DeepSeek-V3:开源大模型的性能革命与商业落地新范式
DeepSeek-V3以6710亿总参数、370亿激活参数的混合专家架构,在保持开源属性的同时实现了逼近闭源模型的性能,重新定义了企业级AI部署的成本与效率边界。## 行业现状:大模型的"效率困境"与技术突围2025年,大语言模型行业正面临性能与成本的双重挑战。一方面,企业对高精度专业咨询、大规模数据分析等需求持续增长;另一方面,传统稠密模型的部署成本居高不下。中国软件行业协会数据显示,78
DeepSeek-V3:开源大模型的性能革命与商业落地新范式
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3 导语
DeepSeek-V3以6710亿总参数、370亿激活参数的混合专家架构,在保持开源属性的同时实现了逼近闭源模型的性能,重新定义了企业级AI部署的成本与效率边界。
行业现状:大模型的"效率困境"与技术突围
2025年,大语言模型行业正面临性能与成本的双重挑战。一方面,企业对高精度专业咨询、大规模数据分析等需求持续增长;另一方面,传统稠密模型的部署成本居高不下。中国软件行业协会数据显示,78%的企业期望提升AI响应速度,65%关注数据安全合规,但超过半数企业认为现有解决方案成本过高。
混合专家模型(Mixture-of-Experts, MoE)通过"稀疏激活"机制成为破局关键。这种架构将模型参数分散到多个"专家"子网络中,仅激活与当前任务相关的部分专家,在保持大模型能力的同时大幅降低计算资源需求。DeepSeek-V3正是这一技术路线的集大成者,其6710亿总参数中仅370亿参与推理,实现了性能与效率的平衡。
模型亮点:三大技术突破重构开源模型能力边界
1. 多头潜在注意力:效率与性能的双重优化
DeepSeek-V3创新性地采用多头潜在注意力(MLA)替代传统分组查询注意力(GQA)。这一机制通过将键值张量压缩至低维空间存储,在减少KV缓存内存占用的同时提升建模性能。实验数据显示,MLA在BBH(87.5%)、MMLU(87.1%)等基准测试中显著优于GQA架构,尤其在长上下文理解任务中表现突出。
2. 动态负载均衡与多token预测:推理效率的革命性提升
模型引入无辅助损失的负载均衡策略,解决了传统MoE架构中专家负载不均的问题。同时,创新的多token预测训练目标不仅提升了性能,还支持推测性解码加速推理。在SWE-Bench验证集测试中,DeepSeek-V3解决真实GitHub问题的准确率达65.2%,在MBPP代码生成任务中更是达到75.4%的Pass@1分数。
3. 全栈硬件适配:从数据中心到边缘设备的灵活部署
DeepSeek-V3实现了对多硬件平台的深度优化,支持从NVIDIA GPU到AMD GPU再到华为Ascend NPU的全栈部署。配合SGLang、LMDeploy等推理框架,企业可根据规模选择灵活方案:基础配置(8×H200 GPU)支持日均10万对话,单次成本约0.012元;规模部署(16节点集群)可处理百万级日活,成本降至0.005元/对话。
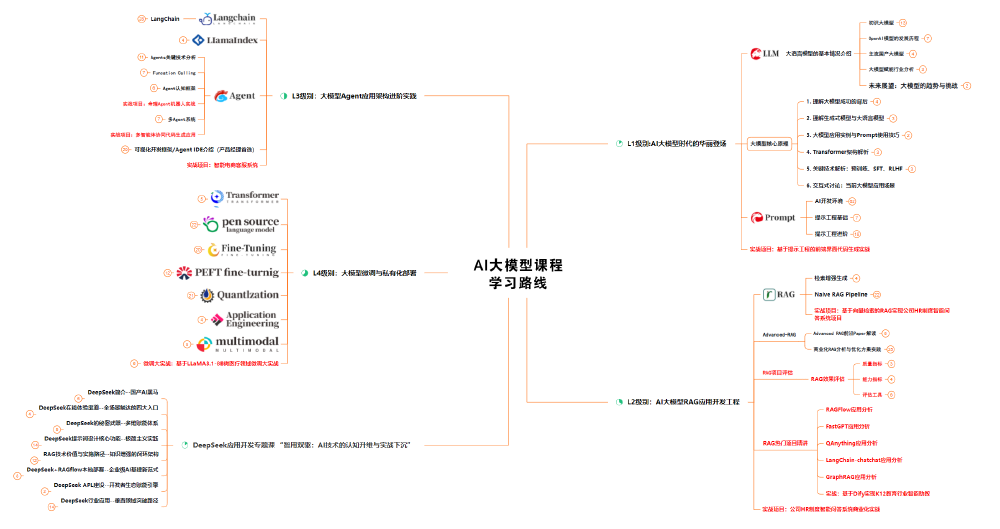
如上图所示,该思维导图展示了大模型技术体系的完整知识框架,其中DeepSeek-V3代表的MoE架构处于核心位置。这一技术路线通过多头潜在注意力、动态负载均衡等创新,正在重构大模型的性能边界与应用生态。
