硬核拆解:Claude Advisor“黑箱“策略 | 从一行代码到生产决策树
摘要:Anthropic推出的Advisor策略是一种模型级协作机制,让轻量级Claude Sonnet在遇到复杂任务时自动向更强的Claude Opus寻求帮助。
【编者按】 Sonnet便宜但易错,Opus强大但昂贵——Advisor号称能一行代码解决这个两难。但它究竟是"智能调度"还是"玄学黑箱"?本文从官方用法到推测机制,再到生产决策树,帮你做出清醒的判断。
📖 阅读指南:本文采用分层披露方式编写。内容按可信度分为三类:
✅ 官方确认:来自Anthropic官方文档
⚠️ 合理推测:基于API行为和工程逻辑的推演
❓ 未公开黑箱:目前无法验证的问题
建议配合以上标签阅读。
一、Advisor 策略是什么
1.1 一句话定义
Advisor 策略是 Anthropic 提供的一种模型级协作机制:让轻量级模型(Claude Sonnet)在面临复杂任务时,自动向更强的模型(Claude Opus)寻求帮助。
1.2 为什么需要这个策略
在 AI 应用开发中,开发者常面临一个权衡:
| 选择 | 优势 | 劣势 |
|---|---|---|
| 用轻量模型(Sonnet) | 成本低、延迟低 | 复杂任务容易出错 |
| 用强模型(Opus) | 能力强、准确率高 | 成本高、响应慢 |
传统解决方案:开发者自己写路由逻辑——先让 Sonnet 尝试,出错再调 Opus。这需要大量的工程工作和边界判断。
Advisor 策略的解决思路:把这个判断逻辑下沉到模型层,让模型自己决定"何时需要帮助"。
二、如何使用(官方确认)✅
2.1 基础调用方式
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6", # 轻量执行者模型
max_tokens=4096,
tools=[{
"type": "advisor_20260301" # 启用 Advisor 功能
}],
messages=[{
"role": "user",
"content": "分析这份合同中的隐藏法律风险"
}]
)
print(response.content)2.2 关键参数说明
| 参数 | 必填 | 说明 |
|---|---|---|
tools |
是 | 必须包含 type: "advisor_20260301" 才能启用 |
model |
是 | 执行者模型,目前支持 Sonnet 4.x 系列 |
advisor_model |
否 | 可选,指定咨询对象(默认 Opus) |
max_advisor_calls |
否 | 可选,限制单次任务的咨询次数 |
2.3 响应结构
启用 Advisor 后,响应中可能包含以下额外字段:
{
"content": "...",
"usage": {
"input_tokens": 1250,
"output_tokens": 890,
"advisor_tokens": 2100 # 顾问模型消耗的 Token
},
"advisor_metadata": {
"calls_made": 1, # 本次任务咨询次数
"consultation_reason": "legal_complexity_high" # 触发原因
}
}注:
advisor_metadata字段在官方文档中标记为 "beta",可能变动。⚠️
三、架构机制分析
💡 本章导读:官方文档能告诉我们的就这么多。现在我们来干点有意思的:像法医解剖一样,根据API的行为和公开的蛛丝马迹,一起"推测"一下Advisor这个"黑箱"里面到底在发生什么。
⚠️ 重要提示:以下内容为工程师的合理推演,请带着批判性思维阅读。可信度已在每小节标注。
3.1 工作流程(合理推测)⚠️
基于官方描述和工程逻辑,Advisor 策略的工作流程可能如下:
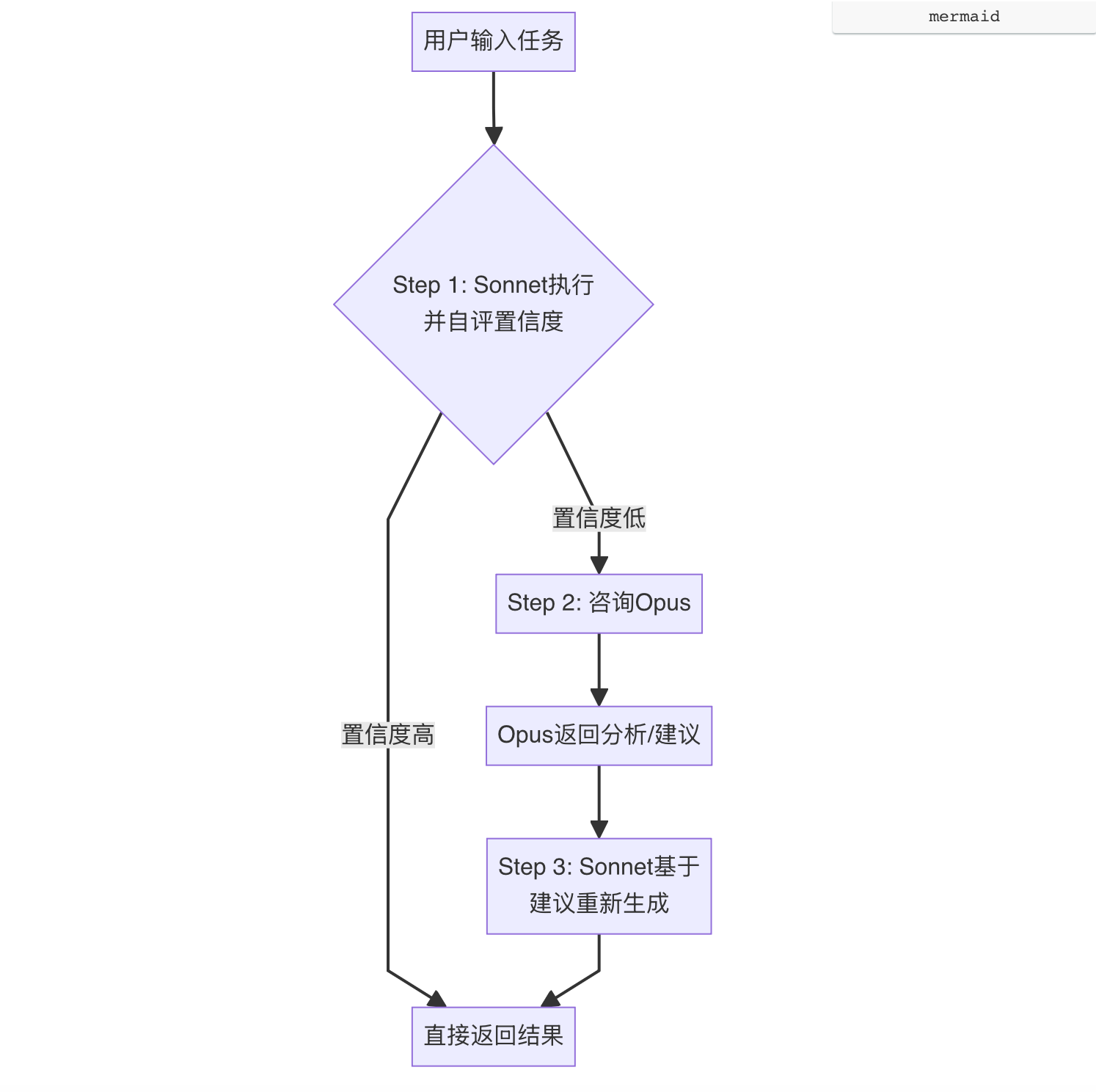
⚠️ 可信度:★★★☆☆(基于官方"模型自主判断何时咨询"的描述和通用工程逻辑推导)
