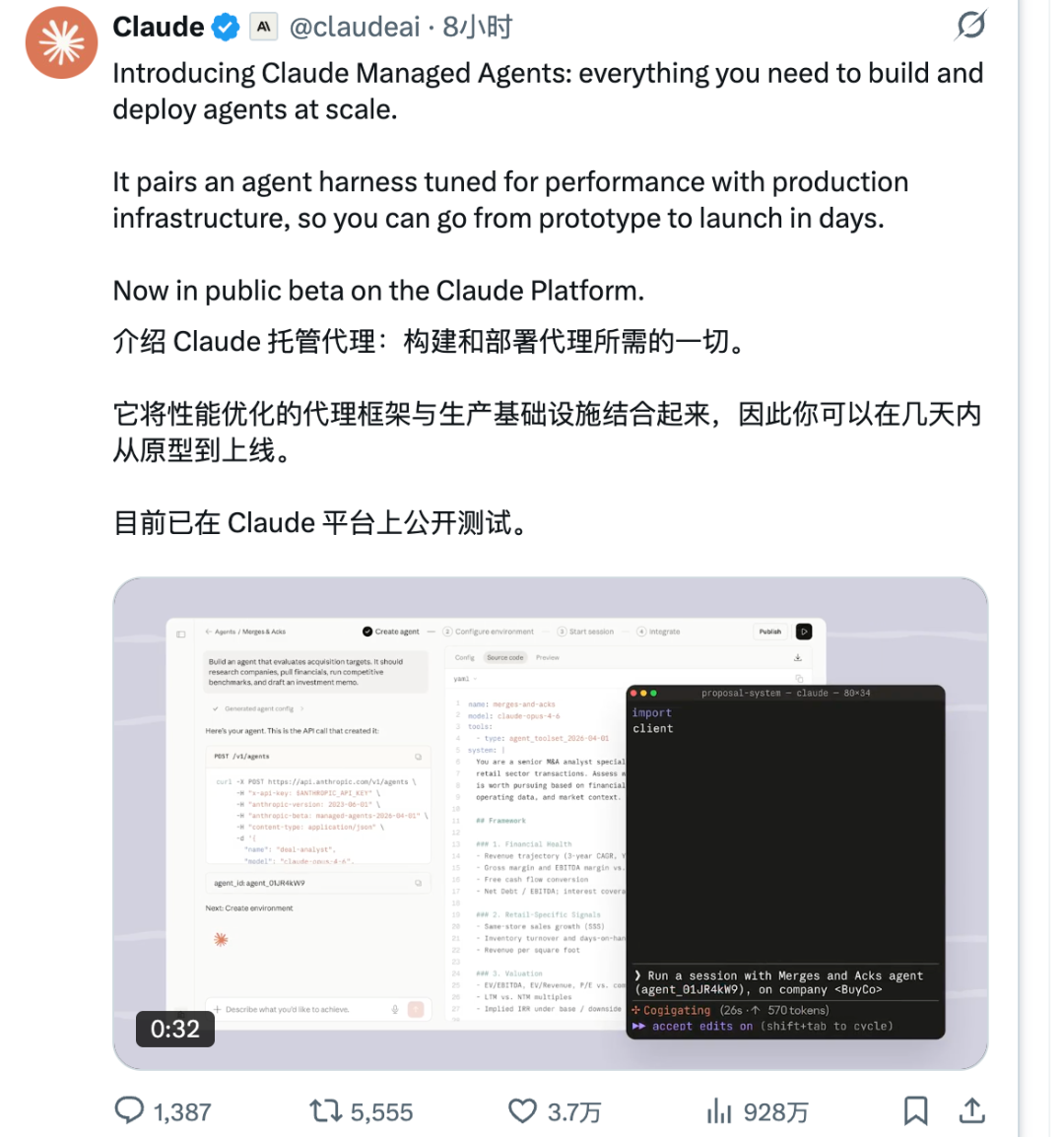
Anthropic突然出手!Claude Managed Agents上线,AI基础设施「AWS时刻」正式到来
AI生成的代码跑在沙盒里,访问外部系统的凭证存在沙盒外的「保险箱」里,两边物理隔离。有人说这是「降维打击」,有人说这是「AI领域的AWS时刻」,还有人说——做智能体中间件的创业公司,可以开始准备B计划了。在工程、产品、销售、市场、财务各部门都部署了专项智能体,每个一周内上线,通过Slack和Teams接任务,交回来的是表格、PPT、App这些实际交付物。,短期内最直观的感受可能是:你用的那些Saa
一句话:Anthropic要替你把智能体基础设施全包了——从沙盒到凭证管理,从状态恢复到多智能体调度。企业级AI智能体,真的要平民化了。
就在刚刚,Anthropic宣布旗下产品 Claude Managed Agents 正式进入公测。消息一出,AI基础设施圈立刻炸锅。有人说这是「降维打击」,有人说这是「AI领域的AWS时刻」,还有人说——做智能体中间件的创业公司,可以开始准备B计划了。
|
关键数字 |
说明 |
| 年ARR突破300亿美元 |
是去年12月的3倍,大部分增长来自企业客户 |
| 首次响应延迟中位数降60% |
极端情况降超90% |
| Sentry数周上线 |
从立项到全流程自动化,省掉持续维护基础设施的开销 |
这到底是什么?和Claude Code有什么区别?
如果你用过Claude Code,你已经见过AI智能体的工作方式:给它一个任务,它自己规划步骤、调用工具、写代码、改文件,一步步把事做完。
区别在于:
-
• Claude Code跑在你的电脑上——给开发者个人用的命令行工具,关机即停。
-
• Managed Agents跑在Anthropic的云上——给企业用的API服务,24小时不间断,断线不丢进度,产品可以直接内嵌智能体能力。
