我把Claude Code泄露的代码改造成python程序了,其中的大模型记忆模块与上下文工程分析
本文分析了Claude Code开源AI助手的记忆模块与上下文工程实现。记忆模块采用基于文件的持久化系统,支持4种记忆类型(用户、反馈、项目和引用记忆),通过自动梦境整合机制定期将临时日志转为持久化主题文件。上下文工程采用分块组装方式构建系统提示,包含静态规则和动态环境信息,并实现自动压缩机制处理长对话历史。系统通过模块化设计实现了跨会话记忆存储与智能上下文管理。
项目概述
Claude Code开源代码是一个交互式 AI 助手系统,下面我来详细解析Claude Code的记忆模块与上下文工程分析,其中采用模块化架构设计,本文档详细分析其记忆模块和上下文工程的实现机制。
我把Claude Code泄露的代码改造成python程序了,并且接入Qwen大模型,来进行问答。下面我将对Claude Code大模型记忆模块与上下文工程进行详细分析。
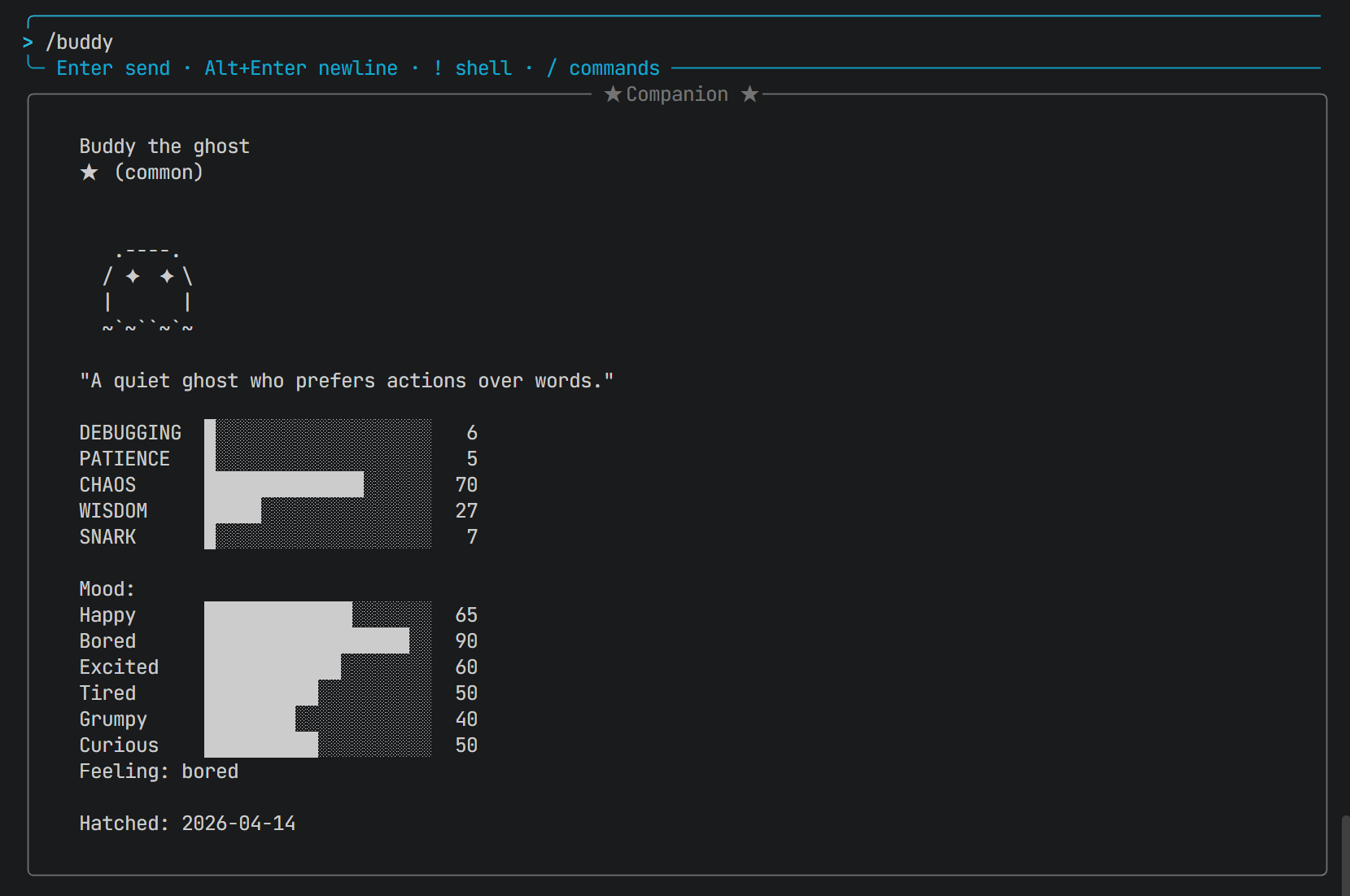
Claude Code中还有很多隐藏的功能,比如电子宠物:
一、记忆模块
1.1 架构设计
记忆模块位于 features/memory.py,采用基于文件的持久化系统,支持跨会话记忆存储和检索。
核心目录结构:
~/.config/cc-mini/
├── memory/ # 记忆存储目录
│ ├── MEMORY.md # 记忆索引文件(<200 行)
│ ├── logs/ # 按日追加的日志
│ │ └── YYYY/MM/YYYY-MM-DD.md
│ └── [topic].md # 主题记忆文件
└── sessions/ # 会话记录目录
└── [session_id].jsonl
1.2 记忆类型(4 种)
系统采用与 Claude Code 相同的 4 类型记忆分类:
1.2.1 用户记忆
- 用途:存储用户的角色、目标、职责和知识
- 保存时机:了解到用户的角色、偏好、职责或知识时
- 示例:用户是后端工程师,偏好使用 PostgreSQL
1.2.2 反馈记忆
- 用途:用户给出的指导或纠正,确保跨会话一致性
- 保存时机:用户纠正你的行为方式时
- 结构:
- 规则描述 - **Why:** 原因说明 - **How to apply:** 应用方式
1.2.3 项目记忆
- 用途:正在进行的工作、目标、bug 或事件
- 保存时机:了解到谁在做什么、为什么做、何时完成
- 要求:相对日期必须转换为绝对日期
1.2.4 引用记忆
- 用途:指向外部系统中信息的位置
- 示例:“bug 追踪在 Linear 项目 INGEST 中”
1.3 记忆保存方式
方式 A:<memory> 标签(快速笔记)
def extract_memory_tags(text: str) -> list[str]:
"""从文本中提取所有 <memory>...</memory> 标签内容"""