3.2 置信度判断机制(推测)⚠️
⚠️ 核心推测:Advisor的核心很可能是一个内置于Sonnet模型的置信度评估模块。它通过分析生成文本的熵、不确定性词汇以及领域标签来决定是否求助。
以下是基于 LLM 不确定性的常见指标,推测的置信度评估逻辑:
class ConfidenceEstimator:
"""
推测的置信度评估逻辑
基于: Anthropic 博客对模型不确定性的讨论 + 通用 LLM 工程实践
"""
def estimate(self, generation_output) -> float:
signals = []
# 信号 1: Token 熵值
# 高熵 = 模型在多个选项间犹豫 = 低置信度
if hasattr(generation_output, 'token_entropy'):
entropy_score = 1.0 - min(generation_output.token_entropy / 2.0, 1.0)
signals.append(entropy_score)
# 信号 2: 拒绝模式检测
# 出现 "我不确定"、"可能"、"大概" 等不确定表达
uncertainty_markers = [
"我不确定", "I'm not sure", "uncertain",
"可能", "probably", "maybe",
"需要更多信息", "need more information"
]
has_uncertainty = any(marker in generation_output.text
for marker in uncertainty_markers)
signals.append(0.0 if has_uncertainty else 1.0)
# 信号 3: 自我纠正请求
# 模型主动提出需要验证或检查
if "让我再检查一下" in generation_output.text or \
"let me verify" in generation_output.text.lower():
signals.append(0.3) # 明显不自信
# 信号 4: 领域复杂度标记
# 某些领域(法律、医疗、数学证明)默认触发咨询
if generation_output.domain in ['legal', 'medical', 'mathematical_proof']:
signals.append(0.5) # 降低阈值
return sum(signals) / len(signals) if signals else 0.5
# 推测的咨询触发阈值
CONSULTATION_THRESHOLD = 0.6 # 置信度低于此值时触发咨询可信度评估:★★☆☆☆(基于公开论文中 LLM 不确定性检测方法的合理推测,非 Anthropic 官方实现)
3.3 上下文合并机制(推测)⚠️
当触发咨询时,推测的上下文打包方式:
def package_consultation_context(
original_task: str,
executor_draft: str,
executor_confidence: float
) -> dict:
"""
推测的上下文打包逻辑
"""
return {
"consultation_request": {
"original_query": original_task,
"executor_attempt": executor_draft,
"executor_confidence": executor_confidence,
"uncertainty_regions": extract_uncertain_parts(executor_draft),
"timestamp": datetime.now().isoformat()
}
}
# 顾问返回的建议格式(推测)
advisor_response_format = """
<advisor_analysis>
