ESP32-S3-CAM:豆包语音识别文字后控制小车(二)——跑通demo代码
前面帖子里好不容易注册好了后台接口,但是怎么用,那个接入文档 非常细,但是内容太多太复杂,后来有次出差的时候,想了下,要不然先把官网给的python代码跑通,C++代码 142M确实没有勇气下载,主要没有时间去细看。上面安装过程就不一一介绍了,网上大把常规操作,python安装环境从清华镜像下载比较快,pycharm从官网下载最新的。这个音频文件,是我自己 用手机录了三秒录音,默认是2声道wav格
ESP32-S3-CAM:豆包语音识别文字后控制小车(规划)
前面帖子里好不容易注册好了后台接口,但是怎么用,那个接入文档 非常细,但是内容太多太复杂,后来有次出差的时候,想了下,要不然先把官网给的python代码跑通,C++代码 142M确实没有勇气下载,主要没有时间去细看。
于是继续安装python环境,版本3.12.X,注意添加环境变量。
安装pycharm IDE环境,这些都可以问豆包或者kimi。
上面安装过程就不一一介绍了,网上大把常规操作,python安装环境从清华镜像下载比较快,pycharm从官网下载最新的。
安装完以后,把下面这个py文件下载下来,本以为直接就能跑通。
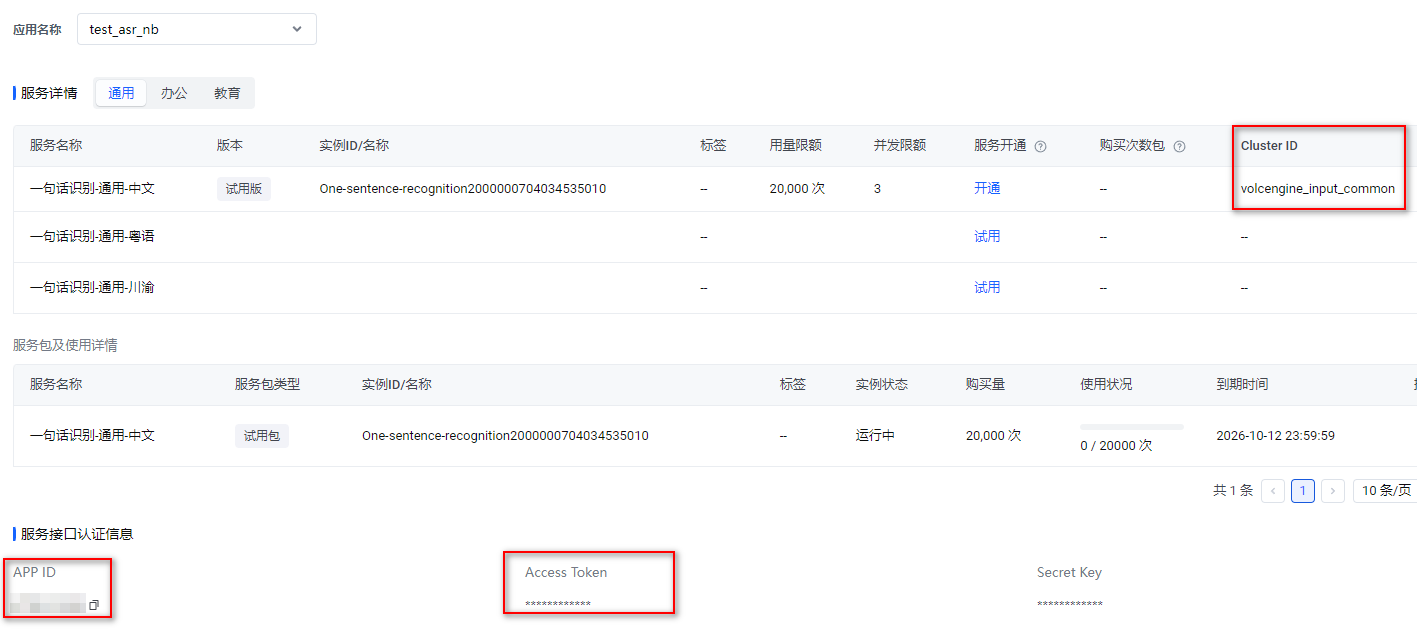
代码中这几个字段,需要自己根据前面帖子里项目管理页面去复制粘贴。
audio_path 就是音频本地文件在你电脑上的相对路径。
appid = "xxx" # 项目的 appid
token = "xxx" # 项目的 token
cluster = "xxx" # 请求的集群
audio_path = "" # 本地音频路径
audio_format = "wav" # wav 或者 mp3,根据实际音频格式设置
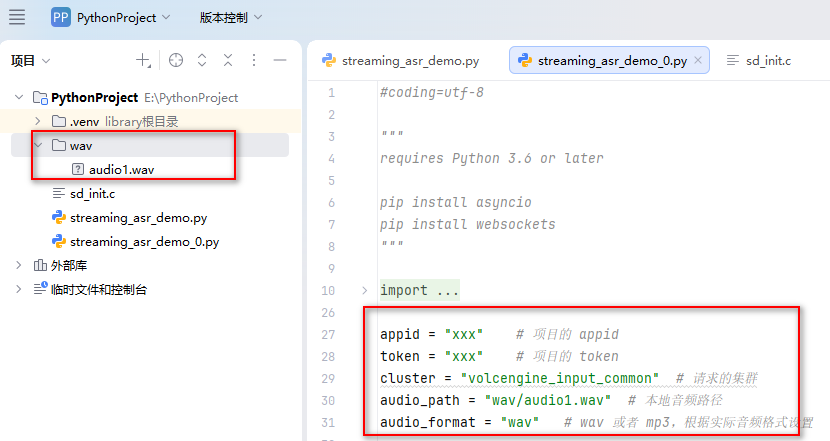
在pycharm项目目录里添加了一个资源文件,其他字段根据前面注册的情况填写即可。
编译运行后,结果报错一堆:
E:\PythonProject\.venv\Scripts\python.exe E:\PythonProject\streaming_asr_demo_0.py
Traceback (most recent call last):
File "E:\PythonProject\streaming_asr_demo_0.py", line 357, in <module>
test_one()
File "E:\PythonProject\streaming_asr_demo_0.py", line 343, in test_one
result = execute_one(
^^^^^^^^^^^^
File "E:\PythonProject\streaming_asr_demo_0.py", line 339, in execute_one
result = asyncio.run(asr_http_client.execute())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python312\Lib\asyncio\runners.py", line 195, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "C:\Python312\Lib\asyncio\runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python312\Lib\asyncio\base_events.py", line 691, in run_until_complete
return future.result()
^^^^^^^^^^^^^^^
File "E:\PythonProject\streaming_asr_demo_0.py", line 306, in execute
with open(self.audio_path, mode="rb") as _f:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: ''丢给kimi,代码修复后就可以跑了。
#coding=utf-8
"""
requires Python 3.6 or later
pip install asyncio
pip install websockets
"""
import asyncio
import base64
import gzip
import hmac
import json
import logging
import os
import uuid
import wave
from enum import Enum
from hashlib import sha256
from io import BytesIO
from typing import List
from urllib.parse import urlparse
import time
import websockets
appid = "" # 项目的 appid
token = "" # 项目的 token
cluster = "volcengine_input_common" # 请求的集群
audio_path = "wav/audio1.wav" # 本地音频路径
audio_format = "wav" # wav 或者 mp3,根据实际音频格式设置
PROTOCOL_VERSION = 0b0001
DEFAULT_HEADER_SIZE = 0b0001
PROTOCOL_VERSION_BITS = 4
HEADER_BITS = 4
MESSAGE_TYPE_BITS = 4
