【极简版】用Claude code将小红书帖子总结为md文档的方法
本文介绍了一种利用Claude Code提取小红书帖子内容并转换为md笔记的方法。配置要求包括Windows 10系统、Chrome浏览器和Thinkpad电脑。核心步骤包括:1)创建SKILL.md文件定义处理流程;2)从Chrome导出cookies;3)通过Python脚本解析帖子内容;4)视频转录处理;5)生成结构化Markdown笔记。该方法支持文字、图片和视频内容的提取,最终生成简洁明
配置:
系统:Windows10
电脑:Thinkpad
浏览器:Chrome
前提:电脑上需要先装上claude code,网上教程很多。
参考:(这个方案比较复杂全面,实操下来很多内容可以不需要)chenxiachan/xhs-claude-skills: Claude Code slash commands for extracting Xiaohongshu posts into Obsidian notes
目的:
喜欢做一些个人的知识沉淀,懒得自己打字总结笔记,想用AI。不支持大批量。

步骤一:
假设你想要放的位置是D:\claude\xhs\,则在这个目录下,你需要创建文件D:\claude\xhs\.claude\skills\xhs\SKILL.md,内容如下:(记得修改其中涉及的路径)
---
name: xhs
description: 提取小红书帖子内容(文字、图片、视频转录),整理为 Markdown 并保存
user-invocable: true
argument-hint: <小红书链接>
allowed-tools: Bash, Read, Write, Edit, Glob, Grep
---
用户希望提取小红书帖子内容。请按以下步骤处理:
## 常量定义
- Cookies 文件: `./cookies.json`(从 Chrome 导出的小红书 cookies)
- Obsidian 保存目录: `D:\claude\xhs\`
- Whisper 模型: `mlx-community/whisper-large-v3-turbo`
## 输入
用户提供的小红书链接: $ARGUMENTS
## 提取流程
### 步骤 0:检查 Cookies
1. 检查 `./cookies.json` 是否存在
2. 如果不存在,告知用户需要从 Chrome 导出 cookies:
- 在 Chrome 打开 xiaohongshu.com 并确认已登录
- 打开 DevTools Console,运行以下代码将 cookies 复制到剪贴板:
```javascript
copy(JSON.stringify(document.cookie.split('; ').map(c => {
const [name, ...rest] = c.split('=');
return { name, value: rest.join('='), domain: '.xiaohongshu.com', path: '/',
expires: Date.now()/1000 + 86400*30, size: name.length + rest.join('=').length,
httpOnly: false, secure: false, session: false, priority: 'Medium',
sameParty: false, sourceScheme: 'Secure', sourcePort: 443 };
})))
```
- 将剪贴板内容保存到 `./cookies.json`
- 然后终止流程,等用户完成后重新运行
### 步骤 1:解析链接
从 URL 中提取帖子 ID(24 位十六进制字符串)和 xsec_token 参数。
### 步骤 2:获取帖子内容
使用 Python 脚本,通过 Cookies 请求帖子页面 HTML,从 `window.__INITIAL_STATE__` 解析全部帖子数据:
```python
import json
import re
import sys
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 读取 cookies.json(格式:[{"name": "...", "value": "...", ...}, ...])