<uncertainty_assessment>
执行者的主要不确定点分析...
</uncertainty_assessment>
<suggested_improvements>
<point priority="high">建议 1...</point>
<point priority="medium">建议 2...</point>
</suggested_improvements>
<confidence_recommendation>
建议的置信度阈值调整...
</confidence_recommendation>
</advisor_analysis>可信度评估:★★☆☆☆(基于 XML 是 Claude 偏好的结构化格式,以及系统提示词中常见的包装模式推测)
四、黑箱清单 ❓
🕵️ 本章导读:与其假装知道,不如坦诚列出我们目前确实不知道的东西。以下是公开渠道无法获得确切答案的问题。如果 Anthropic 某天公布技术白皮书,本文会第一时间更新。
以下问题目前无法从公开渠道获得确切答案:
| 问题 | 状态 | 说明 |
|---|---|---|
| 具体置信度阈值是多少? | ❓ 未公开 | 可能是动态调整,可能是固定值,官方未披露 |
| 是否包含"求助行为"的强化学习训练? | ❓ 未公开 | 模型训练细节属于商业机密 |
| Token 如何计费?分别计费还是合并? | ❓ 未公开 | 定价页面未说明 Advisor 模式特殊计费规则 |
| 顾问模型的系统提示词是什么? | ❓ 未公开 | 闭源,无法获取 |
| 单次任务的最大咨询次数上限? | ❓ 未公开 | API 文档未明确限制 |
| 是否存在咨询循环的风险控制? | ❓ 未公开 | 如 A→B→A 的循环调用是否有拦截机制 |
为什么这些重要:这些是判断"原理到实现"深度的核心问题。本文作为架构设计分析,坦诚标注未知比假装知道更负责任。
五、代码对比:一行配置 vs 自建路由
💡 本章导读:这是本文最实用的对比章节。我们会用完整的 40 行代码,展示"不用 Advisor 时需要自己实现什么",然后对比"用 Advisor 时只需要写什么"。差距一目了然。
5.1 传统自建路由(~40 行代码)
这是不使用 Advisor 时,开发者需要自己实现的完整路由逻辑:
import anthropic
import re
class ManualRouter:
"""手动实现 Sonnet → Opus 的路由逻辑"""
def __init__(self):
self.client = anthropic.Anthropic()
# 需要自己定义不确定性关键词
self.UNCERTAINTY_PATTERNS = [
r"不确定", r"可能", r"需要.*确认",
r"not sure", r"uncertain", r"might"
]
def detect_uncertainty(self, text: str) -> bool:
"""手动检测模型输出的不确定性"""
return any(re.search(p, text, re.IGNORECASE)
for p in self.UNCERTAINTY_PATTERNS)
def call_sonnet(self, messages) -> dict:
"""调用 Sonnet"""
return self.client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=messages
)
def call_opus(self, task, sonnet_output) -> dict:
"""调用 Opus,传入 Sonnet 的输出作为上下文"""
return self.client.messages.create(
model="claude-opus-4",
max_tokens=4096,
messages=[{
"role": "user",
"content": f"""任务: {task}
