Claude Opus 4.7:视觉代码双封神,但也学会了“暗中涨价”和“不说人话”?
重度依赖视觉识别:处理密集数据图表、UI 截图或文档抽取的任务,Opus 4.7 的 3.75MP 高清视力是降维打击。构建复杂的 Agent 系统:它的自我修复能力和工具调用成功率提升了 10-15%,能显著减少崩溃死循环。文案创作与翻译:如果你依赖 Claude 的“好文笔”,建议先用少量任务进行 A/B 测试,看看你是否能忍受它新学的“AI 八股文”。成本敏感型团队:请务必监控升级后的第一周
Anthropic 在毫无预警的情况下,正式发布了其最新旗舰模型——Claude Opus 4.7。
虽然官方坦言这还不是他们内部正在测试的最强模型(Claude Mythos Preview),但 Opus 4.7 的核心能力依然带来了质的飞跃。
目前,该模型已在 Claude.ai、API、Amazon Bedrock 以及 Google Cloud Vertex AI 等全渠道上线。
尽管官方标价维持在 5 美元/百万输入 Token 和 25 美元/百万输出 Token,但先别高兴得太早——许多开发者和深度用户在实测后发现,这次更新藏着不少“坑”。
一、毫无争议的“史诗级”进化
1. 视觉能力爆表:从“近视眼”到“显微镜”
这是本次更新中最令人瞩目的亮点。
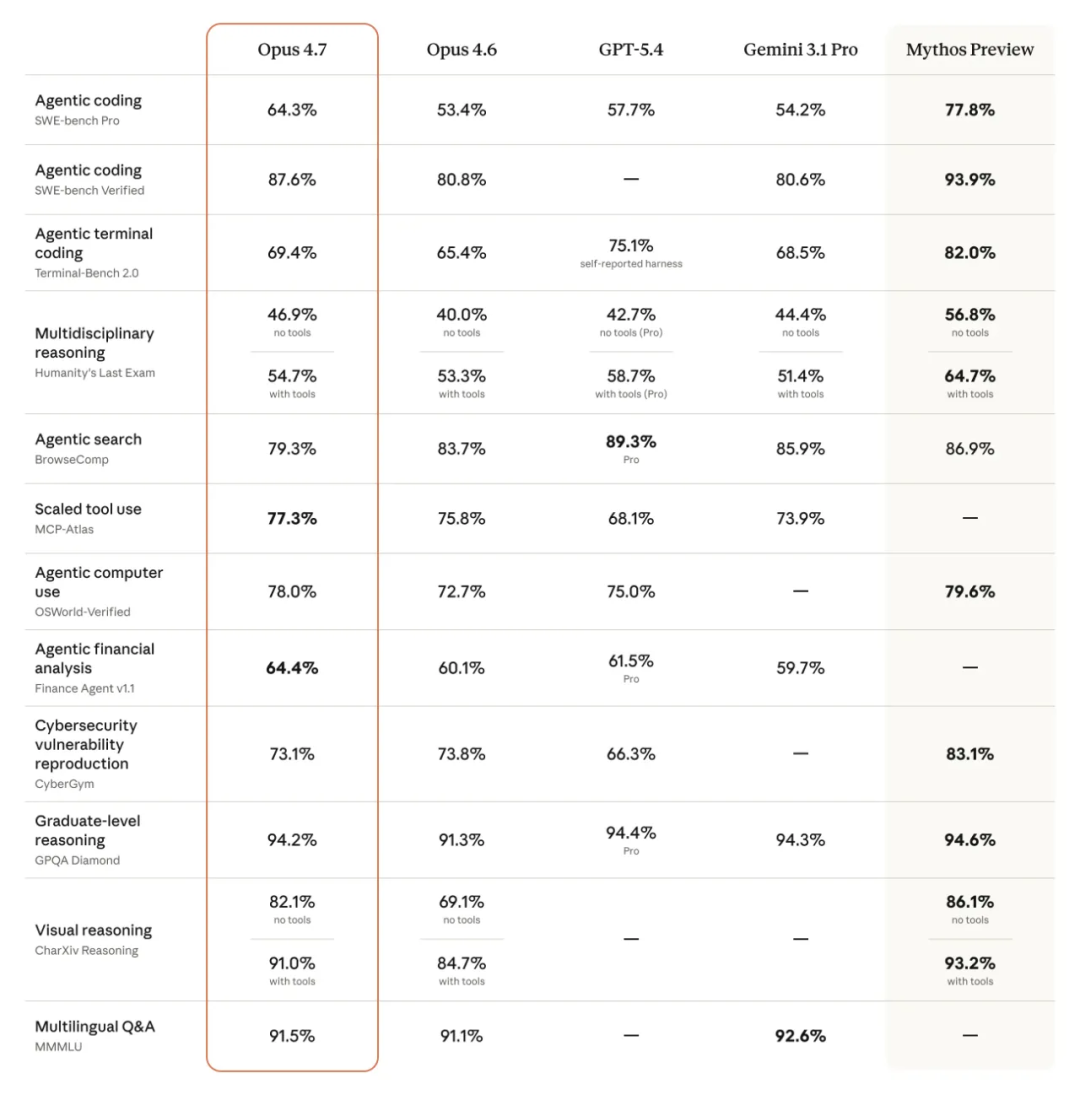
在 XBOW 视觉基准测试中,Opus 4.7 的视觉敏锐度从前代(4.6)的 54.5% 疯狂飙升至 98.5%。
分辨率翻倍:图像输入的最高分辨率达到了长边 2576 像素(约 3.75 百万像素),是前代模型的 3 倍以上。
实际体验:过去,给 Claude 喂复杂的终端截图、金融报表或密集的系统后台图,它经常会“看花眼”甚至产生幻觉。
现在,它可以精准读取小字、化学结构式和复杂的架构图,甚至能逐个分析竞品界面上的每个组件,彻底解决了生产力场景下的视觉痛点。
2. 代码与 Agent 能力:解决前代束手无策的难题
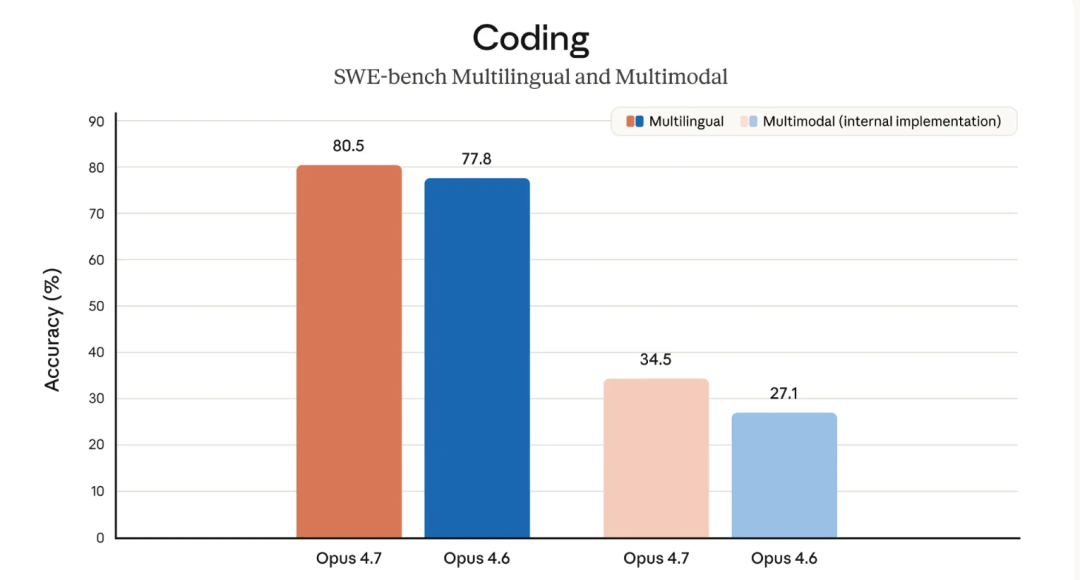