MESSAGE_TYPE_SPECIFIC_FLAGS_BITS = 4
MESSAGE_SERIALIZATION_BITS = 4
MESSAGE_COMPRESSION_BITS = 4
RESERVED_BITS = 8
# Message Type:
CLIENT_FULL_REQUEST = 0b0001
CLIENT_AUDIO_ONLY_REQUEST = 0b0010
SERVER_FULL_RESPONSE = 0b1001
SERVER_ACK = 0b1011
SERVER_ERROR_RESPONSE = 0b1111
# Message Type Specific Flags
NO_SEQUENCE = 0b0000 # no check sequence
POS_SEQUENCE = 0b0001
NEG_SEQUENCE = 0b0010
NEG_SEQUENCE_1 = 0b0011
# Message Serialization
NO_SERIALIZATION = 0b0000
JSON = 0b0001
THRIFT = 0b0011
CUSTOM_TYPE = 0b1111
# Message Compression
NO_COMPRESSION = 0b0000
GZIP = 0b0001
CUSTOM_COMPRESSION = 0b1111
def generate_header(
version=PROTOCOL_VERSION,
message_type=CLIENT_FULL_REQUEST,
message_type_specific_flags=NO_SEQUENCE,
serial_method=JSON,
compression_type=GZIP,
reserved_data=0x00,
extension_header=bytes()
):
"""
protocol_version(4 bits), header_size(4 bits),
message_type(4 bits), message_type_specific_flags(4 bits)
serialization_method(4 bits) message_compression(4 bits)
reserved (8bits) 保留字段
header_extensions 扩展头(大小等于 8 * 4 * (header_size - 1) )
"""
header = bytearray()
header_size = int(len(extension_header) / 4) + 1
header.append((version << 4) | header_size)
header.append((message_type << 4) | message_type_specific_flags)
header.append((serial_method << 4) | compression_type)
header.append(reserved_data)
header.extend(extension_header)
return header
def generate_full_default_header():
return generate_header()
def generate_audio_default_header():
return generate_header(
message_type=CLIENT_AUDIO_ONLY_REQUEST
)
def generate_last_audio_default_header():
return generate_header(
message_type=CLIENT_AUDIO_ONLY_REQUEST,
message_type_specific_flags=NEG_SEQUENCE
)
def parse_response(res):
"""
protocol_version(4 bits), header_size(4 bits),
message_type(4 bits), message_type_specific_flags(4 bits)
serialization_method(4 bits) message_compression(4 bits)
reserved (8bits) 保留字段
header_extensions 扩展头(大小等于 8 * 4 * (header_size - 1) )
payload 类似与http 请求体
"""
protocol_version = res[0] >> 4
header_size = res[0] & 0x0f
message_type = res[1] >> 4
message_type_specific_flags = res[1] & 0x0f
serialization_method = res[2] >> 4
message_compression = res[2] & 0x0f
reserved = res[3]
header_extensions = res[4:header_size * 4]
payload = res[header_size * 4:]
result = {}
payload_msg = None
payload_size = 0
if message_type == SERVER_FULL_RESPONSE:
payload_size = int.from_bytes(payload[:4], "big", signed=True)
payload_msg = payload[4:]
elif message_type == SERVER_ACK:
seq = int.from_bytes(payload[:4], "big", signed=True)
result['seq'] = seq
if len(payload) >= 8:
payload_size = int.from_bytes(payload[4:8], "big", signed=False)
payload_msg = payload[8:]
elif message_type == SERVER_ERROR_RESPONSE:
code = int.from_bytes(payload[:4], "big", signed=False)
result['code'] = code
payload_size = int.from_bytes(payload[4:8], "big", signed=False)
payload_msg = payload[8:]
if payload_msg is None:
return result
if message_compression == GZIP:
payload_msg = gzip.decompress(payload_msg)
if serialization_method == JSON:
payload_msg = json.loads(str(payload_msg, "utf-8"))
elif serialization_method != NO_SERIALIZATION:
payload_msg = str(payload_msg, "utf-8")
result['payload_msg'] = payload_msg
result['payload_size'] = payload_size
return result
def read_wav_info(data: bytes = None) -> (int, int, int, int, int):
with BytesIO(data) as _f:
wave_fp = wave.open(_f, 'rb')
nchannels, sampwidth, framerate, nframes = wave_fp.getparams()[:4]
wave_bytes = wave_fp.readframes(nframes)
return nchannels, sampwidth, framerate, nframes, len(wave_bytes)
class AudioType(Enum):
LOCAL = 1 # 使用本地音频文件
class AsrWsClient:
def __init__(self, audio_path, cluster, **kwargs):
"""
:param config: config
"""
self.audio_path = audio_path
self.cluster = cluster
self.success_code = 1000 # success code, default is 1000
self.seg_duration = int(kwargs.get("seg_duration", 15000))
self.nbest = int(kwargs.get("nbest", 1))
self.appid = kwargs.get("appid", "")
self.token = kwargs.get("token", "")
self.ws_url = kwargs.get("ws_url", "wss://openspeech.bytedance.com/api/v2/asr")
self.uid = kwargs.get("uid", "streaming_asr_demo")
self.workflow = kwargs.get("workflow", "audio_in,resample,partition,vad,fe,decode,itn,nlu_punctuate")
self.show_language = kwargs.get("show_language", False)
self.show_utterances = kwargs.get("show_utterances", False)
self.result_type = kwargs.get("result_type", "full")
self.format = kwargs.get("format", "wav")
self.rate = kwargs.get("sample_rate", 16000)
self.language = kwargs.get("language", "zh-CN")
self.bits = kwargs.get("bits", 16)
self.channel = kwargs.get("channel", 1)
self.codec = kwargs.get("codec", "raw")
self.audio_type = kwargs.get("audio_type", AudioType.LOCAL)
self.secret = kwargs.get("secret", "access_secret")
self.auth_method = kwargs.get("auth_method", "token")
self.mp3_seg_size = int(kwargs.get("mp3_seg_size", 10000))
def construct_request(self, reqid):
req = {
'app': {
'appid': self.appid,
'cluster': self.cluster,
'token': self.token,
},
'user': {
'uid': self.uid
