告别全网瞎搜!Claude 风格的 Easysearch 企业级实战助手从 0 到 1 实现
收益是——回答风格、必备章节(比如「官方文档溯源」)、Easysearch 与 ES 差异,小东西,省一大截排查时间。、盯 allocation 的人,要的是可复制命令和可追溯链接,不是空话。里真正填好的值给「挡掉」——这种坑在 Windows 上特别常见。,重启进程就生效——对排查类工具来说,这比先搭 K8s 实在多了。可以分开——文案短一点没关系,模型里仍然是完整 Markdown。——剩下才
这套 Easysearch 排查助手,从零到一到底做了什么?
系统介绍
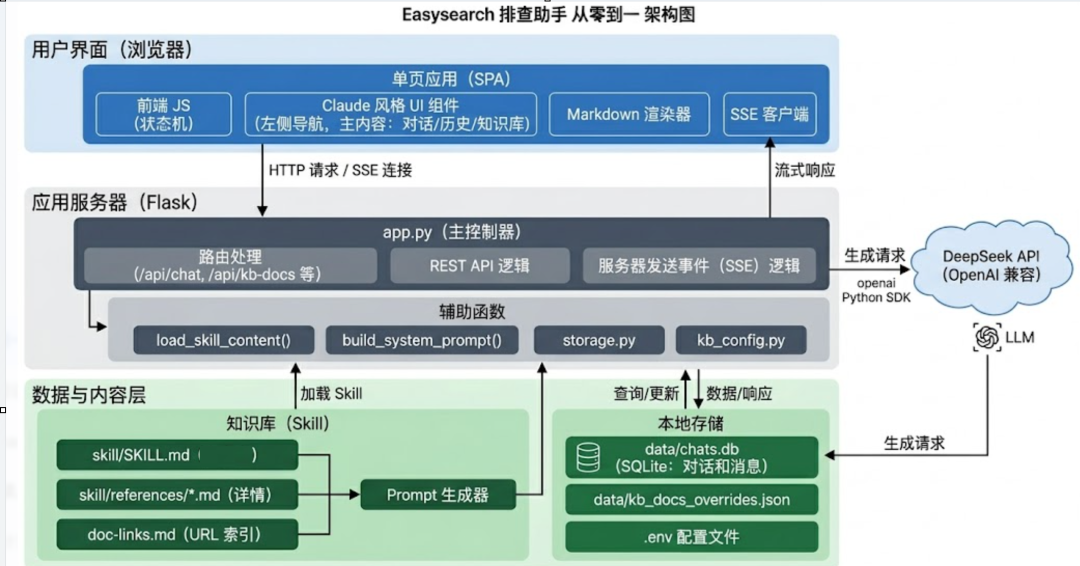
