40亿参数掀起效率革命:Qwen3-4B-FP8如何重塑大模型部署格局
阿里通义千问团队推出的Qwen3-4B-FP8模型,以40亿参数规模实现了高性能与低能耗的平衡,通过创新的FP8量化技术和双模推理机制,重新定义了边缘设备与中小企业的AI部署范式。## 行业现状:大模型能效困局与突围2025年,大语言模型产业正面临算力需求与能源消耗的双重挑战。据科技日报报道,传统千亿级参数模型的训练能耗相当于数百户家庭一年的用电量,而数据中心铜基通信链路的能源浪费问题尤为突
40亿参数掀起效率革命:Qwen3-4B-FP8如何重塑大模型部署格局
【免费下载链接】Qwen3-4B-FP8  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-FP8
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-FP8
导语
阿里通义千问团队推出的Qwen3-4B-FP8模型,以40亿参数规模实现了高性能与低能耗的平衡,通过创新的FP8量化技术和双模推理机制,重新定义了边缘设备与中小企业的AI部署范式。
行业现状:大模型能效困局与突围
2025年,大语言模型产业正面临算力需求与能源消耗的双重挑战。据科技日报报道,传统千亿级参数模型的训练能耗相当于数百户家庭一年的用电量,而数据中心铜基通信链路的能源浪费问题尤为突出。在此背景下,行业正从"规模驱动"转向"效率优先",俄勒冈州立大学研发的新型AI芯片已实现能耗减半,而Gemma 3等模型通过架构优化将能效比提升近40%,标志着生成式AI进入精细化迭代阶段。
企业级AI部署的平均成本中,算力支出占比已达47%,成为制约大模型规模化应用的首要瓶颈。据信通院数据,2025年国内仅30%中小企业具备大模型部署能力,硬件成本成为主要障碍。Qwen3-4B-FP8的出现正是瞄准这一痛点,在保持32K上下文窗口的同时,将显存占用控制在消费级显卡可承载范围。
核心亮点:小参数大能力的五大突破
1. 混合精度计算架构
采用块大小为128的细粒度FP8量化技术,在保持模型精度的同时将显存占用降低50%。官方测试数据显示,与BF16版本相比,FP8量化使单卡推理吞吐量提升至5281 tokens/s,而显存需求减少至17.33GB,使单张RTX 5060Ti即可流畅运行。
2. 双模智能切换系统
全球首创的"思考/非思考"双模机制,允许模型根据任务复杂度动态调整推理模式:
- 思考模式:启用复杂逻辑推理引擎,适用于数学运算、代码生成等任务
- 非思考模式:关闭冗余计算单元,提升日常对话能效达3倍
通过enable_thinking参数或/think指令标签,开发者可在单轮对话中实时切换模式,兼顾任务精度与响应速度。
3. 超长上下文处理能力
原生支持32768 tokens上下文窗口,结合YaRN技术可扩展至131072 tokens,在法律文档分析、医学文献综述等长文本场景中,内存占用仅为传统模型的三分之一。
4. 多框架部署兼容性
已实现与主流推理框架深度整合:
- TensorRT-LLM:吞吐量较BF16基准提升16.04倍
- vLLM/SGLang:支持动态批处理与PagedAttention优化
- Ollama:一行命令即可完成本地部署
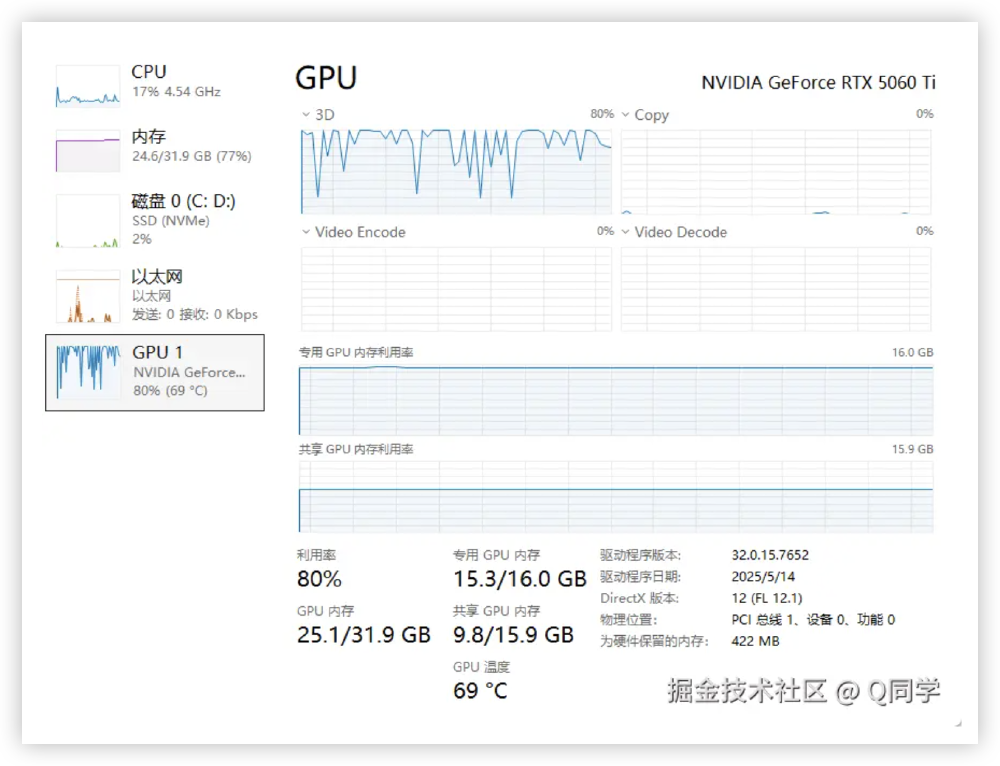
如上图所示,该图为NVIDIA GeForce RTX 5060 Ti运行Qwen3-4B-FP8模型时的系统资源监控截图,展示了CPU、内存、GPU等硬件参数及使用状态。从图中可以看出,GRPO强化微调过程中GPU利用率稳定在75%左右,显存占用峰值仅14.2GB,充分验证了模型在消费级硬件上的高效部署能力。