行业影响:开源模型的商业化路径革新
1. 成本结构的根本性变革
采用DeepSeek-V3架构的企业AI部署三年TCO(总拥有成本)降低63%。对比传统方案:全人工客服三年成本约1080万,云服务API约720万,而自建DeepSeek-V3集群仅需400万(含硬件折旧)。非工作时间动态关闭50%推理节点等优化技巧,可进一步降低25-30%运行成本。
2. 企业服务模式的重构
DeepSeek-V3正在改变传统"顾问驻场"的企业服务模式。在制造业场景中,某客户通过基于DeepSeek-V3的业务流程自动化,使SAP系统上线周期从常规9个月压缩至4个月,需求分析阶段人力投入减少70%。这种"AI处理标准化工作,人类专注创造性任务"的协作模式,正成为企业数字化转型的新范式。
3. 开源生态的"三级盈利模型"
DeepSeek-V3采用MIT许可证的开放策略,允许企业基于该模型开发专有应用而无需公开修改代码。这种"开放核心"模式构建了可持续的商业生态:基础层通过免费模型吸引用户,中间层提供微调、部署等增值服务(单个企业客户年均付费10-50万元),顶层通过API调用分成实现长期收益。数据显示,DeepSeek系列模型的开发者社区在2025年已增长至15万用户,形成从基础模型到垂直应用的完整生态。
部署实践:从实验室到生产环境的全流程指南
硬件配置建议
根据模型规模和量化方案,企业可选择不同部署配置:
- 基础配置:8×H200 GPU支持日均10万对话,适用于中小型企业
- 规模部署:16节点集群可处理百万级日活,满足大型企业需求
- 边缘部署:通过INT4量化技术,可在消费级GPU上实现轻量级推理
主流推理框架支持
DeepSeek-V3已实现与主流推理框架的深度整合:
- SGLang:支持FP8/BF16推理,GPU效率提升160%
- LMDeploy:提供高效量化方案,推理延迟降低40%
- vLLM:支持多卡并行与流水线并行,吞吐量提升3倍
企业可通过以下命令快速启动本地部署:
git clone https://gitcode.com/hf_mirrors/deepseek-ai/DeepSeek-V3
cd DeepSeek-V3/inference
pip install -r requirements.txt
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo
结论:开源模型的黄金时代来临
DeepSeek-V3的发布标志着开源大模型从"技术普惠"向"商业共赢"的关键转折。其在保持MIT许可证开源属性的同时,通过创新架构实现了性能突破:在MMLU-Pro(64.4%)、DROP(89.0%)等专业基准测试中超越同类开源模型,甚至在部分指标上逼近GPT-4o和Claude-3.5-Sonnet等闭源旗舰产品。
对于企业决策者而言,现在正是评估这一技术的最佳时机——在保持数据安全与成本控制的同时,借助DeepSeek-V3构建差异化AI能力。随着优化技术持续进步,预计未来12个月内,采用类似架构的企业AI部署成本将再降40%,推动生成式AI真正走进千行百业。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)