这是一个 单机可跑的 Web 小应用:浏览器里聊天,背后 Flask 接 DeepSeek(OpenAI 兼容协议),把本地 Markdown 知识库(Skill) 整包塞进系统提示词里,让模型像带了「INFINI 官方文档 + 实战经验小抄」一样回答;对话记在本地 SQLite,不依赖云数据库。
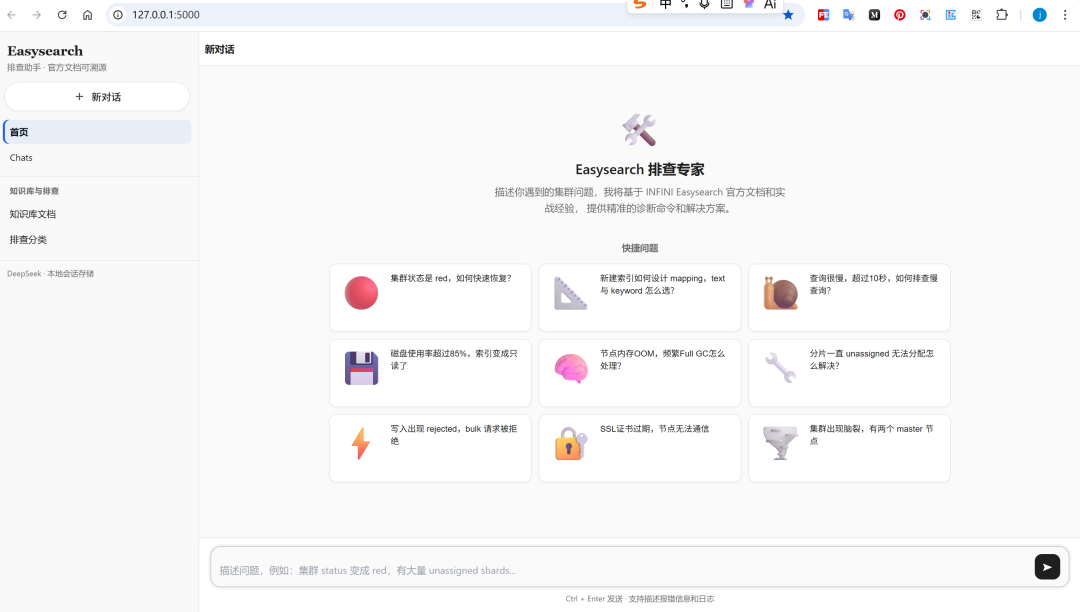
——说白了:搜集群、看 _cat、盯 allocation 的人,要的是可复制命令和可追溯链接,不是空话。
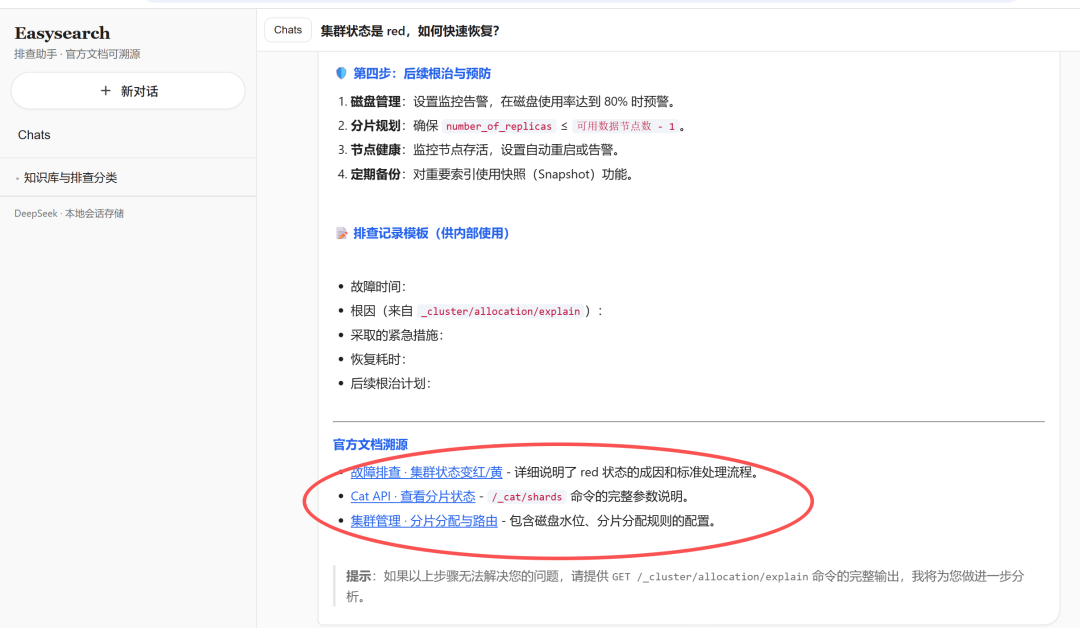
这系统就是把这件事产品化了。
第一层:为什么是 Flask,而不是一上来微服务?