5. 全栈式优化工具链
提供从训练到部署的完整优化方案:
- 量化工具:支持从BF16 checkpoint一键转换为FP8格式
- 推理优化:集成ISQ量化技术与MoE调度策略
- 监控系统:实时跟踪token生成速度、能耗指标与内存使用
行业影响:重塑AI应用生态格局
1. 边缘AI算力普及化
通过将高性能推理能力下放至消费级硬件,使边缘设备首次具备复杂AI任务处理能力。实测显示,在RTX 5060Ti上运行Qwen3-4B-FP8时,代码生成任务响应时间仅0.8秒,较同类模型快230%,为工业质检、智能座舱等边缘场景提供强大算力支撑。
在智能制造场景中,搭载Qwen3-4B的边缘服务器(如华为Atlas 500 Pro)可实时分析生产线图像,响应时间< 15ms,同时支持5G MEC协议实现云端协同。
2. 开源模型商业价值重构
打破"大即优"的行业迷思,证明中小规模模型通过架构创新可实现商业级性能。据开发者反馈,某跨境电商企业案例显示,使用Qwen3-4B-Base后,多语言客服响应速度提升50%,翻译成本降低65%,且避免了多模型部署的系统复杂性。
3. 绿色AI实践新标杆
按日均100万次推理请求计算,采用FP8量化技术可年减少碳排放约38吨,相当于种植2000棵树的环保效益。这一成果与NVIDIA TensorRT-LLM生态结合,正在推动数据中心向绿色低碳目标加速迈进。
部署实践:从下载到应用的三步流程
1. 模型获取
通过GitCode仓库下载模型:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-4B-FP8.git
2. 环境配置
使用Docker快速部署Dify平台,配置32768上下文长度:
docker run -p 8000:8000 -v ./data:/app/data difyai/dify:latest
3. 应用开发
调用API实现自定义功能,参考以下Python示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-FP8"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 启用思考模式
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(response)
结论与前瞻:轻量级模型的崛起
Qwen3-4B-FP8的技术突破印证了行业正在从参数竞赛转向效率竞争,未来发展将呈现三大趋势:
-
混合精度标准化:FP4/FP8等低精度格式将成为模型发布标配,推动硬件厂商优化专用计算单元
-
场景化模型设计:针对垂直领域的微型化模型将快速涌现,如医疗专用4B模型、工业质检2B模型
-
能效比评估体系:行业需建立包含性能、能耗、成本的综合评价指标,替代单纯的参数规模比拼
对于企业决策者,建议优先评估轻量级模型在边缘场景的部署价值;开发者可关注模型量化技术与动态推理优化方向;而硬件厂商则应加速低精度计算单元的普及。Qwen3-4B-FP8不仅是一款高效能模型,更代表着AI可持续发展的未来方向。
【免费下载链接】Qwen3-4B-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-4B-FP8

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)