在业界权威的 SWE-bench Verified 评测中,Opus 4.7 拿下了 87.6% 的高分(前代为 80.8%),SWE-bench Pro 得分也跃升至 64.3%。
不仅是更快,而是更强:它能解决 Opus 4.6 甚至 Sonnet 4.6 根本无法破解的复杂并发 bug。
自我验证:在编写系统级代码之前,Opus 4.7 会自行进行数学证明和逻辑验证,遇到缺失数据会直接报错,而不是像过去那样强行编造答案。
新增 /ultrareview:Claude Code CLI 引入了深度代码审查功能,能像资深工程师一样做架构级别的 Review,Pro 和 Max 用户可免费试用 3 次。
3. 新增 xhigh 推理模式与 Task Budgets
xhigh 推理等级:在原本的 high 和 max 之间新增了一档,Anthropic 推荐将其作为处理复杂编程和 Agent 任务的默认起点。
它能在“深入思考”与“节省 Token”之间找到完美的甜蜜点。
Task Budgets(任务预算):针对长时间运行的复杂 Agent 任务,开发者现在可以为模型设定一个 Token 预算(最低 2万 Token),模型会看着“倒计时”来分配精力,避免前面花光预算导致任务半途而废。
二、警惕“暗坑”与社区大吐槽
尽管跑分华丽,但在 Reddit 等社区和资深开发者的实测中,Opus 4.7 却引发了大量争议。
1. 变相涨价与额度刺客
价格没变,但成本涨了。
Opus 4.7 使用了全新的 Tokenizer,导致同样的文本输入,现在会比以前多消耗 1.0 到 1.35 倍的 Token(最多增加约 35%)。
由于 Claude Code 默认将所有套餐的 effort 调至 xhigh,Reddit 上大量用户抱怨他们“仅仅问了几个问题就触发了 5 小时或周度使用限制”。
如果你是按量付费的 API 用户,月底的账单可能会让你大吃一惊。
2. 变得“太听话”,旧 Prompt 大量失效
Opus 4.7 的指令遵从度变得极其激进且字面化。
过去:如果你的提示词写得很模糊,Claude 会“善意地”结合上下文猜测你的意图。