0 到 1 阶段,目标很实在:能演示、能改、能部署在一台机器上。Flask 轻、路由清晰,一个 app.py 把页面、REST API、流式响应串起来,心智负担小。
-
模板:
render_template("index.html")一把梭出单页壳子,剩下交互全靠前端 JS。
-
静态资源:
static/claude_style.css管样式,不跟业务搅在一起。
这不是「技术选型炫技」,而是迭代速度:你改一段 Prompt、加一篇 skill/references/*.md,重启进程就生效——对排查类工具来说,这比先搭 K8s 实在多了。
第二层:模型怎么接?OpenAI SDK + DeepSeek 端点
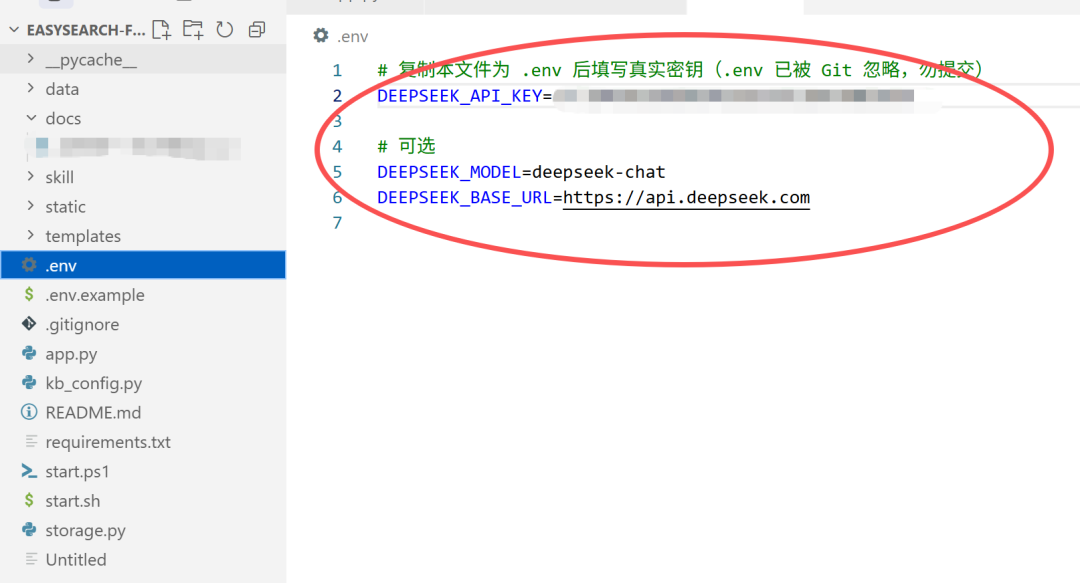
底层用的是 官方 openai Python 包,但 base_url 指向 DeepSeek 兼容端点(默认 https://api.deepseek.com),api_key 从环境变量或项目根目录 .env 读。
这里有两个工程向细节,做过生产对接的人会点头:
load_dotenv(..., override=True)
避免你机器上有个空的 DEEPSEEK_API_KEY 环境变量,把 .env 里真正填好的值给「挡掉」——这种坑在 Windows 上特别常见。
encoding="utf-8-sig"
模型名默认 deepseek-chat,想换推理模型可以改环境变量——协议兼容,换模型不用改业务代码结构。
第三层:Skill 不是附件,是「系统提示词本体」
很多人第一次做 RAG 会想着:先向量库、再检索、再拼 Prompt。这个项目的路线更直接、也更适合强规则领域(官方链接必须对、术语必须准):
-
启动时
load_skill_content()读skill/SKILL.md,再按文件名排序读skill/references/*.md。 -