return [m.strip() for m in re.findall(r"<memory>(.*?)</memory>", text, re.DOTALL)]
在对话中,模型可以输出:
<memory>用户偏好使用 PostgreSQL 而非 MySQL</memory>
系统会自动提取并追加到当日日志。
方式 B:结构化文件(持久化记忆)
写入 .md 文件到记忆目录,使用 frontmatter 格式:
---
name: 用户数据库偏好
description: 用户对数据库的技术偏好
type: user
---
用户偏好使用 PostgreSQL 而非 MySQL,因为需要复杂查询支持。
然后在 MEMORY.md 中添加索引指针:
- [用户数据库偏好](user-db-preference.md) — 技术偏好说明
1.4 记忆不保存的内容
系统明确规定了不应保存的内容:
- 代码模式、架构、文件路径(可从代码库读取)
- Git 历史、最近变更(
git log/git blame是权威来源) - 调试解决方案(修复在代码中,上下文在 commit message)
- CLAUDE.md 文件中已记录的内容
- 临时任务详情或当前对话上下文
1.5 自动梦境整合(Auto Dream)
系统实现了自动记忆整合机制,定期将日志中的临时记忆整合为持久化主题文件。
触发条件:
def should_auto_dream(memory_dir, min_hours, min_sessions, current_session_id):
"""
检查是否触发自动整合:
1. 时间间隔 ≥ min_hours(默认由配置决定)
2. 新会话数 ≥ min_sessions
3. 包含 10 分钟扫描节流,避免频繁检查
"""
锁机制:
- 锁文件:
.consolidate-lock - 锁持有者 PID 存储在文件内容中
- 锁过期时间:1 小时(3600 秒)
- 支持锁回收(持有者进程死亡后)
1.6 梦境整合流程
整合过程分为 4 个阶段:
Phase 1 - Orient(定位)
- 使用 Glob 列出记忆目录中的所有文件
- 读取
MEMORY.md了解当前索引 - 浏览现有主题文件,避免重复创建
Phase 2 - Gather(收集)
按优先级收集新信息:
- 日志文件:追加式日志流
- 漂移的记忆:与当前代码库矛盾的事实
- 转录搜索:使用 grep 搜索 JSONL 转录中的关键术语
Phase 3 - Consolidate(整合)
- 将新信息合并到现有主题文件
- 将相对日期转换为绝对日期
- 删除矛盾的事实
Phase 4 - Prune and Index(修剪和索引)
- 更新
MEMORY.md,保持在 200 行以内 - 每行 <150 字符:
- [标题](文件.md) — 一句话钩子 - 移除过时、错误或已被取代的记忆指针
