Learn-Claude-Code | 笔记 | Planning & Coordination | s04 Subagents
Learn-Claude-Code | 笔记 | Planning & Coordination | s04 Subagents
目录
前言
在上篇文章 Learn-Claude-Code | 笔记 | Planning & Coordination | s03 TodoWrite 中,我们介绍了开源项目 learn-claude-code 第三个章节 s03: TodoWrite 的内容,这篇文章我们继续跟着教程文档来学习规划与拆解后续内容,记录下个人学习笔记,和大家一起分享交流😄
Note:本篇文章主要学习记录教程第二部分 Planning & Coordination 中 s04: SubAgents 章节的内容。
github:https://github.com/shareAI-lab/learn-claude-code
reference:https://chatgpt.com/
1. s04: SubAgents
如果说 s03 解决的是 “Agent 在多步任务里怎么不跑偏”,那么到了 s04,这一节开始进一步回答一个更偏系统架构层的问题:
当任务已经复杂到不适合继续塞在同一个上下文里时,Agent 该怎么办?
在前面三节里,我们已经逐步搭起了一个越来越像样的最小 Agent。s01 用 loop 把模型和外部世界接了起来,s02 用结构化工具把能力边界从 bash 里拆了出来,s03 又进一步引入了 todo 机制,让模型开始显式维护执行计划。从执行能力的角度看,这个系统已经不再只是一个 “一问一答” 的 ChatBot,而是开始具备了一种持续行动和自我管理的能力。
但前面几节仍然默认了一个前提:所有动作都发生在同一个 messages 上下文里。
也就是说,不管是读文件、写文件、编辑文件、跑命令,还是写 todo、更新进度,所有这些信息最终都会不断积累进同一个消息历史中。刚开始这当然没什么问题,因为前面几节的任务规模都还比较小;可一旦任务稍微复杂一些,这种 “所有信息都堆进一个上下文” 的方式就会迅速暴露出新的问题:上下文开始膨胀,注意力开始被污染。
所以 s04 要解决的,已经不再是 “工具怎么接进 loop” 或 “todo 怎么约束执行过程”,而是:
当一个大任务里包含某些适合独立完成的小任务时,如何把它们拆出去,在一个新的干净上下文里执行,然后只把必要结果带回来。
这其实已经开始非常接近真实 Agent 系统里的 “子任务委派”了。也就是说,从这一节开始,Agent 不再只是单线程地在一个 messages[] 里走完整个任务,而是第一次具备了 “把一部分工作交给另一个新上下文去完成” 的能力。
这个思路在文档里被称为 Subagent / Context Isolation,也就是子智能体与上下文隔离。教程明确强调,父智能体通过 task 工具把子任务交出去,子智能体在一份新的 messages=[] 中独立工作,最后只返回摘要文本,而完整的子上下文直接丢弃。这样父上下文就能保持干净,避免无关的探索细节不断污染主对话。
2. 问题
我们先来看一个很朴素的问题:为什么 s03 那种单一上下文共享模式,到这里开始不够用了?🤔
在 s03 中,我们已经给 Agent 增加了 TodoWrite,也就是说它不再只是 “想到什么做什么”,而是开始有了一份显式的进度表。这个改进确实很重要,因为它大幅增强了多步任务中的执行纪律。但要注意,s03 真正解决的是 “计划丢失” 的问题,而不是 “上下文膨胀” 的问题。
换句话说,即使现在模型已经会先列 todo、再逐步更新状态,执行过程中产生的那些真实信息,依旧还是会一轮轮地往 messages 里追加。比如为了回答一个看似很简单的问题:
What testing framework does this project use?
模型可能会去:
- 读好几个 Python 文件
- 搜索配置文件
- 查看项目目录
- 跑一些 bash 命令确认结构
最后也许它真正需要返回给父智能体的,只不过是一个词 pytest,但在单一上下文模式下,为了得到这个词所产生的全部中间过程,都会永久留在主对话的 messages 历史里。也就是说,一个小子问题的探索细节,会把整个主上下文越撑越大。
文档里对这个问题说得很直接:智能体工作得越久,messages 数组就越胖;每次读文件、跑命令的输出都会永久留在上下文里,但很多时候父智能体真正需要的只是一个很短的结论,而不是整个探索轨迹。
这其实是一个非常典型的系统问题。因为模型的上下文窗口虽然看起来很大,但它并不是 “免费资源”。任何无关或次要的信息一旦不断残留在主上下文里,都会对后续推理造成干扰。前面 s03 的 todo 至少还能帮助模型记住 “现在做到哪一步了”,但它并不能阻止 messages 变得越来越臃肿。
所以 s04 这一节真正要解决的问题可以概括为一句话:
不是所有工作都值得永久留在主上下文里。
有些任务其实非常适合被拿到一个新的、干净的上下文中独立完成,完成之后再只把结果摘要带回来。这样父智能体既能利用子任务的执行能力,又不必把全部过程细节都背在自己身上。
3. 解决方案
明确问题之后,s04 给出的解法也非常干脆:为父智能体增加一个新的 task 工具,用它来生成一个拥有全新 messages=[] 的子智能体。
文档给出的整体结构如下:
Parent agent Subagent
+------------------+ +------------------+
| messages=[...] | | messages=[] | <-- fresh
| | dispatch | |
| tool: task | ----------> | while tool_use: |
| prompt="..." | | call tools |
| | summary | append results |
| result = "..." | <---------- | return last text |
+------------------+ +------------------+
Parent context stays clean. Subagent context is discarded.
这个图说明了 s04 的设计依然延续了前面几节的一贯风格:不改最底层 loop,只是在工具层加一个新能力。
这个新能力并不是 read、write、edit 那样的直接执行工具,也不是像 s03 的 todo 那样的状态写入工具,而是一个更高一级的 “委派工具”。父智能体一旦调用 task,程序就会启动一个新的子智能体,让它在一份全新的 messages=[] 里工作。
这个子智能体与父智能体共享同一个文件系统,所以它依然能读写当前项目里的文件,也依然能使用 bash、read_file、write_file、edit_file 这些基础工具;但它不会继承父智能体已经积累下来的那一长串对话历史。也就是说,它拿到的是同一个工作区,却不是同一份上下文。
整个子任务完成之后,程序只把子智能体最终产出的摘要文本返回给父智能体,而子智能体内部完整的消息历史则直接丢弃。文档和代码都明确写了这一点:父上下文保持干净,子上下文被丢弃;子智能体以 fresh messages=[] 启动,最终只返回 summary-only result 给父端。
这一步变化的意义非常大。因为从 s04 开始,Agent 不再只是 “在一个大上下文里不断堆动作”,而是开始具备了一种更接近真实操作系统的调度能力:把局部工作隔离到一个新的过程里做,主过程只拿结果,不背细节。
4. Subagent Context Isolation 流程图分析
这一节教程配了 6 张 Subagent Context Isolation 的图,如果把它们串起来看,其实非常适合帮助我们理解 s04 的主线到底是什么。和 s03 的 Nag System 图强调 “计划与监督” 不同,这一组图更像是在解释一种 “父进程 / 子进程式” 的上下文隔离机制。