全部拼成一大段文本,嵌进
build_system_prompt()里。 -
每次请求对话,system 消息里都带着完整知识库。
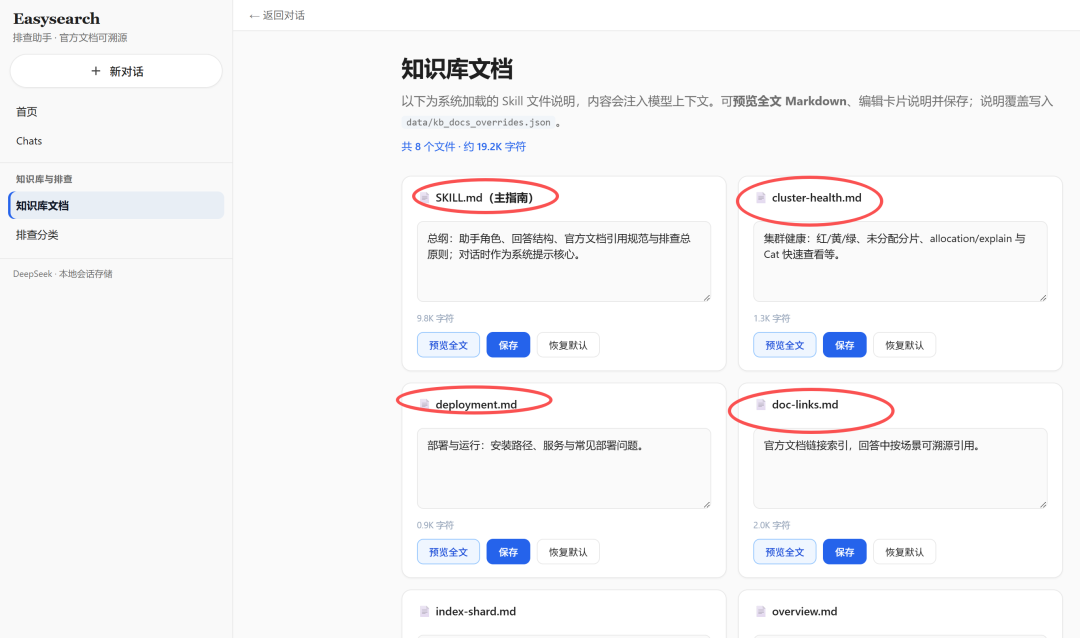
也就是说:不是「检索后再问模型」,而是「模型出厂就背熟了这本小册子」。
代价是 token 会变长;收益是——回答风格、必备章节(比如「官方文档溯源」)、Easysearch 与 ES 差异,全在掌控中,不会出现「检索漏了一条就胡扯」的情况。
这和带一本手写笔记进考场是一个逻辑——笔记要结构化、可引用、可更新,所以我们把 doc-links.md 做成链接索引表,强制回答里给出 docs.infinilabs.com 的真实 URL,而不是让用户去猜「到底看哪一页」。
第四层:系统提示词里「埋了规矩」
除了知识正文,build_system_prompt() 里还写了行为准则和硬约束:
-
中文、步骤化、命令可复制。
-
每轮要有「官方文档溯源」小节,链接必须落在 INFINI 文档站。
-
开发类问题要会用到
elasticsearch-best-practices.md那种融合版说明,避免把 Elasticsearch 官网当唯一真理。
这不是装饰,是产品定义:「能搜」和「敢在生产里照做」中间,差的就是这些规矩。
第五层:流式输出 SSE,为什么聊天体验像「真的在打字」
接口 /api/chat/stream 用 Server-Sent Events:服务端一块块 yield JSON,前端 fetch + ReadableStream 解析,边收边往页面里 append。
好处很直观:
-
用户不用干等整段答案出完才看见字。
-
长回答(排查步骤多的时候)心理压力小很多——这点和 Claude 类产品是同一套 UX 逻辑。
非流式的 /api/chat 也留着,给脚本或调试用——**同一套 build_openai_messages**,避免两套逻辑漂移。