1.7 会话持久化
会话记录采用 JSONL 格式(每行一个 JSON 对象):
def save_session(messages: list[dict], session_id: str) -> None:
"""序列化消息到 JSONL 并更新 last-session 符号链接"""
SESSIONS_DIR.mkdir(parents=True, exist_ok=True)
path = SESSIONS_DIR / f"{session_id}.jsonl"
with path.open("w", encoding="utf-8") as f:
for msg in messages:
f.write(json.dumps(serialize_message(msg), default=str) + "\n")
SessionStore 类管理单个会话:
append_message():追加消息到 JSONLload_messages():从 JSONL 读取所有消息list_sessions():列出可用会话(按更新时间排序)- 自动生成标题(从第一条用户消息提取)
二、上下文工程
2.1 系统提示架构
系统提示采用分块组装方式,位于 core/context.py。
静态部分(按顺序):
- Intro Section:角色介绍和安全准则
- System Section:系统行为规则
- Doing Tasks Section:任务执行指南
- Actions Section:操作风险评估
- Using Tools Section:工具使用偏好
- Tone and Style Section:沟通风格
- Output Efficiency Section:输出效率要求
动态部分:
- Environment Section:工作目录、Git 状态、平台信息
- Git Section:当前分支、状态、最近提交
- CLAUDE.md Section:项目特定指令(如果存在)
- Memory Section:记忆系统指令和索引
- Companion Section:AI 伴侣介绍(如果启用)
- Plan Mode Section:计划模式指令(如果激活)
2.2 记忆系统注入
记忆系统通过 build_memory_system_section() 函数注入到系统提示:
def build_memory_system_section(memory_dir: Path) -> str:
"""返回记忆指令 + MEMORY.md 内容"""
index = load_memory_index(memory_dir) # 读取 MEMORY.md,截断到 10,000 字符
section = """
# Auto Memory
You have a persistent, file-based memory system at `{memory_dir}/`.
...