核心定义: 你告诉Anthropic你要什么样的AI智能体,它帮你在云端跑起来,基础设施全包,按用量收费。沙盒、凭证管理、状态恢复、权限控制、全链路追踪——全部开箱即用。
对企业意味着什么?一个能上线的智能体,远不止「调一下API」那么简单。以前需要专职工程师团队搭好几个月的东西,现在直接拿来用。
几种典型用法:
-
• 事件触发型: 系统发现bug,自动派智能体修复并提PR,中间不需要人介入。
-
• 定时型: 每天早上自动生成GitHub活动摘要或团队工作简报。
-
• 即发即忘型: 在Slack里给智能体派个活,它做完把表格、PPT、App交回来。
-
• 长时间任务型: 跑几个小时的深度研究或代码重构。
谁在用?怎么用的?
Notion 让用户在工作区直接把编码、做PPT、整理表格这些活扔给Claude,几十个任务并行跑,整个团队在同一个输出上协作。产品经理Eric Liu说,用户可以把开放式的复杂任务直接委托出去,不用离开Notion。
Sentry 做了「从发现bug到提交修复代码」的全自动流程。AI debug工具Seer找到问题根因后,Claude直接写补丁、开PR。工程总监说,几周就上线了,还省掉了持续维护自建基础设施的运营开销。
Atlassian 把它接进了Jira,开发者可以直接在看板里把任务分配给Claude智能体,跟人一样认领工单。
Rakuten 在工程、产品、销售、市场、财务各部门都部署了专项智能体,每个一周内上线,通过Slack和Teams接任务,交回来的是表格、PPT、App这些实际交付物。
最有意思的是法律科技公司 General Legal:他们的智能体能根据用户提问,临时写工具来查数据。以前每个用户问题都要提前预判并开发检索工具,现在智能体自己按需生成。CTO说开发时间缩短了10倍。
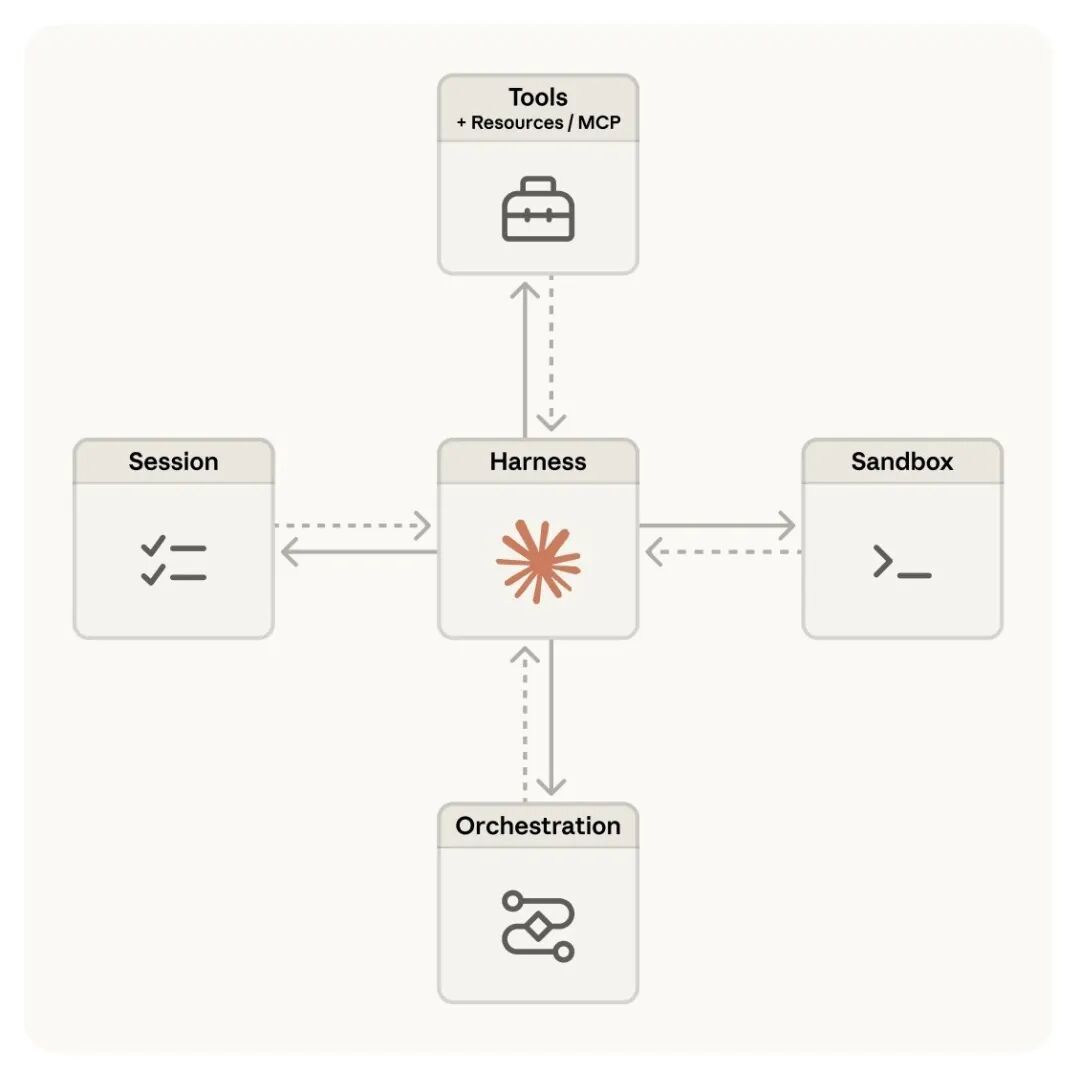
技术上怎么做到的?「大脑和手分开」