},
'request': {
'reqid': reqid,
'nbest': self.nbest,
'workflow': self.workflow,
'show_language': self.show_language,
'show_utterances': self.show_utterances,
'result_type': self.result_type,
"sequence": 1
},
'audio': {
'format': self.format,
'rate': self.rate,
'language': self.language,
'bits': self.bits,
'channel': self.channel,
'codec': self.codec
}
}
return req
@staticmethod
def slice_data(data: bytes, chunk_size: int) -> (list, bool):
"""
slice data
:param data: wav data
:param chunk_size: the segment size in one request
:return: segment data, last flag
"""
data_len = len(data)
offset = 0
while offset + chunk_size < data_len:
yield data[offset: offset + chunk_size], False
offset += chunk_size
else:
yield data[offset: data_len], True
def _real_processor(self, request_params: dict) -> dict:
pass
def token_auth(self):
return {'Authorization': 'Bearer; {}'.format(self.token)}
def signature_auth(self, data):
header_dicts = {
'Custom': 'auth_custom',
}
url_parse = urlparse(self.ws_url)
input_str = 'GET {} HTTP/1.1\n'.format(url_parse.path)
auth_headers = 'Custom'
for header in auth_headers.split(','):
input_str += '{}\n'.format(header_dicts[header])
input_data = bytearray(input_str, 'utf-8')
input_data += data
mac = base64.urlsafe_b64encode(
hmac.new(self.secret.encode('utf-8'), input_data, digestmod=sha256).digest())
header_dicts['Authorization'] = 'HMAC256; access_token="{}"; mac="{}"; h="{}"'.format(self.token,
str(mac, 'utf-8'), auth_headers)
return header_dicts
async def segment_data_processor(self, wav_data: bytes, segment_size: int):
reqid = str(uuid.uuid4())
# 构建 full client request,并序列化压缩
request_params = self.construct_request(reqid)
payload_bytes = str.encode(json.dumps(request_params))
payload_bytes = gzip.compress(payload_bytes)
full_client_request = bytearray(generate_full_default_header())
full_client_request.extend((len(payload_bytes)).to_bytes(4, 'big')) # payload size(4 bytes)
full_client_request.extend(payload_bytes) # payload
header = None
if self.auth_method == "token":
header = self.token_auth()
elif self.auth_method == "signature":
header = self.signature_auth(full_client_request)
async with websockets.connect(self.ws_url, additional_headers=header, max_size=1000000000) as ws:
# 发送 full client request
await ws.send(full_client_request)
res = await ws.recv()
result = parse_response(res)
if 'payload_msg' in result and result['payload_msg']['code'] != self.success_code:
return result
for seq, (chunk, last) in enumerate(AsrWsClient.slice_data(wav_data, segment_size), 1):