with open('./cookies.json') as f:
cookies_list = json.load(f)
# 转换为 requests 可用的字典格式
cookies_dict = {c['name']: c['value'] for c in cookies_list}
url = sys.argv[1]
# 配置会话,带重试机制
session = requests.Session()
retries = Retry(total=2, backoff_factor=0.5, status_forcelist=[500, 502, 503, 504])
session.mount('https://', HTTPAdapter(max_retries=retries))
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
'Referer': 'https://www.xiaohongshu.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Sec-Ch-Ua': '"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"macOS"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'Cache-Control': 'max-age=0',
}
# 发送请求(禁用 SSL 验证,模拟原 urllib 行为)
response = session.get(url, headers=headers, cookies=cookies_dict, timeout=15, verify=False)
response.encoding = 'utf-8'
html = response.text
# 提取 window.__INITIAL_STATE__
m = re.search(r'window\.__INITIAL_STATE__\s*=\s*(\{.+?\})\s*</script>', html, re.DOTALL)
if not m:
print('ERROR: Could not find window.__INITIAL_STATE__', file=sys.stderr)
sys.exit(1)
raw = m.group(1).replace('undefined', 'null')
data = json.loads(raw)
# 帖子数据在: data['note']['noteDetailMap'][<key>]['note']
# 包含: title, desc, type, time, user, imageList, video, interactInfo, ipLocation
```
如果请求失败(被重定向到 404/错误页),说明 cookies 过期,提示用户按步骤 0 重新导出。
### 步骤 3:视频转录(仅视频帖子)
如果帖子 type 为 video,执行以下子步骤:
#### 3a. 提取视频 URL
从步骤 2 获取的数据中解析视频流:
```
note['video']['media']['stream'] -> 按 h264 > h265 > av1 优先级取第一个的 masterUrl
```
#### 3b. 下载视频并提取音频
```bash
curl -L -o D:/claude/xhs/tmp/xhs_{post_id}.mp4 -H "Referer: https://www.xiaohongshu.com/" <视频URL>
ffmpeg -y -i D:/claude/xhs/tmp/xhs_{post_id}.mp4 -vn -acodec pcm_s16le -ar 16000 -ac 1 D:/claude/xhs/tmp/xhs_{post_id}.wav
```
#### 3c. 语音转录
```python
import mlx_whisper
result = mlx_whisper.transcribe("D:/claude/xhs/tmp/xhs_{post_id}.wav",
path_or_hf_repo="mlx-community/whisper-large-v3-turbo", language="zh", verbose=False)
```
#### 3d. 清理转录文本
- 去除尾部重复字符(背景音乐噪音)
- 按语义断句,添加标点和段落
- 如有步骤/要点结构,用 Markdown 格式化
#### 3e. 清理临时文件
```bash
rm -f D:/claude/xhs/tmp/xhs_{post_id}.mp4 D:/claude/xhs/tmp/xhs_{post_id}.wav
```
### 步骤 4:整理输出并保存
将内容整理为 Markdown 文件,保存到 `<Obsidian 保存目录>/{YYYY-MM-DD} {短标题}.md`。
- 文件名格式:`{发布日期} {短标题}.md`,短标题不超过15个字,是核心洞察的极简概括
- 日期前缀确保按时间排序
- 不创建子目录,所有帖子 md 直接放在 xhs 文件夹下
- 媒体文件统一放在 `<Obsidian 保存目录>/img/` 或 `<Obsidian 保存目录>/video/`
**写作风格:Peter Thiel 式——直接、反直觉、一句话给判断。笔记是决策工具,不是知识库。用户扫一眼就能决定:深挖还是跳过。**
文件结构(**无 YAML frontmatter**):
```markdown
# 一句话核心洞察(反直觉的判断,不是描述性标题)
核心论点,2-3句话。直接给出"大多数人觉得X,但其实Y"的判断。
不废话,不铺垫,像 Thiel 在董事会上说话。
**与我的关联:** 一句话。读取用户的 memory(~/.claude/projects/*/memory/ 下的
user 和 project 类型记忆)了解用户背景、研究方向和当前工作,据此说清楚
这个内容跟用户有什么关系。如果 memory 不可用,从通用的个人发展/工具/方法论角度切入。
**值得深挖吗:** 是/否。一句话理由。
> [!tip]- 详情
> 帖子核心内容的结构化整理(折叠状态,点开才看到):
> - 从 desc 和视频转录中提炼,清理 `#xxx[话题]#` 标记
> - 按逻辑结构分节,保留关键数据和结论
> - 图片用 `` 嵌入
> - 视频帖子在此处放整理后的转录内容
> [!info]- 笔记属性
> - **来源**: 小红书 · 作者名
> - **帖子ID**: xxx
> - **链接**: 原始链接
> - **日期**: YYYY-MM-DD
> - **类型**: image/video
> - **互动**: N赞 / N收藏 / N评论
> - **标签**: 标签1, 标签2, ...