以下是较轻量模型的尝试结果,请指出问题并给出改进建议:
---
{sonnet_output}
---"""
}]
)
def route(self, messages, max_opus_calls=2) -> str:
"""核心路由逻辑"""
opus_calls = 0
while opus_calls < max_opus_calls:
# Step 1: Sonnet 尝试
sonnet_resp = self.call_sonnet(messages)
sonnet_text = sonnet_resp.content[0].text
# Step 2: 检查是否需要升级
if not self.detect_uncertainty(sonnet_text):
return sonnet_text # 置信度够,直接返回
# Step 3: 调用 Opus
opus_resp = self.call_opus(messages[-1]["content"], sonnet_text)
opus_advice = opus_resp.content[0].text
# Step 4: 合并上下文,让 Sonnet 重新生成
messages.append({"role": "assistant", "content": sonnet_text})
messages.append({"role": "user", "content": f"参考顾问建议:{opus_advice}\n请基于此改进你的回答。"})
opus_calls += 1
return sonnet_text # 达到上限,返回最后一次结果
# 使用:需要实例化、配置、调参
router = ManualRouter()
result = router.route(messages=[{"role": "user", "content": "分析合同法律风险"}])5.2 Advisor 模式
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=[{"type": "advisor_20260301"}], # 仅此一行
messages=[{"role": "user", "content": "分析合同法律风险"}]
)5.3 差异对比
| 维度 | 传统自建路由 | Advisor 模式 |
|---|---|---|
| 代码量 | ~40 行 | 1 行 |
| 不确定性检测 | 需自己写正则/分类器 | 模型内置(黑箱) |
| 上下文传递 | 需手动拼接 | 自动处理 |
| 调用次数控制 | 需自己实现 | max_advisor_calls 参数 |
| 可定制性 | 高(完全可控) | 低(无法调判断逻辑) |
| 可观测性 | 高(每个步骤你都知道) | 低(黑箱运行) |
| 维护成本 | 高(关键词需持续更新) | 低(Anthropic 维护) |
六、竞品对比
💡 本章导读:Claude Advisor 不是唯一的选择。OpenAI 和 Google 也提供了类似能力,但实现路径完全不同。这里我们基于各平台的公开 API 文档做功能对比,帮你快速了解行业现状。
| 维度 | Claude Advisor | OpenAI GPT | Google Gemini |
|---|---|---|---|
| 模型协作触发 | 模型自主判断(黑箱) | 开发者显式控制 | 开发者显式控制 |
| 强弱模型路由 | 内置(Sonnet→Opus) | 需自建路由层 | 需自建路由层 |
| 使用复杂度 | 低(一行配置) | 中(需写判断逻辑) | 中(需写判断逻辑) |
| 可控性 | 低(无法干预判断逻辑) | 高(完全可控) | 高(完全可控) |
| 透明度 | 低(不知道何时/为何咨询) | 高(代码即逻辑) | 高(代码即逻辑) |
| 适用场景 | 快速原型、不想写路由逻辑 | 生产环境、需精细控制 | 生产环境、需精细控制 |
6.1 什么时候选 Advisor?