先看第一张图。左边是 Parent Process,里面已经积累了一些消息:
user: Build login + testsassistant: Planning approach...tool_result: project structure
右边的 Child Process 还没有真正生成,只是一个灰色的占位框,里面写着 not yet spawned,下方说明文字写的是:
Parent Context
The parent agent has accumulated messages from the conversation.
这张图对应的其实就是 s03 以及之前几节的默认状态:父智能体随着对话不断推进,messages 里已经积累了越来越多上下文。到这里为止,系统还没有做什么新动作,但它已经明确点出了问题的出发点:父上下文已经存在,并且还会继续增长。

接着看第二张图。右侧的 Child Process 开始出现,里面只放了一条新的消息:
task: Write unit tests for auth
同时左边父进程上方出现了一个标记 task prompt。这一步的说明写的是:
Spawn Subagent
Task tool creates a child with fresh messages[]. Only the task description is passed.
这一步非常关键,因为它说明:父智能体在调用 task 工具之后,并不是把自己整个上下文都复制给子智能体,而只是把 “任务说明” 这一小段 prompt 传给它。
也就是说,父进程里原本累积的那些消息,比如 “Build login + tests”、“Planning approach…” 以及前面工具返回的 project structure,并不会自动出现在子进程的上下文里。子智能体拿到的不是 “父智能体的全部记忆”,而只是 “一项明确的任务描述”。
文档和代码都强调了这一点:子智能体以 fresh messages=[] 启动,父端只通过 task 工具把 prompt 传进去,而不是共享整个 conversation history。

第三张图里,子进程开始真正工作了。它的上下文中出现了:
task: Write unit tests for authtool_use: read auth.tstool_use: write tests
而左边父进程仍然保持原样,没有同步出现这些子任务细节。下方说明写的是:
Independent Work
The child has its own context. It doesn't see the parent's history.
这一步已经非常直观地把 “上下文隔离” 展示出来了。子智能体不是父智能体对话历史的一部分扩展,而是真正拥有一份独立的 messages[]。它在里面读文件、写测试、继续调用工具,但这些行为都只发生在子进程自己的上下文空间里,并不会持续污染父上下文。也就是说,父子之间共享的是工作区,不共享的是对话历史。

第四张图进一步展示了子进程的最终状态。右边不再显示一长串子任务历史,而是出现了一条新的摘要消息:
summary: 3 tests written, all passing
下方说明写的是:
Compress Result
The child's full conversation compresses into one summary.
这一张图其实就是整个 s04 的灵魂。因为它说明子智能体内部即使跑了很多轮工具调用,最后真正返回给父端的,也只是一个被压缩后的 summary。换句话说,子智能体所做的大量探索和执行,本质上会被 “压缩” 为一句摘要结果,而不会原样灌回父智能体的 messages 里。
代码里的 run_subagent() 也正是这样做的:子端循环运行,直到 stop_reason != "tool_use",最后只把 response.content 里的文本拼接出来返回;完整的 sub_messages 则不会回到父端,而是随着函数结束直接丢弃。

第五张图展示了这个摘要如何被送回父进程。左边父进程顶部出现了一个 summary 标记,下方说明写的是:
Return Summary
Only the summary returns. The child's full context is discarded.
这一步对应的其实就是父智能体把子任务结果当成一次普通 tool_result 收下。也就是说,从父端视角看,它并不会意识到子进程内部究竟读了多少文件、执行了多少工具、产生了多少中间对话,它只会得到一个最终摘要,然后把这个摘要继续作为上下文的一部分参与后续决策。
这个设计非常漂亮,因为它把子任务的 “工作量” 完全隐藏在子上下文里,而把父上下文中保留下来的内容控制到最小。

最后第六张图把整个效果总结了出来。左边父进程中现在包含:
user: Build login + testsassistant: Planning approach...tool_result: project structuresummary: 3 tests written, all passing
而右边子进程整块已经被灰化,并写着 context discarded。底部说明写的是:
Clean Context
The parent gets a clean summary without context bloat. This is fresh-context isolation via messages[].
这张图其实已经把 s04 的全部价值说完了。父智能体不再需要背着子任务内部那一长串 read / write / bash 细节,它只拿到一个干净的总结结果;而子智能体的完整上下文则随着任务结束被彻底丢弃。于是父上下文既保留了决策所需的核心信息,又避免了被无关的探索过程不断撑大。
完整动画演示如下图所示:

5. 工作原理(代码分析)
看完流程图之后,接下来我们正式进入 agents/s04_subagent.py 的代码。和前面几节一样,文件顶部依然先给出了这一节脚本的意图说明:
#!/usr/bin/env python3
# Harness: context isolation -- protecting the model's clarity of thought.
"""
s04_subagent.py - Subagents
Spawn a child agent with fresh messages=[]. The child works in its own
context, sharing the filesystem, then returns only a summary to the parent.
...
Key insight: "Process isolation gives context isolation for free."
"""
这段注释概括了 s04 的核心思想:通过 process isolation,实现 context isolation。
也就是说,这一节并没有试图在一个 messages[] 里做复杂的上下文裁剪规则,而是更干脆地把子任务整个拿到另一个 “过程” 里去做。只要子任务天然运行在独立的 messages=[] 里,那么上下文隔离这件事就几乎是 “白送” 的。这也是代码注释里那句 “Process isolation gives context isolation for free.” 的真正含义。
初始化部分和 s02 / s03 基本一致,还是 .env、Anthropic 客户端、WORKDIR、MODEL 这些运行时准备逻辑。真正开始体现 s04 主题的,是两条 system prompt:
SYSTEM = f"You are a coding agent at {WORKDIR}. Use the task tool to delegate exploration or subtasks."
SUBAGENT_SYSTEM = f"You are a coding subagent at {WORKDIR}. Complete the given task, then summarize your findings."
这里第一次出现了父端和子端各自独立的 system prompt。
父智能体的 prompt 里强调的是 Use the task tool to delegate exploration or subtasks,也就是说,它被鼓励在适合的时候把探索性工作或子任务委派出去;而子智能体的 prompt 则更直接:Complete the given task, then summarize your findings. 这说明子端并不是一个完整复制父端职责的第二个 agent,它的角色更专一:拿到一个明确任务,完成它,然后给出摘要。
也就是说,从系统提示词层面,父子智能体的分工已经被提前写进去了。父端负责统筹与委派,子端负责局部执行与总结。
接下来先看工具层。你会发现这一节并没有重新发明一套新工具,而是继续沿用了前面 s02 那批基础能力:
bashread_filewrite_fileedit_file
这些工具的 handler 实现和前面几节几乎一致,仍然有 safe_path() 做路径沙箱,run_bash() 做危险命令拦截、超时控制和输出截断,run_read()、run_write()、run_edit() 也都还是那套稳定的结构化工具写法。
这一点其实很重要,因为它说明 s04 的重点根本不在 “新增了什么基础执行能力”,而在 “这些能力在父端和子端之间如何被分配”。换句话说,s04 真正变化的是调度与上下文结构,而不是底层能力集合本身。
在这一节里,最关键的工具层设计是把工具分成了两组:
CHILD_TOOLS = [bash, read_file, write_file, edit_file]
PARENT_TOOLS = CHILD_TOOLS + [task]
文档里对这件事总结得很明确:父智能体有一个 task 工具,而子智能体拥有除 task 之外的所有基础工具;换句话说,task 是父端专属工具,子端不能继续生成新的子端,禁止递归生成 subagent。
这个设计其实非常漂亮,因为它既保证了父智能体拥有 “委派能力”,又避免了子智能体无限递归地产生更多子智能体。要是不给这个边界,理论上子端也可以不断再调 task 去生成孙智能体、重孙智能体,整个系统的控制流很快就会变得难以管理。
现在通过把 task 放在 PARENT_TOOLS 而不是 CHILD_TOOLS 里,代码层面就直接把这条边界硬编码出来了。这和 s02 里用 safe_path() 做路径硬约束、s03 里用单一 in_progress 做状态硬约束,其实是完全同一种工程思路:不要只靠 prompt 约束,要让代码真正把不希望发生的事变成 “做不到”。
理解了父端 / 子端工具的区别之后,接下来就进入这一节最核心的函数:run_subagent()
def run_subagent(prompt: str) -> str:
sub_messages = [{"role": "user", "content": prompt}] # fresh context
for _ in range(30): # safety limit
response = client.messages.create(
model=MODEL, system=SUBAGENT_SYSTEM, messages=sub_messages,
tools=CHILD_TOOLS, max_tokens=8000,
)
sub_messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
break
results = []
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler else f"Unknown tool: {block.name}"
results.append({"type": "tool_result", "tool_use_id": block.id, "content": str(output)[:50000]})
sub_messages.append({"role": "user", "content": results})
return "".join(b.text for b in response.content if hasattr(b, "text")) or "(no summary)"
首先最重要的一句就是:
sub_messages = [{"role": "user", "content": prompt}]
这一句意味着子智能体启动时,拿到的是一份全新的消息历史,而不是父智能体当前的 messages 副本。它的上下文只有一条用户消息,也就是父端传来的任务描述。
也就是说,子端天然就被隔离在一个 fresh context 里了。这和前面那几张流程图里的第二、三步是完全对应的:父端只传一个 task prompt 给子端,而不是把自己的历史全部塞进去。
然后往下看,我们会发现 run_subagent() 内部其实又跑了一次完整的 agent loop。它照样是:
- 调模型
- 追加 assistant 输出
- 检查
stop_reason - 遍历
tool_use - 执行工具
- 再把
tool_result加回子消息历史
也就是说,子智能体并不是什么特殊的 “轻量函数”,它本质上就是又起了一个缩小版 agent loop。唯一的区别在于,这个 loop 用的是 SUBAGENT_SYSTEM 和 CHILD_TOOLS,并且跑在自己的 sub_messages 里。
这一点特别关键,因为它说明 s04 依然没有推翻 s01 确立下来的最小骨架。即使到了子智能体层面,系统底层的运行模式也仍然还是那个最熟悉的 while-loop + tool_use + tool_result。前面几节建立的核心模式,到这里依旧没有变,只是现在这个模式可以在一个新的局部上下文里再运行一次了。
再往下看,还能发现一个很有意思的安全细节:
for _ in range(30): # safety limit
这里对子智能体 loop 增加了一个最多 30 轮的 safety limit。这一点虽然文档里只是轻轻带过,但从工程角度非常合理。因为子智能体既然是自动运行的,就必须防止它在某些情况下无限循环、一直卡在内部探索里出不来。
这个上限就像 run_bash() 里的 timeout 一样,都是在给自动执行能力加边界。也就是说,s04 不只是讲“如何生成 subagent”,也同时体现出一条很成熟的工程意识:凡是自动运行的过程,都要有退出保险。
最后看返回值:
return "".join(b.text for b in response.content if hasattr(b, "text")) or "(no summary)"
这句其实就是整个 s04 最灵魂的一句代码。因为它说明,子智能体跑完之后,父智能体真正拿到的,只是这一轮最终 response 里的文本部分。至于子智能体在整个运行过程中积累下来的 sub_messages,在函数结束之后就直接随着局部变量生命周期消失了,不会再回流到父上下文里。这就对应了文档和流程图中一直强调的那句话:Only the summary returns. The child’s full context is discarded.
也正因为这样,s04 才真正把 “上下文隔离” 这件事做扎实了。父智能体不是通过某种复杂算法从子任务对话里筛选重点,而是从一开始就让子任务整个运行在一个独立空间里,最后只拿一份浓缩结果回来。这样一来,父上下文就天然保持干净,不需要再额外做 “清理”。
理解了 run_subagent() 之后,再看 PARENT_TOOLS:
PARENT_TOOLS = CHILD_TOOLS + [
{"name": "task", "description": "Spawn a subagent with fresh context. It shares the filesystem but not conversation history.",
"input_schema": {"type": "object", "properties": {"prompt": {"type": "string"}, "description": {"type": "string", "description": "Short description of the task"}}, "required": ["prompt"]}},
]
input_schema 格式化后的内容如下:
{
"type": "object",
"properties": {
"prompt": {
"type": "string"
},
"description": {
"type": "string",
"description": "Short description of the task"
}
},
"required": [
"prompt"
]
}
这里第一次把 task 工具正式暴露给父智能体。这个 schema 也很有意思,它不只是要一个 prompt,还支持一个 description 字段,用来给这次子任务一个简短说明。
也就是说,父端在调用子任务时,不只是单纯丢一句长 prompt 过去,还可以附带一个更短的标签,方便日志输出或人类观察。更重要的是,description 的存在也说明 task 已经不再是普通执行工具,而是一种更高层级的 “任务调度入口”。
最后再来看父端自己的 agent_loop(),你就会发现这一节最漂亮的地方,还是那种熟悉的 “核心 loop 依然没怎么变” 的感觉:
def agent_loop(messages: list):
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=PARENT_TOOLS, max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
results = []
for block in response.content:
if block.type == "tool_use":
if block.name == "task":
desc = block.input.get("description", "subtask")
print(f"> task ({desc}): {block.input['prompt'][:80]}")
output = run_subagent(block.input["prompt"])
else:
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler else f"Unknown tool: {block.name}"
print(f" {str(output)[:200]}")
results.append({"type": "tool_result", "tool_use_id": block.id, "content": str(output)})
messages.append({"role": "user", "content": results})
先看整体结构:最外层 while True 没变;每轮先调 client.messages.create(...) 没变;把 assistant 输出追加到 messages 没变;通过 stop_reason != "tool_use" 判断退出没变;执行完工具后再把 tool_result 作为新的 user 消息加回上下文也没变。
真正变化的地方,其实只有工具执行这一小段。s02 是查 TOOL_HANDLERS,s03 是在此基础上加了 todo 和 nag,到了 s04,这里多了一个特殊分支:如果工具名是 "task",那就不再直接走普通 handler,而是转而调用 run_subagent() 去启动一个新的子循环;如果不是 task,那就继续像以前一样按 TOOL_HANDLERS 执行基础工具。
也就是说,s04 的全部新能力,本质上也只是往工具执行分发逻辑里加了一个更高层级的 handler。这一点和 s02 里 “加工具 = 加 handler + 加 schema”,s03 里 “加 todo = 加 handler + 加状态层” 是一脉相承的。直到这一节,整个项目依旧在坚持同一个方法论:能力扩展永远发生在 loop 外围,而不是推翻 loop 本身。
所以从代码角度看,s04 这一节最漂亮的地方就在这里:它表面上看引入了父智能体、子智能体、上下文隔离、summary-only return,好像系统一下子复杂了很多,但真正落到核心运行骨架上,改动依旧非常克制。
底层 while-loop 完全没变,tool_use / tool_result 协议也没变,甚至子智能体内部都还是在跑同样的 loop 模式。变化只是在工具层里新增了一个 task 调度入口,并在这个入口背后起了一个 fresh-context 的子循环。
这种设计风格和 s02、s03 完全一致,也正因为这样,这个项目才会一直显得非常整洁:每一节都在加能力,但几乎从不推翻前面已经建立起来的核心结构。到了 s04,这个项目已经第一次长出了非常典型的 “多进程式” Agent 味道:父端统筹,子端局部探索,最后只把必要结果带回来。
博主在给定下面的提示词情况下:
Delegate: read all .py files and summarize what each one does
想通过调试看看整个过程发生了什么,我们来具体分析下:
1. 父智能体第一次 loop(请求开始)

