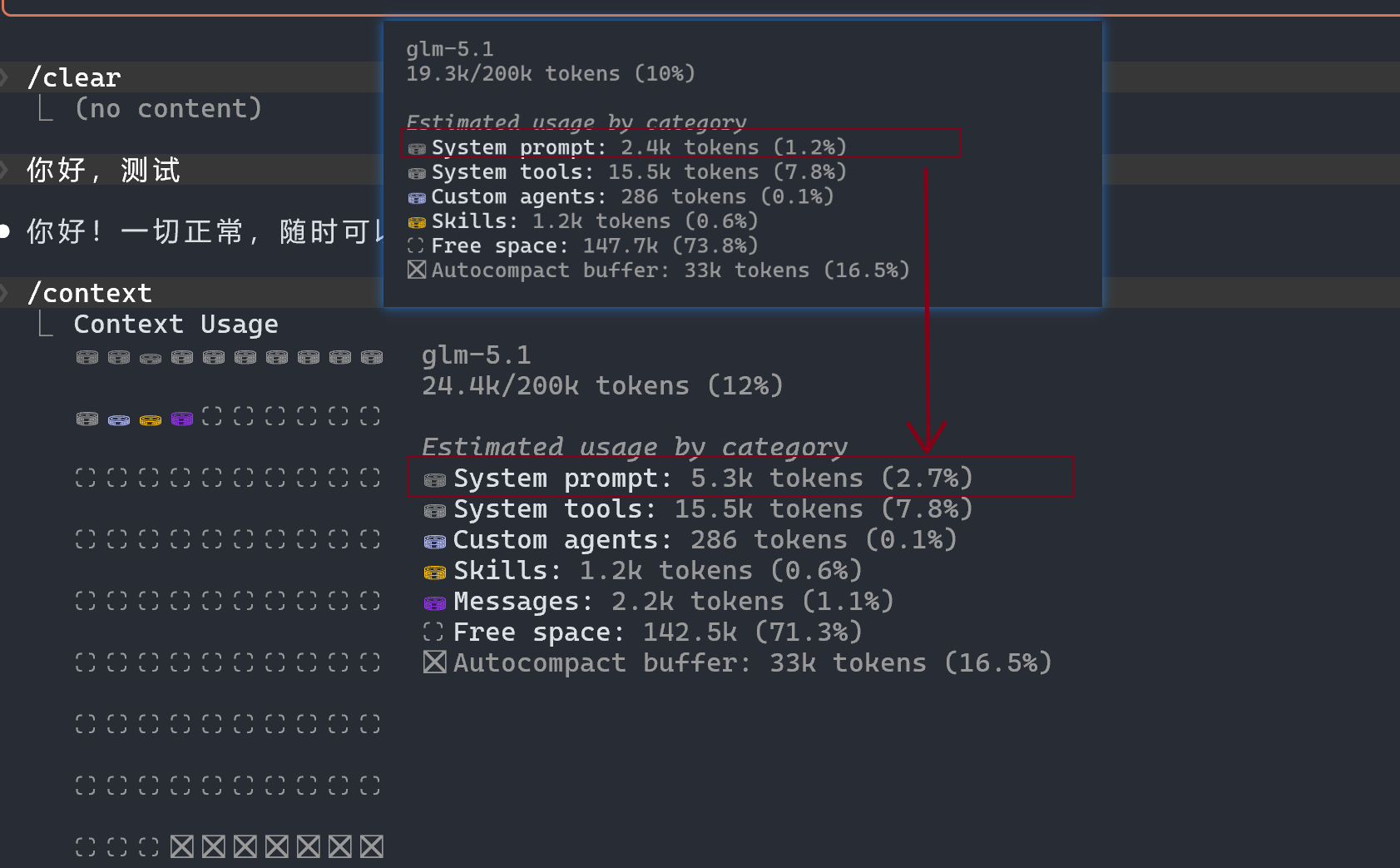
5.3k+15.5k+1.2k = 24.4k tokens!
这下我们知道,真正打个招呼其实用了 5.3 - 2.4 = 2.9K tokensl.
那么你可能就会有疑问了,这里最占大头的systems tools是什么?为什么它要15.5k??
2.但是在其他的场合中,要怎么避免tokens消耗过快呢?
2.1 /clear
这是最有效的指令,直接一键清空上下文,当然(它和重新打开一个claude界面是一样的效果)。
为什么呢?
假设第一次提问,你发给claude:苹果是红色的吗?
claude回复:11k tokens
第二次提问,你发给claude: 特朗普打伊朗的原因?
好,那么此刻,claude会做什么呢?
claude会将 苹果是红色的吗? + 第一次提问回复的11k tokens + 特朗普打伊朗的原因? 全部打包重新发到官网!即传给大模型的input tokens 会瞬间暴涨到11k+ tokens!!那么这样来回10次,哪怕是个简单的问题,也会直接耗尽100w tokens!
这下知道为什么claude的tokens消耗越来越快了吧!
2.2 /compact
假设,你现在两次发给claude的问题本就是上下文相关的,比如第一个问题要求完成功能1.1 第二个问题要求完成功能1.2,而功能1.1和1.2是强相关的,这下子,/clear就不合适了。
可以执行 /compact,这样大模型就会自动去提炼,将长长的上下文进行压缩了。/compact执行完会清爽很多!
2.3 settiong.json文件设置
在settions.json (Linux环境下是 ~/.claude/settions.json,windows对应的是 C:/users/用户名/.claude/settings.json)进行设置:
添加以下两行:
“CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC”: “1”, ## 关闭不必要通信,类似浏览器cookies
“MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES” : “3” # 连续3次失败就停止尝试
{
"autoUpdatesChannel": "latest",
"enabledPlugins": {
"claude-md-management@claude-plugins-official": true,
"code-simplifier@claude-plugins-official": true,
"commit-commands@claude-plugins-official": true,
"superpowers@claude-plugins-official": true
},
"env": {
"ANTHROPIC_AUTH_TOKEN": "{你的API KEY}",
"ANTHROPIC_BASE_URL": "http://8.145.56.52:80",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5",
"ANTHROPIC_MODEL": "glm-5.1",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1" ## 关闭不必要通信,类似浏览器cookies
},
"MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES" : "3" # 连续3次失败就停止尝试,
"model": "opus[1m]"
}
2.4 专项专立
对于不同的project,在不同的project维护各自的CLAUDE.md文件、.claude文件夹。
创建CLAUDE.md文件是为了让claude每次进入这个项目都能快速地理解整个项目,而不是每次都花费大量的tokens去重新读取整个项目。
而创建不同的.claude文件夹则是在不同的project下可以配置不同的skills、mcp。想想,为什么project1要去额外加载project2中需要的技巧呢?假设它们是公用的,那为什么不放到总的环境设置中进行维护?

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)