适合场景:
-
快速验证 MVP,不想投入工程资源写路由逻辑
-
任务边界模糊,难以用规则定义"何时需要强模型"
-
对成本不敏感,优先考虑开发速度
不适合场景:
-
需要精确控制成本的场景(无法预测何时触发咨询)
-
需要审计追踪的场景(不知道模型为何咨询)
-
延迟敏感的场景(咨询过程增加额外 RTT)
七、实际应用示例
💡 本章导读:代码时间到!我们准备了三个层次的示例:先来一个5分钟快速体验,再看完整的业务场景代码。
7.0 5 分钟快速体验
想最快感受 Advisor 的效果?试试这个经典的"伪证明"数学题——它恰恰是 Sonnet 容易"自我怀疑"的那类问题:
import anthropic
import os
client = anthropic.Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
# 著名的"1=2"伪证明,Sonnet 可能需要求助
tricky_prompt = """
请判断以下证明过程是否正确:
证明 1 = 2:
1. 令 a = b
2. 两边同乘a: a² = ab
3. 两边同减b²: a² - b² = ab - b²
4. 因式分解: (a+b)(a-b) = b(a-b)
5. 两边同除(a-b): a+b = b
6. 因为 a=b, 代入: b+b = b -> 2b = b
7. 两边同除b: 2 = 1
请问这个证明的漏洞在哪里?
"""
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=[{"type": "advisor_20260301"}],
messages=[{"role": "user", "content": tricky_prompt}]
)
print(response.content[0].text)
# 查看是否触发了 Advisor
if hasattr(response, 'advisor_metadata'):
print(f"\n---\n✨ 本次回答触发了 Advisor 策略!")
print(f"咨询原因: {response.advisor_metadata.consultation_reason}")
else:
print("\n---\n👌 本次回答未触发 Advisor,Sonnet 独立完成。")💡 预期结果:Sonnet 应该能发现第5步"两边同除(a-b)"时 a-b=0,不能做除法。但因为这是一个涉及数学严谨性的证明题,Advisor 很可能被触发作为"第二道防线"来验证推理。
7.1 法律合同审查
import anthropic
client = anthropic.Anthropic()
contract_text = """
本协议自签署之日起生效,有效期为三年。
任何一方可在提前30天书面通知对方后终止本协议。
...(合同内容)...