第六层:SQLite 本地会话——「你的聊天记录是你的」
storage.py 里用 SQLite 建了两张表:chats(会话元数据)和 messages(消息行)。
路径在 data/chats.db,外键级联删除,按 updated_at 排序列表——这就是侧栏「历史对话」的数据来源。
设计取向很清晰:
-
不登录、不账号体系:先把「单人本地工具」做到极致。
-
UUID 会话 id:合并、删除、多端扩展以后都好接。
你如果熟悉 ES 圈子的工具链,可以理解为:集群在远程,脑子(对话)在本地——符合很多工程师的真实使用场景。
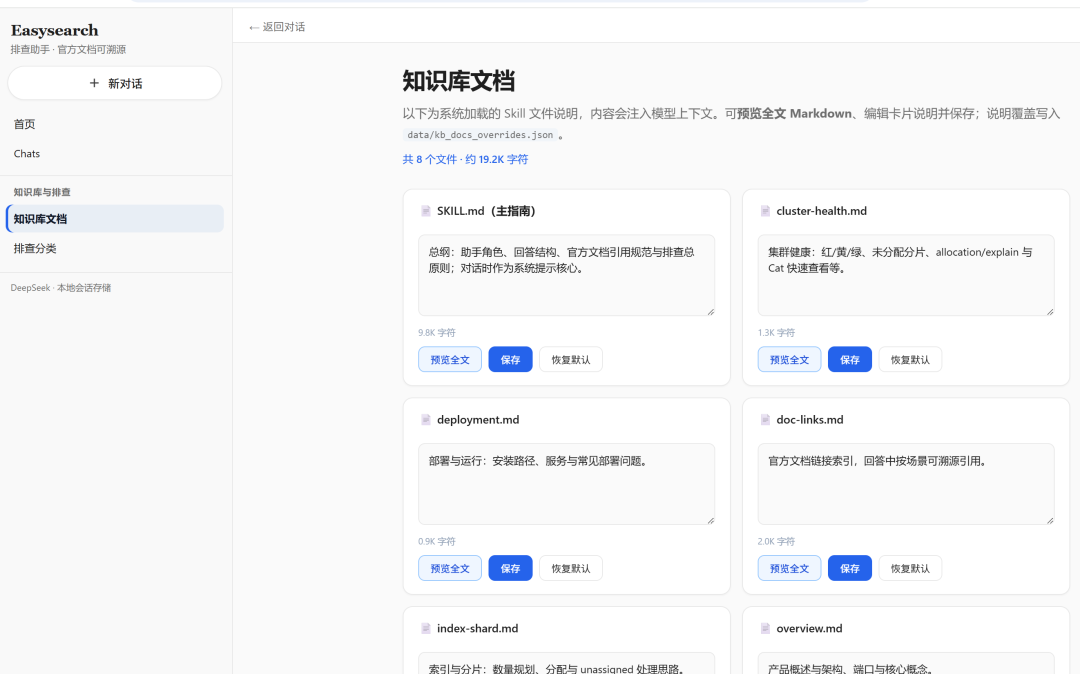
第七层:知识库页面的「可运营」——kb_config
光有默认说明不够,有人想给每张卡片写自己的一句人话介绍。于是:
-
默认说明在
app.py的SKILL_FILE_DESCRIPTIONS。 -
用户自定义写在 **
data/kb_docs_overrides.json**,由kb_config.py读写、合并。
-
前端「知识库文档」页可以编辑保存,走 **
PUT /api/kb-docs**。
effective_description() 解决的是:展示用文案和真正注入模型的全文可以分开——文案短一点没关系,模型里仍然是完整 Markdown。
第八层:全文预览 API
GET /api/skill-file?name=xxx.md 返回某个 skill 文件的原文,前端用已有的 Markdown 转 HTML 逻辑做模态框预览。
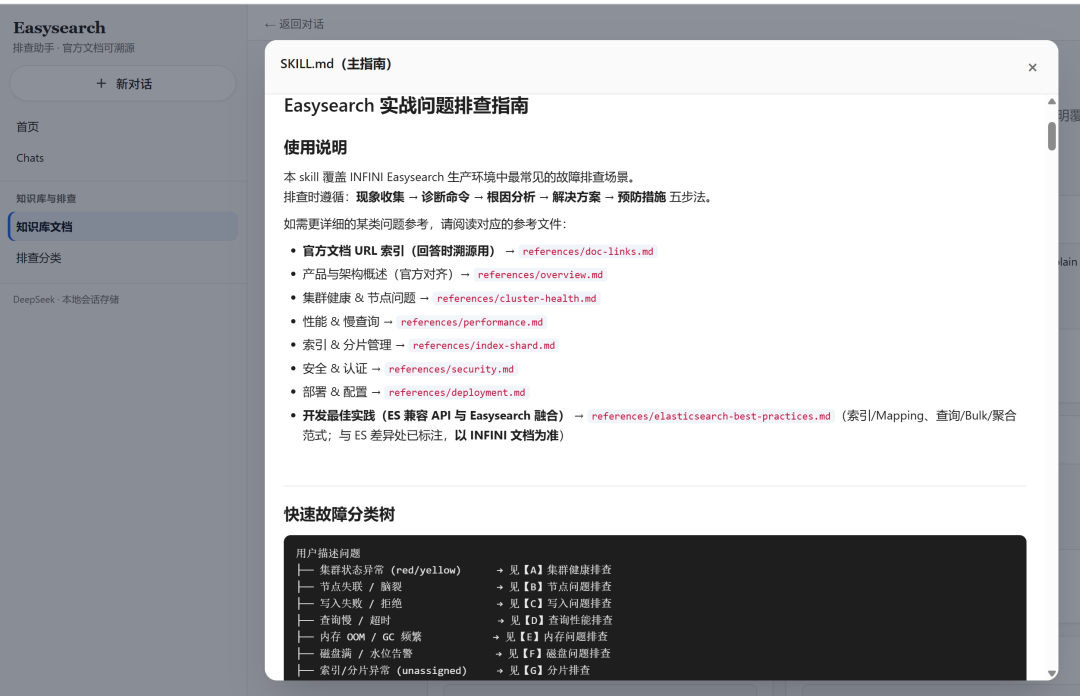
技术点不大,产品意义是:让人敢点「预览」——看得见全文,才信得过助手读的是同一本书。
第九层:前端——「像 Claude」到底像在哪?