现在:如果你写了“始终输出 JSON”,它连解释的废话都不会有,哪怕遇到需要澄清的问题也会强行输出纯 JSON。
这意味着你过去精心调优的 Prompt 库可能需要全部重新审计和修改。
3. 创作者的噩梦:它开始“不说人话”了
Claude 系列一直以其“文笔好、有人味”深受知识工作者和创作者的喜爱。
但部分重度用户实测发现,Opus 4.7 的行文风格出现了明显的降级。
它开始频繁使用诸如“稳稳接住”、“收口”、“压实”等极其僵硬、充满大厂“黑话”的 AI 浓汤体,丧失了此前的文学品味,越来越像 GPT-5.4 的机器人口吻。
对于非编程类的文本创作用户来说,这无疑是一个巨大的打击。
4. API 接口的“霸王条款”与性能倒退
长文本检索能力(MRCR 基准)腰斩:
Reddit 网友扒出,在 1M 上下文检索中,其得分从 4.6 版本的 78.3% 暴跌至 4.7 版本的 32.2%。
虽然官方解释这是因为测试方法的调整,但这依然引发了长文本用户的恐慌。
参数大砍:
在 API 中,temperature、top_p、top_k 等控制随机性的参数被直接移除(设置为非默认值将报错)。
同时,上一代的“扩展思考”被强制替换为“自适应思考”。
三、总结与建议:你应该立刻升级吗?
强烈建议立刻切换的情况:
重度依赖视觉识别:处理密集数据图表、UI 截图或文档抽取的任务,Opus 4.7 的 3.75MP 高清视力是降维打击。
构建复杂的 Agent 系统:它的自我修复能力和工具调用成功率提升了 10-15%,能显著减少崩溃死循环。
建议观望或谨慎操作的情况:
文案创作与翻译:如果你依赖 Claude 的“好文笔”,建议先用少量任务进行 A/B 测试,看看你是否能忍受它新学的“AI 八股文”。
成本敏感型团队:请务必监控升级后的第一周 Token 消耗量,Tokenizer 的改变可能会让你的账单飙升 30% 以上。
拥有庞大旧 Prompt 库:在部署到生产环境前,请预留至少一天时间重新审计和测试所有的提示词。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)