"""
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=[{"type": "advisor_20260301"}],
messages=[{
"role": "user",
"content": f"""
请审查以下合同,识别其中的隐藏法律风险:
{contract_text}
需要特别关注:
1. 对甲方不利的条款
2. 表述模糊可能引发争议的条款
3. 违约责任不对等的条款
"""
}]
)
print(response.content[0].text)
# 检查是否触发了 Advisor
if hasattr(response, 'advisor_metadata'):
print(f"咨询次数: {response.advisor_metadata.calls_made}")
print(f"触发原因: {response.advisor_metadata.consultation_reason}")7.2 数学证明验证
# 在数学证明这类需要高置信度的场景,Advisor 可能频繁触发
math_problem = """
证明:对于任意正整数 n,存在 n 个连续的合数。
"""
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=[{"type": "advisor_20260301"}],
messages=[{
"role": "user",
"content": f"请给出严谨的数学证明:\n\n{math_problem}"
}]
)八、生产环境:监控与成本控制
💡 本章导读:看完前面的内容,你可能会问:"如果 Advisor 是黑箱,我在生产环境怎么用?" 本章提供两个实用方案:监控工具(让你知道它被触发了多少次)和成本估算(帮你判断预算是否扛得住)。
8.1 监控 Advisor 调用情况
在实际生产中,你需要追踪 Advisor 的触发频率和成本影响:
import anthropic
import time
class AdvisorMonitor:
"""监控 Advisor 调用情况的包装器"""
def __init__(self):
self.client = anthropic.Anthropic()
self.stats = {
"total_calls": 0,
"advisor_triggered": 0,
"total_advisor_tokens": 0,
"latency_with_advisor": [],
"latency_without_advisor": [],
}
def call_with_tracking(self, messages, enable_advisor=True):
"""带追踪的 API 调用"""
tools = [{"type": "advisor_20260301"}] if enable_advisor else []
start = time.perf_counter()
response = self.client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=tools,
messages=messages
)
elapsed = time.perf_counter() - start
self.stats["total_calls"] += 1
# 解析 Advisor 元数据
if hasattr(response, 'advisor_metadata'):
self.stats["advisor_triggered"] += 1
self.stats["latency_with_advisor"].append(elapsed)
if hasattr(response, 'usage') and \
hasattr(response.usage, 'advisor_tokens'):
self.stats["total_advisor_tokens"] += \
response.usage.advisor_tokens
print(f"[Advisor] 触发咨询: "
f"{response.advisor_metadata.calls_made} 次, "
f"原因: {response.advisor_metadata.consultation_reason}, "