Anthropic工程团队写了一篇博客,标题叫《大脑与手的分离》。这个架构思路是整个产品的核心。
最早他们把所有东西塞进一个容器:AI的推理循环、代码执行环境、会话记录,全在一起。好处是简单,坏处是鸡蛋全在一个篮子里——容器一挂,整个会话就丢了。
后来他们做了一个关键拆分:
┌────────────────────────────────────────┐
│ 大脑(Brain) │
│ Claude模型 + 调度框架 │
│ 负责思考、规划、决策 │
└────────────────────────────────────────┘
↓ ↓
┌──────────────────┐ ┌──────────────────┐
│ 手(Hands) │ │ 记忆(Memory) │
│ 沙盒执行环境 │ │ 独立会话日志 │
│ 按需启动 │ │ 任意层崩溃不丢失 │
└──────────────────┘ └──────────────────┘三者互不依赖,任何一个出问题都不影响其他两个。
快
不是每个任务都要启动完整的沙盒环境。AI真正需要跑代码时才按需启动,首次响应延迟中位数降了约60%,极端情况降超90%。
安全
AI生成的代码跑在沙盒里,访问外部系统的凭证存在沙盒外的「保险箱」里,两边物理隔离。AI全程不经手真实凭证——它用git push/pull操作代码,但Token对它不可见。Slack、Jira等服务通过MCP协议接入,请求经过代理层,代理层去保险箱取凭证,AI不接触。
灵活
大脑不关心手是什么。工程博客里有句话值得反复咂摸:
「调度框架不知道沙盒到底是一个容器、一部手机、还是一个宝可梦模拟器。只要符合'名字和输入进去,字符串出来'的接口就行。」
这意味着:模型升级了换大脑;需要新工具加一双手;存储方案改了替换记忆层。就像操作系统的 read() 命令不关心底下是1970年代的磁盘还是现代SSD——抽象层稳定了,底下的实现随便换。
一个关键洞察:为什么自己搭「Harness」是徒劳的?