不是照搬品牌,而是交互与视觉习惯:
|
点 |
作用 |
|---|---|
|
左侧固定导航 + 主区内容 |
对话、历史、知识库、排查分类场景切换清楚 |
|
浅灰背景 + 白卡片 |
阅读疲劳低
,长回答友好 |
|
圆角、轻阴影、克制配色 |
不像传统后台表格
,愿意多停留 |
|
移动端侧栏抽屉 |
小屏也能用,不牺牲主流程 |
排查分类页用 响应式 Grid 铺 A~J 场景,展开某类时占满一行——这是信息密度和可读性的折中,和聊天区「宽松」形成对比。
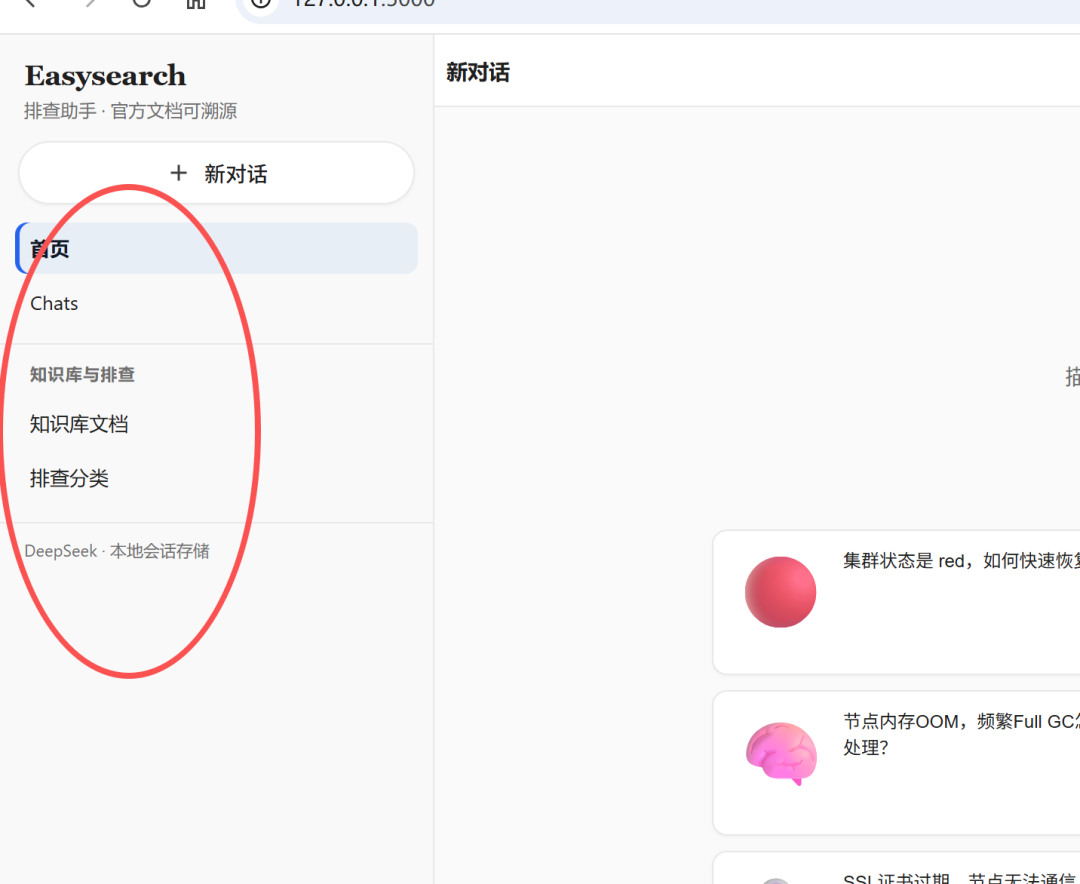
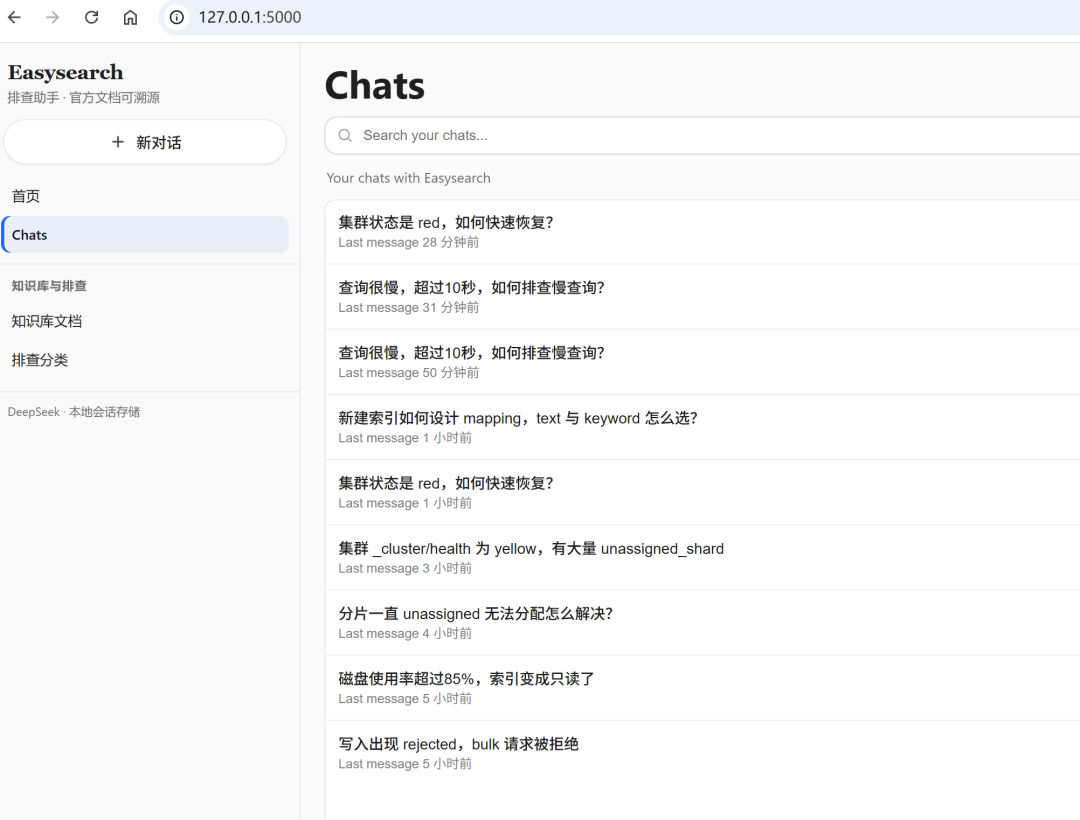
JS 侧主要是单页状态机:display:none 切换 chat-view / chats-view / kb-docs-view / kb-categories-view,配合 syncNavWithView() 给侧栏加 .active——没有上重型框架,维护成本低。
第十层:从 0 到 1 的「最小闭环」长什么样?
用一张心智图收个尾:
flowchart LR
Browser[浏览器]
Flask[Flask 路由]
Prompt[系统提示 = Skill 全文 + 规矩]
DS[DeepSeek API]
DB[(SQLite 会话)]
Browser --> Flask
Flask --> Prompt
Prompt --> DS