# if no compression, comment this line
payload_bytes = gzip.compress(chunk)
audio_only_request = bytearray(generate_audio_default_header())
if last:
audio_only_request = bytearray(generate_last_audio_default_header())
audio_only_request.extend((len(payload_bytes)).to_bytes(4, 'big')) # payload size(4 bytes)
audio_only_request.extend(payload_bytes) # payload
# 发送 audio-only client request
await ws.send(audio_only_request)
res = await ws.recv()
result = parse_response(res)
if 'payload_msg' in result and result['payload_msg']['code'] != self.success_code:
return result
return result
async def execute(self):
with open(self.audio_path, mode="rb") as _f:
data = _f.read()
audio_data = bytes(data)
if self.format == "mp3":
segment_size = self.mp3_seg_size
return await self.segment_data_processor(audio_data, segment_size)
if self.format != "wav":
raise Exception("format should in wav or mp3")
nchannels, sampwidth, framerate, nframes, wav_len = read_wav_info(
audio_data)
size_per_sec = nchannels * sampwidth * framerate
segment_size = int(size_per_sec * self.seg_duration / 1000)
return await self.segment_data_processor(audio_data, segment_size)
def execute_one(audio_item, cluster, **kwargs):
"""
:param audio_item: {"id": xxx, "path": "xxx"}
:param cluster:集群名称
:return:
"""
assert 'id' in audio_item
assert 'path' in audio_item
audio_id = audio_item['id']
audio_path = audio_item['path']
audio_type = AudioType.LOCAL
asr_http_client = AsrWsClient(
audio_path=audio_path,
cluster=cluster,
audio_type=audio_type,
**kwargs
)
result = asyncio.run(asr_http_client.execute())
return {"id": audio_id, "path": audio_path, "result": result}
def test_one():
result = execute_one(
{
'id': 1,
'path': audio_path
},
cluster=cluster,
appid=appid,
token=token,
format=audio_format,
)
print(result)
print("ASR结果: "+ result['result']['payload_msg']['result'][0]['text'])
if __name__ == '__main__':
test_one()
最后输出的识别结果如下:
E:\PythonProject\.venv\Scripts\python.exe E:\PythonProject\streaming_asr_demo.py
{'id': 1, 'path': 'wav/audio1.wav', 'result': {'payload_msg': {'addition': {'duration': '1380', 'logid': '20260412204314AEA058073860379BBC1A', 'split_time': '[]'}, 'code': 1000, 'message': 'Success', 'reqid': 'b52e33f1-ba2d-4a99-859c-d8007b841bd1', 'result': [{'confidence': 0, 'text': '头抬高!'}], 'sequence': -2}, 'payload_size': 228}}
ASR结果: 头抬高!这个音频文件,是我自己 用手机录了三秒录音,默认是2声道wav格式,然后传到电脑上的。
这些文件后面也要拷贝到SD卡里,用于转换后的C++ 代码使用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)