f"耗时: {elapsed:.2f}s")
else:
self.stats["latency_without_advisor"].append(elapsed)
return response
def print_stats(self):
"""输出统计摘要"""
total = self.stats["total_calls"]
triggered = self.stats["advisor_triggered"]
rate = triggered / total * 100 if total > 0 else 0
avg_with = (sum(self.stats["latency_with_advisor"]) /
len(self.stats["latency_with_advisor"])
if self.stats["latency_with_advisor"] else 0)
avg_without = (sum(self.stats["latency_without_advisor"]) /
len(self.stats["latency_without_advisor"])
if self.stats["latency_without_advisor"] else 0)
print(f"\n{'='*50}")
print(f"Advisor 调用统计")
print(f"{'='*50}")
print(f"总调用次数: {total}")
print(f"触发咨询次数: {triggered} ({rate:.1f}%)")
print(f"顾问Token消耗: {self.stats['total_advisor_tokens']:,}")
print(f"平均延迟(有咨询): {avg_with:.2f}s")
print(f"平均延迟(无咨询): {avg_without:.2f}s")
print(f"{'='*50}")
# 使用示例
monitor = AdvisorMonitor()
result = monitor.call_with_tracking(
messages=[{"role": "user", "content": "分析合同法律风险"}]
)
monitor.print_stats()8.2 性能数据:待实测 ⏳
⚠️ 重要提示:以下数据为 理论估算,未经实测。基于 Sonnet 和 Opus 的公开性能指标推导,仅供参考。如有条件,建议自行对照实验验证。
| 指标 | 理论估算 | 说明 |
|---|---|---|
| 触发咨询的额外延迟 | +1.5~3s | Opus 推理速度比 Sonnet 慢 2-3 倍 |
| 法律/医疗类任务触发率 | 估计 30-60% | 复杂度高,Sonnet 容易不确定 |
| 通用 QA 触发率 | 估计 5-15% | 简单问题直接回答 |
| 顾问 Token 消耗 | 约为执行者的 1.5-2x | 上下文打包 + Opus 输出较长 |
⚠️ 再次提醒:上述数值均为估算,实际表现可能因任务类型、上下文长度、温度参数等因素有显著差异。生产环境使用前务必实测。
如果你有条件实测,建议在以下三类任务上做对照实验:
简单问答(应该很少触发 Advisor)
多步推理(中等触发率)
专业领域(法律/数学,高触发率)
对照组:同任务不用 Advisor、纯 Sonnet 完成 vs 用 Advisor 完成,记录准确率、延迟、Token 消耗。
九、已知限制 ❓
💡 本章导读:除了第四章那些"不知道能否实现"的黑箱问题,还有一些已经确认做不到的限制。在做技术选型时,这些才是真正的"红线"。
除了第四章的黑箱问题,以下限制来自官方文档和实际使用的可确认信息:
| 限制 | 说明 | 影响 |
|---|---|---|
| 仅支持 Sonnet → Opus 方向 | 不能自定义执行者/顾问组合(如 Haiku → Sonnet) | 灵活性不足 |
| 无法干预判断逻辑 | 黑箱运行,不能调整置信度阈值、关键词列表 | 无法针对业务优化 |
| 无法关闭特定领域触发 | 如果模型认为数学题需要咨询,无法阻止 | 可能产生不必要的成本 |
| 依赖 Anthropic API | 无离线/私有化部署选项 | 数据合规场景受限 |