父智能体模型第一次响应结果
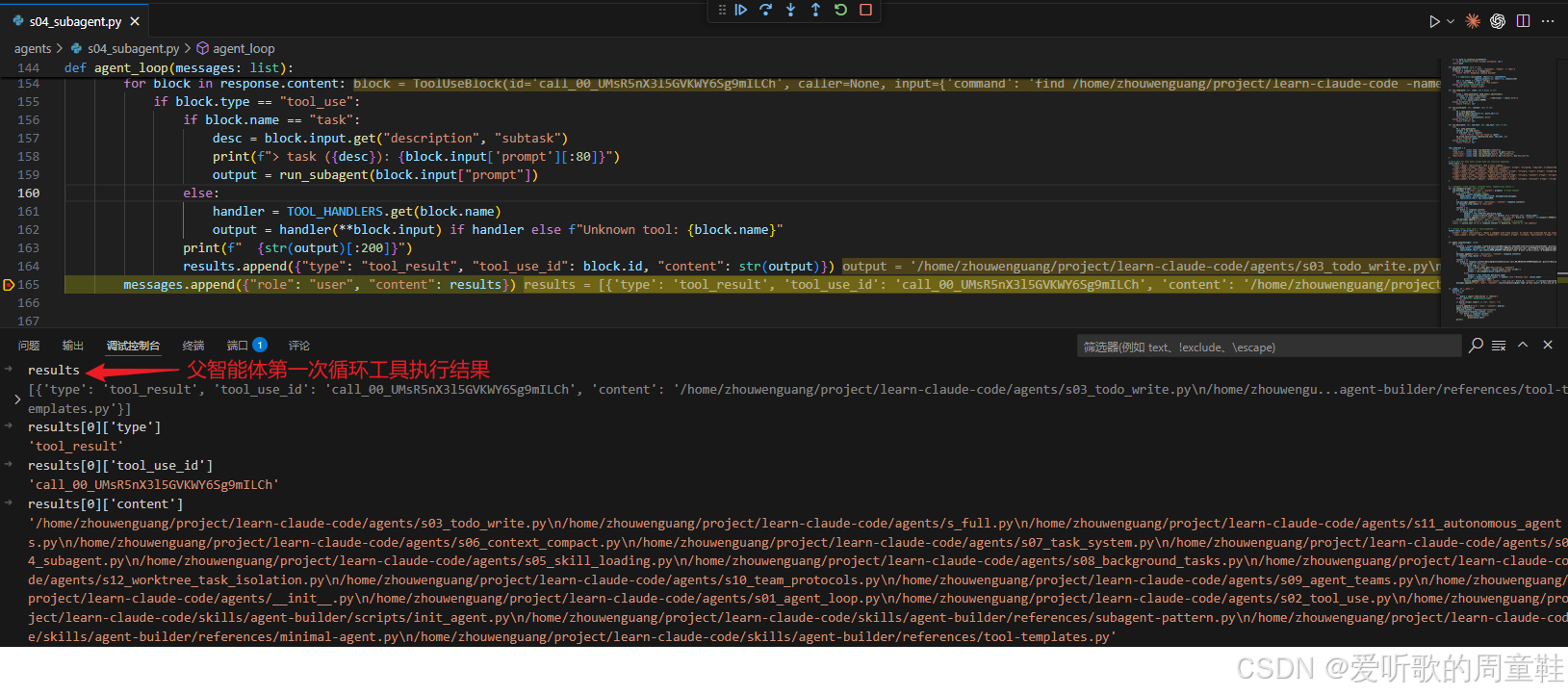
父智能体工具第一次执行结果
这一轮模型响应 response.content[0] 先是一个 TextBlock,模型先用自然语言说明自己要去读取所有 .py 文件并总结它们的作用;紧接着 response.content[1] 是一个 ToolUseBlock,调用的是 bash 工具,命令内容是:
find /home/zhouwenguang/project/learn-claude-code/agents -name "*.py" -type f
再看这一轮工具执行结果,可以看到 results[0]["content"] 返回的是一长串 .py 文件路径,主要包括 agents 和 skills 两个文件夹下的 .py 文件。
从系统结构上看,这一轮依旧完全符合前面几节的老模式:模型先做出判断,然后调用基础工具,再把工具结果回填到父上下文里。也就是说,虽然 s04 已经引入了子智能体,但父智能体本身并没有失去基础执行能力,它依然可以先自己做一层轻量探索,然后再决定是否值得把后续工作委派出去。
2. 父智能体第二次 loop(第一次调用 task 工具)
2.1 父智能体第二次 loop 模型响应