[完整的记忆类型说明和保存指南]
"""
if index:
section += f"\n## Current Memory Index (MEMORY.md)\n{index}\n"
return section
2.3 上下文压缩
当上下文接近模型限制时,系统会自动压缩历史消息。
核心机制:
class CompactService:
def compact(self, messages, system_prompt, custom_instructions=""):
"""压缩消息列表,返回 (new_messages, summary_text)"""
history, recent = _split_recent(messages) # 分离历史和最近消息
# 对历史部分调用 LLM 生成摘要
summary = self._client.create_message(
model=self._model,
max_tokens=COMPACT_MAX_OUTPUT_TOKENS, # 4096
system=COMPACT_SYSTEM,
messages=cleaned_history,
)
# 构建新消息列表:[摘要用户消息] [确认助手消息] [最近消息]
new_messages = [
{"role": "user", "content": summary},
{"role": "assistant", "content": "Understood..."},
]
new_messages.extend(recent)
return new_messages, summary
2.4 压缩触发条件
自动压缩阈值计算:
def _auto_compact_threshold(model: str) -> int:
"""context_window - max_output_reserve - buffer"""
cw = _context_window_for_model(model) # 模型上下文窗口
max_out_reserve = min(20_000, cw // 5) # 预留输出空间
return cw - max_out_reserve - AUTOCOMPACT_BUFFER_TOKENS # buffer=13,000
模型上下文窗口:
| 模型系列 | 上下文窗口 |
|---|---|
| claude-opus-4-6 | 1,000,000 |
| claude-sonnet-4-6 | 1,000,000 |
| claude-opus-4 | 200,000 |
| claude-sonnet-4 | 200,000 |
| claude-3-5-sonnet | 200,000 |
触发判断:
def should_compact(messages, model=None, last_input_tokens=None):
if last_input_tokens and model:
# 使用 API 返回的实际 token 数
return last_input_tokens >= _auto_compact_threshold(model)
# 回退到基于字符的估算
return estimate_tokens(messages) > COMPACT_THRESHOLD_TOKENS # 100,000
2.5 消息分割策略
压缩时会保留最近的对话:
def _split_recent(messages):
"""分离 (待摘要历史, 保留的最近消息)"""
# 向后遍历,直到满足两个条件:
# 1. 至少 MIN_RECENT_MESSAGES = 6 条消息
# 2. 至少 MIN_RECENT_TOKENS = 10,000 个 token
# 保证不分割 tool_use / tool_result 对
if keep_start > 0:
msg = messages[keep_start]
if msg 是纯 tool_results 的用户消息:
keep_start -= 1 # 包含前一条助手消息
2.6 摘要提示词
压缩使用的提示词结构:
## Primary Request
用户的总体目标
## Key Technical Concepts
建立的技术概念、模式、框架或约束
## Files and Code
讨论或修改的关键文件及简要说明
## Errors and Fixes
遇到的错误及解决方式
## Current Work
最近工作内容及当前状态
## Pending Tasks
未完成的任务或下一步
2.7 媒体剥离
压缩前会剥离历史消息中的图片/文档以节省 token:
def _strip_media(messages):
"""将 images/documents 替换为文本标记"""
for block in content:
if block.type == "image":
new_blocks.append({"type": "text", "text": "[image]"})
elif block.type == "document":
new_blocks.append({"type": "text", "text": "[document]"})
三、LLM 客户端抽象
3.1 多提供商支持
core/llm.py 实现了对 Anthropic 和 OpenAI 的抽象:
class LLMClient:
def __init__(self, provider="anthropic", api_key=None, base_url=None):
self.provider = validate_provider(provider)
if provider == "openai":
self._client = OpenAI(api_key, base_url)
else:
self._client = anthropic.Anthropic(api_key, base_url)
3.2 流式响应
支持流式输出和工具调用:
def stream_messages(self, model, max_tokens, messages, system, tools):
if provider == "openai":
return _OpenAIStream(...)
return _AnthropicStream(...)