| 顾问模型不可更换 | 只能用 Opus 作为顾问 | 如果未来有更强模型需等待官方更新 |
| 无实时流式咨询反馈 | 咨询过程对用户不可见,只能看到最终结果 | 无法做渐进式 UI 展示 |
advisor_metadata 仍在 Beta |
字段结构可能变动 | 生产代码需做好适配准备 |
这些限制意味着:Advisor 适合快速原型和内部工具,不适合对可解释性、成本控制有严格要求的生产环境。
十、诚实结论
10.1 Advisor 策略的本质
Claude Advisor 策略是一种"封装好的模型协作模式"——它把"轻模型不确定时咨询强模型"这个常见的工程需求,下沉到模型层面自动完成。
核心价值:降低开发者的心智负担,一行代码启用强弱模型协作。 核心代价:失去透明度和控制力,运行过程成为黑箱。
10.2 "原理到实现"的困境
本文标题未使用"原理到实现",原因在于:
对于闭源系统,真正的"原理到实现"需要以下至少之一:
-
官方技术白皮书披露架构细节
-
大规模 API 行为逆向工程
-
开源实现代码
目前 Anthropic 未提供以上任何一项。因此,负责任的技术写作应该:
-
明确标注哪些是官方确认的事实
-
坦诚说明哪些是合理推测
-
诚实列出哪些是未知的黑箱
10.3 决策树:我该用 Advisor 吗?
如果你还在纠结是否使用 Advisor,可以用以下决策树快速判断:
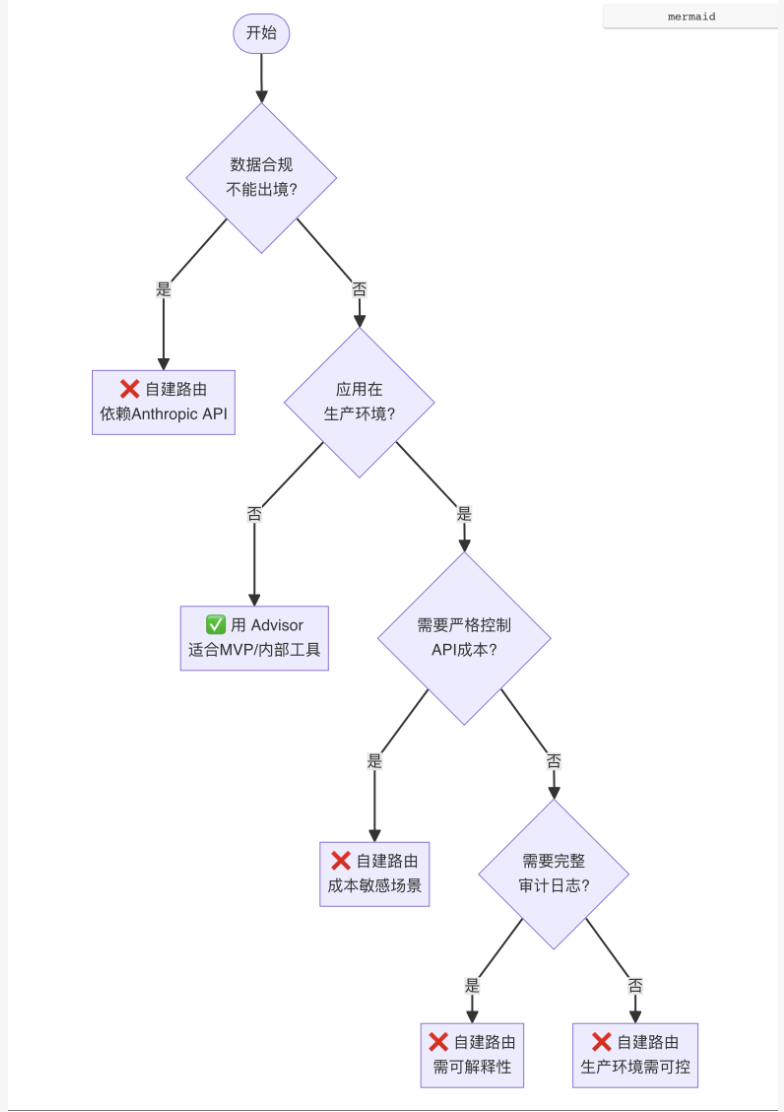
💡 解读:上面的决策树看起来 "几乎都不推荐 Advisor"?没错。因为 Advisor 的设计初衷就是"简化开发"而非"生产就绪"。如果你的场景足够简单到可以用 Advisor,通常也意味着你可以完全用 Sonnet 搞定,没必要引入 Opus 的成本。
快速对照表:
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 内部工具/MVP/原型 | ✅ Advisor | 省开发时间,成本可控 |
| 数据合规(数据不能出境) | ❌ 自建路由 | Advisor 依赖 Anthropic API |
| 对外产品(成本敏感) | ❌ 自建路由 | Advisor 成本不可预测 |
| 金融/医疗/法律合规场景 | ❌ 自建路由 | 需要完整审计日志 |
| 延迟敏感(实时交互) | ❌ 自建路由 | Advisor 可能增加 1-3s |
| 任务类型明确且稳定 | ❌ 自建路由 | 可以写规则优化,比黑箱高效 |
| 任务边界模糊多变 | ✅ Advisor | 黑箱自适应比规则更灵活 |
10.4 给你的建议
| 场景 | 建议 |
|---|---|
| 想快速验证想法 | 用 Advisor,省掉写路由的麻烦 |
| 数据合规要求 | 自建路由(本地模型),不能依赖海外 API |
| 需要精确控制成本 | 自己写路由逻辑,不用 Advisor |
| 需要审计和可解释性 | 自己写路由逻辑,不用 Advisor |
| 想深入理解机制 | 等 Anthropic 发布技术白皮书,或关注开源复现项目 |
💬 讨论区:你怎么看?
读完本文,你打算在自己的项目中用 Advisor 吗?还是更倾向于自建路由?
欢迎在评论区分享:
你的应用场景是什么?
你会选择 Advisor 还是自建路由?理由是什么?
如果 Anthropic 开放阈值调整接口,你会使用吗?
期待你的观点!👇
参考资料
-
Anthropic API Documentation - Tool Use ✅
-
Anthropic Blog: "Building effective agents" ✅
-
Simon Willison's analysis of Claude tool use patterns ⚠️
-
OpenAI Function Calling Documentation(竞品对比参考)✅
-
Google Gemini Function Calling Documentation(竞品对比参考)✅
声明:本文部分内容基于合理推测,已在文中明确标注可信度。如需100%准确的技术细节,建议直接联系 Anthropic 技术支持或等待官方技术白皮书。
📧 联系作者:如有实测数据愿意分享,或发现本文事实性错误,欢迎在评论区留言或私信指正。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)