父智能体模型第二次响应结果
父智能体第二次 loop 才真正进入 s04 这一节最关键的部分。从调试图里可以看到,这一轮 response.content[0] 仍然先是一个 TextBlock,模型说明自己接下来要读取每个 Python 文件并总结它们的作用。
而真正值得关注的是 response.content[1],这里已经不再是 bash、read_file 之类的基础工具,而是明确出现了一个 ToolUseBlock,工具名变成了 task,同时它的输入里包含了两个字段:
descriptionprompt
其中 description 是一个较短的任务概括,大意是 “Read and summarize all Python files in the agents directory”;而 prompt 则是一段更完整的子任务说明,要求子智能体去读取 agents 目录下所有 Python 文件,并总结每个文件的用途和功能。
这一步非常关键,因为它说明父智能体在拿到第一轮的文件列表之后,已经判断出:后续工作不再适合继续塞在父上下文里做,而是更适合委派给一个新的子上下文。 换句话说,父智能体并没有自己继续一轮轮读每个文件、再在自己的 messages[] 里积累大量中间分析,而是选择在第二轮就把这个 “遍历所有 Python 文件并逐个理解” 的任务整体打包成一个 subtask,交给 task 工具去处理。
从工程角度看,这正是 s04 所强调的上下文隔离思想。因为 “读取所有 Python 文件并总结每个文件做什么” 这种任务天然会产生大量中间信息:每读一个文件就会有一段内容,每分析一个脚本就会有一段解释。如果这些内容全都留在父上下文里,很快就会把父智能体的 messages[] 撑得非常臃肿。
现在通过 task 工具,父端把这部分探索性工作整个拿出去,让子智能体在 fresh context 中完成,自己只保留一次委派动作和最终结果,这样父上下文就能保持干净得多。
2.2 子智能体第一次 loop

子智能体模型第一次响应结果

子智能体工具第一次执行结果
子智能体第一次 loop 的调试结果特别能体现 “fresh context” 这件事。首先从图里可以看到,子智能体拿到的 prompt 并不是父智能体整个对话历史,而只是那段明确的任务描述:
Please read all the Python files in the /home/zhouwenguang/project/learn-claude-code/agents directory and provide a summary of what each file does. Focus on understanding the purpose and functionality of each agent script.
也就是说,子智能体的起点不是 “继承父端的全部 messages[]”,而只是一个干净的 user prompt。随后在第一次响应里,response.content[0] 先是一个 TextBlock,模型说明自己会读取该目录下所有 Python 文件并总结它们的作用;紧接着 response.content[1] 就是一个 ToolUseBlock,调用的工具是普通的 bash,命令内容是:
find /home/zhouwenguang/project/learn-claude-code/agents -name "*.py" -type f
注意这里其实和父智能体第一次 loop 做的事情非常像:子智能体也会先列出所有 .py 文件。看起来有点 “重复”,但这正好说明了上下文隔离的本质:子智能体并不知道父智能体前面已经列过一次文件列表了,因为这个信息并没有被传进来。对它来说,自己拿到的是一个全新的任务,所以它也需要重新从最基础的探索开始。
这种 “重复” 在局部看来似乎有些多余,但从整体系统角度看,它换来的是上下文的彻底隔离,也就是父智能体不需要把这类过程细节一直背在自己身上。
再看子智能体第一次工具执行结果,返回的仍然是一长串 agents/ 目录下的 .py 文件路径。这说明子智能体已经开始在自己的上下文里建立对目标目录的认识。也就是说,到了这里为止,父智能体只是 “发出委托”,真正的目录探索工作已经在子智能体自己的 messages[] 中独立展开了。
2.3 子智能体第二次 loop