DS --> Browser
Flask --> DB你换一篇 Skill、重启服务,闭环不变;你换模型(仍兼容 OpenAI 协议),也就改环境变量。
这就是「0 到 1」里刻意保持的简单:先把领域知识绑死在 Prompt 里,把体验绑死在流式 + 本地存储里——剩下才是向量库、多用户、权限,那是 1 到 10 的故事了。
谁适合拿来用、拿来改?
-
Easysearch / ES 兼容栈的运维、实施:
当随身问答本,命令和链接都能对上号。
-
想给团队做一个「带规范文档的问答界面」的开发者:
这套结构换领域(换 Skill 目录 + 改溯源链接规则)就能复用。
-
介意数据出境的:
对话在本地 SQLite,只有调用模型时走 API——边界清晰。
结语
这套东西没有「黑科技」,有的是把领域知识、模型规矩、产品体验拧在一根绳上的耐心。
前端像 Claude,是为了让你愿意打开、愿意多问一句;背后像一本随时可改的实战笔记,是为了你照做的时候心里不虚。

Elasticsearch vs Easysearch 选型避坑指南
Easysearch 向量搜索 vs Elasticsearch:别再问"兼容不兼容"了,先看这篇
古法工具,依然受用——Cerebro + Easysearch 避坑指南
Easysearch——Elasticsearch 国产化替代方案!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)