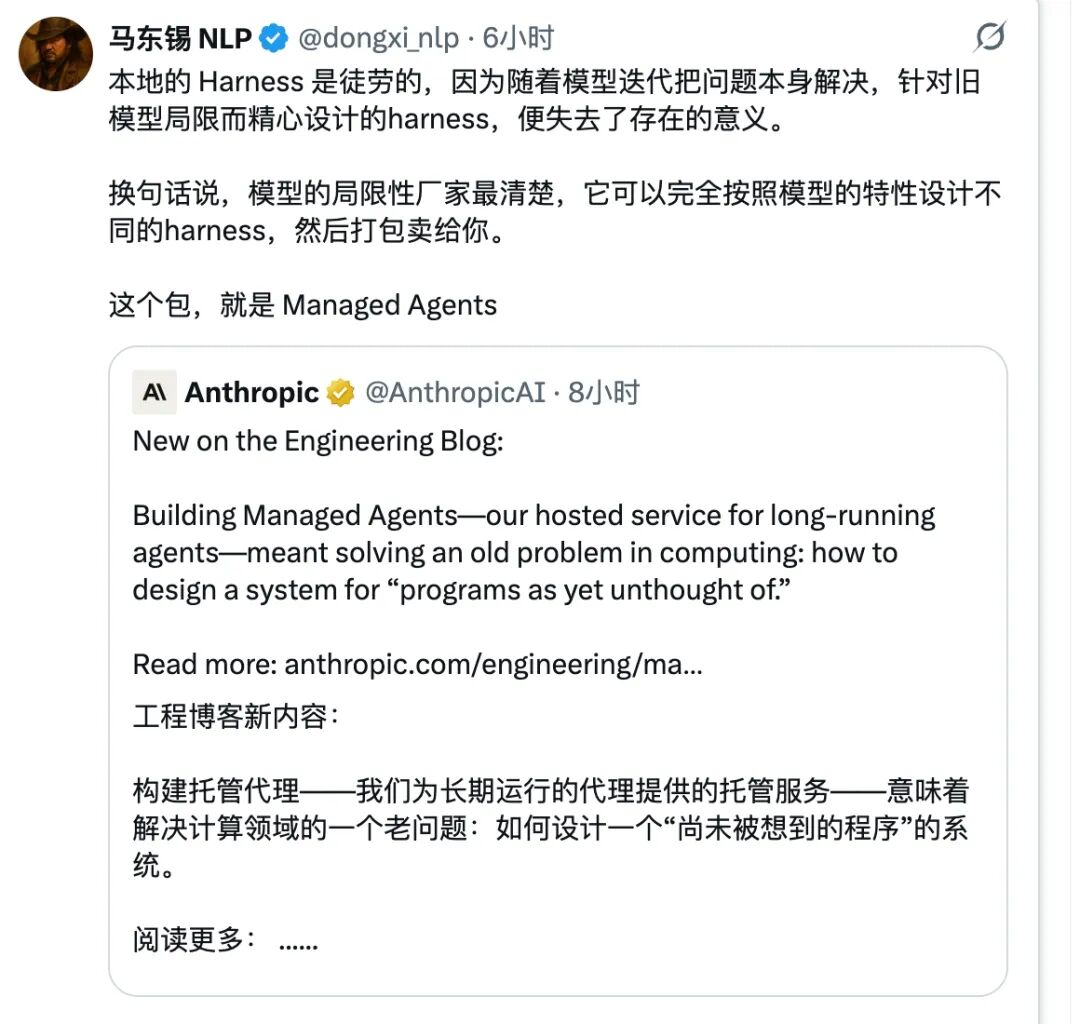
「本地的Harness是徒劳的,因为随着模型迭代把问题本身解决,针对旧模型局限精心设计的harness便失去了存在的意义。模型的局限性厂家最清楚,它可以完全按照模型的特性设计不同的harness,然后打包卖给你。这个包,就是Managed Agents。」
—— 马东锡 @dongxi_nlp
Anthropic工程博客里有个具体案例:Claude Sonnet 4.5快到上下文窗口极限时会「焦虑」,草草结束任务。他们在调度框架里加了上下文重置来应对。但Claude Opus 4.5出来后,这个毛病消失了,之前的补丁反而变成了累赘。
你自己搭调度框架,每次模型升级你都得跟着改。交给Anthropic,他们替你优化——或者更准确地说,他们优化了再卖给你。
定价参考
|
计费项 |
价格 |
备注 |
|
Token费用 |
按Anthropic API标准价 |
与直接调API一致 |
|
运行时费用 |
$0.08 / 会话小时 |
空闲时段不计费 |
|
网页搜索 |
$10 / 千次 |
按需使用 |
SDK支持 Python、TypeScript、Java、Go、Ruby、PHP 六种语言。Claude Code用户可在最新版本中输入 /claude-api managed-agents-onboarding 快速接入。
局限性:不是万能药
有几个需要注意的点:
-
• 部分功能仍在预览阶段。 多智能体协作、高级记忆工具、自我评估迭代等能力目前还没有全面开放,需要申请才能使用。
-
• 平台绑定。 选择Managed Agents意味着智能体基础设施绑在了Anthropic生态里,未来迁移成本不可忽视。