子智能体模型第二次响应结果

子智能体工具第二次执行结果
子智能体第二次 loop 展示的正是它如何在自己的上下文里继续展开局部探索。从调试图里可以看到,这一轮 response.content[0] 仍然先是一个 TextBlock,模型说自己要先读取每个 Python 文件来理解它们的作用,并且会从 agents 目录里的文件开始;紧接着 response.content[1] 则是一个新的 ToolUseBlock,工具已经从上一轮的 bash 切换成了 read_file,读取的具体路径是:
/home/zhouwenguang/project/learn-claude-code/agents/__init__.py
而工具执行结果也确实返回了 __init__.py 的内容摘要。可以看到这里返回的文本并不长,大意是说明 agents/ 目录里包含了一系列 harness implementations(s01-s12)以及一个完整参考实现 s_full,每个文件都可以独立运行,并逐步展示一个 AI coding agent 的构建过程。
后续就是不断调用工具查看每个文件,这里我们就不一一展示了,我们直接来看子智能体最后返回的结果。
2.4 子智能体最终总结
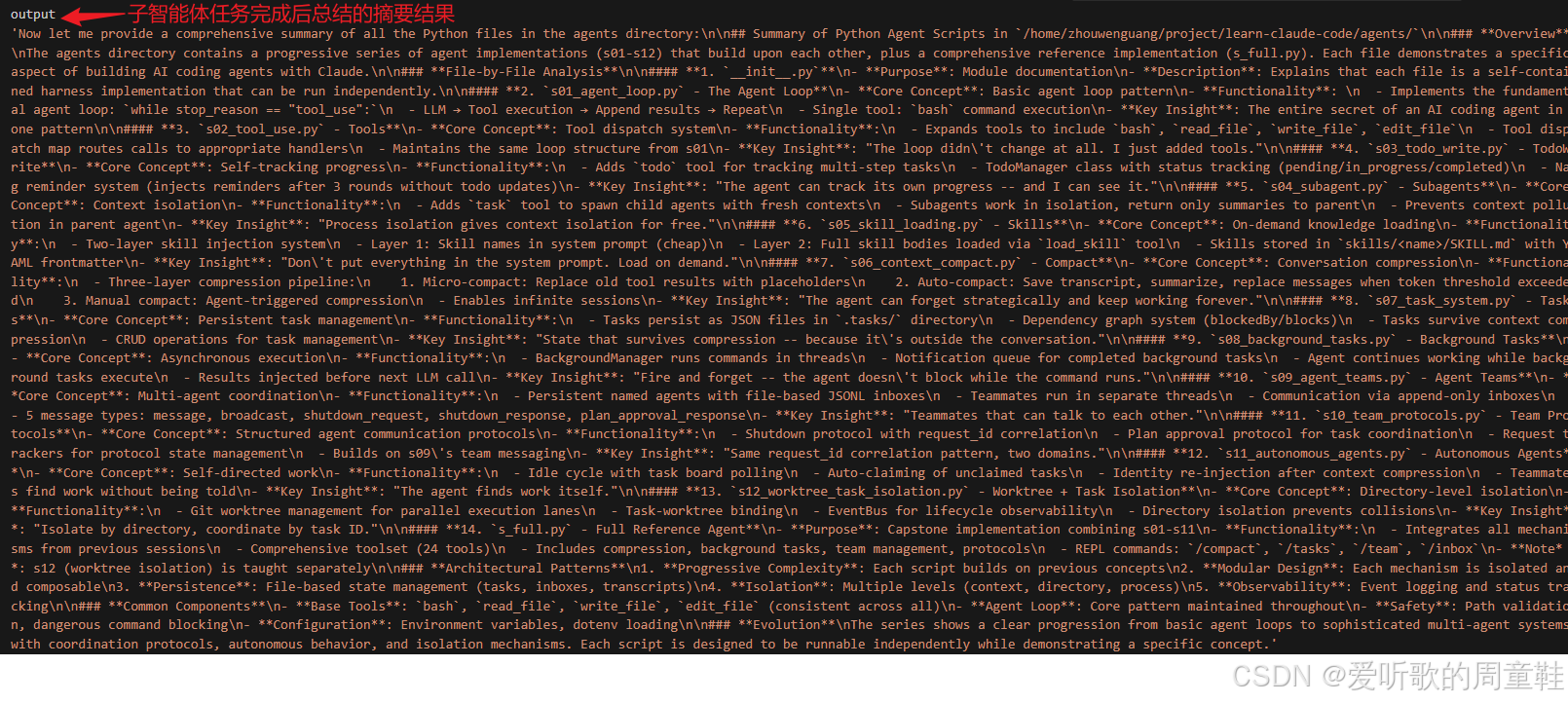
子智能体模型最终总结结果(agents 文件夹)
子智能体最终返回的结果,可以说是整个 s04 机制最核心的体现。从调试图里可以看到,output 已经不再是某条工具命令的结果,也不再是某个单独文件的内容,而是一段非常长的综合性摘要文本。
它从整体上总结了 agents/ 目录的作用,然后又按文件逐一梳理了每个脚本的核心概念、功能职责和关键 insight,比如:
s01_agent_loop.py:最小 agent loops02_tool_use.py:结构化工具系统s03_todo_write.py:todo 任务跟踪与 nag reminders04_subagent.py:子智能体与上下文隔离- 后面 s05 ~ s12 也都被按类似方式做了归纳
- 甚至还额外总结了整个项目的架构模式、演进路径和核心设计思想
这一步特别值得注意,因为它说明子智能体并不是简单地把自己读取到的原始文件内容原样拼回去,而是在自己的上下文里做了一次 “压缩” 和 “抽象”,把大量逐文件探索结果浓缩成了一份高层总结。这也正对应了前面流程图里那一步:
Compress Result
The child's full conversation compresses into one summary.
换句话说,子智能体真正带回给父智能体的,并不是 “我做过什么” 的原始痕迹,而是 “我发现了什么” 的浓缩结论。这就是 s04 中 summary-only return 的意义所在。因为父智能体真正关心的,从来不是子端内部具体读了多少个文件、走了多少轮 loop,而只是:你把这个子任务做完之后,能给我什么结果。
2.5 父智能体第二次 loop 工具执行
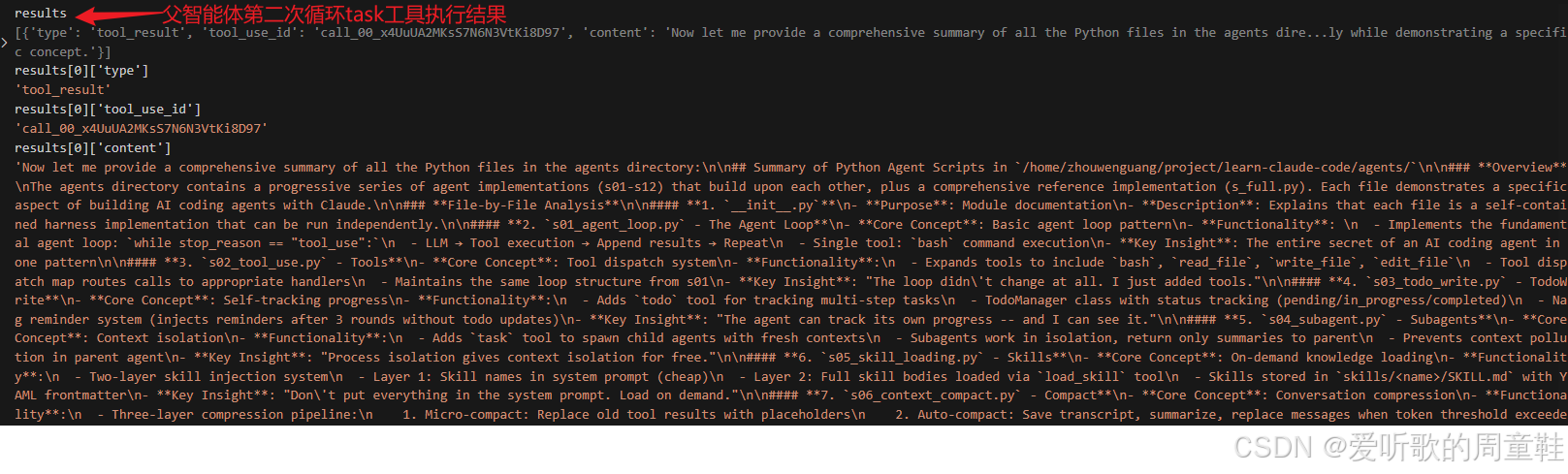
父智能体工具第二次执行结果
最后再来看父智能体第二次 loop 的工具执行结果,也就是 task 工具真正返回给父端的内容。从调试图里可以看到,父智能体这一轮 results[0]["content"] 里保存的,已经不再是子智能体内部那些中间工具调用结果,而正是子智能体最后整理出来的那份综合性摘要。
父智能体第二次 loop 虽然表面上只是执行了一次工具,但这个工具背后实际上已经完成了一整个独立的子任务流程:
- 子智能体拿到 prompt
- 子智能体在 fresh context 中列文件
- 子智能体逐个读文件并分析
- 子智能体把分析压缩成摘要
- 最后父端收到这份摘要作为普通
tool_result
这也正是 s04 里最想展示的点:父端上下文保持干净,子端完整上下文在任务完成后直接丢弃。
3. 父智能体第三次 loop(第二次调用 task 工具)