```
关键约束:
- 折叠区域外的可见内容**不超过 6 行**
- 标题必须是洞察/判断,不是"XX帖子的总结"
- 图片使用 `urlDefault` 字段的 URL
步骤二:
在这个文件夹(xhs)下打开claude code(命令行方式),cc会自动扫描这个skill。你只需在命令行中输入:
/xhs <小红书帖子链接>即可运行。第一次的时候需要按提示在chrome浏览器中登录小红书并在相应位置(一般就是根目录)新建cookies.json文件。
效果:
目录下新增分析后的文件。
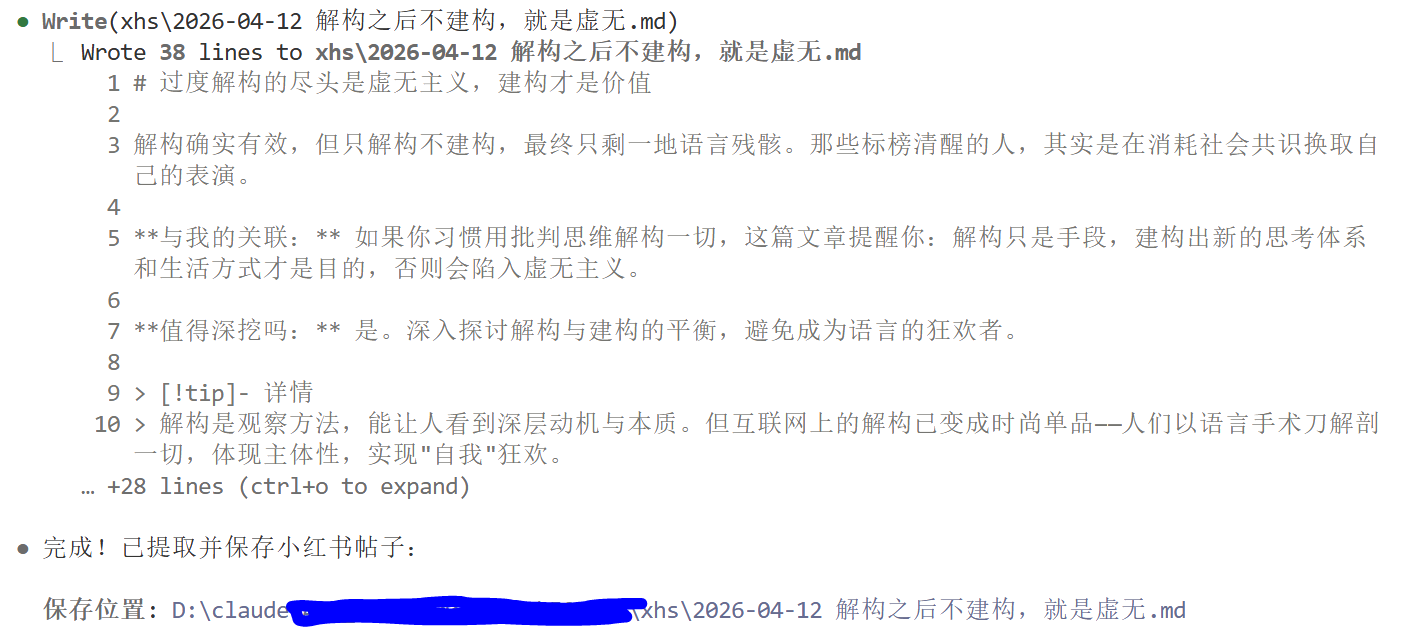
注意:
1. 感觉运行时间比较长,我的尝试中,一个帖子解析用时7分钟,用的是glm47的模型。
2. 小红书反爬机制貌似挺强大的,所以这个cookies可能需要经常更新(手动)。
3. 这个skill的注册是按项目的, 你换个项目文件夹就没有这个skill了(但其实只需要把这个SKILL.md复制到新目录的.claude/skills/xhs/即可)。不过个人感觉这样更灵活自由。
4. SKILL.md中的内容和原作者相比有一些修改,主要是代码的部分。其实自然语言处理逻辑也可也根据自己的偏好去修改。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)