-
• 上下文管理仍是难题。 长时间任务中哪些信息该保留、哪些该丢弃,仍然涉及不可逆的决策。目前的做法是把上下文存储和上下文管理分开:存储保证不丢,管理策略随模型进化调整。
-
• 成本可预测性。 $0.08/会话小时听起来不多,但智能体跑几个小时的复杂任务,Token消耗加上运行时费用,成本可能不低。企业需要做好预算评估。
Managed Agents降低了基础设施的门槛,但没有解决更深的问题:怎么定义好的任务?怎么设计好的工作流?怎么建立信任让AI接触核心业务数据?这些,Managed Agents帮不了你。
AI基础设施的「AWS时刻」真的来了
十年前企业纠结「上不上云」,最终绝大多数选择了托管——因为基础设施从来不是核心竞争力。现在的问题是「智能体基础设施自建还是托管」,历史会重演吗?
从技术角度看,「大脑和手分离」这个架构是真正值得关注的东西。它解决了AI智能体落地的几个核心痛点,同时为多智能体协作打下了基础——多个大脑共享手,一个大脑可以把手交给另一个大脑。
OpenAI已经推出了自己的Agent平台Frontier,这个赛道的竞争刚刚开始。而Anthropic年ARR突破300亿美元、是去年12月三倍的增长数字,已经让华尔街开始重新审视传统SaaS公司的估值逻辑。
如果你是普通用户,短期内最直观的感受可能是:你用的那些SaaS产品里,会有越来越多的AI智能体在后台帮你干活,而这些智能体很可能就跑在Managed Agents上。
提问: AI智能体的基础设施,最终会像云计算一样被几家大厂垄断吗?做智能体中间件的团队,出路在哪里?欢迎在评论区分享你的判断。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)