父智能体模型第三次响应结果

子智能体模型最终总结结果(skills 文件夹)

父智能体工具第三次执行结果
父智能体第三次 loop 非常有意思,因为它进一步说明了 s04 中父智能体的职责并不是 “自己把所有目录都读完”,而是 不断判断哪些部分值得继续委派给新的子上下文去做。
从调试图里可以看到,这一轮父智能体的 response.content[0] 仍然是一个 TextBlock,模型说明自己接下来要读取并总结 skills 目录中的 Python 文件;而 response.content[1] 再次不是基础工具,而仍然是 task 工具。也就是说,在完成前面对 agents/ 目录的总结之后,父智能体并没有直接在自己的上下文里继续分析 skills/ 目录,而是再次把这部分工作整体打包成一个新的子任务交给子智能体。
这一步其实非常能体现 s04 的 “父端统筹、子端探索” 思路。因为从任务性质上看,分析 skills/ 目录和前面分析 agents/ 目录是同一类问题:都需要列文件、逐个读取、理解用途、最后压缩成摘要。父智能体显然已经 “学会” 了这种模式,所以它会继续复用 task 工具,把这类天然容易产生上下文膨胀的探索型工作继续隔离出去做,而不是重新塞回自己的 messages[] 中。
再看子智能体最终返回的总结结果,可以看到这一次 output 已经变成了对 skills 目录下 Python 文件的一份综合性摘要。它从整体上总结了 skills 目录的结构和作用,然后重点归纳了诸如:
minimal-agent.pysubagent-pattern.pytool-templates.pyinit_agent.py
这些文件的用途、核心特性和适用场景,同时还上升到更高层总结了整个 skills 目录在项目中的架构意义,比如它代表的是一种模块化 agent architecture,强调最小实现、上下文隔离、可复用工具模板以及脚手架能力。
4. 父智能体第四次 loop

父智能体模型第四次响应结果
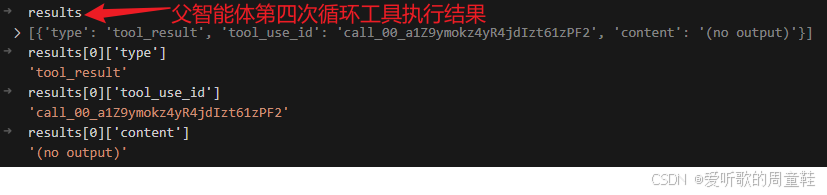
父智能体工具第四次执行结果
父智能体第四次 loop 开始做一件和前面略有不同、但同样很合理的事情:检查项目根目录下是否还存在其他 Python 文件需要纳入总结范围。
从调试图里可以看到,这一轮 response.content[0] 先是一个 TextBlock,模型说自己要检查项目根目录中是否还有其他 Python 文件;紧接着 response.content[1] 调用的是普通的 bash 工具,而不是 task。命令内容大致是:
find /home/zhouwenguang/project/learn-claude-code -name "*.py" -type f | grep -v "/agents/" | grep -v "/skills/"
这一步特别值得注意,因为它说明父智能体并不是 “所有事情都交给子智能体”。对于这种非常轻量、边界清楚、输出也不会太长的检查动作,父智能体完全可以自己做。换句话说,父智能体并不会机械地把一切都委派出去,而是会根据任务性质决定:哪些工作适合本地快速完成,哪些工作更适合交给子上下文。
再看工具执行结果,返回的是 (no output),这说明在父智能体当前这条检查命令下,并没有发现额外的 .py 文件输出出来。
5. 父智能体第五次 loop