3.3 错误处理
重试机制:
_MAX_RETRIES = 10
_BASE_DELAY = 0.5
_MAX_DELAY = 32.0
def _compute_retry_delay(attempt, retry_after=None):
if retry_after:
return retry_after # 尊重 API 的 Retry-After 头
# 指数退避 + 抖动
delay = min(_BASE_DELAY * (2 ** attempt), _MAX_DELAY)
jitter = delay * random.uniform(0, 0.25)
return delay + jitter
错误类型分类:
- 认证错误:立即返回,不重试
- 上下文溢出:减少 max_tokens 后重试
- 可重试错误(限流、连接、内部错误):指数退避重试
- 其他 API 错误:返回错误信息
四、成本追踪
4.1 Token 成本计算
features/cost_tracker.py 实现成本追踪:
@dataclass(frozen=True)
class _PricingTier:
input: float # $/MTok
output: float
cache_write: float
cache_read: float
定价层级示例:
| 模型 | 输入 | 输出 | 缓存写 | 缓存读 |
|---|---|---|---|---|
| claude-3-5-haiku | $0.80 | $4.0 | $1.0 | $0.08 |
| claude-sonnet | $3.0 | $15.0 | $3.75 | $0.30 |
| claude-opus-4-1 | $15.0 | $75.0 | $18.75 | $1.50 |
4.2 成本计算公式
def calculate_cost(model, usage):
tier = _tier_for_model(model)
cost = (
input_tokens * tier.input
+ output_tokens * tier.output
+ cache_read * tier.cache_read
+ cache_write * tier.cache_write
) / 1_000_000
return cost
注意:Anthropic API 的 input_tokens 已排除缓存 token,缓存部分单独计费。
4.3 Advisor 成本
Advisor 功能(智能建议)的 token 单独计费:
if advisor_in or advisor_out:
advisor_tier = _tier_for_model(advisor_model)
advisor_cost = (
advisor_in * advisor_tier.input
+ advisor_out * advisor_tier.output
) / 1_000_000
五、关键设计模式
5.1 追加式日志(Append-Only Logs)
日志采用追加式写入,保证数据完整性:
def append_to_daily_log(memory_dir, entry):
path = daily_log_path(memory_dir) # YYYY/MM/YYYY-MM-DD.md
timestamp = datetime.now().strftime("%H:%M")
with path.open("a", encoding="utf-8") as f:
f.write(f"- [{timestamp}] {entry}\n")
5.2 索引与内容分离
MEMORY.md 仅作为索引,不包含实际记忆内容:
- 索引文件:<200 行,每行<150 字符
- 主题文件:完整记忆内容
- 优势:系统提示中只注入索引,节省 token
5.3 锁文件模式
使用文件 mtime 作为时间戳,文件内容为 PID:
def try_acquire_lock(memory_dir):
lp = _lock_path(memory_dir)
# 检查锁是否过期(>1 小时)
# 检查持有者进程是否存活
# 写入自己的 PID
lp.write_text(str(os.getpid()))
5.4 节流机制
防止频繁扫描会话文件:
_SESSION_SCAN_INTERVAL_S = 600 # 10 分钟
if now - _last_session_scan_at < SESSION_SCAN_INTERVAL_S:
return False # 跳过本次检查
_last_session_scan_at = now
5.5 角色交替保证
API 要求消息严格的用户/助手交替:
def _fix_alternation(messages):
fixed = [messages[0]]
for msg in messages[1:]:
if msg["role"] == fixed[-1]["role"]:
# 合并到前一条消息
fixed[-1]["content"] = prev + "\n" + cur
else:
fixed.append(msg)
return fixed
六、总结
记忆模块核心特性
- 4 类型分类法:user/feedback/project/reference
- 双模式保存:
<memory>标签(临时)和结构化文件(持久) - 自动整合:基于时间和会话数的触发条件
- 锁机制:防止并发整合冲突
- 索引分离:MEMORY.md 仅作索引,节省 token
上下文工程核心特性
- 分块组装:静态 + 动态部分模块化组合
- 自动压缩:基于模型上下文窗口的智能阈值
- 消息分割:保留最近 6 条消息或 10k token
- 媒体剥离:压缩前移除图片/文档
- 结构化摘要:7 部分摘要模板
设计亮点
- 追加式日志:简单可靠,易于回溯
- 节流机制:避免不必要的频繁操作
- 错误恢复:多层次重试和回退策略
- 成本感知:实时追踪 token 使用和成本
- 多提供商:统一的 Anthropic/OpenAI 抽象
这套系统实现了持久化记忆、智能上下文管理和成本优化的平衡,为长周期 AI 助手交互提供了坚实基础。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)