父智能体模型第五次响应结果

父智能体工具第五次执行结果
父智能体第五次 loop 可以看成是第四次 loop 的进一步确认,只不过这次检查得更直接、更具体。
从调试图里可以看到,这一轮 response.content[0] 仍然先是一个 TextBlock,模型说自己要检查项目根目录下是否有 Python 文件;随后 response.content[1] 再次调用 bash 工具,命令大致是:
ls -la /home/zhouwenguang/project/learn-claude-code/*.py 2>/dev/null || echo "No Python files in root directory"
和上一轮相比,这里不再是用 find + grep -v 做全局排除式搜索,而是直接针对项目根目录这一层做精确检查。
工具执行结果也非常清楚,返回的是 No Python files in root directory。
6. 父智能体第六次 loop(无工具调用,回答完成)
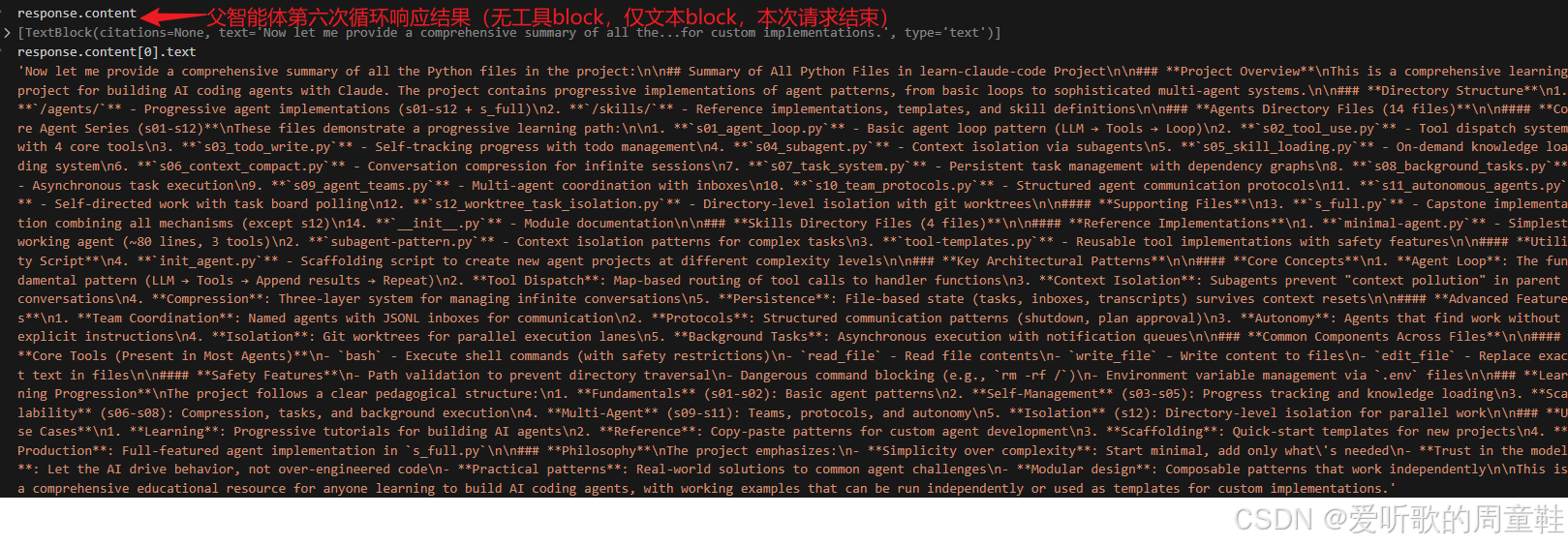
父智能体模型第六次响应结果
父智能体第六次 loop 就是整个请求的收束时刻了。从调试图里可以看到,这一轮的 response.content 已经不再包含任何 ToolUseBlock,只剩下一个单独的 TextBlock。这意味着本轮 stop_reason != "tool_use",父智能体认为自己已经掌握了足够的信息,不再需要继续调用任何工具,整个请求到这里正式结束。
而从最终返回的文本内容来看,父智能体已经把前面几轮收集到的信息组织成了一份完整的项目级总结。它先从整体上概括了整个 learn-claude-code 项目的定位与目标,然后按目录对 Python 文件进行了结构化说明:
agents/:s01-s12 加上 s_full 的渐进式 agent 实现skills/:参考实现、模板、脚手架和技能定义- 再进一步总结项目中的核心概念、关键模式、架构特征、常见工具、安全设计以及演进路线
也就是说,父智能体最终给出的并不是把前面两个子任务摘要和几条 bash 结果简单拼接在一起,而是在更高层做了一次再组织。子智能体负责的是局部探索和局部压缩,而父智能体负责的是把这些局部摘要重新编排成一份更完整、更适合对外输出的全局总结。
这一轮特别能体现父端和子端的角色差异:
- 子智能体:负责深入一个局部目录,做细节探索,并生成局部摘要
- 父智能体:负责统筹多个局部摘要,再决定是否还需要额外验证,并最终生成全局回答
所以父智能体第六次 loop 的结束,也正好把 s04 整节课的运行模式完整展示出来了。整个过程并不是 “父智能体把所有细节都亲自做完”,也不是 “把所有工作都交给子智能体之后自己完全不思考”,而是一种非常清晰的分层协作:
父端先做轻量判断
↓
把重探索任务委派给子端
↓
子端返回局部摘要
↓
父端再检查是否还存在遗漏范围
↓
确认信息足够后,父端生成最终全局总结
也正因为这样,s04 所引入的子智能体机制才不是简单的 “多起一个 loop”,而是真正开始让整个 Agent 系统具备了上下文分层管理和任务分工协作的能力。对比前面几节单一上下文不断膨胀的执行方式,这里已经可以明显看到一种更成熟的架构雏形:局部问题放到局部上下文里解决,全局问题由父上下文统一收束。
OK,以上就是 Subagent 工作原理的完整分析了。
大家也可以试试下面这些 prompt,感受下父智能体把探索型工作委派给子智能体之后,整个上下文会有什么变化:
1. Use a subtask to find what testing framework this project uses
2. Delegate: read all .py files and summarize what each one does
3. Use a task to create a new module, then verify it from here
6. 相对 s03 的变更
| 组件 | 之前 (s03) | 之后 (s04) |
|---|---|---|
| Tools | 5 | 5 (基础) + task (仅父端) |
| 上下文 | 单一共享 | 父 + 子隔离 |
| Subagent | 无 | run_subagent() 函数 |
| 返回值 | 不适用 | 仅摘要文本 |
7. 小结
如果说 s03 最大的贡献,是让 Agent 开始学会显式维护执行进度;那么 s04 的贡献就是让我们进一步看到:有些任务不应该只是 “按计划做”,还应该 “在合适的上下文里做”。
从教程文档来看,这一节最核心的结论其实非常明确:随着 Agent 持续工作,messages 会越来越胖,而很多探索性子任务真正有价值的只是最后那个结论,而不是完整过程;所以最干净的做法,不是让父智能体把所有细节都背下来,而是把子任务放到一份新的 messages=[] 中独立完成,最后只把总结结果带回来。
文档和代码都明确说明了这种模式:父端通过 task 工具生成子智能体,子端拥有 fresh context 和基础工具,但没有 task,避免递归生成;子端完整上下文在结束后被丢弃,父端只收到摘要文本,从而保持主上下文干净。
所以,s04 真正的价值并不只是多了一个 task 工具,也不只是多写了一个 run_subagent() 函数,而是第一次把 “上下文” 本身当成了需要被精细管理的系统资源。从这一节开始,这个项目已经不再只是一个会调工具、会写 todo 的单体 Agent,而是开始长出一种更成熟的架构意识:不是所有问题都该在一个脑子里想完,有些事情最好的做法,是交给一个干净的新脑子去想,然后只把结论带回来。
OK,以上就是本期想要分享的全部内容了。
结语
本篇文章我们围绕 s04 SubAgents 这一节,完整梳理了 Agent 在引入子智能体之后,是如何通过上下文隔离来应对复杂任务的。
相比前面的 s01~s03,这一节的变化不再只是 “能力增强”,而是第一次触及到了 Agent 系统中的一个更底层问题:上下文本身也是一种需要被管理的资源。随着任务规模的增长,把所有信息都堆进同一个 messages[] 中,不仅会带来性能开销,更会直接影响模型的注意力分配与推理质量。
Subagent 给出的解法其实非常克制:不去设计复杂的上下文裁剪策略,而是通过 “新建一个干净上下文” 来天然实现隔离。父智能体只负责统筹与决策,子智能体在局部上下文中完成探索,最后以摘要形式返回结果。这种设计让系统在面对复杂任务时,既能保持执行能力,又不会被中间过程不断拖累。
从工程视角来看,这一节最重要的收获,并不是 task 工具本身,而是一种更通用的设计原则:局部问题应该在局部上下文中解决,而全局上下文只保留对决策真正有价值的信息。这与传统系统中的进程隔离、模块边界划分,其实是完全一致的思想。
也正因为如此,Subagent 的引入标志着 Agent 系统从 “单上下文执行” 迈向 “分层上下文管理” 的阶段。模型不再需要在一个不断膨胀的上下文中维持所有细节,而是可以通过结构化的任务委派,把复杂性拆分并控制在合理范围内。
下篇文章我们将来学习 s05 skills 章节的内容,敬请期待🤗
参考

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)